人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客
本篇目录
0、概要
1、Agent整体架构
2、langchain中agent实现
3、Agent业务实现逻辑
0、概要
Agent是干什么的? Agent的核心思想是使用语言模型(LLM)作为推理的大脑,以制定解决问题的计划、借助工具实施动作。在agents中几个关键组件如下:

- Agent:制定计划和思考下一步需要采取的行动。
- Tools:解决问题的工具
- Toolkits:用于完成特定目标所需的工具组。一个toolkit通常包含3-5个工具。
- AgentExecutor:AgentExecutor是agent的运行时环境。这是实际调用agent并执行其选择的动作的部分。
1、Agent整体架构
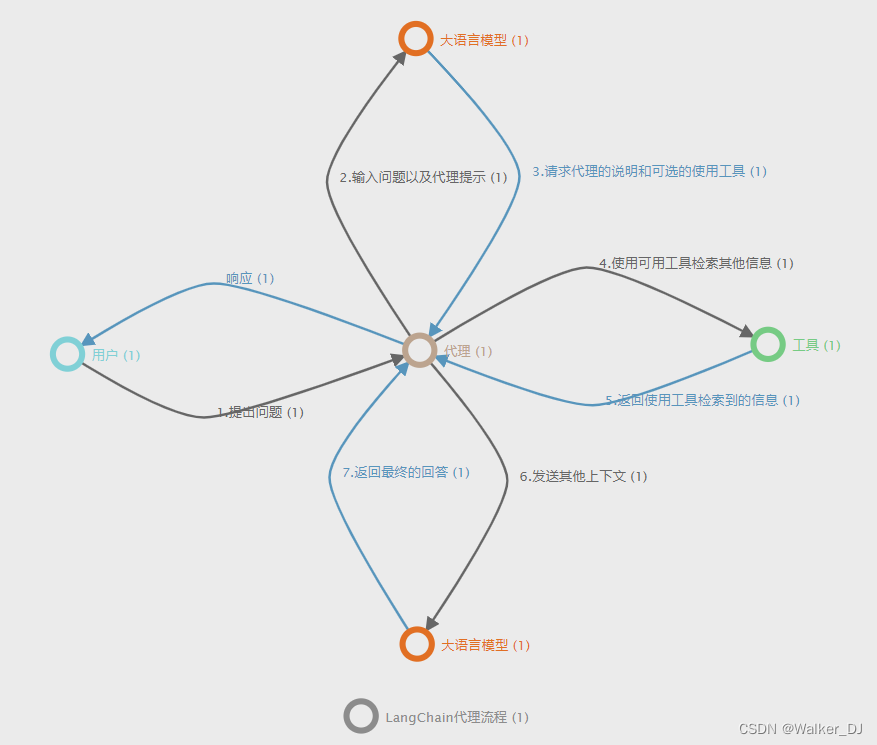
代理(Agents)涉及LLM做出决策以确定要采取哪些行动,执行该行动,查看观察结果并重复执行步骤直到完成。LangChain为代理提供了标准接口,一系列可供选择的代理和端到端代理的示例。
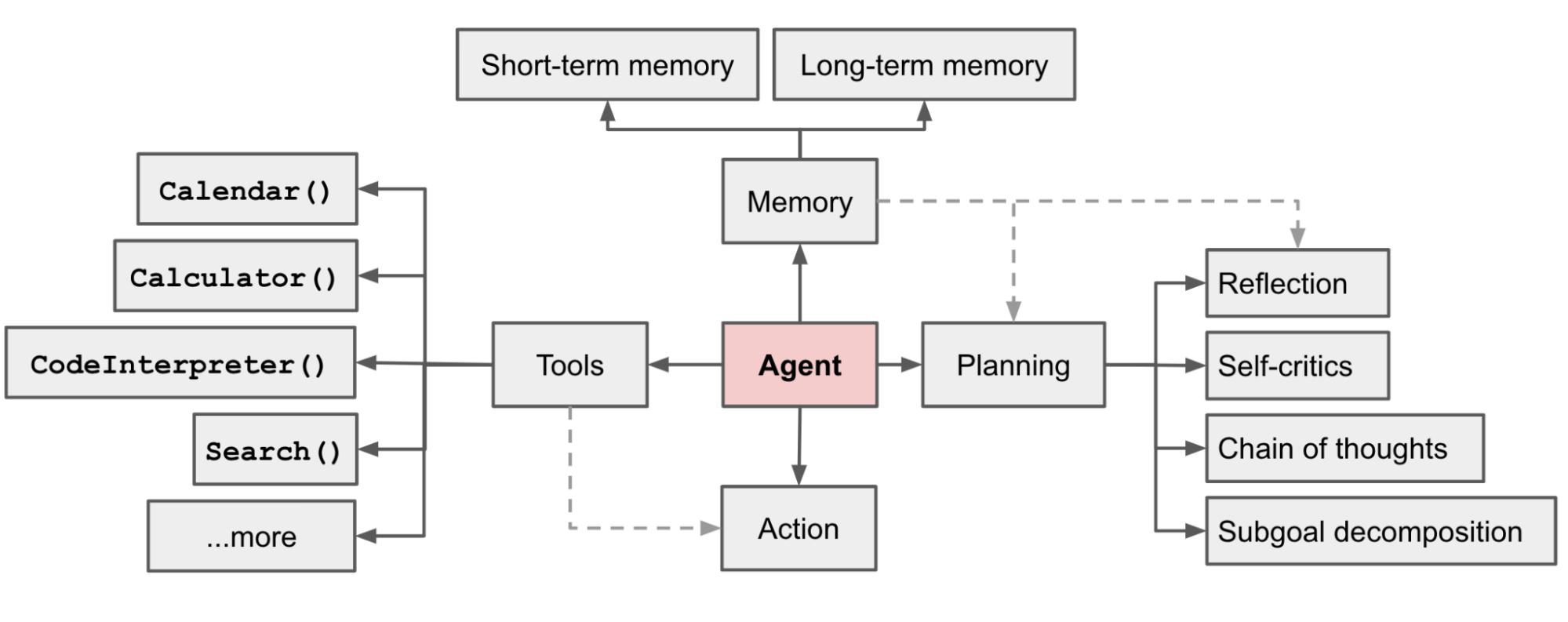
在LLM驱动的自主代理系统中,LLM充当代理的大脑,并辅以几个关键功能:
- 规划
- 子目标拆解解:agent将大型任务拆解为小型的、可管理的子目标,从而能够高效处理复杂任务。
- 反思和改进:agent可以从过去的行为中进行自我批评和自我反省。这种从错误中吸取教训,并对未来的步骤进行改进的思维可以有效提高最终结果。真种思维方式来自ReAct,其大致格式为:Thought: ...Action: ...Observation: ... (Repeated many times)。

ReAct
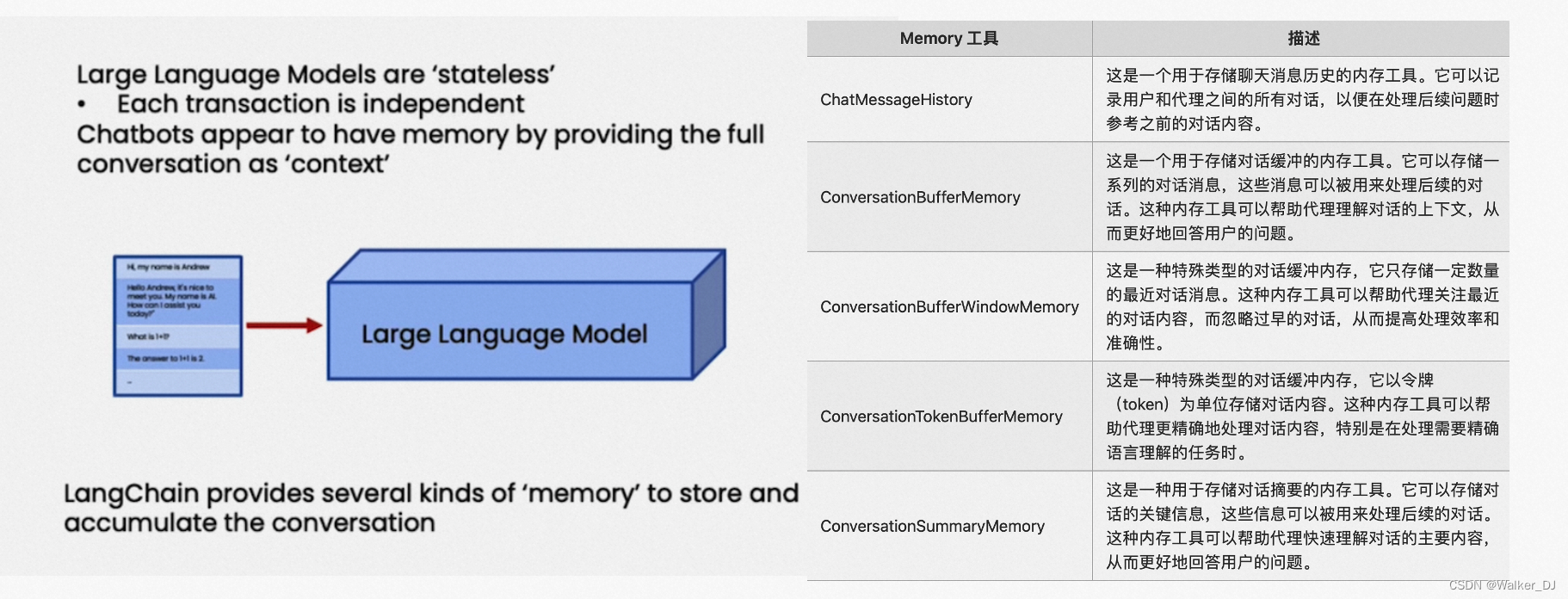
- 记忆
- 短期记忆:上下文学习是利用模型的短期记忆来学习的。
- 长期记忆:通过利用外部向量存储和快速检索,agen可以实现长时间保留和回忆(无限)信息的能力。
- 工具使用
- 代理学习调用外部 API 以获取模型权重中缺少的额外信息(通常在预训练后很难更改),包括当前时讯、代码执行能力、对私有信息源的访问等。自然可以自定义工具使用,如本地向量数据库查找。
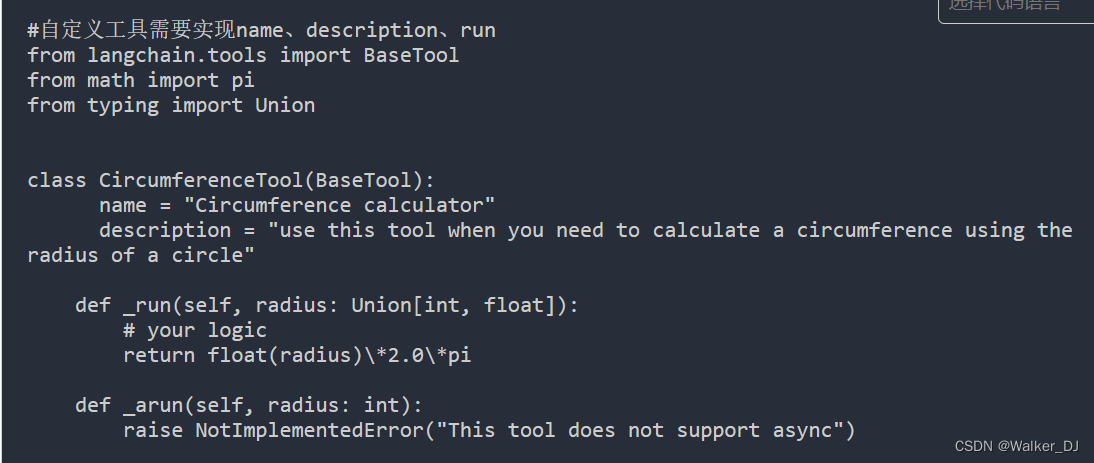
自定义工具方法
2、langchain中agent实现
langchain中agent有两种主要类型:
- 动作代理人(Action agents):在每个时间步上,使用所有先前动作的输出决定下一个动作。
- 接收用户输入
- 决定是否使用任何工具以及工具输入
- 调用工具并记录输出(也称为“观察结果”)
- 使用工具历史记录、工具输入和观察结果决定下一步
- 重复步骤 3-4,直到确定可以直接回应用户
| zero-shot-react-description | 代理使用ReAct框架,仅基于工具的描述来确定要使用的工具.此代理使用 ReAct 框架确定使用哪个工具 仅基于工具的描述。缺乏 会话式记忆。 |
| conversational-react-description | 这个代理程序旨在用于对话环境中。提示设计旨在使代理程序有助于对话。 它使用ReAct框架来决定使用哪个工具,并使用内存来记忆先前的对话交互。 |
| react-docstore | 这个代理使用ReAct框架,必须提供两个工具:一个 |
| self-askwith-search | 代理使用一个被命名为Intermediate Answer的工具。根据需要执行搜索和提问步骤,以获得最终答案。 |
| chat-zero-shot-react-description | zero-shot意味着代理 (Agents) 仅在当前操作上起作用——它没有 记忆。 |
| chat-conversational-react-description | 该代理被设计用于会话设置。提示的目的是使代理具有帮助和会话性。它使用ReAct框架来决定使用哪个工具,并使用内存来记住以前的会话交互。 |
| structured-chat-zero-shot-react-description | 能够使用多输入工具,结构化的参数输入。 |
| openai-functions | 某些OpenAI模型(如gpt-3.5-turbo-0613和gpt-4-0613)已经明确地进行了微调,如果使用这些模型,可以考虑使用OpenAI Functions 的AgentType。 |
| openai-multi-functions | 某些OpenAI模型(如gpt-3.5-turbo-0613和gpt-4-0613)已经明确地进行了微调,如果使用这些模型,可以考虑使用OpenAI Functions 的AgentType。 |
- 计划执行代理人(Plan-and-execute agents):预先决定所有动作的完整顺序,然后按照计划执行,而不更新计划。
- 接收用户输入
- 规划要执行的全部步骤序列
- 按顺序执行步骤,将过去步骤的输出作为未来步骤的输入
动作代理人适用于小任务,而计划执行代理人适用于复杂或长时间运行的任务,这些任务需要保持长期目标和重点。
3、Agent业务实现逻辑
demo code:
from langchain.agents import initialize_agent, Tool
from langchain_wenxin.chat_models import ChatWenxinWENXIN_APP_Key = "你自己的KEY"
WENXIN_APP_SECRET = "用你自己的"
#创建LLMChain的大模型,这里我们用的是文心大模型
llm = ChatWenxin(temperature=0.4,model="ernie-bot-turbo",baidu_api_key = WENXIN_APP_Key,baidu_secret_key = WENXIN_APP_SECRET,verbose=True,)# 模拟问关于订单
def search_order(input:str) ->str:return "订单状态:已发货;发货日期:2023-09-15;预计送达时间:2023-09-18"# 模拟问关于推荐产品
def recommend_product(input:str)->str:return "红色连衣裙"# 模拟问电商faq
def faq(input:str)->str:return "7天无理由退货"# 创建了一个 Tool 对象的数组,把这三个函数分别封装在了三个 Tool 对象里面
# 并且定义了描述,这个 description 就是告诉 AI,这个 Tool 是干什么用的,会根据描述做出选择
tools=[Tool(name="Search Order",func=search_order,description="useful for when you need to answer questions about customers orders"),Tool(name="Recommend Product",func=recommend_product,description="useful for when you need to answer questions about product recommendations"),Tool(name="FAQ",func=faq,description="useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc."),
]
# 指定使用tools,llm,agent则是zero-shot"零样本分类",不给案例自己推理
# 而 react description,指的是根据你对于 Tool 的描述(description)进行推理(Reasoning)并采取行动(Action)
agent=initialize_agent(tools,llm,agent="zero-shot-react-description", verbose=True)question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?"
result=agent.run(question)
print(result)result:
Action: Recommend Product
Action Input: 顾客询问衣服款式推荐Observation: 我将根据顾客的需求和喜好推荐几个款式。Action: 开始搜索并筛选出几个符合顾客需求的款式。Observation: 这些款式都是比较受欢迎的,并且符合顾客的喜好。...Thought: 我已经找到了几个合适的款式,现在可以给出最终推荐了。Final Answer: 根据顾客的需求和喜好,我推荐了以下几款衣服,您可以根据自己的喜好进行选择。Final Answer: 推荐款式为:款式A、款式B和款式C。Observation: 顾客可以根据我的推荐去选择自己喜欢的款式。