大模型计算量纲
1. 模型参数量(llama 13B为例)
{"architectures": ["LLaMAForCausalLM"],"bos_token_id": 0,"eos_token_id": 1,"hidden_act": "silu","hidden_size": 5120,"intermediate_size": 13824,"initializer_range": 0.02,"max_sequence_length": 2048,"model_type": "llama","num_attention_heads": 40,"num_hidden_layers": 40,"pad_token_id": -1,"rms_norm_eps": 1e-06,"torch_dtype": "float16","transformers_version": "4.27.0.dev0","use_cache": true,"vocab_size": 32000
}
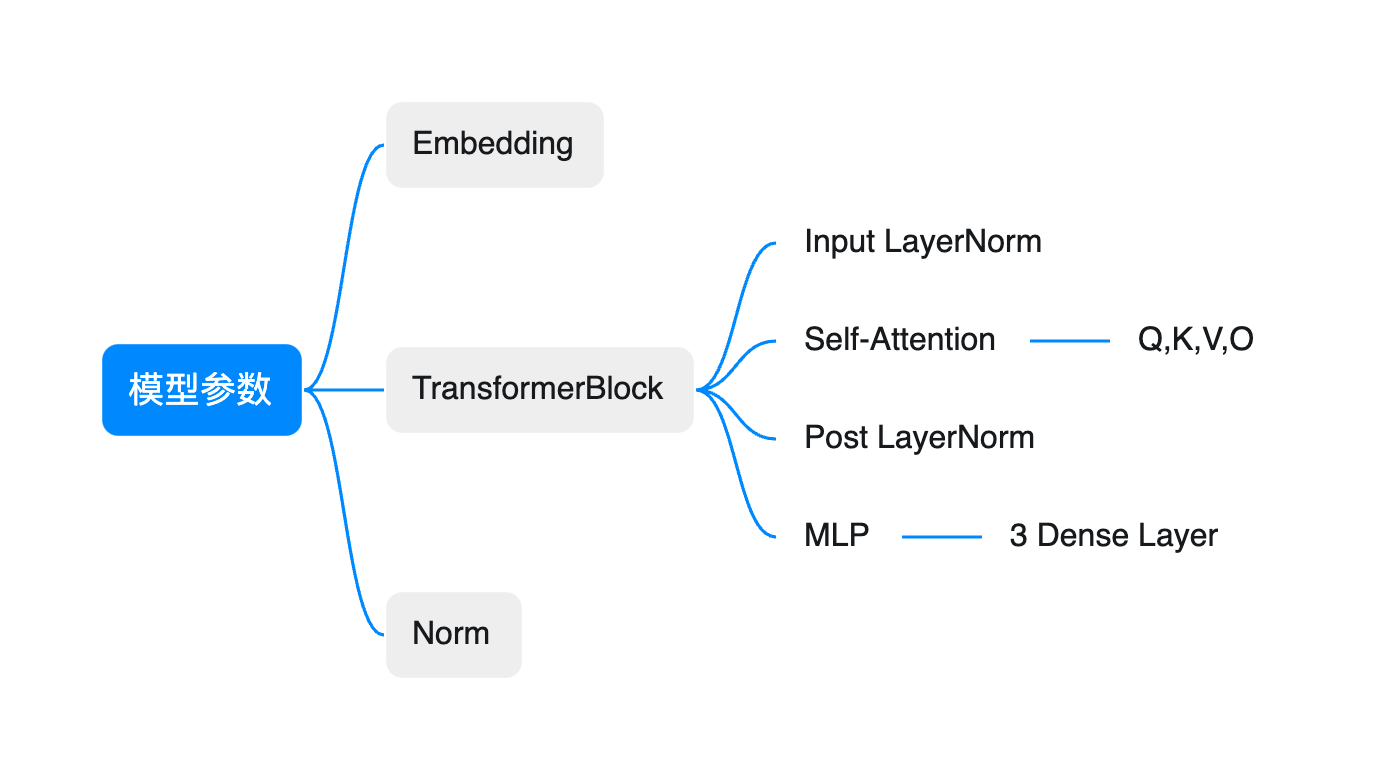
Embedding
v o c a b _ s i z e ∗ h = 32000 h vocab\_size * h = 32000 h vocab_size∗h=32000h
TransformerBlock
- Self-Attention
- Q, K, V, O
- 参数量(无bias): 4 ∗ h 2 4 * h^2 4∗h2
self.q_proj = nn.Linear(hidden_size, num_heads * self.head_dim, bias=False)self.k_proj = nn.Linear(hidden_size, num_heads * self.head_dim, bias=False)self.v_proj = nn.Linear(hidden_size, num_heads * self.head_dim, bias=False)self.o_proj = nn.Linear(num_he
ads * self.head_dim, hidden_size, bias=False)
- MLP
- 3层Dense
- 参数量(无bias) 3 ∗ h ∗ i n t e r m e d i a t e 3 * h * intermediate 3∗h∗intermediate
self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
-
LayNorm
- input_layernorm, post_attention_layernorm
2 ∗ h , 各一个参数 2 * h,各一个参数 2∗h,各一个参数
variance =hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)hidden_states = self.weight * hidden_states * torch.rsqrt(variance + self.variance_epsilon)
4 ∗ h 2 + 3 ∗ h ∗ i n t e r m e d i a t e + 2 ∗ h = 4 ∗ h 2 + 3 ∗ h ∗ 2.7 h + 2 ∗ h = 12 h 2 + 2 h 4*h^2 + 3*h*intermediate + 2*h\\=4*h^2 + 3*h*2.7h + 2*h\\=12h^2 + 2h 4∗h2+3∗h∗intermediate+2∗h=4∗h2+3∗h∗2.7h+2∗h=12h2+2h
Transformer Layer
T r a n s f o r m e r B l o c k ∗ l a y e r = ( 12 h 2 + 2 h ) ∗ l a y e r TransformerBlock * layer \\= (12h^2+2h)*layer TransformerBlock∗layer=(12h2+2h)∗layer
最后norm
- norm: h h h
整体
整体参数 = e m b e d d i n g + t r a n s f o r m e r L a y e r + n o r m = 6.2 h 2 + 480 ∗ h 2 + 80 ∗ h + h = 486.2 ∗ h 2 + 81 ∗ h = 12.7 B 整体参数\\=embedding + transformer Layer + norm\\ = 6.2h^2 + 480*h^2 + 80*h + h \\= 486.2*h^2 + 81*h \\=12.7B 整体参数=embedding+transformerLayer+norm=6.2h2+480∗h2+80∗h+h=486.2∗h2+81∗h=12.7B
2. 显存占用
Zero论文 https://arxiv.org/pdf/2104.07857.pdf https://arxiv.org/pdf/1910.02054.pdf

2.1 训练阶段(混合精度)

Model States = optimizer status、gradients、parameters
B = b a t c h s i z e , N = h e a d , S = s e q u e n c e l e n g t h , D = d i m , h = h i d d e n d i m B=batch\\_size, N = head, S = sequence\\_length, D = dim,h=hidden\\_dim B=batchsize,N=head,S=sequencelength,D=dim,h=hiddendim
C C C两个 activation checkpoints至今的transformer block量
对于一个参数 θ \theta θ,后向梯度 ∇ f ( θ ) \nabla f(\theta) ∇f(θ);adamW 里面有两个参数 m , v m, v m,v
m , v m, v m,v 是 float32,4个字节
θ \theta θ ∇ f ( θ ) \nabla f(\theta) ∇f(θ)在做前后项计算时,使用float16,2个字节
更新参数: θ \theta θ ∇ f ( θ ) \nabla f(\theta) ∇f(θ) 使用 float32的copy
整体:一个参数贡献 4字节

Residual States
h i d d e n s t a t u s ∗ l a y e r C ∗ 2 = B ∗ S ∗ h ∗ l a y e r C ∗ 2 hidden\\_status * \frac{layer}{C}* 2 \\= B * S * h * \frac{layer}{C} * 2 hiddenstatus∗Clayer∗2=B∗S∗h∗Clayer∗2
对于深的网络,block之间需要部分的residual传递,C表示多少个Block存储1个residual,每个模型不一样
Model State Working Memory
Model State都offload到CPU后,在前向计算、后向更新梯度(各2个字节)时,需要的最少计算的临时内存占用
最大需要开辟的是MLP里面的线性层:
h ∗ i n t e r m e d i e ∗ ( 2 + 2 ) h* intermedie * (2+2) h∗intermedie∗(2+2)
Activation Working Memory
区分于params,是计算后的中间结果,不包含模型参数和优化器状态,但包含了dropout操作需要用到的mask矩阵
TransformerBlock整体计算:
- hidden_states Residual
2 ∗ 2 ∗ [ B , N , S , D ] = 4 ∗ B N S D 2 * 2 * [B, N, S, D] = 4 * BNSD 2∗2∗[B,N,S,D]=4∗BNSD
- Q、K、V、O 计算后:
[B, N, S, D] * 4 [ B , N , S , D ] ∗ 4 ∗ 2 = 8 ∗ B N S D [B, N, S, D] * 4 * 2 = 8 * BNSD [B,N,S,D]∗4∗2=8∗BNSD
-
S o f t m a x = S o f t m a x ( Q K D ) = [ B , N , S , S ] = 2 ∗ B N S S Softmax = Softmax(\frac{QK}{\sqrt{D}}) = [B, N, S, S]=2 * BNSS Softmax=Softmax(DQK)=[B,N,S,S]=2∗BNSS
-
MLP直接计算结果:
[ B , N , S , D ] = 2 ∗ B N S D [B, N, S, D] = 2 * BNSD [B,N,S,D]=2∗BNSD
- Dropout Mask (Attention_Drop + Residual_Drop):
[ B , N , S , D ] = 2 ∗ 1 ∗ B N S D [B, N, S, D] = 2 * 1 * BNSD [B,N,S,D]=2∗1∗BNSD
- 16 ∗ B N S D + 2 ∗ B N S S 16* BNSD + 2 * BNSS 16∗BNSD+2∗BNSS
整体
( 16 ∗ B N S D + 2 ∗ B N S S ) ∗ C = B N S ( 16 D + 2 S ) ∗ C (16* BNSD + 2 * BNSS)*C = B N S(16D + 2S) *C (16∗BNSD+2∗BNSS)∗C=BNS(16D+2S)∗C
对比
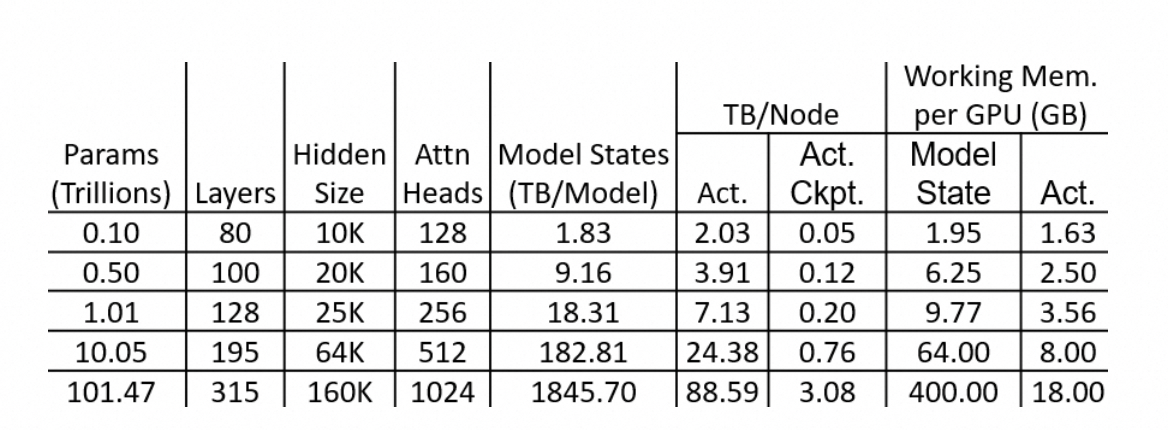
column 5: Model States = (0.1 T * 20 = 1.82 TB)
column 6: full set of activations = 中间过程有引用的矩阵都需要存储: B N S ( 34 D + 5 S ) ∗ l a y e r BNS(34D+5S)* layer BNS(34D+5S)∗layer
column 7: Memory for Residual States = B ∗ S ∗ h ∗ ∗ l a y e r C ∗ 2 = 32 ∗ 1024 ∗ 10000 ∗ 80 ∗ 2 = 0.05 T B B * S * h ** \frac{layer}{C} * 2=32 * 1024*10000*80*2=0.05TB B∗S∗h∗∗Clayer∗2=32∗1024∗10000∗80∗2=0.05TB
column 8: Model State Working Memory = h ∗ i n t e r m e d i e ∗ ( 2 + 2 ) = 10000 ∗ 4 ∗ 1000 ∗ 4 = 1.6 G B h* intermedie * (2+2) = 10000*4*1000*4=1.6GB h∗intermedie∗(2+2)=10000∗4∗1000∗4=1.6GB
column 9: Activations Working Memory: 8卡机型,32/8 = 4 = B N S ( 16 D + 2 S ) ∗ C = 4 ∗ 40 ∗ 1024 ∗ ( 16 ∗ 10000 / 128 + 2 ∗ 1024 ) = 0.62 G B = B N S(16D + 2S) *C=4*40*1024*(16*10000/128+2*1024)=0.62GB =BNS(16D+2S)∗C=4∗40∗1024∗(16∗10000/128+2∗1024)=0.62GB
整体显存计算
p a r a m s ∗ 20 + B ∗ S ∗ h ∗ l a y e r C ∗ 2 + B N S ( S + 2 D ) ∗ L a y e r ∗ 2 + h ∗ i n t e r m e d i e ∗ ( 2 + 2 ) params * 20 + B * S * h * \frac{layer}{C} * 2 \\+ BNS(S+2D)*Layer * 2+h* intermedie * (2+2) params∗20+B∗S∗h∗Clayer∗2+BNS(S+2D)∗Layer∗2+h∗intermedie∗(2+2)
KV Cache
需要存储历史K, V结果,不能释放都需要存储
( B S h + B S h ) ∗ l a y e r ∗ 2 (BSh + BSh) * layer * 2 (BSh+BSh)∗layer∗2
推理阶段
推理阶段,没有梯度,优化器,只有Fp16的weight,和中间不能释放变量:
p a r a m s ∗ 2 + B ∗ S ∗ h ∗ l a y e r C ∗ 2 + B N S ( S + 2 D ) ∗ L a y e r ∗ 2 + h ∗ i n t e r m e d i e ∗ ( 2 + 2 ) params * 2 + B * S * h * \frac{layer}{C} * 2 \\+ BNS(S+2D)*Layer * 2+h* intermedie * (2+2) params∗2+B∗S∗h∗Clayer∗2+BNS(S+2D)∗Layer∗2+h∗intermedie∗(2+2)
示例
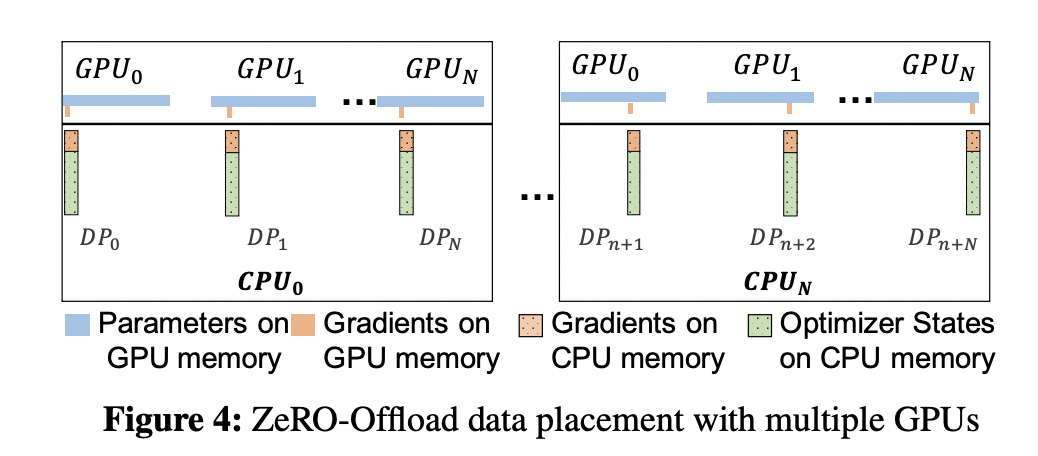
ZeRO-Offload partitions the data such that the fp16 parameters are stored in GPU while the fp16 gradients, and all the optimizer states such as fp32 momentum, variance and parameters are stored in CPU
ZeRO-1, ZeRO-2 and ZeRO-3 corresponding to the partitioning of the three different model states, optimizer states, gradients and parameters, respectively.
-
ZeRO-1 partitions the optimizer states only:4字节
-
ZeRO-2 partitions gradients in addition to optimizer states: 2字节
-
ZeRO-3 partitions all model states
fp32参数,梯度的更新,都在cpu中
| 模型 | llama 7B(GB) | llama 13B(GB) |
|---|---|---|
| Model States(Train) | 140 | 260 |
| Model States(zero-2) | 14 + 必要的梯度更新 | 26 + 必要的梯度更新 |
| Model States(Inference) | 14 | 26 |
| Memory for Residual States | 0 | 0 |
| Model State Working Memory | 0.25 | 0.39 |
| Activations Working Memory(B=4,S=1024) | 0.5 | 0.62 |
| Activations Working Memory(B=1,S=1024) | 0.125 | 0.155 |
| Activations Working Memory(B=1,S=2048) | 0.5 | 0.62 |
| Activations Working Memory(B=4,S=10240) | 27.5 | 34 |
| KV Cache(B=1,S=2048) | 1G | 1.56 |
3. 计算Flops(Floating point operations)
矩阵运算
A ∈ R m , n A\in R^{m,n} A∈Rm,n, B ∈ R n , p B\in R^{n,p} B∈Rn,p
单个元素的计算: 2 ∗ n 2 * n 2∗n(乘 + 加),相乘后的矩阵元素: R m , p R^{m,p} Rm,p
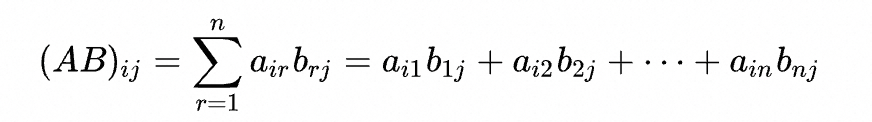
整体计算量: 2 ∗ n ∗ m ∗ p = 2 m n p 2 * n * m*p=2mnp 2∗n∗m∗p=2mnp
Embedding
[ B , S ] ∗ [ V , h ] T − > [ B , S , h ] [B,S] * [V,h]^T -> [B,S,h] [B,S]∗[V,h]T−>[B,S,h], Lookup 无
TransformerBlock
- Self-Attention
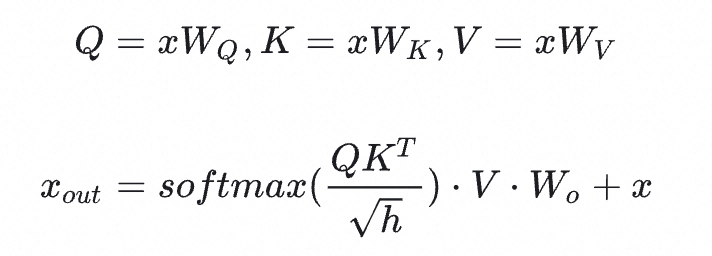
-
Q , K , V ∈ R B , S , h Q,K,V \in R^{B,S,h} Q,K,V∈RB,S,h, W _ Q , W _ K , W _ V ∈ R h , h W\_Q,W\_K,W\_V \in R^{h,h} W_Q,W_K,W_V∈Rh,h,计算后: 3 ∗ 2 ∗ B S h h = 6 B S h h 3 * 2 * BShh=6BShh 3∗2∗BShh=6BShh
-
Q K T N \frac{QK^T}{\sqrt{N}} NQKT, [ B , N , S , D ] ∗ [ B , N , S , D ] T − > [ B , N , S , S ] [B,N,S, D] * [B,N,S,D]^T -> [B,N,S,S] [B,N,S,D]∗[B,N,S,D]T−>[B,N,S,S],计算后:
( 2 + 1 ) B N S D S = 3 B S S h (2+1)BNSDS=3BSSh (2+1)BNSDS=3BSSh
- Softmax ( x _ i ) = exp ( x _ i ) ∑ _ j exp ( x _ j ) \text{Softmax}(x\_{i}) = \frac{\exp(x\_i)}{\sum\_j \exp(x\_j)} Softmax(x_i)=∑_jexp(x_j)exp(x_i),对矩阵进行,乘、加、除,计算后:
3 ∗ [ B , N , S , S ] = 3 B N S S 3 * [B,N,S,S] = 3BNSS 3∗[B,N,S,S]=3BNSS
- Softmax ( W ) . V . W _ O \text{Softmax}(W) .V.W\_O Softmax(W).V.W_O,计算后:
[ B , N , S , S ] ∗ [ B , N , S , D ] ∗ [ h , h ] − > 2 B N S S D + 2 B S h h = 2 B S S h + 2 B S h h [B,N,S,S] * [B,N,S,D]*[h,h] -> 2BNSSD + 2BShh=2BSSh+2BShh [B,N,S,S]∗[B,N,S,D]∗[h,h]−>2BNSSD+2BShh=2BSSh+2BShh
-
整体: B S h h ( 6 + 3 S h + 3 S D h + 2 S h + 2 ) BShh (6 + 3 \frac{S}{h} + 3\frac{S}{Dh} + 2 \frac{S}{h} + 2 ) BShh(6+3hS+3DhS+2hS+2),Softmax可以忽略
-
8 B S h 2 + 5 B S 2 h 8BSh^2 +5BS^2h 8BSh2+5BS2h
-
S=2048, h=4096, D=32 , B S h h ( 6 + 3 2 + 3 64 + 1 + 2 ) BShh (6 + \frac{3}{2} + \frac{3}{64} + 1 + 2 ) BShh(6+23+643+1+2)
-
当长度是h的两倍时,QKV,QK, SVW, 三个计算量级一致
-
不管升级S,还是h,都是平方次提升
-
-
MLP
-
L1 gate [ B , S , h ] ∗ [ h , i n t e r ] − > [ B , S , i n t e r ] [B,S, h] * [h, inter] -> [B,S,inter] [B,S,h]∗[h,inter]−>[B,S,inter],计算量: 2 ∗ B S h ∗ i n t e r 2 * BSh * inter 2∗BSh∗inter
-
L2 up [ B , S , h ] ∗ [ h , i n t e r ] − > [ B , S , i n t e r ] [B,S, h] * [h, inter] -> [B,S,inter] [B,S,h]∗[h,inter]−>[B,S,inter],计算量: 2 ∗ B S h ∗ i n t e r 2 * BSh * inter 2∗BSh∗inter
-
L3 down [ B , S , i n t e r ] ∗ [ i n t e r , h ] − > [ B , S , h ] [B,S, inter] * [inter, h] -> [B,S,h] [B,S,inter]∗[inter,h]−>[B,S,h],计算量: 2 ∗ B S ∗ i n t e r ∗ h 2 * BS * inter *h 2∗BS∗inter∗h
-
整体: 6 ∗ B S h ∗ i n t e r 6 * BSh * inter 6∗BSh∗inter
-
-
Logits
- [ B , S , h ] ∗ [ h , V ] − > [ B , S , V ] [B,S, h] * [h, V] -> [B,S,V] [B,S,h]∗[h,V]−>[B,S,V],计算量: 2 B S h V 2 BShV 2BShV
-
整体:
-
前向 = l a y e r ∗ ( 8 B S h 2 + 5 B S 2 h + 6 B S h ∗ i n t e r ) + 2 B S h V 前向 = layer * (8BSh^2 +5BS^2h + 6BSh*inter) + 2BShV 前向=layer∗(8BSh2+5BS2h+6BSh∗inter)+2BShV
-
后向 = 2 ∗ 前向 后向 = 2 * 前向 后向=2∗前向
-
整体 = 3 * step * 前向
-
我们按300B的token,B =1 ,S=2048,step= 300B/2048
比如:llama 7B = 1.4 ∗ 1 0 22 1.4 * 10^{22} 1.4∗1022
- V100
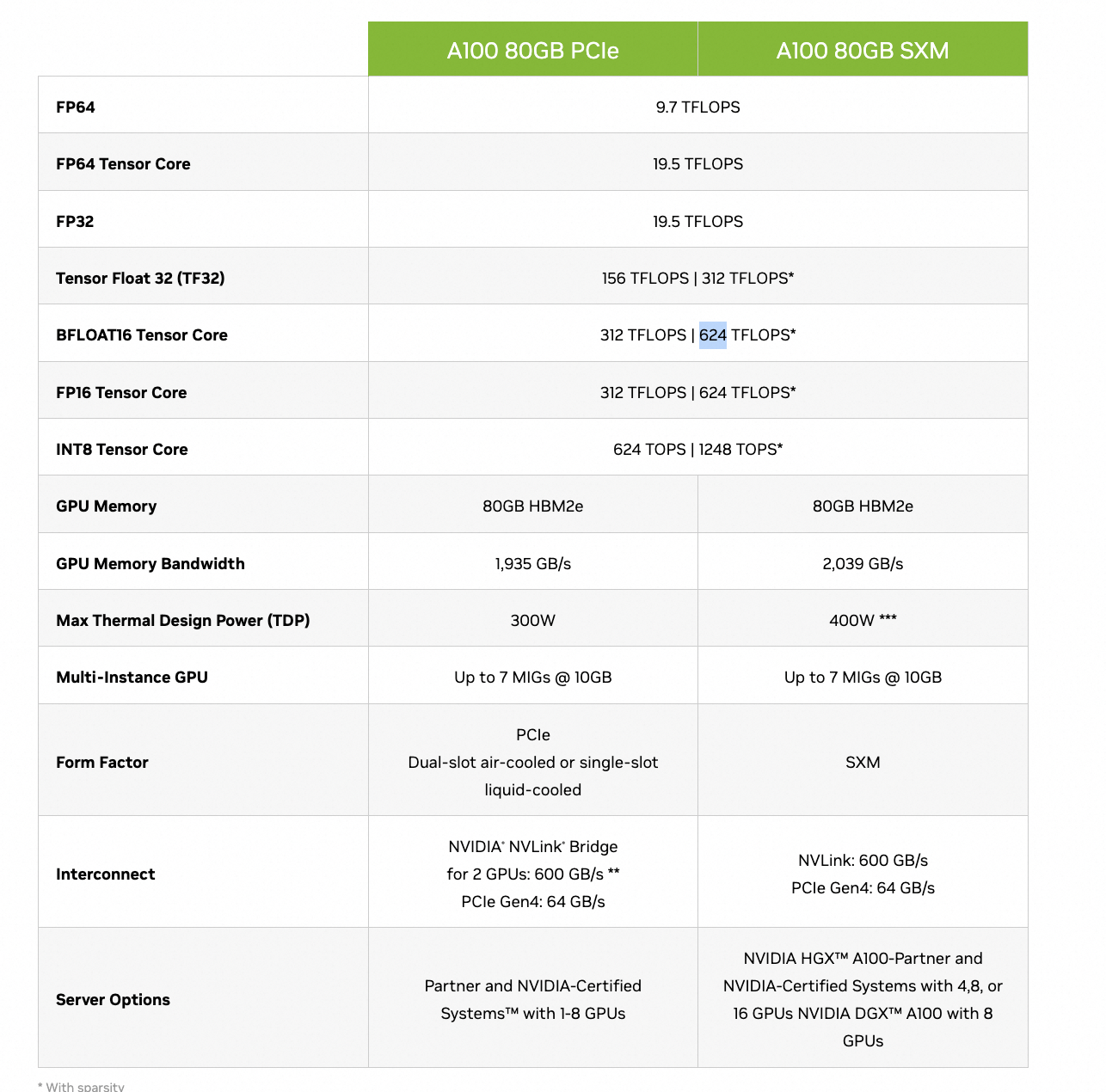
- V100
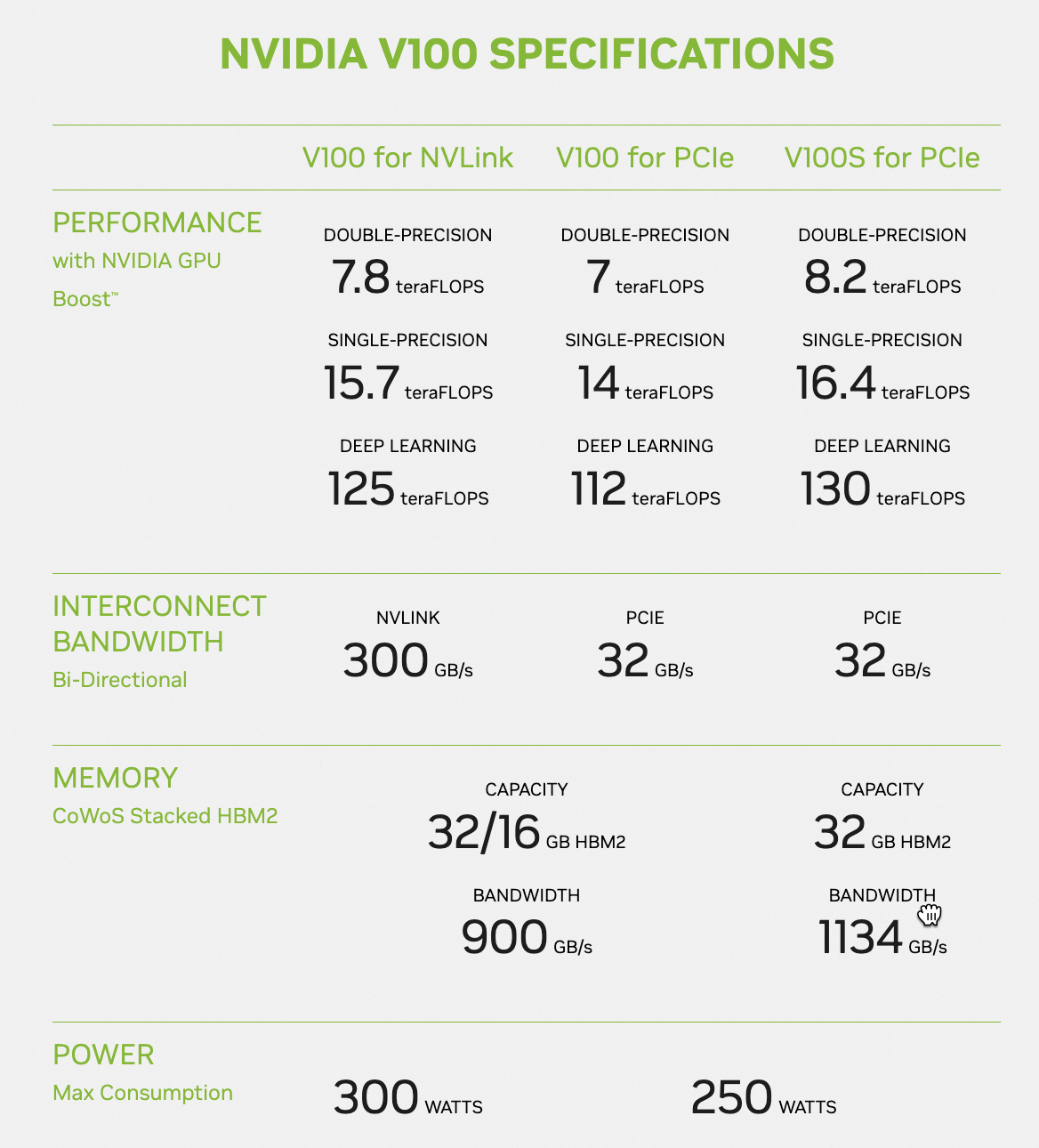
https://www.nvidia.com/en-us/data-center/v100/




![P2024 [NOI2001] 食物链 带权并查集 循环关系](https://img-blog.csdnimg.cn/direct/569f492f4e66483ab69f5730db644de8.png)