文章目录
- 1. 概要
- 2. 方法
- 3. 实验
- 3.1 Compare with SOTA
- 3.2 PRE-TRAINING DATA REQUIREMENTS
- 3.3 SCALING STUDY
- 3.4 自监督学习
- 4. 总结
- 参考
论文: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
代码:https://github.com/google-research/vision_transformer
代码2:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
我们在Transformer详解(1)—原理部分详细介绍了transformer在NLP领域应用的原理,transformer架构自发布以来已经在自然语言处理任务上广泛应用,今天我们将介绍如何将transformer架构应用在图像领域。
1. 概要
基于self-attention的网络架构在NLP领域中取得了很大的成功,但是在CV领域卷积网络架构仍然占据主导地位。受到transformer在NLP中应用成功的启发,也有很多工作尝试将self-attention与CNN网络结合,甚至有些工作直接替换CNN网络,理论上这些模型是高效的,由于这些特殊的注意力机制未与硬件加速器有效适配,因此在大规模的图像检测中,经典的ResNet网络架构仍然是SOTA
受到Transformer网络在NLP领域中成功适配的启发,作者提出对transformer尽可能少的修改,直接在图片上应用标准的transformer。为了实现这个目标,首先需要将图片分割成多个patch,并将这些patch转换成embedding作为transformer的输入。图片的patch就相当于NLP中的token。
最后作者得到结论:在数据量不足的情况下进行训练时,ViT不能很好地泛化,效果不如CNN,不过在训练大规模数据时,vit的效果会反超CNN
2. 方法
在模型设计方面,version transformer尽量与原始transformer结构保持一致,因为NLP中的transformer具有高效的实现方式,这样可以开箱即用。模型的整体结构如下所示:
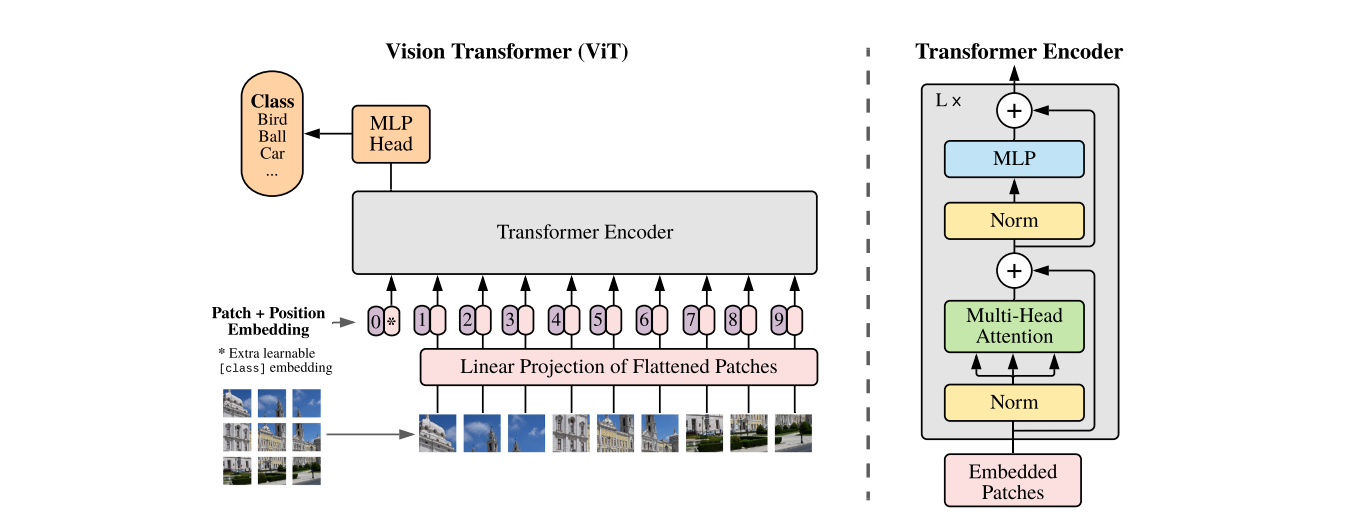
标准的 transformer 输入是一维向量序列,为了处理二维图像,将输入图片 x ∈ R H × W × C \mathbf{x}\in\mathbb{R}^{H\times W\times C} x∈RH×W×C 分割成一系列的patch,并将这些patch平整成一维向量,最终得到 x p ∈ R N × ( P 2 ⋅ C ) \mathbf{x}_p\in\mathbb{R}^{N\times(P^2\cdot C)} xp∈RN×(P2⋅C),其中 ( H , W ) (H,W) (H,W)是原始图片分辨率, C C C 是图片的通道数, ( P , P ) (P,P) (P,P)是每个patch的分辨率, N = H W P 2 N=\frac{HW}{P^2} N=P2HW 是patch的个数,也可以看作是输入序列的长度。由于transformer每一层的输入向量维度都是固定的 D D D,因此需要通过一个可训练的线性层将 flatten patch 的维度从 P 2 C P^2C P2C转换成 D D D,这个线性层的输出称为patch的embedding.
和BERT的 [class] token 类似,在path embedding序列的首位增加了一个可学习向量 z 0 0 = x c l a s s z_0^0=x_{class} z00=xclass,该向量在transformer encoder的输出部分看做是图片的表征,在预训练和微调阶段,该表征后都会接一个分类层。
为了保持位置信息,位置embedding会加到patch embedding上,这里作者使用了一个一维可学习的位置向量,因为通过实验发现使用二维位置向量并没有获得很大的性能提升,通过以上流程处理后的embedding就是transformer的输入embedding。从输入图片到transformer encoder输出可由以下式子表示:
z 0 = [ x class ; x p 1 E ; x p 2 E ; ⋯ ; x p N E ] + E p o s ; E ∈ R ( P 2 ⋅ C ) × D , E p o s ∈ R ( N + 1 ) × D z ′ ℓ = M S A ( L N ( z ℓ − 1 ) ) + z ℓ − 1 ; ℓ = 1 … L z ℓ = M L P ( L N ( z ′ ℓ ) ) + z ′ ℓ ; ℓ = 1 … L y = L N ( z L 0 ) \begin{align} z_0 =&[\mathbf{x}_\text{class};\mathbf{x}_p^1\mathbf{E};\mathbf{x}_p^2\mathbf{E};\cdots;\mathbf{x}_p^N\mathbf{E}]+\mathbf{E}_{pos}; \ \ \ \mathbf{E}\in\mathbb{R}^{(P^{2}\cdot C)\times D}, \mathbf{E}_{pos}\in\mathbb{R}^{(N+1)\times D}\\ \mathbf{z}^{\prime}{}_{\ell} =& \mathrm{MSA(LN(z_{\ell-1}))+z_{\ell-1}};\ \ \ell=1\ldots L \\ \mathbf{z}_{\ell} = &\mathrm{MLP}(\mathrm{LN}(\mathbf{z^{\prime}}_\ell))+\mathbf{z^{\prime}}_\ell; \ \ \ \ell=1\ldots L \\ y =& \mathrm{LN}(\mathbf{z}_{L}^{0}) \end{align} z0=z′ℓ=zℓ=y=[xclass;xp1E;xp2E;⋯;xpNE]+Epos; E∈R(P2⋅C)×D,Epos∈R(N+1)×DMSA(LN(zℓ−1))+zℓ−1; ℓ=1…LMLP(LN(z′ℓ))+z′ℓ; ℓ=1…LLN(zL0)
其中 E E E 是patch维度转换矩阵, M S A MSA MSA是多头注意力层(multi-head self attention), L N LN LN是layer normalization 层, M L P MLP MLP是transformer中前馈网络层
另外,也可以使用CNN网络的特征图作为输入序列,在这种混合模型中,patch embeding 投影层将被用于改变CNN特征图的形状。
在微调阶段,将移除预训练的prediction layer,并新增一个零初始化的预测层,一般来说,在更高分辨率图像上微调是非常有益的。在喂入更高分辨率图像时,保持patch的尺寸不变,这样会造成输入序列长度增加,虽然ViT模型可以处理任意长的输入序列(直到内存不够),但是预训练的位置编码将无效,因此作者根据当前位置在原始图片中的位置,对预训练的位置编码采用2D插值的方法获取最新的位置编码
3. 实验
下文中将用一些简写来代表模型的尺寸和输入patch的尺寸,如ViT-L/16 代表模型为ViT-Large,输入patch的尺寸为 16 × 16 16 \times 16 16×16,下表展示了不同尺寸模型的配置及参数量
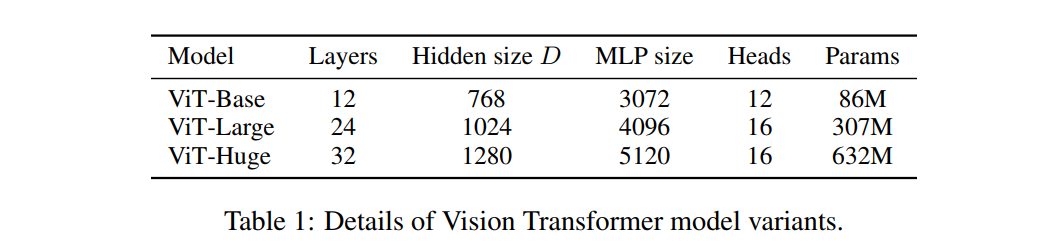
这里需要注意,由于输入序列长度与patch的尺寸成反比,所以,patch 尺寸越小,反而计算量越大
3.1 Compare with SOTA
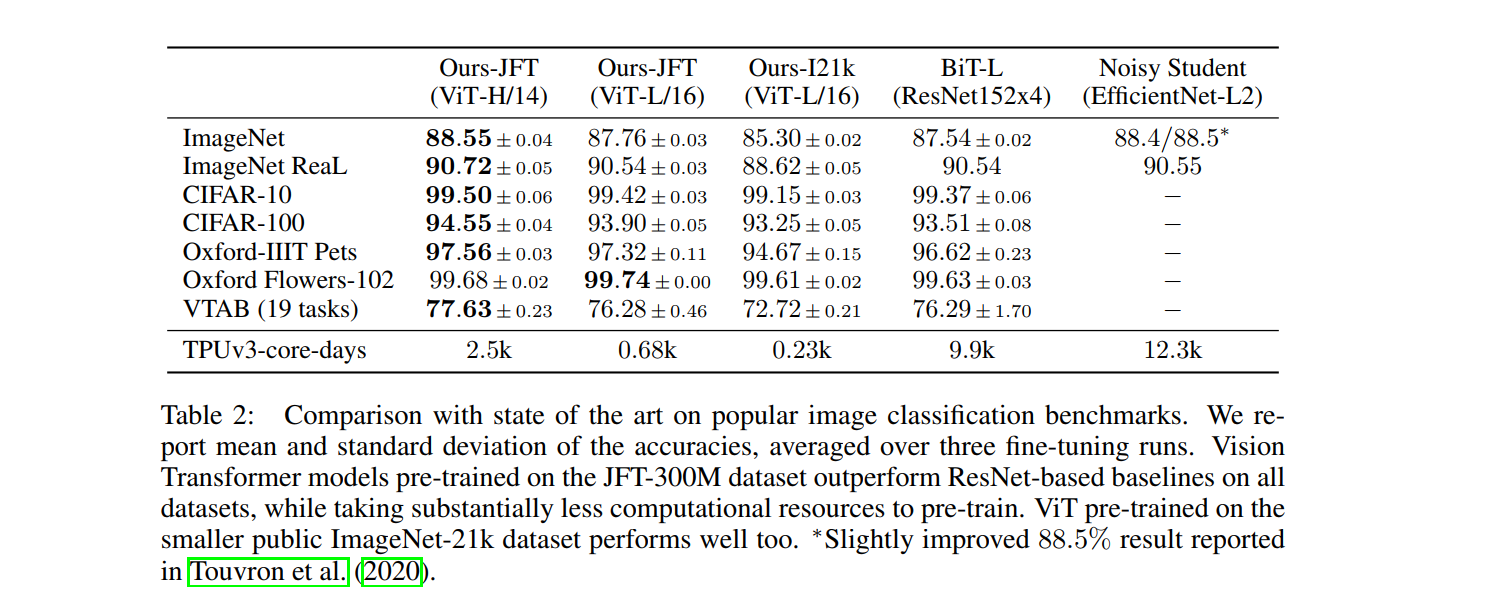
TPU v3-core-days:代表计算量,All models were trained on TPUv3 hardware, and we
report the number of TPUv3-core-days taken to pre-train each of them, that is, the number of TPU
v3 cores (2 per chip) used for training multiplied by the training time in days
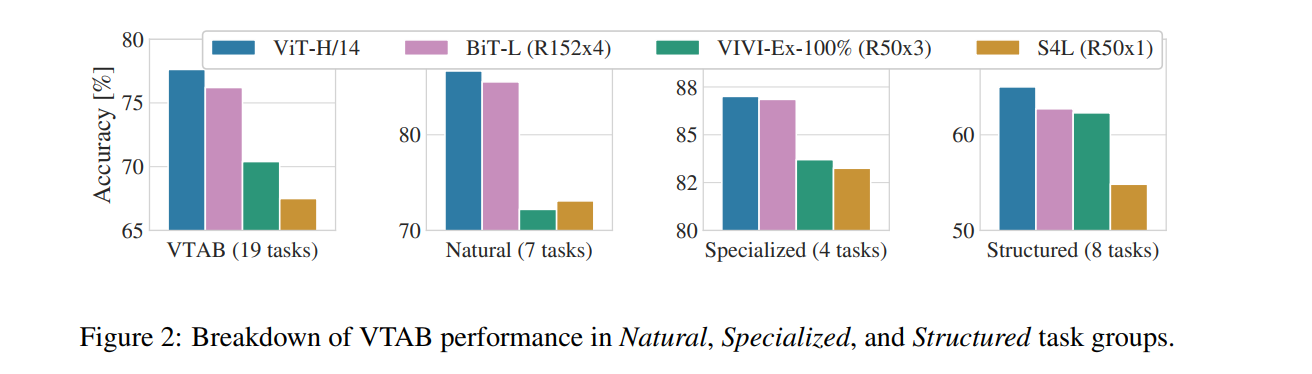
不同模型简介:
- Big Transfer (BiT), which performs supervised transfer learning with large ResNets
- VIVI – a ResNet co-trained on ImageNet and Youtube
- S4L – supervised plus semi-supervised learning on ImageNet
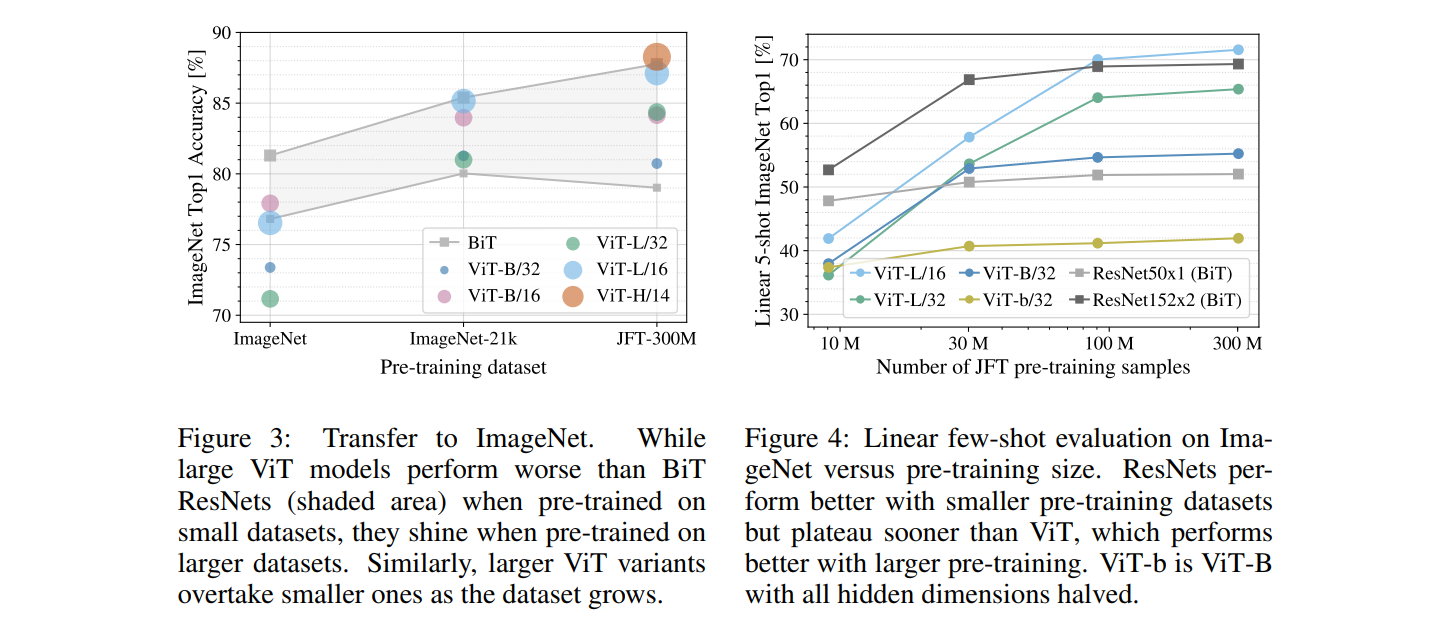
3.2 PRE-TRAINING DATA REQUIREMENTS
作者经过实验得到如下结论:
- 在小数据集上预训练,ViT-Large比ViT-Base要差,在大数据集上训练对ViT-Large比较有益
- 在小数据集上预训练,ViT的效果比CNN还要差,在大数据集上预训练ViT的效果超过CNN
- CNN网络的归纳有偏性在小数据集上是有用的,但是在大数据集上,直接从数据中学习相关的模式更有效
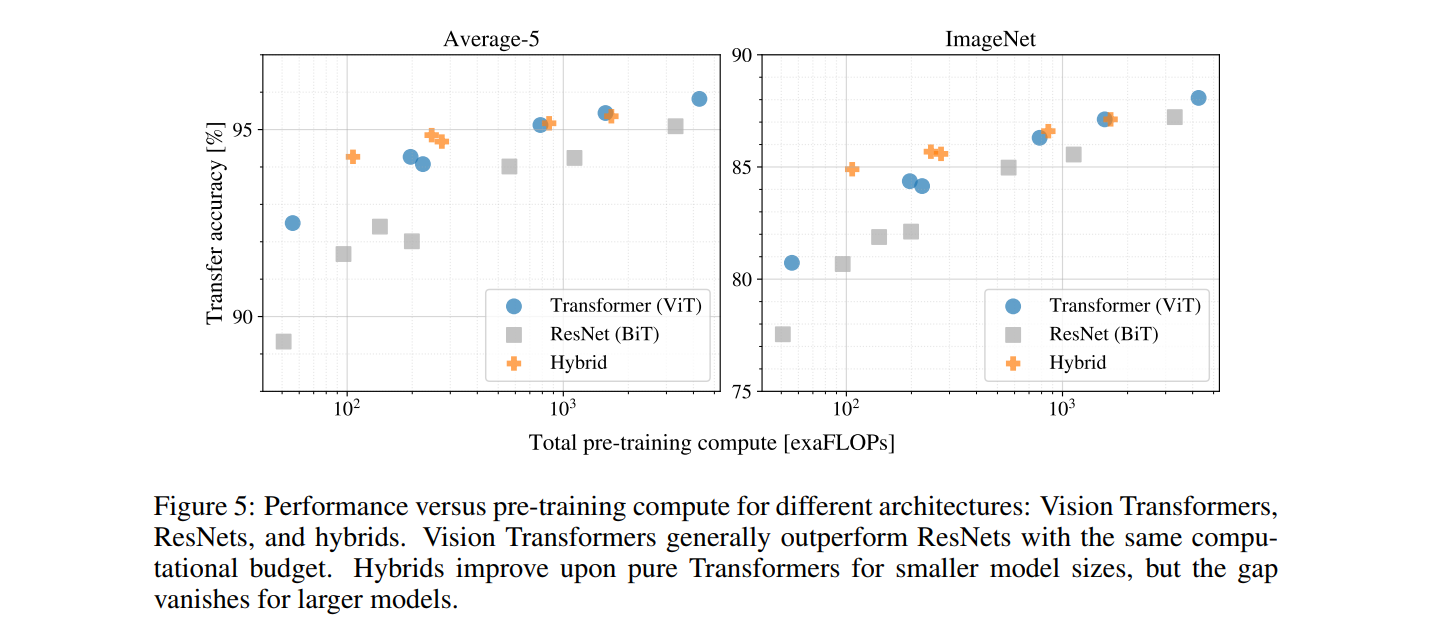
3.3 SCALING STUDY
如下图所示,作者得到如下结论:
- ViT在效果和计算量平衡之间相比ResNet占绝对优势,ResNet需要使用约3倍的算力来获得与ViT相似的结果
- 混合模型在小计算量上相比ViT具有一定的优势,但是这种优势在大模型(大计算量)上逐渐消失
- ViT在当前实验中貌似并没有饱和,这激励着未来的研究
3.4 自监督学习
作者模仿BERT通过mask patch prediction任务进行自监督预训练,ViT-B/16在ImageNet上获得了79.9%的准确率,相比从随机初始化开始训练提升了2%,但是相比于监督学习仍然落后4%。
4. 总结
作者将图片看作是patch序列,并使用标准的Transformer对patch序列进行处理,最终在大数据集上预训练取得了很不错的效果,在图片分类任务上超过了很多SOTA模型。但也还存在一些挑战等待后期处理:
- 将ViT应用在其他计算机视觉任务中,如目标检测、语义分割等
- 还需进一步探索自监督预训练方法
- 进一步扩大ViT模型的规模,可能会取得更好的效果
参考
如何理解Inductive bias?
Translation Equivariance
CNN中的Translation Equivariance【理解】
2D插值(2D interpolation)