基于Prometheus和K8S构建智能化告警系统
- 一、Prometheus简介
- 二、Prometheus特点于样本
- 2.1、特点
- 2.2、样本
- 三、Prometheus组件介绍
- 四、Prometheus工作流程
- 五、Prometheus的几种部署模式
- 5.1、基本高可用模式
- 5.2、基本高可用+远程存储
- 5.3、基本高可用+远程存储+联邦集群
- 六、Prometheus的四种数据类型
- 6.1、Counter
- 6.2、Gauge
- 6.3、histogram
- 6.4、summary
- 七、Prometheus能监控什么
- 7.1、DATABASES-数据库
- 7.2、HARDWARE RELATED-硬件相关
- 7.3、Messaging systems-消息服务
- 7.4、Storage-存储
- 7.5、http-网站服务
- 7.6、API
- 7.7、Logging-日志
- 7.8、Other monitoring systems
- 7.9、Miscellaneous-其他
- 7.10、Software exposing Prometheus metrics-Prometheus度量指标
一、Prometheus简介
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
Prometheus配置:https://prometheus.io/docs/prometheus/latest/configuration/configuration/
Prometheus监控组件对应的exporter部署地址:
https://prometheus.io/docs/instrumenting/exporters/
Prometheus基于k8s服务发现参考:
https://github.com/prometheus/prometheus/blob/release-2.31/documentation/examples/prometheus-kubernetes.yml
二、Prometheus特点于样本
2.1、特点
- 1.多维度数据模型
每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定:
这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。 - 2.灵活的查询语言(PromQL)
可以对采集的metrics指标进行加法,乘法,连接等操作; - 3.可以直接在本地部署,不依赖其他分布式存储;
- 4.通过基于HTTP的pull方式采集时序数据;
- 5.可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
- 6.可通过服务发现或者静态配置来发现目标服务对象(targets)。
- 7.有多种可视化图像界面,如Grafana等。
- 8.高效的存储
每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。 - 9.做高可用
- 可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
2.2、样本
在时间序列中的每一个点称为一个样本(sample),样本由一下三部分组成:
-
指标(metric)
指标名称和描述当前样本特征的labelsets -
时间戳(timestamp)
-
样本值(value)
三、Prometheus组件介绍
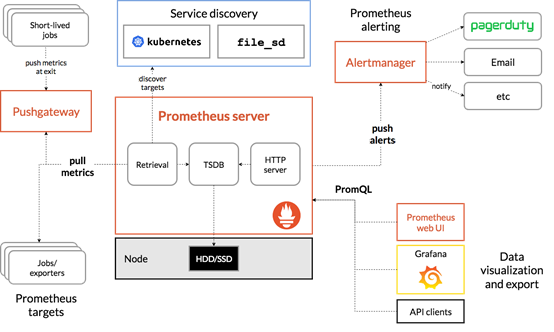
- Prometheus Server
用于收集和存储时间序列数据。 - Client Library
客户端库,检测应用程序代码。当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server 端。 - Exporters
prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到server算,所有向server提供监控数据的程序都可以被称为exporter。 - Alertmanager
从Prometheus server端接收alerts后,会进行去重、分组,并路由到对应的接收方,发出报警,常见的接收方式有:电子邮件、微信、钉钉、slack等。 - Grafana
监控仪表板,可视化监控数据。 - pushgateway
各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
四、Prometheus工作流程
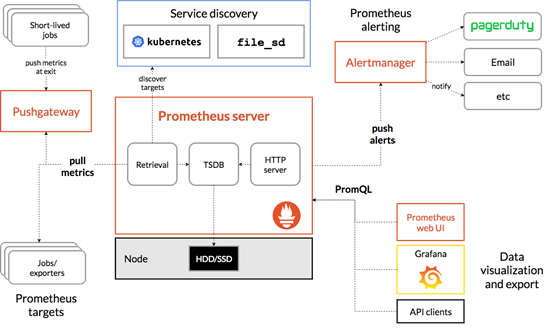
1、Prometheus server可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;
也可以通过pushgateway把采集的数据上报的prometheus server中;
还可以通过一些组件自带的exporter采集相应组件的数据。
2、Prometheus server 把采集到的监控指标数据保存到本地磁盘或者数据库;
3、Prometheus 采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
4、Altermanager通过配置报警接收方,发送报警到邮件、微信或者钉钉等
5、Prometheus自带的web ui界面提供PromQL查询语言,可查询监控数据
6、Grafana可接入prometheus数据源,把监控数据以图形化形式展示出来
Prometheus和Zabbix对比分析

五、Prometheus的几种部署模式
5.1、基本高可用模式
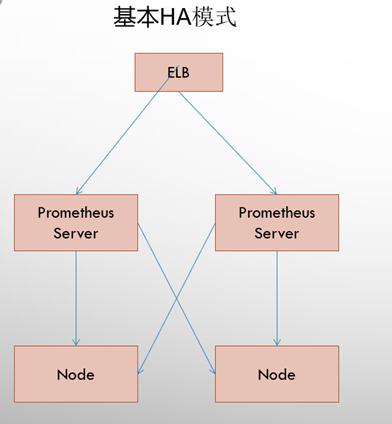
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
5.2、基本高可用+远程存储
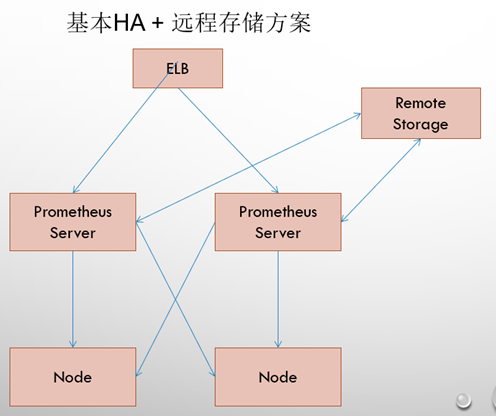
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
5.3、基本高可用+远程存储+联邦集群
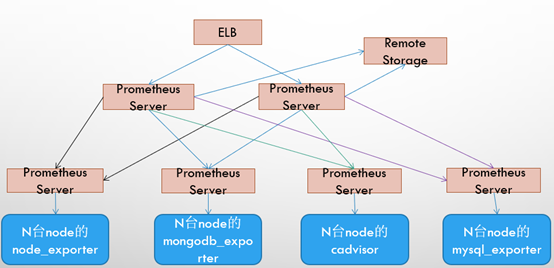
Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
六、Prometheus的四种数据类型
6.1、Counter
Counter是计数器类型:
- Counter用于累计值,例如记录请求次数、任务完成数、错误发生次数
- 一直增加,不会减少
- 重启进程后,会被重置
例如:
http_response_total{method="GET",endpoint="/api/tracks"} 100
http_response_total{method="GET",endpoint="/api/tracks"} 160
Counter数据类型可以让用户方便的了解事件产生的速率变化,在PromQL内置的相关操作函数可以提供相应的分析,比如以HTTP应用请求量来说明:
1、通过rate()函数获取HTTP请求量的增长率 rate(http_requests_total[5m])
2、查询当前系统中,访问量前10的http地址 top(10,http_requeste_total)
6.2、Gauge
Gauge是测量器类型:
- Gauge是常规数据,例如温度变化、内存使用变化
- 可变大、可变小
- 重启进程后,会被重置
例如:
memory_usage_bytes{host="master-01"} 100
memory_usage_bytes{host="master-01"} 30
memory_usage_bytes{host="master-01"} 50
memory_usage_bytes{host="master-01"} 80
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异:
dalta(cpu_temp_celsius{host=“zeus”}[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:
predict_linear(node_filesystem_free{job=“node”}[2h], 4 * 3600) < 0
6.3、histogram
histogram是柱状图,在Prometheus系统的查询语言中,有三种作用:
- 在一段时间时间内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本中总数,最后一般将数据展示为直方图。
- 对每个采样点值累计和(sum)
- 对采样点的次数累计和(count)
度量指标名称: [basename]_上面三类的作用度量指标名称
1、[basename]_bucket{le=“上边界”}, 这个值为小于等于上边界的所有采样点数量
2、[basename]_sum
3、[basename]_count
小结:如果定义一个度量类型为Histogram,则Prometheus会自动生成三个对应的指标
为什么需要柱状图?
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram 类型的样本会提供三种指标(假设指标名称为 ):
样本的值分布在 bucket 中的数量,命名为 _bucket{le=“<上边界>”}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
1、http 请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0
2、http 请求响应时间 <=0.01 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.03、http 请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0
所有样本值的大小总和,命名为 <basename>_sum。
6.4、summary
与histogram类型类似,用于表示一段时间内的数据采集结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
它也有三种作用:
- 对于每个采样点进行统计,并形成分位图。
- 统计班上所有同学的总成绩(sum)
- 统计班上同学的考试总人数(count)
带有度量指标的[basename]的summary 在抓取时间序列数据有如命名。
1、观察时间的φ-quantiles (0 ≤ φ ≤ 1), 显示为[basename]{分位数=“[φ]”}
2、[basename]_sum, 是指所有观察值的总和
3、[basename]_count, 是指已观察到的事件计数值
样本值的分位数分布情况,命名为 <basename>{quantile="<φ>"}。
1、含义: http 请求中有 50% 的请求响应时间是 3.052404983sio_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.5",} 3.052404983
2、含义: http 请求中有 90% 的请求响应时间是 8.003261666sio_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.9",} 8.003261666所有样本值的大小总和,命名为 <basename>_sum。
1、含义:http 请求的总响应时间为 51.029495508sio_namespace_http_requests_latency_seconds_summary_sum{path="/",method="GET",code="200",} 51.029495508样本总数,命名为 <basename>_count。
1、含义:当前一共发生了 12 次 http 请求io_namespace_http_requests_latency_seconds_summary_count{path="/",method="GET",code="200",} 12.0
Histogram 与 Summary 的异同:
它们都包含了 _sum 和 _count 指标
Histogram 需要通过 _bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
prometheus_tsdb_wal_fsync_duration_seconds{quantile=“0.5”} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile=“0.9”} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile=“0.99”} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Promtheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
七、Prometheus能监控什么
- Databases
- Hardware related
- Messaging systems
- Storage
- HTTP
- APIs
- Logging
- Other monitoring systems
- Miscellaneous
- Software exposing Prometheus metrics
7.1、DATABASES-数据库
• Aerospike exporter
• ClickHouse exporter
• Consul exporter (official)
• Couchbase exporter
• CouchDB exporter
• ElasticSearch exporter
• EventStore exporter
• Memcached exporter (official)
• MongoDB exporter
• MSSQL server exporter
• MySQL server exporter (official)
• OpenTSDB Exporter
• Oracle DB Exporter
• PgBouncer exporter
• PostgreSQL exporter
• ProxySQL exporter
• RavenDB exporter
• Redis exporter
• RethinkDB exporter
• SQL exporter
• Tarantool metric library
• Twemproxy
7.2、HARDWARE RELATED-硬件相关
• apcupsd exporter
• Collins exporter
• IBM Z HMC exporter
• IoT Edison exporter
• IPMI exporter
• knxd exporter
• Netgear Cable Modem Exporter
• Node/system metrics exporter (official)
• NVIDIA GPU exporter
• ProSAFE exporter
• Ubiquiti UniFi exporter
7.3、Messaging systems-消息服务
• Beanstalkd exporter
• Gearman exporter
• Kafka exporter
• NATS exporter
• NSQ exporter
• Mirth Connect exporter
• MQTT blackbox exporter
• RabbitMQ exporter
• RabbitMQ Management Plugin exporter
7.4、Storage-存储
• Ceph exporter
• Ceph RADOSGW exporter
• Gluster exporter
• Hadoop HDFS FSImage exporter
• Lustre exporter
• ScaleIO exporter
7.5、http-网站服务
• Apache exporter
• HAProxy exporter (official)
• Nginx metric library
• Nginx VTS exporter
• Passenger exporter
• Squid exporter
• Tinyproxy exporter
• Varnish exporter
• WebDriver exporter
7.6、API
• AWS ECS exporter
• AWS Health exporter
• AWS SQS exporter
• Cloudflare exporter
• DigitalOcean exporter
• Docker Cloud exporter
• Docker Hub exporter
• GitHub exporter
• InstaClustr exporter
• Mozilla Observatory exporter
• OpenWeatherMap exporter
• Pagespeed exporter
• Rancher exporter
• Speedtest exporter
7.7、Logging-日志
• Fluentd exporter
• Google’s mtail log data extractor
• Grok exporter
7.8、Other monitoring systems
• Akamai Cloudmonitor exporter
• Alibaba Cloudmonitor exporter
• AWS CloudWatch exporter (official)
• Cloud Foundry Firehose exporter
• Collectd exporter (official)
• Google Stackdriver exporter
• Graphite exporter (official)
• Heka dashboard exporter
• Heka exporter
• InfluxDB exporter (official)
• JavaMelody exporter
• JMX exporter (official)
• Munin exporter
• Nagios / Naemon exporter
• New Relic exporter
• NRPE exporter
• Osquery exporter
• OTC CloudEye exporter
• Pingdom exporter
• scollector exporter
• Sensu exporter
• SNMP exporter (official)
• StatsD exporter (official)
7.9、Miscellaneous-其他
• ACT Fibernet Exporter
• Bamboo exporter
• BIG-IP exporter
• BIND exporter
• Bitbucket exporter
• Blackbox exporter (official)
• BOSH exporter
• cAdvisor
• Cachet exporter
• ccache exporter
• Confluence exporter
• Dovecot exporter
• eBPF exporter
• Ethereum Client exporter
• Jenkins exporter
• JIRA exporter
• Kannel exporter
• Kemp LoadBalancer exporter
• Kibana Exporter
• Meteor JS web framework exporter
• Minecraft exporter module
• PHP-FPM exporter
• PowerDNS exporter
• Presto exporter
• Process exporter
• rTorrent exporter
• SABnzbd exporter
• Script exporter
• Shield exporter
• SMTP/Maildir MDA blackbox prober
• SoftEther exporter
• Transmission exporter
• Unbound exporter
• Xen exporter
7.10、Software exposing Prometheus metrics-Prometheus度量指标
• App Connect Enterprise
• Ballerina
• Ceph
• Collectd
• Concourse
• CRG Roller Derby Scoreboard (direct)
• Docker Daemon
• Doorman (direct)
• Etcd (direct)
• Flink
• FreeBSD Kernel
• Grafana
• JavaMelody
• Kubernetes (direct)
• Linkerd