Google在2023年12月官宣了Gemini模型,随后2024年2月9日才宣布Gemini 1.0 Ultra正式对公众服务,并且开始收费。现在2024年2月14日就宣布了Gemini 1.5 Pro,史诗级多模态最强MoE首破100万极限上下文纪录!!!Gemini 1.5 Pro在数学、科学和推理方面的表现比Gemini 1.0 Ultra提高了28.9%,在多语言方面提高了22.3%,在编码方面提高了8.9%。此外,在视频理解和音频方面也取得了显著进步。不得不说这技术迭代速度已经有点量级了,让我仍不住想要扒一扒Gemini的爆火路径!

一.简介
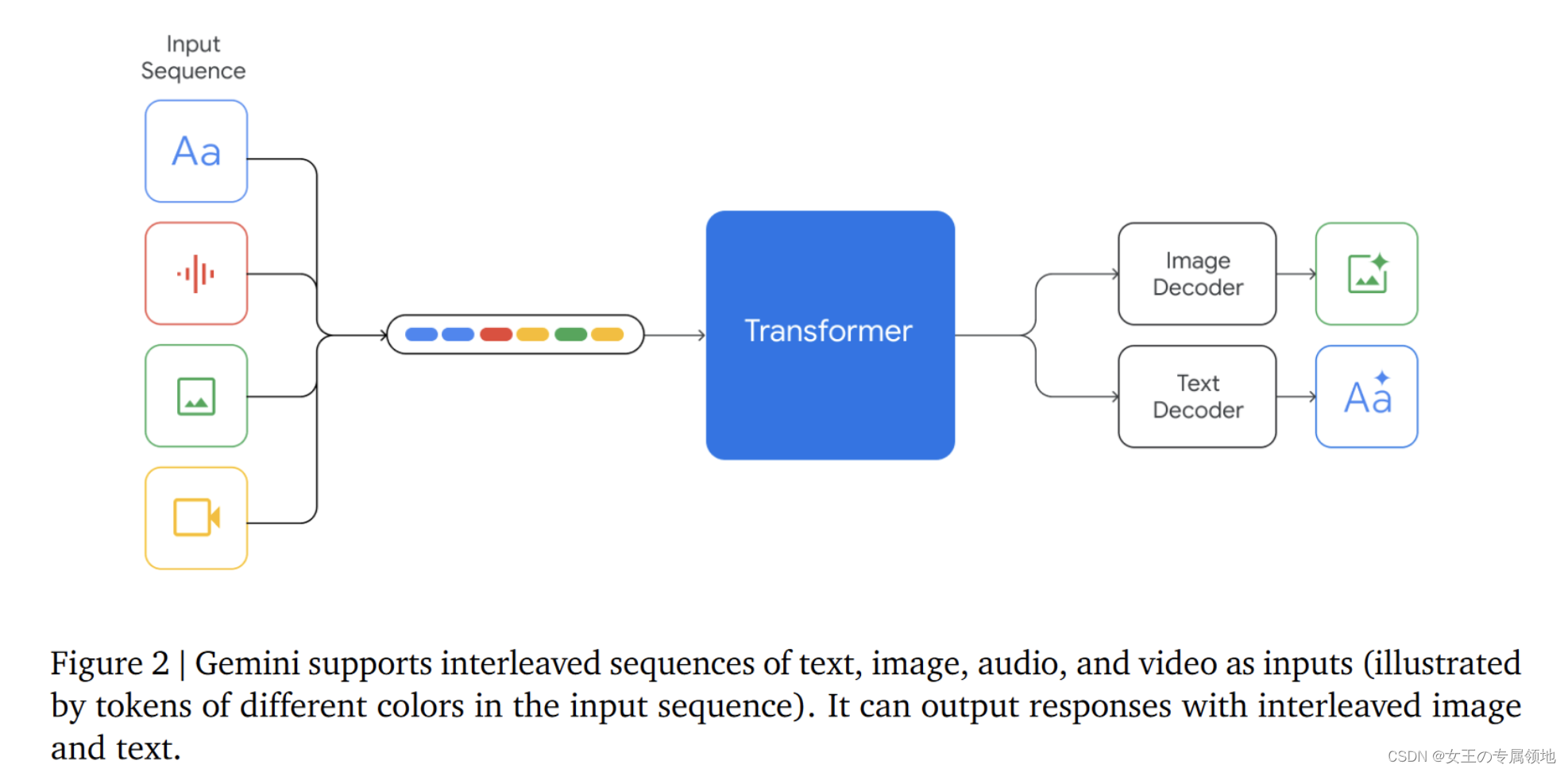
23年12月7日凌晨,Google DeepMind发布Gemini1.0,谷歌将其称为其史上最强大、最通用的模型。该模型作为从头开始构建的多模态,这意味着它可以概括和无缝地理解、操作和组合不同类型的信息,包括文本、代码、音频、图像和视频。Gemini 1.0针对不同的尺寸进行了优化:Ultra、Pro 和 Nano,能够在从数据中心到移动设备的所有设备上高效运行。同时该原生多模态模型通过对不同模态预训练和额外微调等技术,使其在32个广泛使用的学术基准中的30个方面,其性能超过了当前最先进的结果。Gemini Ultra是第一个在MMLU上实现人类专家性能的模型得分超过90%。
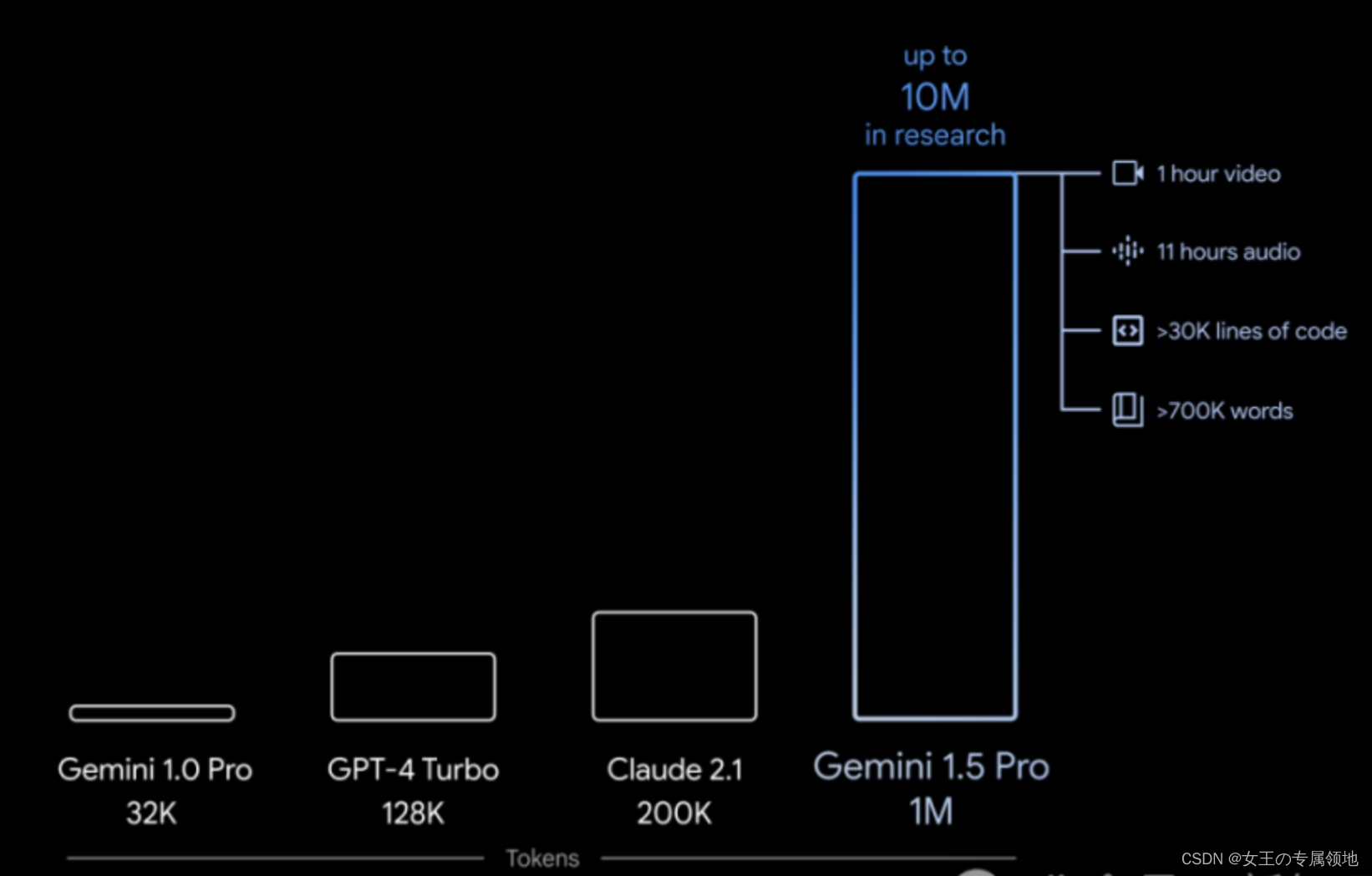
最近也就是2024年2月份,谷歌又在深夜发炸弹,Gemini Ultra发布还没几天,Gemini 1.5就来了。就在刚刚,谷歌DeepMind首席科学家Jeff Dean,以及联创兼CEO的Demis Hassabis宣布了最新一代多模态大模型Gemini 1.5系列的诞生。其中,最高可支持10,000K(100万) token超长上下文的Gemini 1.5 Pro,也是谷歌最强的MoE大模型。在上下文窗口方面,此前的SOTA模型已经「卷」到了200K token(20万)。不难想象,在百万级token上下文的加持下,我们可以更加轻易地与数十万字的超长文档、拥有数百个文件的数十万行代码库、一部完整的电影等等进行交互。
网址:https://deepmind.google/
二、Gemini 模型族概述

Gemini 1.0
官网介绍:https://blog.google/technology/ai/google-gemini-ai/#sundar-note
-
Gemini Ultra:
- 规模:Gemini Ultra是最大规模的模型,提供了最高级别的处理能力和复杂性。
- 应用场景:它适用于高度复杂的任务,如高级推理、深度学习分析和大规模数据集的处理。在需要进行深入的多模态分析和理解的领域,如先进的研究和开发、复杂的自然语言处理和图像理解任务中,Ultra模型展现了显著的优势 。
-
Gemini Pro:
- 规模:Gemini Pro是中等规模的模型,提供了强大的性能和较高的部署灵活性。
- 应用场景:Pro模型适用于需要较高性能但又要求较好可扩展性和部署效率的应用。包括企业级应用、中等规模的数据处理任务和那些需要在资源有限的环境中进行高效处理的场景。例如,在商业智能、中等规模的自然语言处理和多媒体内容分析等方面,Pro模型提供了一个平衡的解决方案 。
-
Gemini Nano:
- 规模:Gemini Nano是最小规模的模型,专为资源受限的环境设计。
- 应用场景:Nano模型特别适合于那些需要在设备上直接运行的应用,如智能手机、嵌入式系统和其他内存受限的设备。它在处理如摘要、阅读理解、文本完成任务等方面表现出色,同时在STEM、编码、多模态和多语言任务上也展示了强大的能力,相对于其大小来说,这是非常显著的性能表现 。
Gemini 1.5 Pro
官网介绍:https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/#sundar-note
Gemini 1.5的设计,基于的是谷歌在Transformer和混合专家(MoE)架构方面的前沿研究。不同于传统的作为一个庞大的神经网络运行的Transformer,MoE模型由众多小型的「专家」神经网络组成。这些模型可以根据不同的输入类型,学会仅激活最相关的专家网络路径。这样的专门化,就使得模型效率大幅提升。而谷歌通过Sparsely-Gated MoE、GShard-Transformer、Switch-Transformer、M4研究,早已成为深度学习领域中MoE技术的领航者。Gemini 1.5的架构创新带来的,不仅仅是更迅速地掌握复杂任务、保持高质量输出,在训练和部署上也变得更加高效。因此,团队才能以惊人的速度,不断迭代和推出更先进的Gemini版本。性能比肩Ultra,大幅超越1.0 Pro在涵盖文本、代码、图像、音频和视频的综合性测试中,1.5 Pro在87%的基准测试上超越了1.0 Pro。
提升结果
- 对于文本处理,Gemini 1.5 Pro在处理高达530,000 token的文本时,能够实现100%的检索完整性,在处理1,000,000 token的文本时达到99.7%的检索完整性。甚至在处理高达10,000,000 token的文本时,检索准确性仍然高达99.2%。
- 在音频处理方面,Gemini 1.5 Pro能够在大约11小时的音频资料中,100%成功检索到各种隐藏的音频片段。
- 在视频处理方面,Gemini 1.5 Pro能够在大约3小时的视频内容中,100%成功检索到各种隐藏的视觉元素。
提升方面
- 深入理解海量信息:Gemini 1.5 Pro已经可以轻松地分析给定提示中的海量内容!能够洞察文档中的对话、事件和细节,展现出对复杂信息的深刻理解。
- 横跨各种不同媒介:Gemini 1.5 Pro还能够在视频中展现出深度的理解和推理能力!得益于Gemini的多模态能力,上传的视频会被拆分成数千个画面(不包括音频),以便执行复杂的推理和问题解决任务。
- 高效处理更长代码:Gemini 1.5 Pro在处理长达超过100,000行的代码时,还具备极强的问题解决能力。
- 分析和掌握复杂代码库:Gemini 1.5 Pro能够迅速吸收大型代码库,并解答复杂的问题。
- 浏览庞大而陌生的代码库:模型能够帮我们理解代码,或定位某个特定功能的实现位置。
- 长篇复杂文档的推理:模型在分析长篇、复杂的文本文档方面也非常出色,例如雨果的五卷本小说《悲惨世界》(共1382页,含732,000个token)。
- Kalamang语翻译:特别引人注目的例子是关于Kalamang语的翻译(卡拉曼语是新几内亚西部、印度尼西亚巴布亚东部不足200人使用的语言,几乎未在互联网上留下足迹。)Gemini Pro 1.5通过上下文学习掌握了Kalamang语的知识,其翻译质量可与使用相同材料学习的人相媲美。
三、技术架构
基于强大的Mixture-of-Expert(MoE)Transformer模型,Gemini 1.5 Pro汲取了众多研究成果,实现了质量与效率的完美平衡。
四、模型能力
- 多模态和多语言能力:Gemini Ultra在32个基准测试中的30个中取得了最新的最高成绩,这些测试覆盖了文本和推理、图像理解、视频理解、语音识别和语音翻译等多个领域。这表明Gemini Ultra不仅在单一领域表现出色,而且在多个领域中都能展现其优越的性能。
- 人类专家级性能的实现:在MMLU(多模态学习理解)基准测试中,Gemini Ultra是首个实现人类专家级性能的模型,其得分超过90%。MMLU是一个著名的基准测试,通过一系列考试来测试知识和推理能力,Gemini Ultra在此测试中的表现显著超过了之前的最佳模型。
- 挑战性多模态推理任务的进步:在MMM(多模态多学科)基准测试中,Gemini Ultra取得了62.4%的新高分,这是一个涵盖关于图像的跨学科问题的测试,要求解决问题的模型具备大学水平的主题知识和深入的推理能力。Gemini Ultra在此测试中的表现比之前最佳的模型高出超过5个百分点。
- 增强的视频理解能力:Gemini Ultra在视频理解基准测试中的表现也非常突出,这体现了它在理解和处理视觉信息方面的高级能力。它能够有效地处理和解析视频内容,为视频内容分析和理解提供了新的可能性。这些突破性成就不仅证明了Gemini Ultra在多模态人工智能领域的领先地位,也展示了它在理解和处理复杂数据方面的强大能力。这对于推动人工智能技术的发展和应用具有重要意义。
五、实际应用前景
Gemini模型在多领域多模态测试基准上的优秀表现,以及其在文本、图片和语音交互形式方面的能力,共同预示了其在多个行业中的广泛应用潜力。这些应用不仅限于提高现有技术和服务的效率和质量,还包括开拓全新的应用领域。以下是一些具体的应用前景:
- 个性化教育和培训:Gemini模型能够分析学生提供的文本、语音反馈和图像,从而提供个性化的学习体验和材料,适用于在线教育和培训平台。
- 健康医疗:在医疗领域,Gemini模型可以分析患者的语音描述、书面病历和医学图像,辅助医生做出更准确的诊断和治疗决策。
- 客户服务和支持:应用于客户服务,Gemini模型可以通过分析客户的语音、文本咨询和相关图片,提供更准确和个性化的服务和支持。
- 自动驾驶汽车:在自动驾驶汽车领域,模型可以结合路面图像、交通标志的文本信息和司机的语音指令,以提高决策的安全性和准确性。
- 内容创作和媒体编辑:在媒体和娱乐行业,Gemini模型可以用于自动生成或编辑包含文本、图像和语音的多媒体内容,如新闻报道、广告和社交媒体内容。
- 商业智能:在商业领域,模型可以分析市场报告、消费者反馈(包括文本和语音)和图像数据,提供市场洞察和决策支持。
- 多语言翻译和全球化服务:Gemini模型的多语言能力使其在跨文化交流和全球化业务扩展中发挥重要作用,特别是在跨语言的文本、图像和语音翻译方面。
六、总结
总的来说Gemini模型能在多基准上取得如此优秀的成绩让我们对以下方面有了新的思考:
- 多模态融合的重要性:Gemini模型的成功凸显了多模态融合在未来人工智能发展中的重要性。这种整合视觉、文本、语音和视频等不同数据形式的能力,不仅增强了模型对复杂世界的理解,还为AI在更广泛领域的应用开辟了新路径。
- 模型可扩展性和灵活性:Gemini模型族中包含不同大小和用途的模型,显示出在设计和实施AI解决方案时的可扩展性和灵活性。这种多样化的模型设计能够满足不同的应用需求,从而使AI技术更加普及和实用。
- AI技术的全球化应用:Gemini模型在多语言任务上的表现强调了AI技术在全球化应用中的重要性。这种能够跨越语言障碍的能力,为AI技术在全球范围内的推广和应用提供了强有力的支持。
- 大规模AI训练的优化:Gemini模型的训练方法体现了大规模AI模型训练过程中的创新和优化。高效的训练方法不仅提高了模型性能,也降低了计算资源的需求,这对于可持续发展的AI技术具有重要意义。
- 人工智能的伦理和安全问题:随着AI模型变得越来越复杂和强大,其在伦理和安全方面的考量也变得更加重要。Gemini模型在数据过滤和安全方面的措施突显了在设计和部署先进AI系统时对这些问题的关注。
总体来说,Gemini模型族的技术突破不仅是技术层面的成就,更是对未来人工智能发展趋势和方向的一种预示。它体现了AI技术向更加高效、灵活、全球化和伦理负责的方向发展的趋势。
谷歌的新 Gemini 模型似乎是迄今为止最大、最先进的 AI 模型之一。与当前驱动AI聊天机器人的其他流行模型相比,Gemini 因其原生的多模态特性而脱颖而出,而其他模型(如 GPT-4)则依靠插件和集成来实现真正的多模态。与主要基于文本的模型 GPT-4 相比,Gemini 可以轻松地在本机执行多模态任务。虽然 GPT-4 在内容创建和复杂文本分析等与语言相关的任务中表现出色,但它求助于 OpenAI 的插件来执行图像分析和访问网络,并依靠 DALL-E 3 和 Whisper 来生成图像和处理音频。
不过这里补充一下,Gemini 在发布时,谷歌给出的一系列 Demo 中最令人眼花缭乱的部分是伪造的。也就是说脚踏实地来说的话,肯定是GPT更接近现实,更接近实用.
但是Gemini 1.5的诞生,意味着性能的阶段飞跃,标志着谷歌在研究和工程创新上,又迈出了登月般的一步。接下来能跟Gemini 1.5硬刚的,大概就是GPT-5了。
参考资料
Gemini 1.0技术报告:https://zhuanlan.zhihu.com/p/671260501
Gemini 1.5技术报告:https://storage.googleapis.com/
Gemini 1.0 论文:https://arxiv.org/abs/2312.11805