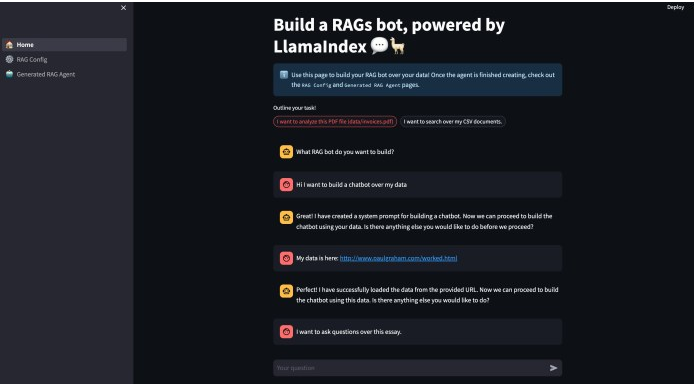
微软的论文
Query2doc: Query Expansion with Large Language Models
https://arxiv.org/pdf/2303.07678.pdf
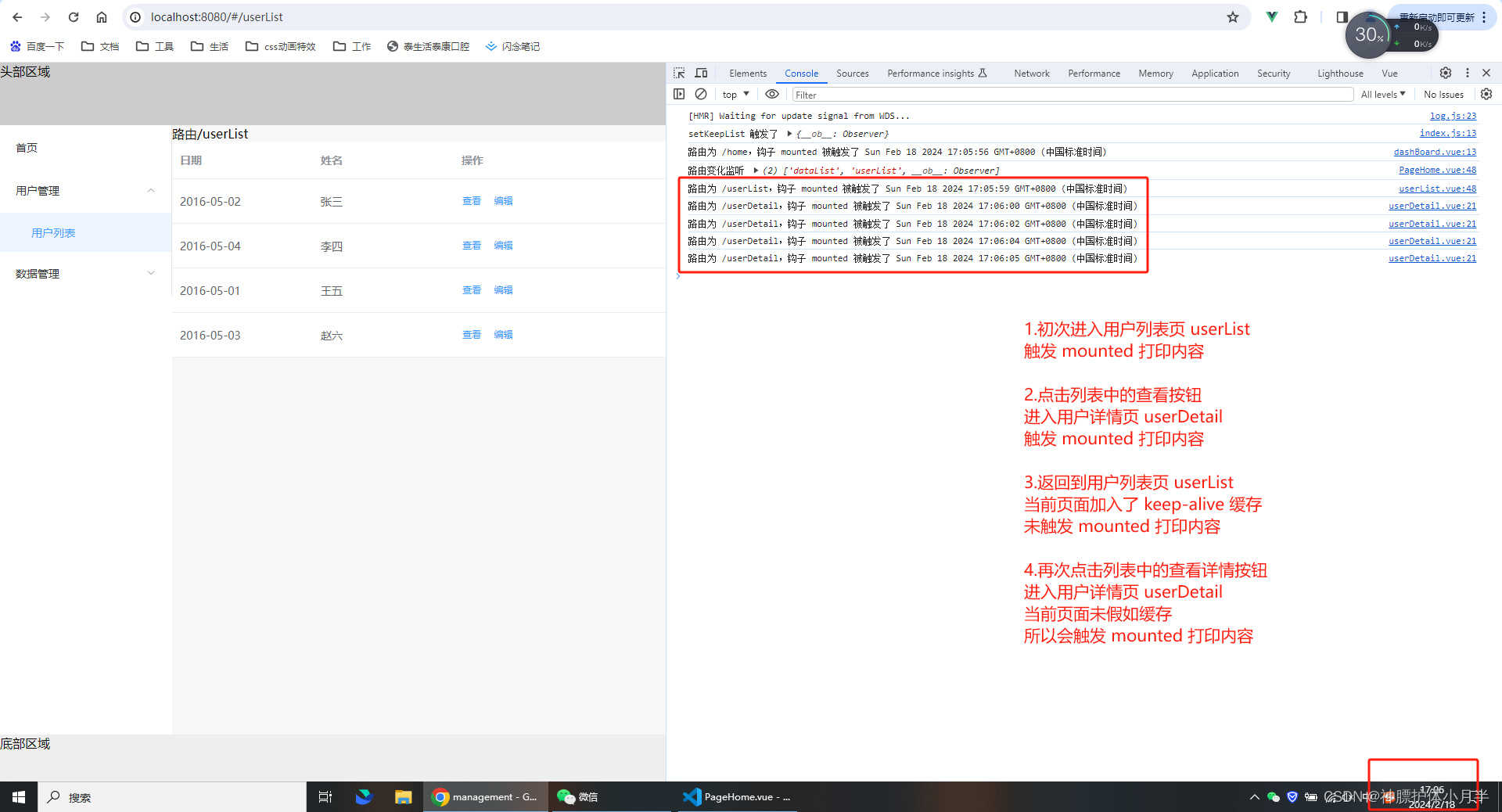
一、生成假设性答案
通过LLM生成query对应的答案。然后将把答案和原始query拼接成新的query,用于检索。例如:

二、如何把答案和原始query进行拼接
分为两种情况
像BM25的稀疏检索,公式为:

其中q+代表最终的query, q代表原始query, 代表由模型生成的答案。由于通常原始query比成成的答案要短很多,为了减少生成的答案的关键词的影响,所以对原始query ×n ,这里是就是重复拼接n次,在论文中认为n为5是一个不错的取值。最后在拼接上生成的答案d。
如果是稀疏向量,则公式为:

最终的query = 原始query + [SEP] + 有模型生成的答案。
三、召回率提升效果如何
根据论文给出的测试结果,对比BM25检索,在不对模型进行微调的情况下,提升了15%左右。
但是对于向量模型的召回提升效果不是很明显。3%以内。

四、模型对召回的影响
根据论文中的数据显示,模型参数规模越大。效果越好!

五、关于如何选择检索模式
根据论文中的数据显示,只使用原始query、只使用生成的伪文档、同时使用query+伪文档三种方式的召回表现,实验结论表明:两者结合>单query>伪文档。这说明生成的伪文档本身有一定的准确率上限,在带来信息增益的同时也引入了额外的噪声,所以只使用伪文档的效果并没有优于原始query。

五、结论
论文中提到的query扩展方法。在不考虑上请求下文的 情况下,有用。