拓展阅读
sensitive-word-admin v1.3.0 发布 如何支持分布式部署?
sensitive-word-admin 敏感词控台 v1.2.0 版本开源
sensitive-word 基于 DFA 算法实现的高性能敏感词工具介绍
更多技术交流

业务背景
如果我们的敏感词部署之后,不会变化,那么其实不用考虑这个问题。
但是实际业务,敏感词总是随着时间不断变化的,所以我们需要支持敏感词的动态修改。
整体设计
pull vs push
以数据库存储自定义场景为例,如果页面修改了敏感词信息,那么如何通知到部署的多台敏感词客户端呢?
一般通知方式有两大类:
1)push 推送方式
修改时同时通知敏感词发生了变化,每个敏感词客户端接收到通知后,重新初始化敏感词信息。
优点是实时性比较高,缺点是需要引入额外的通知机制,需要通知的服务比较多时,也比较麻烦。

2)pull 拉取方式
修改后,直接落库数据库,每一个敏感词客户端自己定时拉取变更的信息。
这种方式有点是非常简单,缺点是存在一定的延迟性。
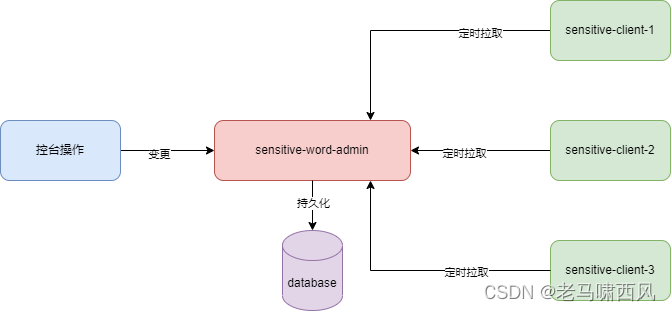
考虑到我们的场景可以允许分钟级的延迟,所以这里先实现定时拉取方式。
如何知道敏感词是否发生了变化?
定时拉取的方式比较简单,但是每一次拉取的话,如何知道是否需要重新初始化呢?
虽然每次的初始化的耗时还好,但是考虑到变更不是很频繁,所以有没有办法定时拉取时知道有没有变化呢?
回顾一下上一篇文章,我们设计的 word 表
create table word
(id int unsigned auto_increment comment '应用自增主键' primary key,word varchar(128) not null comment '单词',type varchar(8) not null comment '类型',status char(1) not null default 'S' comment '状态',remark varchar(64) not null comment '配置描述' default '',operator_id varchar(64) not null default 'system' comment '操作员名称',create_time timestamp default CURRENT_TIMESTAMP not null comment '创建时间戳',update_time timestamp default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间戳'
) comment '敏感词表' ENGINE=Innodb default charset=UTF8 auto_increment=1;
create unique index uk_word on word (word) comment '唯一索引';根据更新时间可以吗?
如果我们所有的数据都不执行物理删除,那么直接根据 word 表的 update_time 即可判断。
但是如果一个数据真的被删除了,那么这种方式就不行了。
delete 的数据怎么办?
如果我们期望执行物理删除的话,那只有添加对应的日志表。
我们可以通过日志表的 update_time 来处理。
操作日志表
v1.2.0 的表设计
回顾一下 v1.2.0 表设计,如下:
create table word_log
(id int unsigned auto_increment comment '应用自增主键' primary key,batch_id varchar(128) not null comment '批次号',word varchar(128) not null comment '单词',type varchar(8) not null comment '类型',status char(1) not null default 'S' comment '单词状态。S:启用;F:禁用',remark varchar(64) not null comment '配置描述' default '',operator_id varchar(64) not null default 'system' comment '操作员名称',create_time timestamp default CURRENT_TIMESTAMP not null comment '创建时间戳',update_time timestamp default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间戳'
) comment '敏感词操作日志表' ENGINE=Innodb default charset=UTF8 auto_increment=1;
create index ix_word on word_log (word) comment '单词普通索引';
create index ix_batch_id on word_log (batch_id) comment '批次号普通索引';枚举:
insert into lc_enum_mapping (table_name, column_name, `key`, label) values ('word_log', 'status', 'S', '正常');
insert into lc_enum_mapping (table_name, column_name, `key`, label) values ('word_log', 'status', 'F', '失效');insert into lc_enum_mapping (table_name, column_name, `key`, label) values ('word_log', 'type', 'ALLOW', '允许');
insert into lc_enum_mapping (table_name, column_name, `key`, label) values ('word_log', 'type', 'DENY', '禁止');表结构调整
我们对原来的表做一点调整。
调整后的建表语句
考虑到后续 sensitive-word 可能做精确的单个单词变化处理,我们最好可以知道每一次词内容的具体变化。
word 敏感词主题 word_before 变更前的单词 word_after 变更后的单词
调整后的建表语句:
drop table word_log;create table word_log
(id int unsigned auto_increment comment '应用自增主键' primary key,batch_id varchar(128) not null comment '批次号',word varchar(128) not null comment '单词',word_before varchar(128) null comment '变更前单词',word_after varchar(128) null comment '变更后单词',type varchar(8) not null comment '类型',status char(1) not null default 'S' comment '单词状态',remark varchar(64) not null comment '配置描述' default '',operator_type varchar(16) not null default '' comment '操作类别',operator_id varchar(64) not null default 'system' comment '操作员名称',create_time timestamp default CURRENT_TIMESTAMP not null comment '创建时间戳',update_time timestamp default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间戳'
) comment '敏感词操作日志表' ENGINE=Innodb default charset=UTF8 auto_increment=1;
create index ix_word on word_log (word) comment '单词普通索引';
create index ix_batch_id on word_log (batch_id) comment '批次号普通索引';
create index ix_update_time on word_log (update_time) comment '更新时间普通索引';添加操作类别(operator_type):
insert into lc_enum_mapping (table_name, column_name, `key`, label) values ('word_log', 'operator_type', 'CREATE', '新增');
insert into lc_enum_mapping (table_name, column_name, `key`, label) values ('word_log', 'operator_type', 'DELETE', '删除');
insert into lc_enum_mapping (table_name, column_name, `key`, label) values ('word_log', 'operator_type', 'UPDATE', '更新');例子
1)新增
新增 '敏感'
word 敏感
word_before null
word_after 敏感2)修改
修改 '敏感',到 '敏感修改'
word 敏感
word_before 敏感
word_after 敏感修改3) 删除
删除 '敏感修改'
word 敏感修改
word_before 敏感修改
word_after null刷新核心逻辑
我们启动一个定时任务,判断存在更新时,则重新初始化对应的敏感词信息。
package com.github.houbb.sensitive.word.admin.web.config;import com.baomidou.mybatisplus.mapper.EntityWrapper;
import com.baomidou.mybatisplus.mapper.Wrapper;
import com.github.houbb.heaven.util.util.DateUtil;
import com.github.houbb.sensitive.word.admin.dal.entity.WordLog;
import com.github.houbb.sensitive.word.admin.service.service.WordLogService;
import com.github.houbb.sensitive.word.bs.SensitiveWordBs;
import groovy.util.logging.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;/*** 分布式部署的更新问题:** 模式1:push* 实时性好,但是需要感知系统的存在。** 模式2:pull* 存在延迟,但是无状态,简单。** 这里采用模式2** @since 1.2.0*/
@Component
@Slf4j
public class MySensitiveWordScheduleRefresh {private static final Logger logger = LoggerFactory.getLogger(MySensitiveWordScheduleRefresh.class);@Autowiredprivate SensitiveWordBs sensitiveWordBs;@Autowiredprivate WordLogService wordLogService;/*** 刷新时间间隔* @since 1.3.0*/@Value("${sensitive-word.refresh-interval-seconds}")private int refreshIntervalSeconds;@PostConstructpublic void init() {logger.info("MySensitiveWordScheduleRefresh init with refreshIntervalSeconds={}", refreshIntervalSeconds);// 单线程定时调度。// TODO: 调整对应的 word_log 实现ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();executorService.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {try {logger.info("MySensitiveWordScheduleRefresh start");refresh();logger.info("MySensitiveWordScheduleRefresh end");} catch (Exception e) {logger.error("MySensitiveWordScheduleRefresh meet ex", e);}}}, refreshIntervalSeconds, refreshIntervalSeconds, TimeUnit.SECONDS);}/*** 更新词库** 每次数据库的信息发生变化之后,首先调用更新数据库敏感词库的方法。* 如果需要生效,则调用这个方法。** 说明:重新初始化不影响旧的方法使用。初始化完成后,会以新的为准。*/private void refresh() {// 延长10S,避免遗漏int timeDiffer = refreshIntervalSeconds + 10;// 判断当前一段时间内是否存在变化?Date date = DateUtil.addSecond(new Date(), -timeDiffer);Wrapper<WordLog> wordLogWrapper = new EntityWrapper<>();wordLogWrapper.gt("update_time", date);int count = wordLogService.selectCount(wordLogWrapper);if(count <= 0) {logger.info("MySensitiveWordScheduleRefresh 没有新增的变化信息,忽略更新。");return;}// 每次数据库的信息发生变化之后,首先调用更新数据库敏感词库的方法,然后调用这个方法。// 后续可以优化为针对变化的初始化。sensitiveWordBs.init();}}sensitive-word.refresh-interval-seconds 属性指定了刷新的间隔,可配置。
小结
分布式环境下还是尽可能的追求架构的简洁性,这里只是一种实现的方式,也可以自己实现基于 push 的模式。
开源代码
sensitive-word-admin v1.3.0
参考资料
https://github.com/houbb/sensitive-word-admin
本文由博客一文多发平台 OpenWrite 发布!