关于Sora的报道,相信很多圈内朋友都已经看到了来自各大媒体铺天盖地的宣传了,这次,对于Sora的宣传,绝不比当初ChatGPT的宣传弱。自OpenAI发布了GPT4之后,就已经有很多视频生成模型了,不过这些模型要么生成的质量堪忧,要么生成的时间太短,比如Gen-2、Pika、Runway、VideoPoet、VideoLDM、Animate Anyone、MagicVideo-V2等视频,很难同时达到高质量生成效果和更长的时长。
Sora之所以出圈,主要有两点,这两点就是之前其他视频生成模型无法解决的痛点,即视频生成的质量和时长。Sora生成的视频呈现出的是大片既视感,无论是镜头变化,还是光影色彩的转变,以及细微到纹理结构的变化,都呈现出了专业摄影师级别的效果;而它生成的视频时长竟然达到了60秒,在此之前,生成最长时长的视频模型VideoPoet也只能生成10秒的时长。这也是为什么当山姆・奥特曼的消息放出后,看到 OpenAI 工程师第一时间展示的 AI 生成视频效果时,人们纷纷表示感叹:好莱坞的时代结束了?
接下来,我们将简单介绍一下Sora的技术实现过程,以及Sora对行业的影响。根据OpenAI的介绍和愿景,Sora不只是一个简单的视频生成工具,而是一个能够改变时代的“世界模型”,Sora的开发工程师表示,Sora通过观察大量数据,可以学会许多关于世界的物理规律,这可以被用来模拟真实世界中的事件发生时的状况,比如智能机器人,自动驾驶等。
比如下面这段提示,“Prompt: Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. The art style is 3D and realistic, with a focus on lighting and texture. The mood of the painting is one of wonder and curiosity, as the monster gazes at the flame with wide eyes and open mouth. Its pose and expression convey a sense of innocence and playfulness, as if it is exploring the world around it for the first time. The use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.”
根据以上提示内容,生成的视频是一个动画场景的特写镜头,一个毛茸茸的小怪物跪在一根正在融化的红蜡烛旁边。视频的主要气氛基调是一种惊奇和好奇,怪物睁大眼睛和张开的嘴盯着火焰。它的姿势和表情传达出一种天真和顽皮的感觉,仿佛它是第一次探索周围的世界。暖色和戏剧性的灯光的使用进一步增强了图像的舒适氛围。

根据上述提示词生成的视频发现Sora确实把握了wonder和 curiosity这两个关键词,小怪物表现出了强烈的好奇心和探索欲,想去触碰到蜡烛但是又害怕的动作和表情一览无余。项目的研究科学家Tim Brooks表示,Sora学会了关于 3D 几何形状和一致性的知识。而且这种知识并非预先设定的,而是它通过观大量数据自然而然地学会的。
视频生成模型的技术最早可以追溯到图像的生成技术,OpenAI在之前的研究中也探讨了利用各种方法进行视频数据的生成模型,包括循环网络、生成对抗网络、自回归变压器和扩散模型等。这些研究通常专注于特定类型的视觉数据、较短的视频或固定大小的视频。相比之下,Sora是一个通用的视觉数据模型,可以生成跨足不同时长、纵横比和分辨率的视频和图像,最高可达一分钟的高清视频。
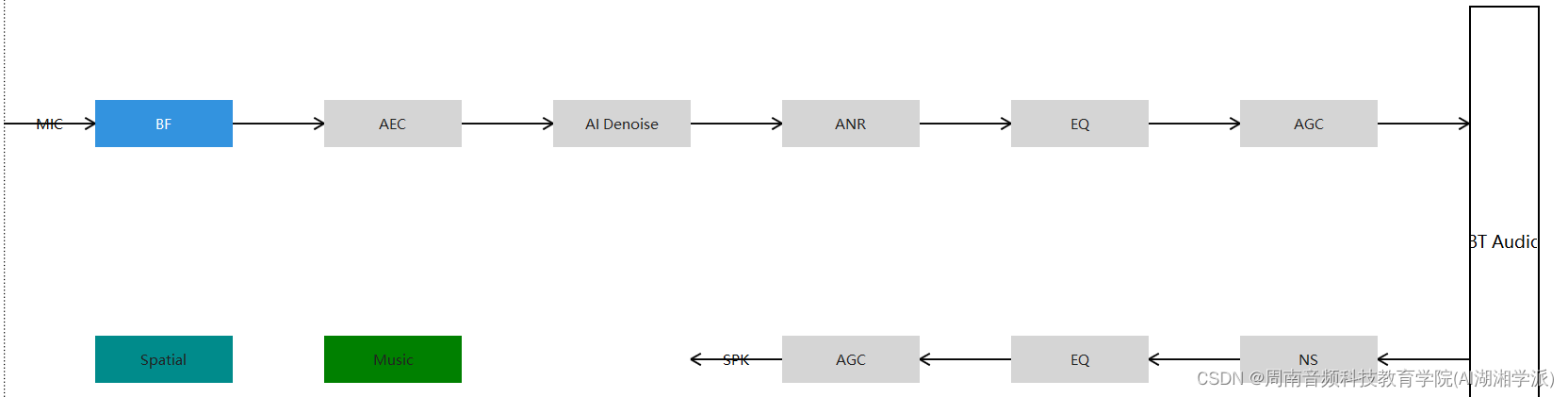
根据OpenAI的技术文档,Sora是一个专注于通过大规模训练在视频数据上进行生成的模型。简单来说,Sora是一个以文本条件为基础,联合训练在可变时间、分辨率和纵横比的视频和图像上的扩散模型。与其他视频生成模型一样,Sora的构建基于transformer框架,具体而言,它采用transformer结构来处理视频和图像的时空patches。根据实验结果显示,扩展视频生成模型是建立物理世界通用模拟器的有前途的方法。
受到大型语言模型的启发,这些模型通过在互联网大规模的数据上进行训练而获得通用能力。语言模型的成功部分得益于使用能够优雅地统一文本的各种模态的token,包括代码、数学和各种自然语言。Sora的开发也借鉴了如何让视觉数据的生成模型也能继承这些优势。与语言模型使用文本token不同,Sora使用的是视觉patches。

先前的研究已经表明,patches是视觉数据模型的有效表示。patches也是一种高度可扩展且有效的表示方法,适用于对各种类型的视频和图像进行生成模型的训练。将视频转化为patches的方法是首先将视频压缩成较低维度的潜在空间,然后将这个表示分解为时空patches。
具体操作步骤是先训练一个网络用于降低视觉数据的维度。这个网络以原始视频作为输入,并输出一个在时间和空间上都进行了压缩的潜在表示。然后Sora在这个压缩的潜在空间上进行训练,然后生成视频。此外还需要训练一个相应的解码器模型,将生成的潜在表示映射回像素空间以生成视频。
对于一个经过压缩的输入视频,首先提取一系列时空patches,这些patches可以充当transformer的token。这个方案对图像也适用,因为图像只是具有单帧的视频。对基于patches的表示使得Sora能够在分辨率、持续时间和纵横比各异的视频和图像上进行训练。在推理时,可以通过将随机初始化的patches以适当大小的网格排列来控制生成视频的尺寸。

具体来说,Sora是一个扩散模型,通过给定的噪声patches(和文本提示等条件信息),它被训练用于预测原始的“清晰”小块。值得注意的是,Sora是一个diffusion transformer。OpenAI的工程师在Sora的研究中发现diffusion transformer在作为视频模型时也能够有效地扩展。他们展示了在Sora训练进行的过程中,使用固定种子和输入的视频样本的比较。随着训练计算量的增加,样本质量会有显著提高。
以往的图像和视频生成方法在训练之前,通常会对视频数据进行调整、裁剪或修剪视频,使其符合模型输入的标准尺寸,例如,256x256分辨率的4秒视频。OpenAI发现,相反地,在原始尺寸上进行训练具有更多的优点。Sora能够采样宽屏的1920x1080视频、垂直的1080x1920视频以及两者之间的任何尺寸。这使得Sora可以直接以各种设备的原生纵横比创建内容。同时还可以在全分辨率生成之前,先在较低尺寸迅速测试内容原型,并且都使用同一个模型进行。
OpenAI研究人员通过实证发现,在原生纵横比上进行视频训练可以改善构图和画面布局。他们将Sora与裁剪了数据的模型版本进行了比较,该版本将所有训练视频裁剪成正方形,这是在训练生成模型时的常见做法。以正方形裁剪训练的模型有时会生成只有主题部分可见的视频。相比之下,Sora生成的视频具有更好的构图。
一般来说,要训练文本到视频生成系统需要大量带有相应文本说明的视频。Sora的开发者应用了从DALL·E 3中引入的重配字幕技术到视频中。他们首先训练一个高度描述性的字幕模型,然后使用它为训练集中的所有视频生成文本字幕。最终发现,在具有高度描述性视频字幕的训练中,不仅可以提高文本的忠实度,还可以提升整体视频的质量。
与DALL·E 3类似,Sora还利用GPT将用户的简短提示转化为更详细的文本说明,然后发送给视频模型。这使得Sora能够生成高质量的视频,准确地遵循用户的提示。
在上文中,我们介绍的都是Sora如何将文本提示生成到视频的案例。但是Sora也可以通过其他输入进行提示生成视频,比如通过输入的图像或视频来生成视频。这种能力使得Sora能够执行各种图像和视频编辑任务,比如创建完美循环视频、使静态图像动起来、将视频向前或向后延长等。
Sora不仅可以生成视频,还能够延长视频的时长,可以是向前或向后延长。我们可以利用这种方法,将视频向前和向后延长,制作出一个无缝的无限循环。对于原视频中某些缺失的过程或者结果进行重新生成补全。
扩散模型已经推动了许多通过文本提示编辑图像和视频的方法。这种技术使得Sora能够在零样本的情况下转换输入视频的风格和环境。还可以使用Sora逐渐插到两个输入视频之间,创建在主题和场景构图完全不同的视频之间的无缝过渡。
当然了,作为视频生成模型,生成图片就是小意思了,Sora可以生成不同尺寸的图像,分辨率最高可达2048x2048。
研究人员发现,在大规模学习数据时,Sora具备新兴的模拟能力,当在大规模进行训练时,视频模型展现出一些有趣的新兴能力。这些能力使得Sora能够模拟物理世界中人、动物和环境的一些方面。这些性质是在没有明确针对3D、物体等的归纳偏见的情况下出现的,纯粹是规模的现象。
比如3D一致性,Sora能够生成具有动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中保持一致地运动。这是Sora完全通过大规模数据学习到的物理空间的规律现象。
Sora对于视频生成最突出的能力是长程协调性和物体永恒性。对于视频生成系统来说,采样长视频时保持时间上的一致性是一个重大挑战。Sora的研究者发现,Sora通常能够有效地建模短程和长程的依赖关系,尽管并非总是如此。例如,我们的模型可以持续追踪人、动物和物体,即使它们被遮挡或离开画面。同样,它可以在单个样本中生成同一角色的多个镜头,保持其在整个视频中的外观。
在视频细节方面,Sora可以堪称完美。比如国内很多动漫,当人物开始吃东西的时候,发现事物并没有发生变化,比如一串糖葫芦吃了很久,还是完整的,也被漫迷们称作“假吃”。而Sora就很明白这点问题。Sora能够明白与世界互动,Sora能够模拟以简单方式影响世界状态的动作。例如,一位画家可以在画布上留下新的笔触,这些笔触随着时间的推移而保持存在,或者一个人可以吃掉一个汉堡并留下咬痕。
Sora还能模拟数字世界,Sora够模拟人工过程,其中一个例子是视频游戏。Sora可以同时使用基本策略控制Minecraft中的玩家,同时以高保真度渲染世界及其动态。通过使用提及“Minecraft”的标题提示Sora,这些能力可以零样本激发。这些能力表明,继续扩大视频模型的规模是通向高度灵活的物理世界和数字世界模拟器,以及其中的物体、动物和人类的有前途的发展路径。
目前,Sora作为模拟器还存在许多限制。例如,它不能准确地模拟许多基本交互的物理过程,比如玻璃破碎。其他交互,比如吃东西,有时不会正确地改变物体的状态。我们在我们的主页上列举了模型的其他常见故障模式,比如在长时间样本中出现的不一致性或物体的突然出现。
话说回来,Sora到底能够改变哪些行业和哪些职业呢?其实回顾一下整个AI生成内容行业就会发现,目前文本内容生成和图像内容生成都已经可以商用了,也就是能够变现了,那么文本生成和图像生成对哪些行业和哪些职业影响最大呢?
相信被波及到的行业和人员心里最清楚,文本方面对自媒体写作人员影响最大,以前写文章需要两三个小时,有了ChatGPT之后,可能就十几分钟,试想一下这对相关岗位的人员会有什么影响,自然是会使用这些工具的自媒体写作人员会更有竞争力,关于图像生成,看一下设计行业就很清楚了,现在包括海报生成、艺术字生成、LOGO生成等都已经逐渐被相关图像生成工具渗透。

那么现在想一下,关于视频生成,受到影响最大的是哪些行业和职业呢?那当然就是和视频最相关的行业和岗位了,首当其冲的就是短视频行业的相关的拍摄和制作人员,其次还有影视行业的演员,摄影师等......
上面所说的内容,绝不是危言耸听,试想一下,当一个行业小白拿着这样的工具开始创作起了视频,他是否会具备和专业视频拍摄人员一样的能力呢?答案是肯定的,因为这个能力不是来自于使用者,而是来自于这个工具本身,使用者只需要把想法告诉它即可。可以想象的到,用不了多久,将会出现很多超级视频创作个体,而且他们都是非专业的,但是却可以和专业人员一教高下。
以前需要表达一个文案或者需要一个产品展示的时候,必然少不了找素材、拍摄等,但是有劳Sora,这一切似乎都变得简单了,你不需要到花费大量的时间上网搜索查找了,甚至也不需要请专业的摄像师来拍摄了。这一切,交给Sora足矣!