一、背景
AI算法中模型训练的主要目的是为了让机器学习算法从给定的标注数据中学习规律、特征和模式,并通过调整模型内部参数,使模型能够对未见过的数据进行准确预测或决策。具体来说:
1. **拟合数据**:模型通过训练来识别输入数据(如图像、文本、声音等)与输出结果之间的关系,以最小化预测值与真实值之间的差异(即误差)。
2. **泛化能力**:训练过程中不仅要求模型在训练集上表现良好,更要确保模型能对未知的新数据样本产生良好的预测效果,这就是模型的泛化能力。
3. **优化参数**:训练过程通过对损失函数的优化,找出一组最优参数组合,使得模型在处理新的未知情况时具有最佳性能。
4. **解决特定任务**:根据不同的应用场景(如分类、回归、聚类、生成等),训练模型来实现特定的机器学习任务目标。
5. **知识表示**:模型训练过程中学习到的知识和结构被编码在其权重和架构中,从而让模型能够表达和理解复杂的输入空间。
综上所述,AI模型训练的核心是通过学习数据中的模式并调整模型参数,以便模型能够在现实应用中有效地解决问题,提供智能决策支持或自动化处理服务。
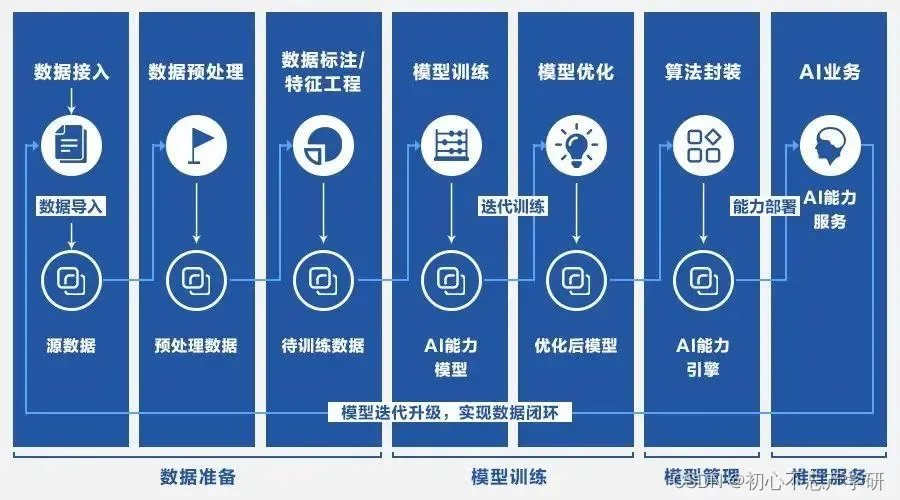
此图片来源于网络
二、模型训练相关算法
AI模型训练过程中通常涉及以下几种类型的算法:
1. **优化算法**:
- **梯度下降法**(Gradient Descent)及其变种,如随机梯度下降(Stochastic Gradient Descent, SGD)、小批量梯度下降(Mini-batch Gradient Descent)、动量梯度下降(Momentum)、RMSProp、Adam等,用于通过迭代更新模型参数以最小化损失函数。
2. **正则化方法**:
- L1和L2正则化,用以防止过拟合,限制模型复杂度。
- Dropout、DropConnect等在深度学习中使用的正则化技术。
3. **初始化算法**:
- 随机初始化模型权重,例如均匀分布、正态分布或Xavier/He初始化等。
4. **激活函数**:
- sigmoid、tanh、ReLU、Leaky ReLU、ELU、Swish等非线性函数,在神经网络中用于引入模型的非线性表达能力。
5. **反向传播算法**:
- 用于计算模型参数的梯度,以便于优化算法进行参数更新。
6. **集成学习算法**:
- 在训练多个模型后整合其预测结果,如Bagging、Boosting(如AdaBoost、Gradient Boosting Machines、XGBoost、LightGBM)、Stacking等。
7. **模型选择与评估算法**:
- 使用交叉验证、网格搜索、贝叶斯优化等方法来寻找最优超参数组合和模型性能评估。
8. **深度学习中的特殊算法**:
- 卷积神经网络(CNN)相关的训练策略,如权值共享、池化操作等。
- 循环神经网络(RNN)及其变体(如LSTM、GRU)的时间序列建模训练方法。
总之,在模型训练的不同阶段会使用到各种各样的算法,这些算法共同协作以达到最优化模型的目的。
三、模型训练阶段初识

此图片来源于网络
模型训练通常经历以下几个阶段:
1. **数据预处理**:
- 数据清洗:去除无效、缺失或错误的数据。
- 数据转换:标准化、归一化、特征缩放等,使数据符合算法的输入要求。
- 特征工程:创建新的特征变量,对原始特征进行编码、组合、提取等操作。
2. **模型定义与初始化**:
- 选择合适的模型架构(例如神经网络、决策树、支持向量机等)。
- 初始化模型参数,如权重矩阵和偏置项。
3. **前向传播**:
- 输入数据通过模型结构计算出预测结果。
4. **损失函数计算**:
- 将模型预测的结果与真实标签对比,计算损失值,这是衡量模型性能好坏的标准。
5. **反向传播与梯度计算**:
- 使用链式法则或其他优化方法计算损失函数相对于所有模型参数的梯度。
6. **参数更新**:
- 根据梯度下降法或其他优化算法更新模型参数,朝着减小损失函数的方向调整模型权重。
7. **迭代训练**:
- 重复上述步骤,每次使用一小批量数据(在批量学习中)或者单个样本(在线学习中),直到模型在训练集上的性能达到预设条件(如达到一定的迭代次数、收敛标准或验证指标不再提升)。
8. **验证与评估**:
- 在训练过程中定期使用验证集来评估模型性能,防止过拟合,并根据需要调整模型复杂度、正则化参数等超参数。
9. **模型测试**:
- 训练完成后,在独立的测试集上评估模型的泛化能力。
10. **模型调优**:
- 如果模型性能未达预期,则可能需要重新调整模型架构、修改超参数或尝试不同的训练策略。
11. **模型保存与部署**:
- 训练得到最优模型后将其保存,以便于后续在实际应用中加载并用于预测或决策。
四、减少模型训练迭代次数
4.1 why
致力于减小模型训练迭代次数的原因主要有以下几点:
1. **节省计算资源**:
- 训练模型是一个计算密集型任务,特别是对于大型的深度学习模型来说,每次迭代可能需要消耗大量的计算力(GPU或TPU等)和时间。减少迭代次数意味着降低整体的计算成本。
2. **加速训练过程**:
- 减少迭代次数能显著加快模型训练速度,使得研究人员能够更快地得到初步结果并进行后续调整,提高研究效率。
3. **防止过拟合**:
- 过多的迭代次数可能导致模型对训练数据过度拟合,即模型过于复杂以至于捕捉到了训练数据中的噪声和细节,而忽视了泛化到未见过数据的能力。通过控制迭代次数和其他正则化策略可以避免这一问题。
4. **优化实验效率**:
- 在实际应用中,我们经常需要尝试不同的模型结构、参数设置以及训练策略。如果每次训练都需要大量迭代,则会大大拖慢实验进度。因此,缩短单次训练所需迭代次数有助于提高实验效率。
5. **实时性要求**:
- 在某些对实时性有严格要求的应用场景下,如自动驾驶、在线推荐系统等,模型需要快速更新以适应新的环境变化或用户行为模式。减少训练迭代次数有利于满足这类需求。
然而,需要注意的是,并非所有的模型都适合在较少迭代次数下就能达到良好性能。有时候,为了提升模型精度和泛化能力,适度增加迭代次数是必要的。关键在于找到合适的平衡点,既保证模型性能又兼顾计算效率。
4.2 how
减小模型训练迭代次数并保证或提高模型性能的方法可以围绕优化算法、学习率策略、正则化手段以及数据增强等方面进行:
1. **合适的学习率与学习率调整策略**:
- 使用较大的初始学习率可以更快地接近损失函数的最小值区域。
- 应用动态学习率调整策略,如ReduceLROnPlateau(在验证指标不再提升时减少学习率)、余弦退火(Cosine Annealing)或指数衰减等,能够在不增加迭代次数的前提下更高效地收敛。
2. **优化器选择和超参数调优**:
- 选择适合问题的优化器,比如Adam、Adagrad、RMSprop等,它们具有自适应学习率的能力,可能比标准梯度下降法更快地找到最优解。
- 对于某些复杂模型,尝试使用更先进的优化算法,例如二阶方法(如牛顿法、拟牛顿法)及其变种。
3. **预训练与迁移学习**:
- 利用已经在大规模数据集上预训练好的模型作为基础,通过微调(fine-tuning)少量层或整个模型来适应新的任务,这样通常能在较少迭代次数下达到较高的性能水平。
4. **正则化技术**:
- 合理运用正则化方法(L1、L2正则化),Dropout、Batch Normalization等避免过拟合,使模型能够快速收敛到泛化能力较好的区域。
5. **早停法**:
- 在验证集上的性能不再显著提升时提前终止训练,即“Early Stopping”,这有助于防止过度训练,同时也减少了不必要的迭代次数。
6. **数据增强**:
- 增加训练数据的多样性而不增加样本数量,例如对图像数据进行翻转、旋转、裁剪等操作,这有助于模型在有限的迭代次数内学到更多模式。
7. **模型结构改进**:
- 设计高效的模型架构,利用残差连接、注意力机制等技术使得信息流动更为有效,从而加速训练过程中的收敛速度。
8. **批归一化(Batch Normalization)**:
- 在神经网络内部应用批量归一化,可以加快模型的训练速度,因为它允许使用更大的学习率并提供一定的正则化效果。
总之,综合运用上述方法,可以在保持或提高模型性能的同时,有效地减少训练所需的迭代次数。
五、模型训练结果的验证
要全面地对模型训练结果进行验证,可以采用多种方法和技术以确保模型具有良好的泛化能力和鲁棒性。以下是一些建议:
1. **数据集划分**:
- **留出法(Holdout)**:将原始数据集划分为训练集、验证集和测试集。通常比例为70%(训练)、15%(验证)和15%(测试),或者80%(训练)、10%(验证)和10%(测试)。
- **交叉验证**(如k-折交叉验证):用于在有限样本下提高评估准确性,通过重复使用数据的不同子集进行训练和验证。
2. **验证指标**:
- 使用多个评价指标来衡量模型性能,根据任务类型选择合适的度量标准,例如分类问题中的准确率、精确率、召回率、F1分数等;回归问题的均方误差(MSE)、均方根误差(RMSE)、R²得分等。
3. **超参数调优**:
- 使用网格搜索、随机搜索或贝叶斯优化等方法调整模型的超参数,并在验证集上进行评估。
4. **模型性能稳定性检验**:
- 多次运行训练过程并比较结果的一致性,检查模型是否对初始权重的随机初始化敏感。
5. **正则化与复杂度控制**:
- 应用L1/L2正则化、Dropout、Batch Normalization等技术防止过拟合,并观察不同正则化强度下的模型性能变化。
6. **对抗性攻击与防御**:
- 对模型进行对抗样本攻击测试,看其在面对经过轻微扰动的数据时的表现如何,以评估模型的鲁棒性。
7. **模型解释性分析**:
- 使用SHAP值、LIME工具等方法理解模型预测背后的逻辑,检查模型是否学习到了有意义的特征关系。
8. **A/B测试**:
- 在实际应用中部署模型前,可进行线上实验(A/B测试)对比模型效果与其他策略或旧版模型的效果。
9. **分布偏移校验**:
- 确保训练集、验证集和测试集在数据分布上尽可能保持一致。如果发现有分布偏移,应考虑领域适应或迁移学习技术。
10. **模型集成**:
- 训练多个模型并结合他们的预测结果,如平均投票、Stacking 或 Bagging 方法,进一步提升模型的稳定性和性能。
通过以上多种方式综合评估模型,可以从不同角度全面检验模型在各种条件下的表现,确保模型不仅在训练集上有良好性能,在未知的新数据上也能表现出优秀的泛化能力。