文章目录
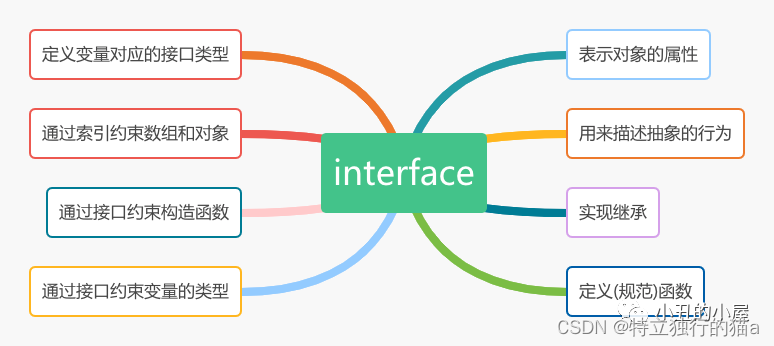
- 一.互联网概念
- 1.产品闭环和业务闭环
- 2.软件设计中的上游和下游
- 3.JDK运行时常量池
- 二.CPU相关概念
- 1.查询CPU信息
- 2.CPU利用率(CPU utilization)和 CPU负载(CPU load)
- 2.1.如何理解CPU负载
- 2.2.top命令查看CPU负载均值
- 2.3.CPU负载和CPU利用率的区别
- 2.4.CPU负载为多少才算比较理想
- 2.5.如何来降低服务器的CPU负载?
- 三.Java线上问题排查工具
- 1.操作系统工具
- 1.1.top:实时显示系统整体资源使用情况
- 1.2.vmstat:监控内存和CPU
- 1.3.iostat:监控IO使用
- 1.4.netstat:监控网络使用
- 1.5.pidstat : 监控指定进程的上下文切换
- 1.6.free:显示内存使用情况
- 1.6.df:显示磁盘使用情况
- 2.JDK命令行性能监控工具
- 2.1.jps-JVM进程状况工具
- 2.2. jinfo-JVM配置信息工具
- 2.3. jstack-JVM堆栈跟踪工具
- 2.4.jmap-JVM内存映射工具
- 2.5.jhat-JVM堆转储快照分析工具
- 2.6. jstat-JVM统计信息监视工具
- 2.7.jcmd:多功能聚合工具
- 2.8.其他(javap、HSDIS)
- 2.9.结合shell脚本使用案例
- 3.JDK可视化性能监控工具
- 3.1.JConsole
- 1.建立连接
- 2.程序概况
- 3.内存监控
- 4.线程监控
- 5.类加载情况
- 6.虚拟机信息
- 3.2.JVisualVM
- 1.安装插件
- 2.生成、浏览堆转储快照
- 3.分析程序性能
- 4.BTrace动态日志跟踪
- 3.3.Java Mission Control
- 1.MBean服务器
- 2.飞行记录器(Flight Recorder)
- 4.第三方工具
一.互联网概念
1.产品闭环和业务闭环
产品闭环
- 产品闭环是能够让
用户主动迭代促进产品发展的方式。例如一些内容产品,比如糗事百科,种子用户产出高质量内容,举报与赞起到筛选内容,提高内容质量的作用,内容质量的提升有助于吸引更多用户。- 这就是产品闭环,产品给予用户需求解决方法,用户帮助产品提升需求解决方案的质量。
业务闭环是
-
业务闭环就是业务流程从顺序变成循环。能够让用户从头到尾,再从尾到头一直处在业务模式当中。将用户锁在这个无限循环的圈圈中。
- 如美团红包:
点餐—>支付—>获得红包—>为了使用红包继续点餐….
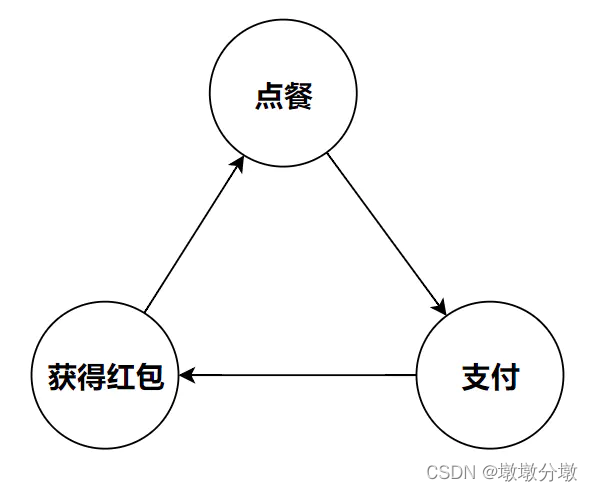
- 如美团红包:
-
当然也有朋友说,
点餐–支付–想要吃饭就继续点餐,这也是一种闭环,当然可以这样理解,但是这种闭环只能奢求用户需求是强烈的,用户不会选择其他竞品,否则你这种闭环只是行业模式的闭环,而不是自己项目中业务模式的闭环。我们更应该做到的是做好闭环的转换,比如上述的例子,加了一个红包之后,就能够促进用户再次来平台点餐消费。
2.软件设计中的上游和下游
- 上游就是被依赖方(
接近数据源) - 下游就是依赖方(
接近用户) - 被依赖方宕机了,依赖方也无法提供服务了。
3.JDK运行时常量池
运行时常量池在JDK1.6在永久代中,JDK1.7被移到Java堆中,JDK1.8在堆外内存-元空间
二.CPU相关概念
1.查询CPU信息
#0.查询cpu的详细信息
cat /proc/cpuinfo#1.查看物理CPU的个数
cat /proc/cpuinfo | grep 'physical id' | sort | uniq | wc -l#2. 查看逻辑CPU的个数
cat /proc/cpuinfo | grep 'processor' | wc -l#3.查看CPU是几核
cat /proc/cpuinfo | grep 'cores' | uniq#4.查询CPU的型号以及逻辑CPU个数
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
2.CPU利用率(CPU utilization)和 CPU负载(CPU load)
2.1.如何理解CPU负载
一个单核的CPU可以形象得比喻成一条单车道!那么:
0.00 表示目前桥面上没有任何的车流。 实际上这种情况与 0.00 和 1.00 之间是相同的,很通畅,过往的车辆可以丝毫不用等待的通过。1.00表示刚好是在这座桥的承受范围内。 不算糟糕,只是车流会有些堵,不过这种情况可能会造成交通越来越慢。超过 1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。 那么情况有多糟糕? 例如2.00的情况说明车流已经超出了桥所能承受的一倍,那么将有多余过桥一倍的车辆正在焦急的等待。3.00的话情况就更不妙了,说明这座桥基本上已经快承受不了,还有超出桥负载两倍多的车辆正在等待。
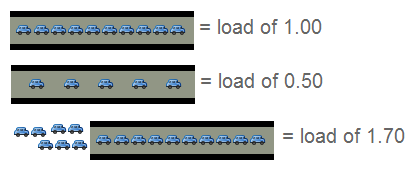
-
上图和
CPU负载情况非常相似。一辆汽车的过桥时间就好比是CPU处理某线程 的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程 在队列中等待的时间。 -
和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,
理想状态 下,都希望负载平均值小于 1.00 。当然不排除部分峰值会超过 1.00,但长此以往保持这 个状态,就说明会有问题,这时候你应该会很焦急。
在多CPU系统中,负载均值是基于内核的数量决定的。以 100% 负载计算,1.00 表示单个处理器,而 2.00 则说明有两个双处理器,那么 4.00 就说明主机具有四个处理器。
- 回到我们上面有关车辆过桥的比喻。
1.00我说过是「一条单车道的道路」。那么在单车道 1.00情况中,说明这桥梁已经被车塞满了。而在双CPU系统中,这意味着多出了一倍的 负载,也就是说还有50% 的剩余系统资源---- 因为还有另外条车道可以通行,所以双处理器的负载满额的情况是 2.00。

2.2.top命令查看CPU负载均值
Linux系统中很多都是用CPU负载均值(load average)来代表当前系统的负载状况,比如使用top命令:
top - 20:12:45 up 3:05, 6 users, load average: 1.16, 1.27, 1.14
Tasks: 208 total, 1 running, 206 sleeping, 0 stopped, 1 zombie
%Cpu(s): 11.8 us, 3.7 sy, 0.0 ni, 84.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 2067372 total, 1998832 used, 68540 free, 54104 buffers
KiB Swap: 2095100 total, 25540 used, 2069560 free, 449612 cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6635 long 20 0 435m 79m 32m S 7.3 3.9 11:31.39 rhythmbox 4523 root 20 0 110m 61m 4804 S 5.3 3.0 8:34.14 Xorg 5316 long 9 -11 162m 5084 4088 S 4.3 0.2 6:01.53 pulseaudio 5793 long 20 0 114m 22m 13m S 4.3 1.1 0:23.38 gnome-terminal ……
在第一行的最后显示的为 load average: 1.16 , 1.27 ,1.14
使用
uptime命令,效果也是类似:
20:15:01 up 3:07, 6 users, load average: 0.43, 0.97, 1.05
- "load average"一共返回3个平均值----1分钟内负载均值、5分钟内负载均值,15分钟内负载均值,从右向左看这几个数据,我们可以
判断系统负载的发展趋势。----应该参考哪个值?- 如果只有1分钟的
负载均值大于1.0,其他2个时间段都小于1.0,这表明只是暂时现象,问题不大。 - 如果15分钟内,平均负载均值
大于1.0(调整CPU核心数之后),表明问题持续存在,不是暂时现象。所以,你应该主要观察"15分钟负载均值",将它作为电脑正常运行的指标。
- 如果只有1分钟的
2.3.CPU负载和CPU利用率的区别
-
CPU利用率:显示的是程序在运行期间实时
占用的CPU百分比 -
CPU负载:显示的是
一段时间内正在使用和等待使用CPU的平均任务数。CPU利用率高,并不意味着负载就一定大。- 举例:有个程序需要一直使用CPU的运算功能,那么此时CPU的使用率可能达到100%,但是CPU的工作负载则是
趋近于“1”,因为CPU仅负责一个工作嘛!如果同时执行这样的程序两个呢?CPU的使用率还是100%,但是工作负载则变成2了。所以也就是说,当CPU的工作负载越大,代表CPU必须要在不同的工作之间进行频繁的工作切换。
- 举例:有个程序需要一直使用CPU的运算功能,那么此时CPU的使用率可能达到100%,但是CPU的工作负载则是
2.4.CPU负载为多少才算比较理想
在评估CPU负载时,我们只以5分钟为单位为统计任务队列长度。如果每隔5分钟统计的时候,发现任务队列长度都是1,那么CPU负载就为1。
-
假如我们是
单核CPU,负载一直为1,意味着没有任务在排队,还不错。但是我那台服务器,是双核CPU,等于是有4个内核,每个内核的负载为1的话,总负载为4。这就是说,如果我那台服务器的CPU负载长期保持在4左右,还可以接受。 -
但是每个内核的负载为1,并不能算是一种理想状态!这意味着我们的
CPU一直很忙,不得清闲。
1.0是负载均值的理想值吗?
- 不一定,系统管理员往往会留一点余地,当
这个值达到0.7,就应当引起注意了。经验法则是这样的:- 当负载均值
持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。 - 当负载均值
持续大于1.0,你必须动手寻找解决办法,把这个值降下来。 - 当系统
负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
- 当负载均值
问题:假设有24个core,那么,load多少合适呢?
# CPU核心数=24个
> grep 'model name' /proc/cpuinfo | wc -l
> 24计算公式=24 * 0.7 = 16.8
个人比较赞同CPU负载小于等于0.5算是一种理想状态。
2.5.如何来降低服务器的CPU负载?
最简单办法的是更换性能更好的服务器,不要想着仅仅提高CPU的性能,那没有用,CPU要发挥出它最好的性能还需要其它软硬件的配合。
- 在服务器其它方面配置合理的情况下,
CPU数量和CPU核心数(即内核数)都会影响到CPU负载,因为任务最终是要分配到CPU核心去处理的。两块CPU要比一块CPU好,双核要比单核好。
因此,我们需要记住,除去CPU性能上的差异,CPU负载是基于内核数来计算的!有一个说法,“有多少内核,即有多少负载”。
三.Java线上问题排查工具
1.操作系统工具
1.1.top:实时显示系统整体资源使用情况
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。uptime命令也可以,但是功能没有top强大
按1 显示所有cpu信息
按大P、shift+小p 按CPU利用率排序
按大M、shift+小m 按内存占比排序
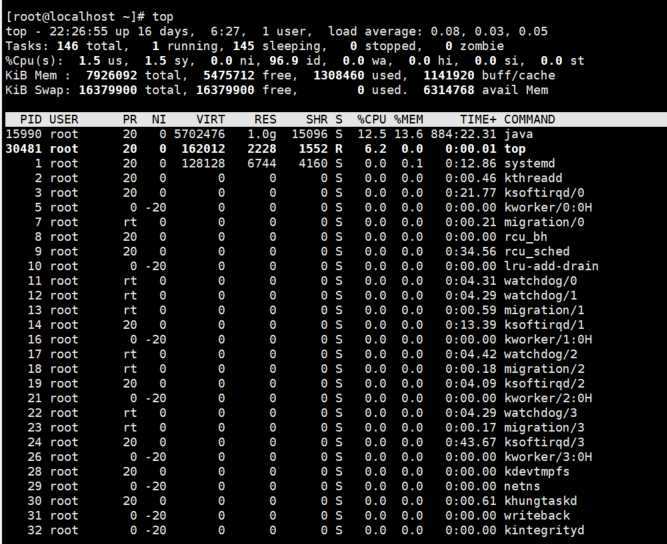
top命令的输出可以分为2个部分:前半部分是系统统计信息,后半部分是进程信息。
在统计信息中:
- 第1行是
任务队列信息,从左到右依次表示:系统当前时间、系统运行时间、当前登录用户,最后的load average表示系统的平均负载。
重点:
load average表示cpu平均负载: 假设三项为为9.73、10.67、10.49,分别代表前一分钟,五分钟,十五分钟的平均CPU负载,最重要的指标是最后一个数字,即前15分钟的平均CPU负载,这个数字越小越好。
- 所谓CPU负载指的是一
段时间内任务队列的长度,通俗的讲,就是一段时间内一共有多少任务在使用或等待使用CPU。
- 第2行是
进程统计信息,分别有正在运行的进程数、睡眠进程数、停止的进程数、僵尸进程数。 - 第3行是
CPU统计信息,us表示用户空间CPU占用率,sy表示内核空间CPU占用率、ni表示用户进程空间改变过优先级的进程cpu的占用率、id表示空闲cpu占用率、wa表示等待输入输出的CPU时间百分比、hi表示硬件中断请求、si表示软件中断请求。
在进程信息区中,显示了系统各个进程的资源使用情况。主要字段的含义:
-
PID:进程id
-
USER:进程所有者的用户名
-
PR:优先级
-
NI:nice值,负值表示高优先级,正值表示低优先级
-
TIME+:进程使用的CPU时间总计,单位1/100秒 -
%CPU:进程使用cpu占比 -
%MEM:进程使用内存占比 -
COMMAND:命令名/命令行
1.2.vmstat:监控内存和CPU
vmstat也是一款功能比较齐全的性能监测工具。它可以·统计CPU、内存使用情况、swap使用情况能信息·。
- 一般通过2个数字参数来完成的,第1个参数是采样的
时间间隔数,单位是秒,第2个参数是采样的次数,如:

上图命令表示每秒采样一次,共三次。
输出的各个列的含义:
Procsr: 运行队列中进程数量b: 等待IO的进程数量Memory(内存)swpd: 使用虚拟内存大小free: 可用内存大小buff: 用作缓冲的内存大小cache: 用作缓存的内存大小Swapsi: 每秒从交换区写到内存的大小so: 每秒写入交换区的内存大小IO:(现在的Linux版本块的大小为1024bytes)bi: 每秒读取的块数bo: 每秒写入的块数system(系统)in: 每秒中断数,包括时钟中断cs: 每秒上下文切换数CPU(以百分比表示)us: 用户进程执行时间(user time)sy: 系统进程执行时间(system time)id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 ,以百分比表示。wa: 等待IO时间
1.3.iostat:监控IO使用
iostat可以提供磁盘IO的监控数据:
avg-cpu: %user %nice %system %iowait %steal %idle1.44 0.00 0.39 0.00 0.00 98.17Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.37 0.47 30.30 3561197 229837730
dm-0 0.44 0.33 29.97 2518272 227313194
dm-1 0.12 0.13 0.33 1013276 2520308
dm-2 0.00 0.00 0.00 502 2068
iostat结果面板 avg-cpu描述的是系统cpu使用情况:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
1.4.netstat:监控网络使用
在web程序中,可能运行需要网络,可以使用netstat命令监控网络流量。
netstat -aActive Internet connections (servers and established)Proto Recv-Q Send-Q Local Address Foreign Address Statetcp 0 0 localhost:30037 *:* LISTENudp 0 0 *:bootpc *:*Active UNIX domain sockets (servers and established)Proto RefCnt Flags Type State I-Node Pathunix 2 [ ACC ] STREAM LISTENING 6135 /tmp/.X11-unix/X0unix 2 [ ACC ] STREAM LISTENING 5140 /var/run/acpid.socket...1.5.pidstat : 监控指定进程的上下文切换
pidstat用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况。用户可以通过指定统计的次数和时间来获得所需的统计信息。
语法 pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
-u:默认的参数,显示各个进程的cpu使用统计
-r:显示各个进程的内存使用统计
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下文切换情况
-t:显示选择任务的线程的统计信息外的额外信息
-T { TASK | CHILD | ALL } 这个选项指定了pidstat监控的。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。ALL表示报告独立的task和task下面的所有线程。注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。
-V:版本号
-h:在一行上显示了所有活动,这样其他程序可以容易解析。
-I:在SMP环境,表示任务的CPU使用率/内核数量
-l:显示命令名和所有参数
1.6.free:显示内存使用情况
语法: free [-bkmotV][-s <间隔秒数>]
选项
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-h 以合适的单位显示内存使用情况,最大为三位数,自动计算对应的单位值。单位有:B = bytesK = kilosM = megasG = gigasT = teras
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
$> free -h总量 已使用 空闲 共享内存 缓存区 可用内存total used free shared buff/cache available
Mem(物理内存): 7.6G 5.5G 342M 159M 1.8G 1.6G
Swap(虚拟内存: 0B 0B 0B
1.6.df:显示磁盘使用情况
语法: df [选项] [文件]
选项
-a 全部文件系统列表
-h 方便阅读方式显示
-H 等于“-h”,但是计算式,1K=1000,而不是1K=1024
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地文件系统
-m 区块为1048576字节
使用方式
$> df -h文件系统 容量 已用 可用 已用% 挂载点
Filesystem Size Used Avail Use% Mounted on
/dev/sda5 89G 75G 15G 84% /
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 3.9G 1.9M 3.9G 1% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/sda2 1014M 137M 878M 14% /boot
overlay 89G 75G 15G 84% /var/lib/docker/overlay2/fa16cec2fb4dbf9ec38189fe9d0cba102d1e2156341ae0223c684ba192078b3c/merged
shm 64M 0 64M 0% /var/lib/docker/containers/03832a0f3a900f30e497f9d0dc670e65c821e12611488731fdb01a7bd4ac0220/shm
tmpfs 783M 0 783M 0% /run/user/0
2.JDK命令行性能监控工具
JDK 本身自带了许多 JVM 调优监控工具,可以帮助我们查看 Java 应用程序的进程、线程、内存栈等信息。这些工具命令包括jps、jstack、jmap、jhat等等。
这些命令所在位置:
- Linux:安装完JDK后,默认放在 /usr/bin/ 下,直接使用即可;
- Windows: 在JDK安装目录的/bin/ 目录下,比如
C:\Program Files\Java\jdk1.8.0_212\bin,如果想要在CMD上使用的话,可以将改路径添加到环境变量 Path 中。
2.1.jps-JVM进程状况工具
jps:(JVM Process Status Tool) :用于显示系统内所有的 HotSpot 虚拟机进程pid
使用方式
-m 输出进程 pid以及传递给main方法的参数
$>jps -m
8464 Jps -m
4600
5052 TestClass1-l 输出应用main class的完整package名或者 执行JAR包完整路径名
$>jps -l
5552 sun.tools.jps.Jps
4600
5052 com.test.TestClass1-v 输出进程pid及传递给JVM的参数
$>jps -v
4600 -Dosgi.requiredJavaVersion=1.8 -Dosgi.instance.area.default=@user.home/eclipse-workspace -XX:+UseG1GC -XX:+UseStringDeduplication -Dosgi.requiredJavaVersion=1.8 -Xms256m -Xmx1024m
10988 Jps -Denv.class.path=.;D:\soft\jdk1.8.0_65\lib\dt.jar;D:\soft\jdk1.8.0_65\lib\tools.jar; -Dapplication.home=D:\soft\jdk1.8.0_65 -Xms8m
5052 TestClass1 -Dfile.encoding=UTF-8
-lmv 组合输出
$>jps -lmv
4600 -Dosgi.requiredJavaVersion=1.8 -Dosgi.instance.area.default=@user.home/eclipse-workspace -XX:+UseG1GC -XX:+UseStringDeduplication -Dosgi.requiredJavaVersion=1.8 -Xms256m -Xmx1024m
5052 com.test.TestClass1 -Dfile.encoding=UTF-8
7612 sun.tools.jps.Jps -lmv -Denv.class.path=.;D:\soft\jdk1.8.0_65\lib\dt.jar;D:\soft\jdk1.8.0_65\lib\tools.jar; -Dapplication.home=D:\soft\jdk1.8.0_65 -Xms8m
2.2. jinfo-JVM配置信息工具
jinfo:(JVM Configuration info):用于实时查看和调整虚拟机运行参数。
语法:jinfo [ option ] pid
使用方式
jinfo -flags {pid}:查看指定java进程的所有jvm运行参数jinfo -flag {name} {pid}:查看指定java进程的某一个参数的值
> jinfo -flag InitialHeapSize 18378jinfo -flag [+|-]{name} {pid}:开启/关闭某个java进程JVM参数
使用 jinfo 可以在不重启虚拟机的情况下,可以动态的修改 jvm 的参数。尤其在线上的环境特别有用。
描述:开启或者关闭对应名称的参数,主要是针对 boolean 值的参数设置的
> jinfo -flag +PrintGC 18378 //开启GC信息打印
> jinfo -flag +PrintGCDetails 18378 //开启打印GC详细信息
>
> jinfo -flag -PrintGCDetails 18378//关闭GC信息打印
> jinfo -flag -PrintGCDetails 18378//关闭打印GC详细信息jinfo -flag {name}={value} {pid}:修改某个java进程JVM参数值jinfo虽然可以在java程序运行时动态地修改虚拟机参数,但并不是所有的参数都支持动态修改jinfo -sysprops {pid}:输出当前java进程JVM所有系统参数值
> jinfo -sysprops 18378
2.3. jstack-JVM堆栈跟踪工具
jstack:查看指定 Java 进程 pid 的当前时刻的线程快照
语法: jstack [options] pid
-l :除了堆栈外,显示关于锁的附加信息
-m :打印 Java 和底层 C/C++ 框架的线程堆栈;
-F :当正常输出的请求不被响应时,强制输出线程堆栈
使用方式
$> jstack 17632022-02-28 18:21:45
Full thread dump OpenJDK 64-Bit Server VM (25.292-b10 mixed mode):"http-nio-8888-Acceptor" #28 daemon prio=5 os_prio=0 tid=0x00007fedf8d9a000 nid=0x713 runnable [0x00007fedc69d6000]java.lang.Thread.State: RUNNABLEat sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:421)at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:249)- locked <0x00000000f864cb60> (a java.lang.Object)
os_prio: 操作系统级别的优先级- prio : 线程优先级`, 即Thread类中优先级
tid:Java内的线程ID的16进制形式, 即Thread类中tid对应值nid:操作系统级别的线程ID的16进制形式pid:操作系统级别进程ID
常见用法
1.查询java进程ID: jps -lm
2.查看进程下所有线程: top -H -p {pid}
3.将十进制线程ID换成16进制:print "%x/n" {线程ID}
4.查看进程下的线程线程快照并过滤关键字:jstack {pid} | grep {线程ID的16进制} -A 30
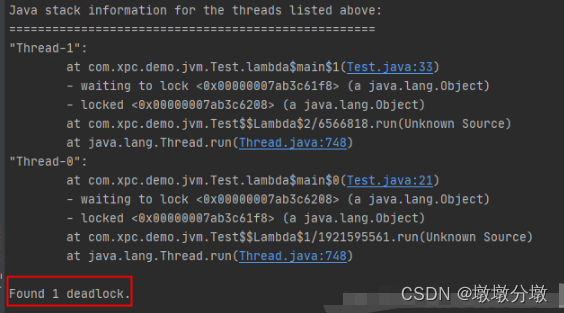
通过jstack来查看线程是否死锁,grep 关键字 “deadlock” 就可以了
jstack -l pid | grep -i -E 'BLOCKED | deadlock'
2.4.jmap-JVM内存映射工具
jmap:(JVM Memory Map): 用于查看堆内存的使用情况,一般与 jhat 结合一起使用,还可以生成内存dump文件,查询finalize执行队列、Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
使用
-XX:+HeapDumpOnOutOfMemoryError参数可以让虚拟机出现OOM的时候自动生成dump文件。
语法:jmap [option] pid
-heap:查看进程堆内存使用情况,包括使用的 GC 算法、堆配置参数和各代中堆内存使用情况;(Linux)
-dump 把进程内存使用情况 dump 到文件中(堆转储快照)。 格式为 -dump:[live,] format=b,file=<dumpFileName> 其中live子参数说明是否只dump出存活的对象
-histo 显示堆中对象统计信息,包括类、实例数量、合计容量,如果带上 live 则只统计活对象;
-F 当虚拟机进程对-dump选项没有响应时,可以使用这个选项强制生成dump快照。(Linux)
-finalizerinfo 显示在 F-Queue 中等待 Finalizer 线程执行 finalize 方法的对象。(Linux)
注意事项:
-dump: 会将整个堆内存信息的dump到文件,如果堆内存比较大的话,会导致dump过程耗时过程,并且dump过程中为了保证信息是可靠的会暂停Java应用堆内存空间大的慎用这个指令否则会导致应用暂停时间过长-histo:live: JVM会先触发gc,然后再统计信息
使用方式
-dump pid:dump堆到文件,format指定输出格式,live指明是活着的对象,file指定文件名 $>jmap -dump:live,format=b,file=dump.hprof 5052
Dumping heap to C:\Users\jasonspears\Desktop\dump.hprof ...
Heap dump file created-------------------------------
-heap pid:打印heap的概要信息,GC使用的算法,heap的配置及使用情况,可以用此来判断内存目前的使用情况以及垃圾回收情况
$>jmap -heap 5052
Attaching to process ID 5052, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.65-b01using thread-local object allocation.
Parallel GC with 4 thread(s)Heap Configuration:MinHeapFreeRatio = 0MaxHeapFreeRatio = 100MaxHeapSize = 2122317824 (2024.0MB)NewSize = 44564480 (42.5MB)MaxNewSize = 707264512 (674.5MB)OldSize = 89653248 (85.5MB)NewRatio = 2SurvivorRatio = 8MetaspaceSize = 21807104 (20.796875MB)CompressedClassSpaceSize = 1073741824 (1024.0MB)MaxMetaspaceSize = 17592186044415 MBG1HeapRegionSize = 0 (0.0MB)Heap Usage:
PS Young Generation
Eden Space:capacity = 34078720 (32.5MB)used = 1022416 (0.9750518798828125MB)free = 33056304 (31.524948120117188MB)3.0001596304086537% used
From Space:capacity = 5242880 (5.0MB)used = 0 (0.0MB)free = 5242880 (5.0MB)0.0% used
To Space:capacity = 5242880 (5.0MB)used = 0 (0.0MB)free = 5242880 (5.0MB)0.0% used
PS Old Generationcapacity = 36175872 (34.5MB)used = 1863752 (1.7774124145507812MB)free = 34312120 (32.72258758544922MB)5.151920042176178% used5486 interned Strings occupying 442328 bytes.-------------------------------
-histo pid:查看堆中对象数量
$> jmap -histo 2003 | morenum #instances #bytes class name
----------------------------------------------1: 46284 4602680 [C2: 8592 1750048 [I3: 46197 1108728 java.lang.String4: 8416 928232 java.lang.Class5: 10368 912384 java.lang.reflect.Method6: 7634 898224 [B7: 25961 830752 java.util.concurrent.ConcurrentHashMap$Node8: 12156 486240 java.util.LinkedHashMap$Entry9: 6483 441904 [Ljava.util.HashMap$Node;-------------------------------
-finalizerinfo pid:打印等待回收的对象信息
$>jmap -finalizerinfo 5052
Attaching to process ID 5052, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.65-b01
Number of objects pending for finalization: 0//经验之谈
1.jcmd 获取Java进程ID(过滤出指定jar的进程信息只获取第一列的pid作为命令2的入参)
$> jcmd | grep 'springboot_gc_test_tool-1.0.jar' | awk '{print $1}'
2.jmap打印指定Java进程的heap的概要信息,GC使用的算法,heap的配置及的使用情况
$> jmap -heap $( jcmd | grep 'springboot_gc_test_tool-1.0.jar' | awk '{print $1}' )
2.5.jhat-JVM堆转储快照分析工具
jhat: (JVM Heap Analysis Tool) 用于和 jmap 搭配使用,用来分析 jmap 生成的 dump文件,jhat 内置了一个微型的 HTTP/HTML 服务器,生成 dump 的分析结果后,可以在浏览器中查看
语法: jhat [options] <heap-dump-file>
-port:指定 Jhat 的 HTTP 服务端口,默认为 7000;
使用方式
$> jhat -port 7000 dump.batReading from dump.bat...
Dump file created Mon Feb 28 19:36:58 CST 2022
Snapshot read, resolving...
Resolving 349828 objects...
Chasing references, expect 69 dots..........................................................
Eliminating duplicate references....................................................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
在浏览器中输入地址:localhost:7000
2.6. jstat-JVM统计信息监视工具
jstat:(JVM statistics Monitoring) 是用于统计监测 JVM运行时状态信息的命令,它可以显示本地或者远程虚拟机进程中的类装载、内存区、垃圾收集、JIT 编译(即时编译)等运行数据。
语法:jstat -<option> [-t] [-h<lines>] <vmid> [<时间间隔> [<次数>]]
对于命令格式中的VMID和LVMID:如果是本地JVM进程,就是进程 ID。如果是JVM虚拟机进程,则VMID的格式为
[protocol:][//]lvmind[@hostname[:port]/servername]interval : 查询间隔count:查询次数 如果省略interval和count,则只查询一次
选项option:表示查询的虚拟机信息,主要分为3类:类装载、垃圾收集、运行期编译状况
-class 监视类装载、卸载数量,总空间以及类装载所耗费的时间
(常用)-gc 监视Java堆情况,包括 Eden 区、2个Survivor 区、老年代、永久代或者 jdk1.8元空间等,容量、已用空间、垃圾收集时间合计等信息
(常用)-gccapacity 监视内容与-gc基本相同,但输出主要关注Java堆各个区域使用的最大、最小空间
(常用)-gcutil 监视内容与-gc基本相同,但输出主要关注已使用空间占总空间的百分比
(常用)-gccause 与-gcutil功能一样,但是会额外输出导致上一次GC产生的原因
(常用)-gcnew 监视新生代GC状况
(常用)-gcnewcapacity 监视内容与-gcnew 基本相同,但输出主要关注Java堆各个区域使用的最大、最小空间
(常用)-gcold 监视老年代代GC状况
(常用)-gcoldcapacity 监视内容与-gcold 基本相同,但输出主要关注Java堆各个区域使用的最大、最小空间
(常用)-gcpermcapacity 输出永久代使用的最大、最小空间
-compiler 输出JIT编译器(即时编译器)编译过的方法、耗时等信息
-printcompilation 输出已经被JIT编译的方法
使用方式
-class pid:查看java进程类加载统计
$>jstat -class 5052
Loaded Bytes Unloaded Bytes Time1663 3061.7 0 0.0 0.37-compiler pid:查看java进程编译统计
$>jstat -compiler 5052
Compiled Failed Invalid Time FailedType FailedMethod659 0 0 0.52 0-gc pid:查看java进程垃圾回收统计
$>jstat -gc 5052S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
5120.0 5120.0 0.0 0.0 33280.0 16650.3 87552.0 0.0 4480.0 767.4 384.0 75.8 0 0.000 0 0.000 0.00-gccapacity pid:查看java堆内存统计
$>jstat -gccapacity 5052NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC43520.0 690688.0 43520.0 5120.0 5120.0 33280.0 87552.0 1381888.0 87552.0 87552.0 0.0 1056768.0 4480.0 0.0 1048576.0 384.0 0 0
比如,需要250毫秒查询一次进程2003 的垃圾收集状况,一共查询4次
$> jstat -gc 2003 250 4S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
1408.0 1408.0 0.0 0.0 11648.0 559.7 28776.0 17264.4 42752.0 40205.1 5632.0 5149.9 172 0.399 5 0.318 0.717
1408.0 1408.0 0.0 0.0 11648.0 559.7 28776.0 17264.4 42752.0 40205.1 5632.0 5149.9 172 0.399 5 0.318 0.717
1408.0 1408.0 0.0 0.0 11648.0 559.7 28776.0 17264.4 42752.0 40205.1 5632.0 5149.9 172 0.399 5 0.318 0.717
以上各列的含义为:
S0C、S1C、S0U、S1U:Survivor0/1区容量(Capacity)和使用量(Used:)(kB)
EC、EU:Eden区容量和使用量(kB)
OC、OU:老年代容量和使用量(kB)
MC、MU:Metaspace容量和使用量(kB)
CCSC、CCSU: 类指针压缩空间容量、类指针压缩空间使用量(kB)(都是针对MetaSpace使用情况)
YGC、YGCT:年轻代GC次数(Count) 和 GC耗时(Time)(秒)
FGC、FGCT:FullGC次数 和FullGC耗时(秒)
GCT:GC总耗时(秒)堆内存 = 年轻代 + 老年代 + 永久代(1.8后移除,使用堆外内存元空间)
年轻代 = Eden 区 + 两个 Survivor 区(From 和 To)
2.7.jcmd:多功能聚合工具
在JDK1.7以后,新增了一个全能工具jcmd,它可以实现上面除了jstat外所有命令的功能。
语法: jcmd <pid | main class> <command ... | PerfCounter.print | -f file>
即:
jcmd pid command
主要参数
| 选项 描述 | |
|---|---|
| help | 打印帮助信息,例如jcmd {pid} help |
| ManagementAgent.stop | 停止JMX Agent |
| ManagementAgent.start_local | 开启本地JMX Agent |
| ManagementAgent.start | 开启JMX Agent |
| Thread.print | 参数-l 打印java.util.concurrent锁信息,相当于:jstack |
| PerfCounter.print | 相当于:jstat -J -Djstat.showUnsupported=true -snap |
| GC.class_histogram | 相当于:jmap -histo |
| GC.heap_dump | 相当于:jmap -dump:format=b,file=xxx.bin |
| GC.run_finalization | 相当于:System.runFinalization() |
| GC.run | 相当于:System.gc() |
| VM.uptime | 参数-date打印当前时间,VM启动到现在的时候,以秒为单位显示 |
| VM.flags | 参数-all输出全部,相当于:jinfo -flags , jinfo -flag |
| VM.system_properties | 相当于:jinfo -sysprops |
| VM.command_line | 相当于:jinfo -sysprops grep command |
| VM.version | 相当于:jinfo -sysprops grep version |
2.8.其他(javap、HSDIS)
javap-class文件分解器
- javap是java class文件分解器,可以
反编译(即对javac编译的文件进行反编译),也可以查看java编译器生成的字节码。
HSDIS:jit生成代码反汇编
- HSDIS是sun推荐的HotSpot虚拟机JIT编译代码的反汇编插件,它包含在HotSpot虚拟机的源码中。了解即可。
2.9.结合shell脚本使用案例
--------------------------
#启动Java进程
nohup java -Xmx1024m -jar springboot_gc_test_tool-1.0.jar &
#启动Java进程并输出GC日志
nohup java -Xmx1024m -Xloggc:/data/jvmtest/gc.log -jar springboot_gc_test_tool-1.0.jar &
# 清理进程
kill -9 $( jcmd | grep 'springboot_gc_test_tool-1.0.jar' | awk '{print $1}' )
--------------------------------------------------------
# 行匹配语句 awk '' 只能用单引号
# 每行按空格或TAB分割,输出文本中的1项#1.jcmd 获取Java进程ID
jcmd | grep 'springboot_gc_test_tool-1.0.jar' | awk '{print $1}'#2.jmap打印指定Java进程的heap的概要信息,GC使用的算法,heap的配置及的使用情况
jmap -heap $( jcmd | grep 'springboot_gc_test_tool-1.0.jar' | awk '{print $1}' ) #3.通过jstat 动态监控GC统计信息,间隔1000毫秒统计一次,每10行数据后输出列标题;各参数代表含义如下:
jstat -gc -h10 $(jcmd | grep 'springboot_gc_test_tool-1.0.jar' | awk '{print $1}') 1000
3.JDK可视化性能监控工具
3.1.JConsole
JConsole( Java Monitoring and Management Console),是一款基于 JMX( Java Manage-ment Extensions) 的可视化监视管理工具。
- 它的功能主要是对Java程序进行
收集和参数调整,不仅可以用在虚拟机本身的管理上,还可以用于运行于虚拟机之上的程序中。
1.建立连接
- JConsole位于
%JAVA_HOME%/bin目录下,直接启动即可使用
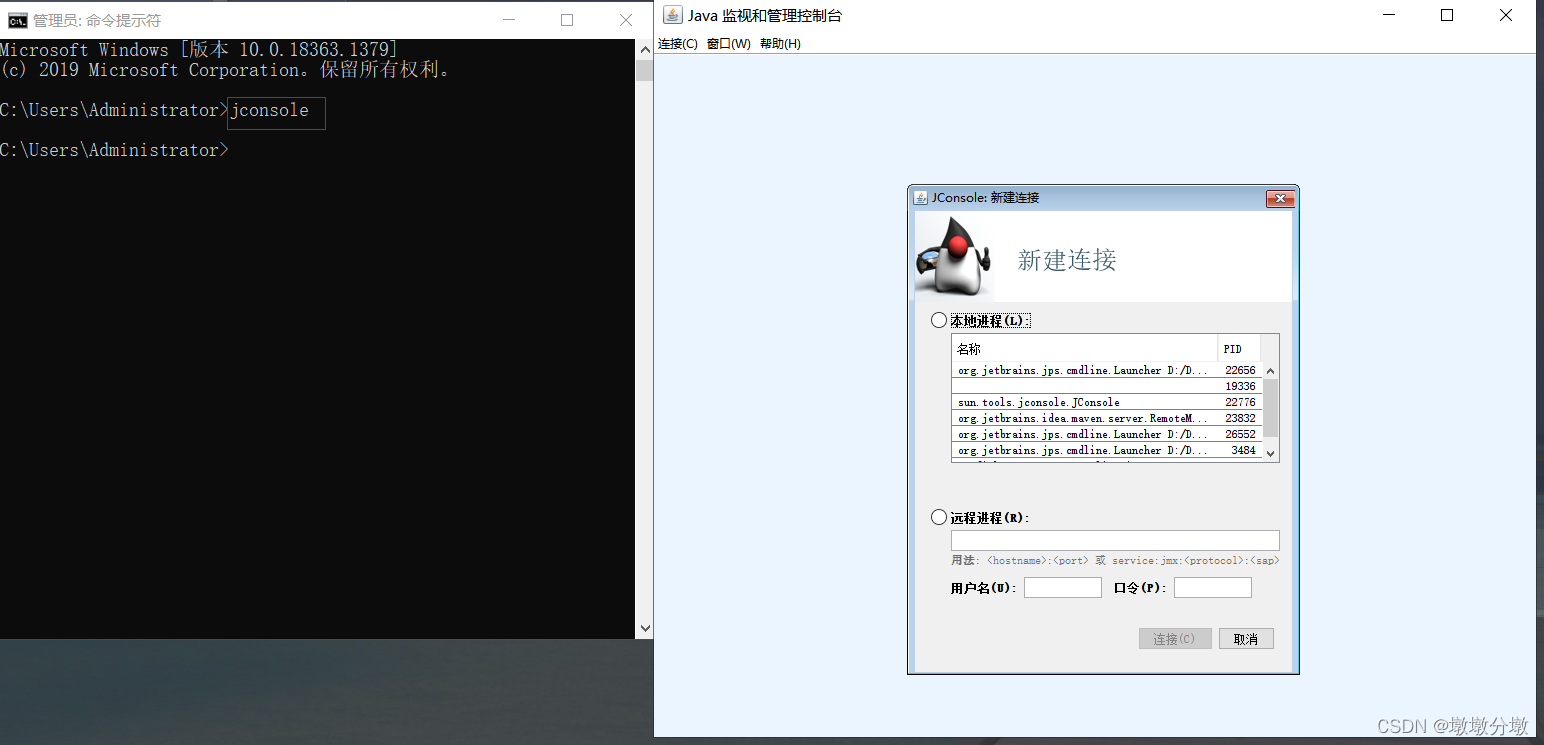
在新建连接对话框中, 显示所有的本地Java应用程序,选择需要连接的程序即可。
下面还有一个用于连接远程进程的文本框,输入正确的远程地址即可连接。
- 如果一个程序需要使用JConsole与那成连接,则需要
在启动Java程序时,加上以下参数:
JAVA_OPTS="-Dfile.encoding=UTF-8"
JAVA_OPTS="$JAVA_OPTS -Dlog.dir=$LOG_PATH"
JAVA_OPTS="$JAVA_OPTS -Djava.rmi.server.hostname=xxx.xxx.xxx.xxx(本机IP) -Dcom.sun.management.jmxremote"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=xx"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.local.only=false"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.ssl=false"
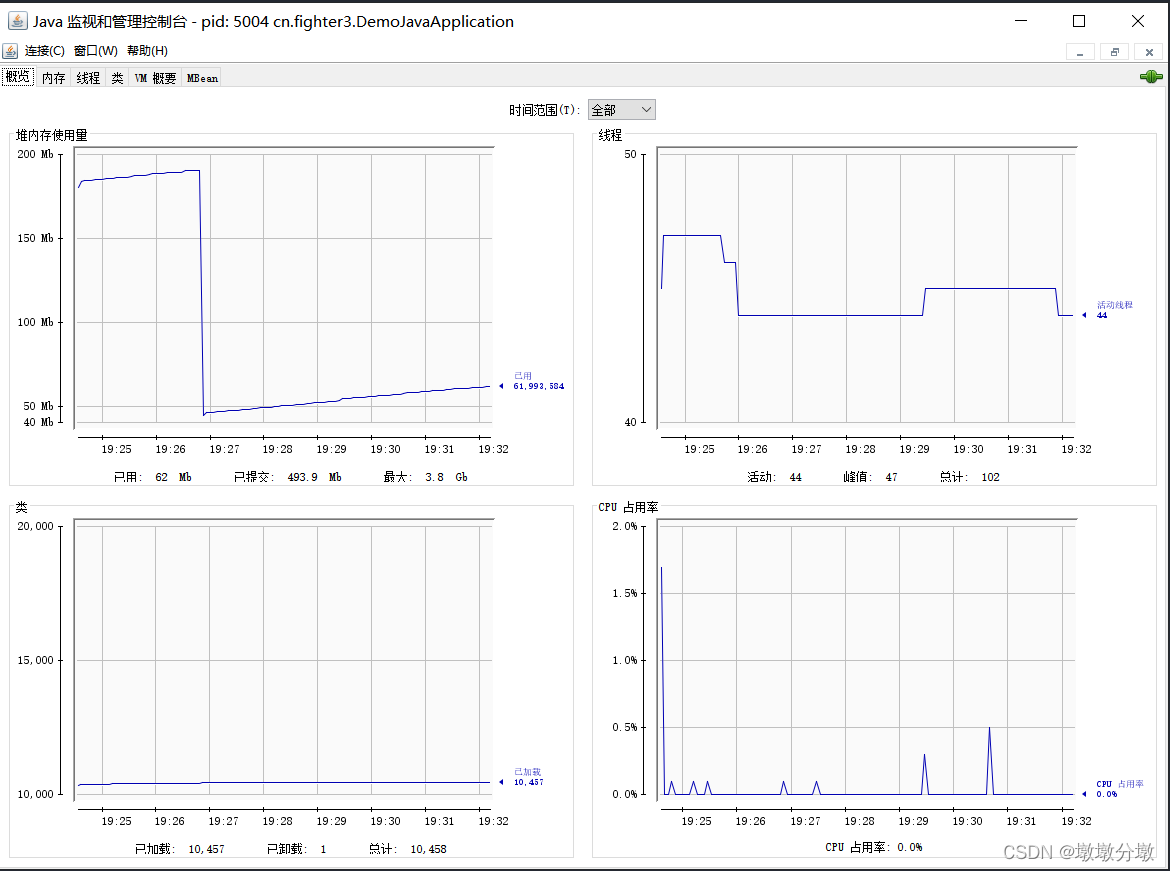
2.程序概况
- 连接本地程序后在
概述可以看到运行的概览信息,包括堆内存使用情况、线程、类、CPU使用情况5项信息的曲线图。
3.内存监控
- 内存的作用相当于
可视化的jstat命令,用于监视被l垃圾收集器管理的虚拟机内存。 - 包含堆内存的整体信息,以及详细的eden区、suvivior区、老年代的使用情况。
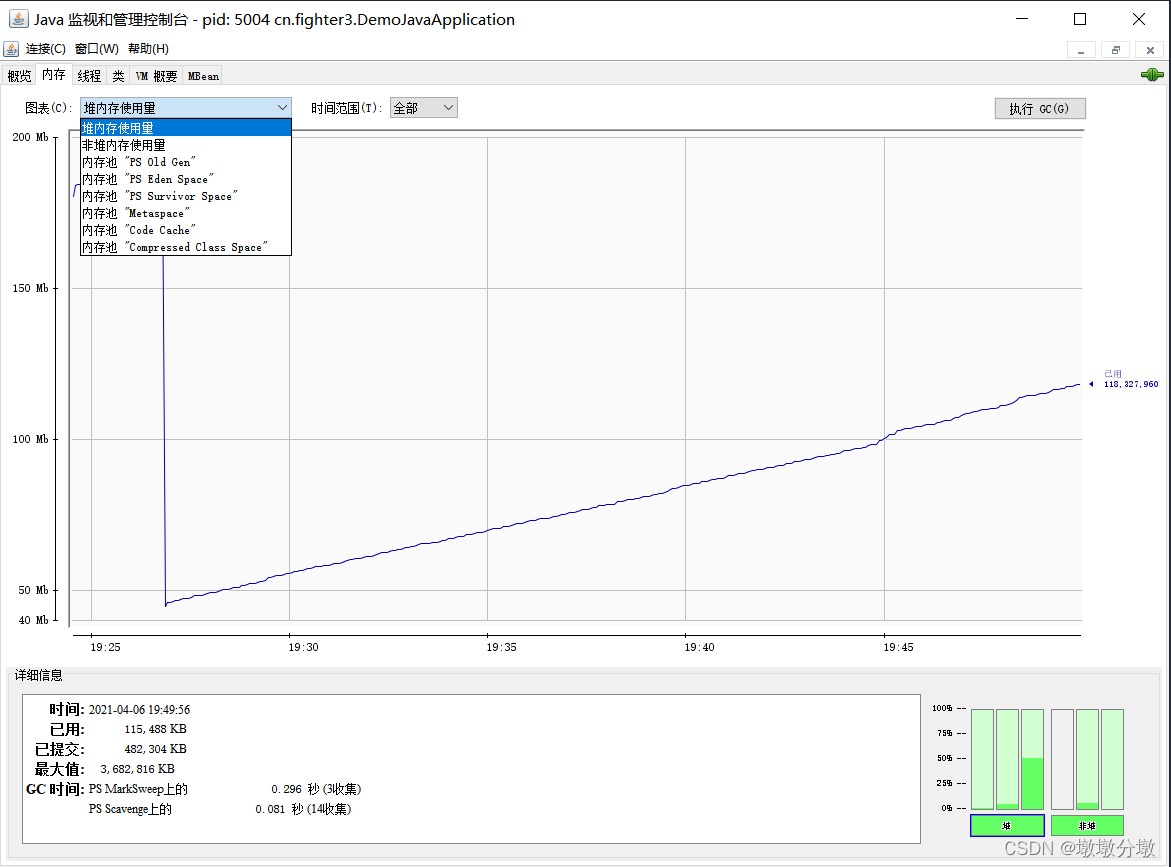
为了更加清晰地查看内存地变化,运行下面一段程序,然后连接:
/*** VM参数: -Xms100m -Xmx100m -XX:+UseSerialGC*/
public class JConcoleRAMMonitor {/**** 内存占位符对象,一个OOMObject大约占64KB*/static class OOMObject {public byte[] placeholder = new byte[64 * 1024];}public static void fillHeap(int num) throws InterruptedException {List<OOMObject> list = new ArrayList<OOMObject>();for (int i = 0; i < num; i++) {// 稍作延时,令监视曲线的变化更加明显Thread.sleep(300);list.add(new OOMObject());}System.gc();}public static void main(String[] args) throws Exception {fillHeap(2000);}
}
这段代码的作用是以64KB/50ms的速度向Java堆中填充数据,一共填充1000次。
-
观察
Eden区的运行趋势,发现呈折线。观察堆内存使用,发现以稍有曲折的状态向上增长。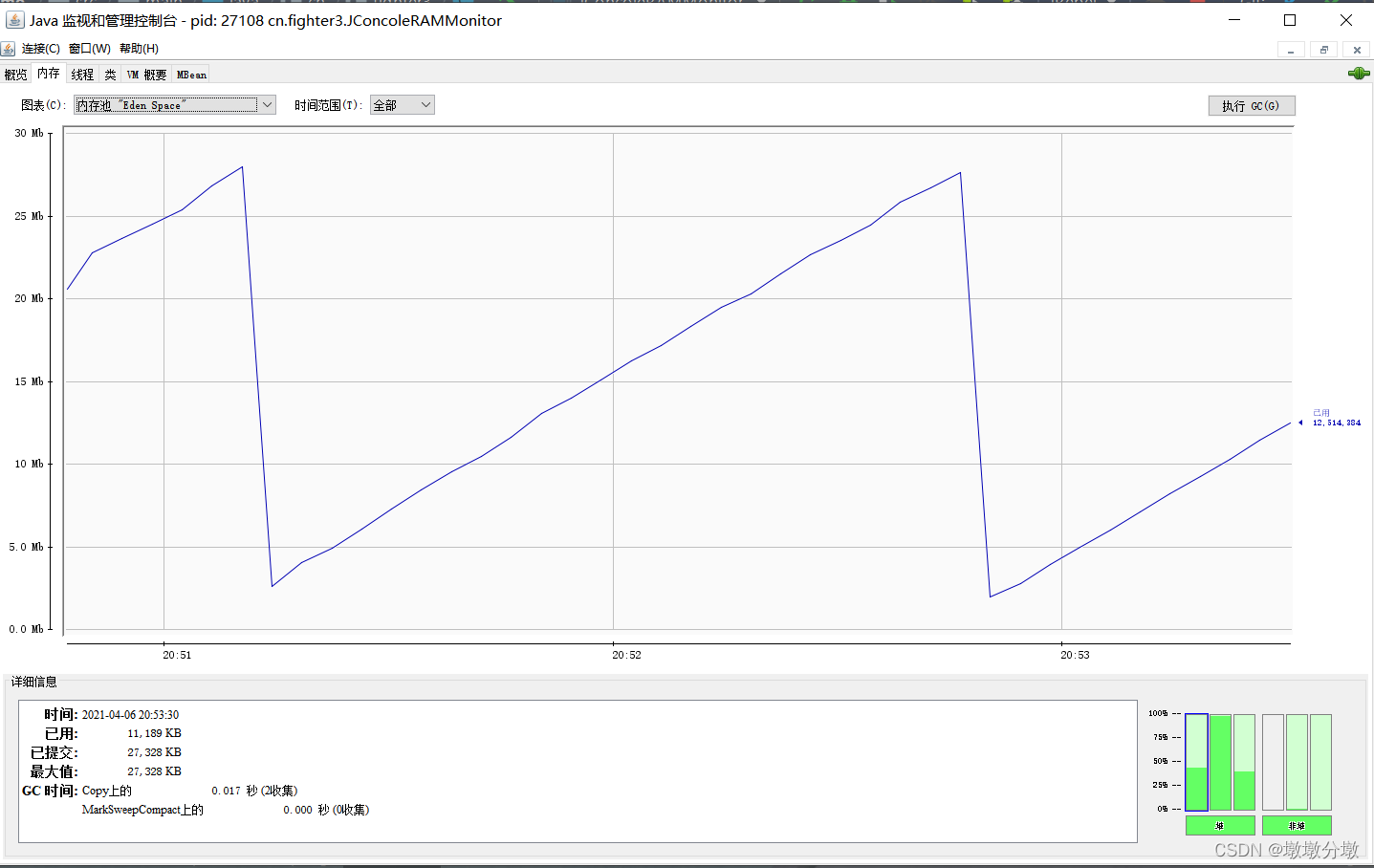
-
执行
System.gc()之后,老年代的柱状图仍然显示峰值状态,最后程序会以堆内存溢出结束,这是因为空间未能回收——List<OOMObject>list对象一直存活,fillHeap()方法仍然没有退出,如果把System.gc()移动到fillHeap()方法外调用就可以回收掉全部内存。
4.线程监控
- JConcole可以监控线程,相当于
可视化的jstack命令。如图,JConcole显示了系统内的线程数量,并在屏幕下方显示了程序中所有的线程。单击线程名称,就可以查看线程的栈信息。
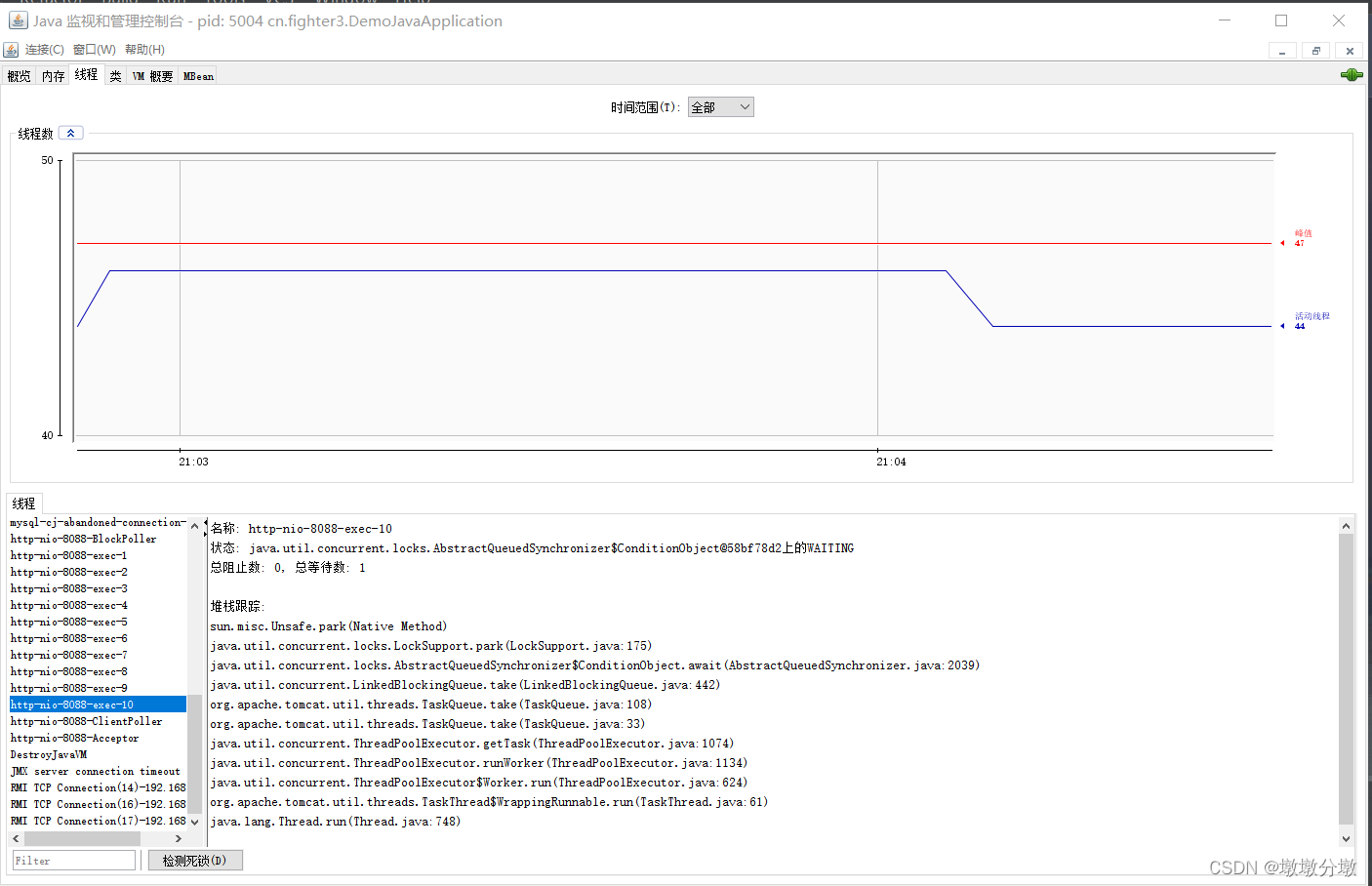
使用JConsole还可以快速定位死锁问题。
public class ThreadLockDemo {/*** 线程死锁等待演示*/static class SynAddRunalbe implements Runnable {int a, b;public SynAddRunalbe(int a, int b) {this.a = a;this.b = b;}@Overridepublic void run() {synchronized (Integer.valueOf(a)) {synchronized (Integer.valueOf(b)) {System.out.println(a + b);}}}}public static void main(String[] args) {for (int i = 0; i < 100; i++) {new Thread(new SynAddRunalbe(1, 2)).start();new Thread(new SynAddRunalbe(2, 1)).start();}}
}出现线程死锁以后,点击JConsole线程面板的检测到死锁按钮,将会看到线程的死锁信息。
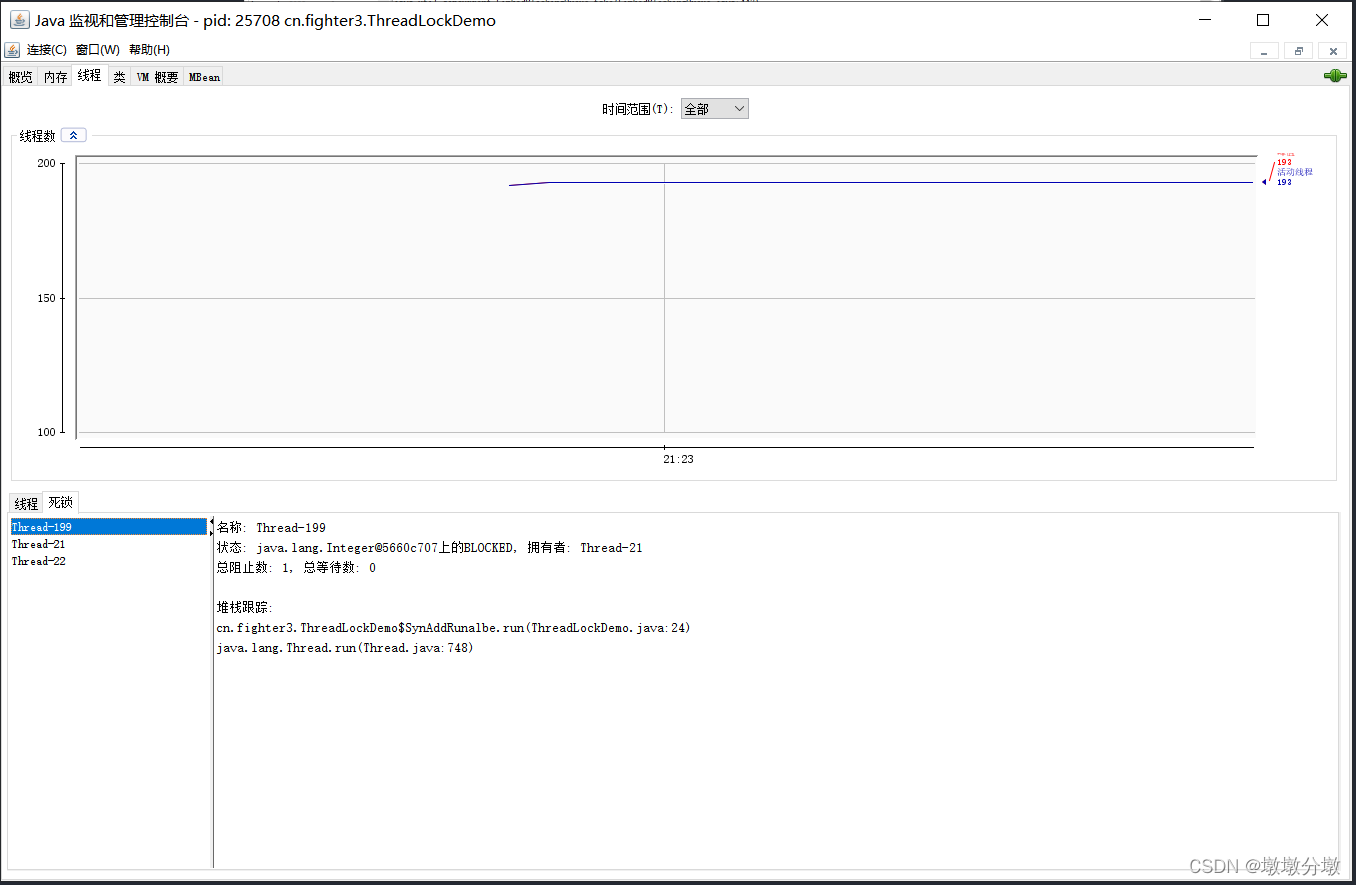
- 可以看到线程Thread-199等待线程Thread-21持有的资源。
5.类加载情况
- v类页面显示
了已经装载的类数量。在详细信息栏中,还显示了已经卸载的类的数量。
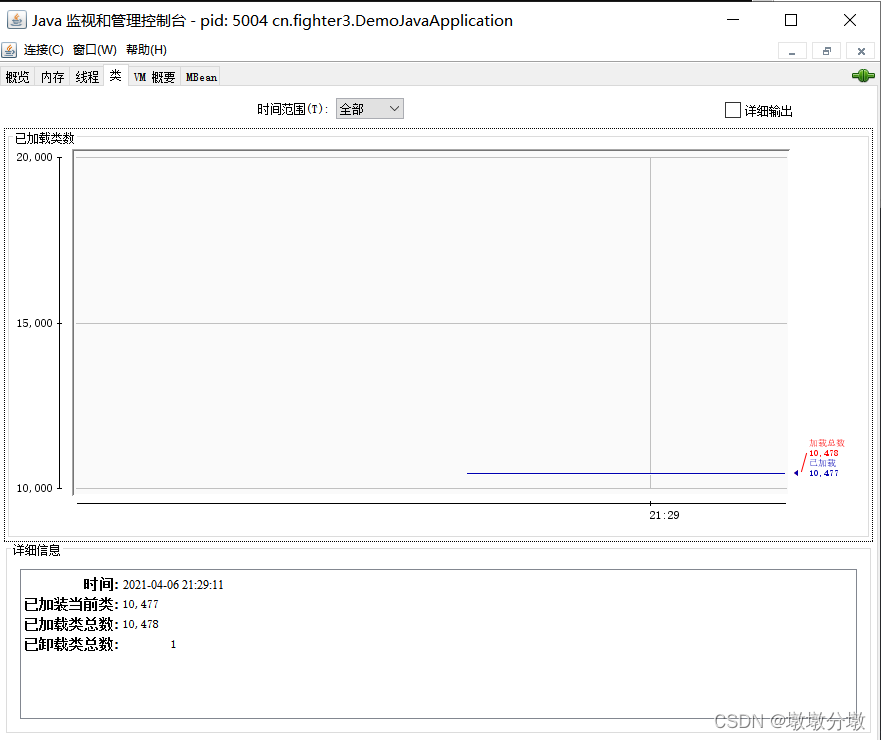
6.虚拟机信息
- 在
VM摘要,JConsole显示了当前应用程序的运行环境,包括虚拟机类型、版本、堆信息以及虚拟机参数等。

3.2.JVisualVM
VisualVM(All-in-One Java Troubleshooting Tool)是功能最强大的运行监视和故障处理程序之一,曾经在很长一段时间内是Oracle官方主力发展的虚拟机故障处理工具。可以分析内存快照、线程快照;监控内存变化、GC 变化
- 相比一些第三方工具,VisualVM有一个很大的优点:
不需要被监视的程序基于特殊Agent去运行,因此它的通用性很强,对应用程序实际性能的影响也较小,使得它可以直接应用在生产环境中。
1.安装插件
在JDK6 Update7以后,VisualVM便作为JDK的一部分发布,它在%JAVA_HOME%/bin 目录下,可直接使用
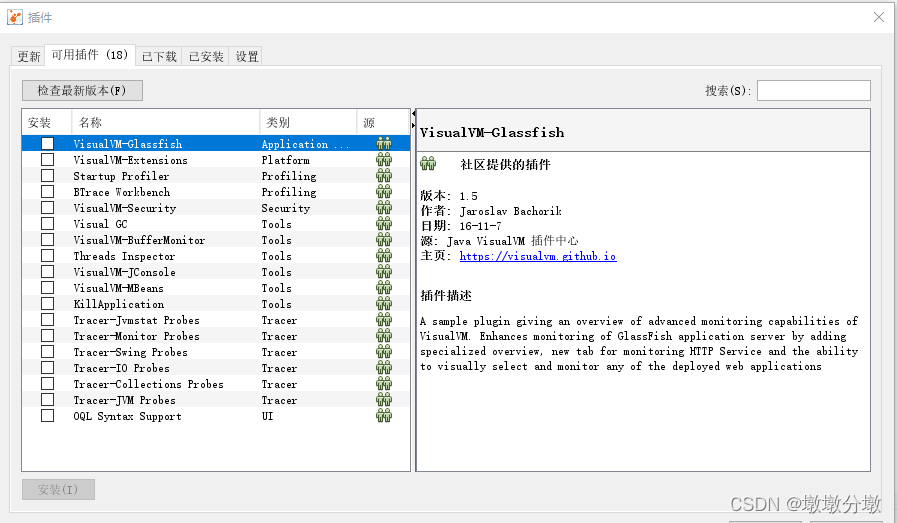
VisualVM的精华之处在于它的插件。插件安装可以手动安装或者自动安装。
-
手动安装,从地址 https://visualvm.github.io/pluginscenters.html 下载载nbm包, 点击
工具->插件->已下载菜单,然后在弹出对话框中指定nbm包路径便可完成安装。 -
一般选择自动安装,点击
工具-> 插件菜单,在可用插件里可以看到可安装的插件,按需安装即可。
VisualVM中概述,监视、线程,MBeans的功能与前面介绍的JConsole差别不大,这里不在重复啰嗦了。
2.生成、浏览堆转储快照
在VisualVM中生成堆转储快照文件有两种方式,可以执行下列任一操作:
- 窗口中
右键单击应用程序节点,然后选择堆Dump。 - 窗口中
双击应用程序节点以打开应用程序标签,然后在“监视”标签中单击堆Dump。
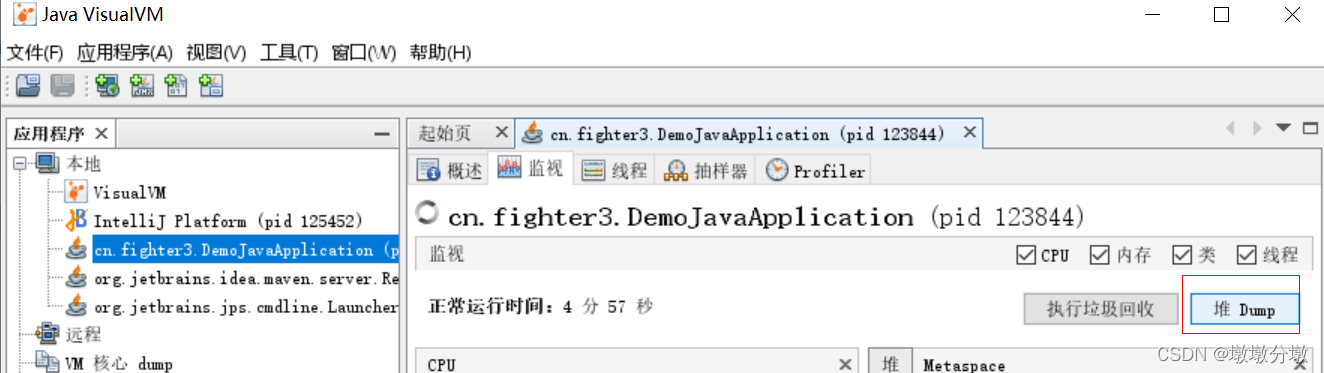
生成堆dump文件之后,该堆的应用程序下增加了一个以[heap-dump]开头的子节点。如果需要把dump文件保存或发送出去,就需要heapdump节点上右键选择“另存为”菜单,否则当VisualVM关闭时,生成的dump文件会被当作临时文件自动清理掉。
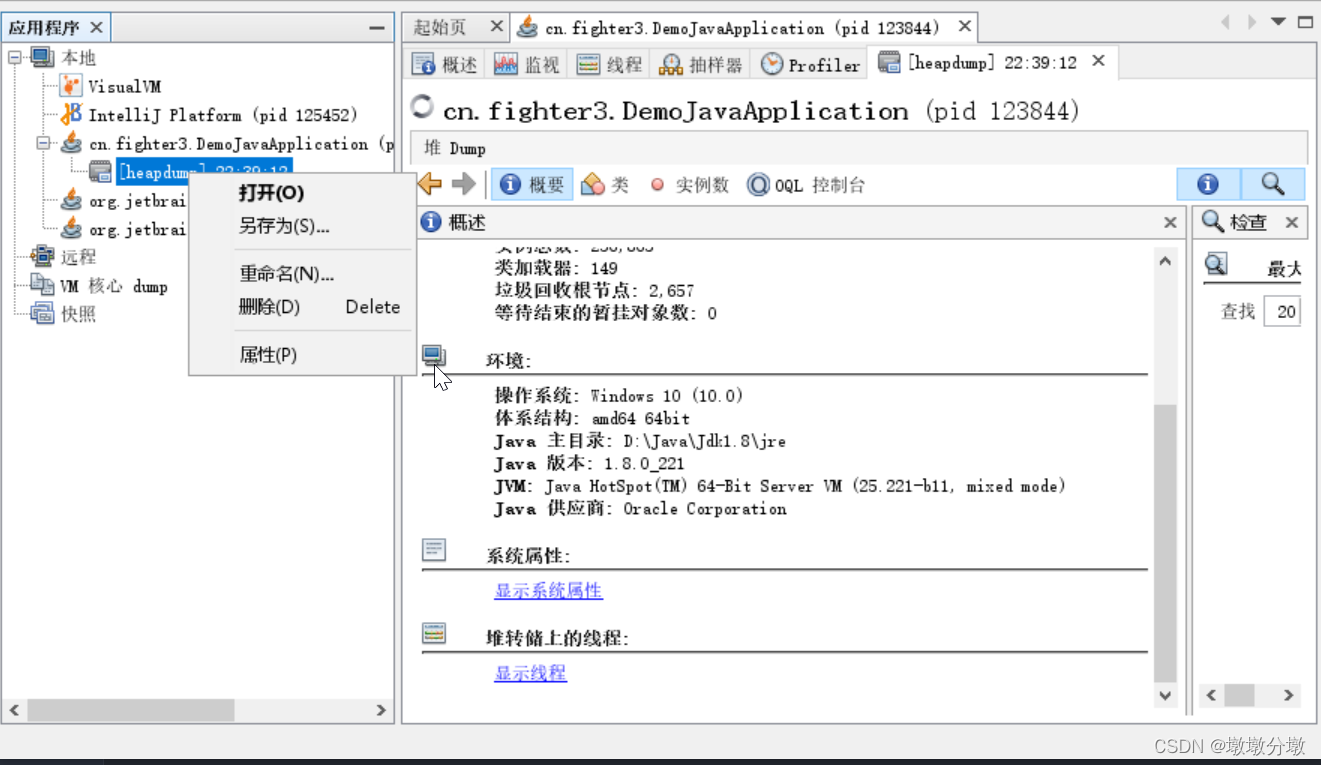
要打开一个由已经存在的dump文件,通过文件菜单中的“装入”功能,选择磁盘上的文件即可。
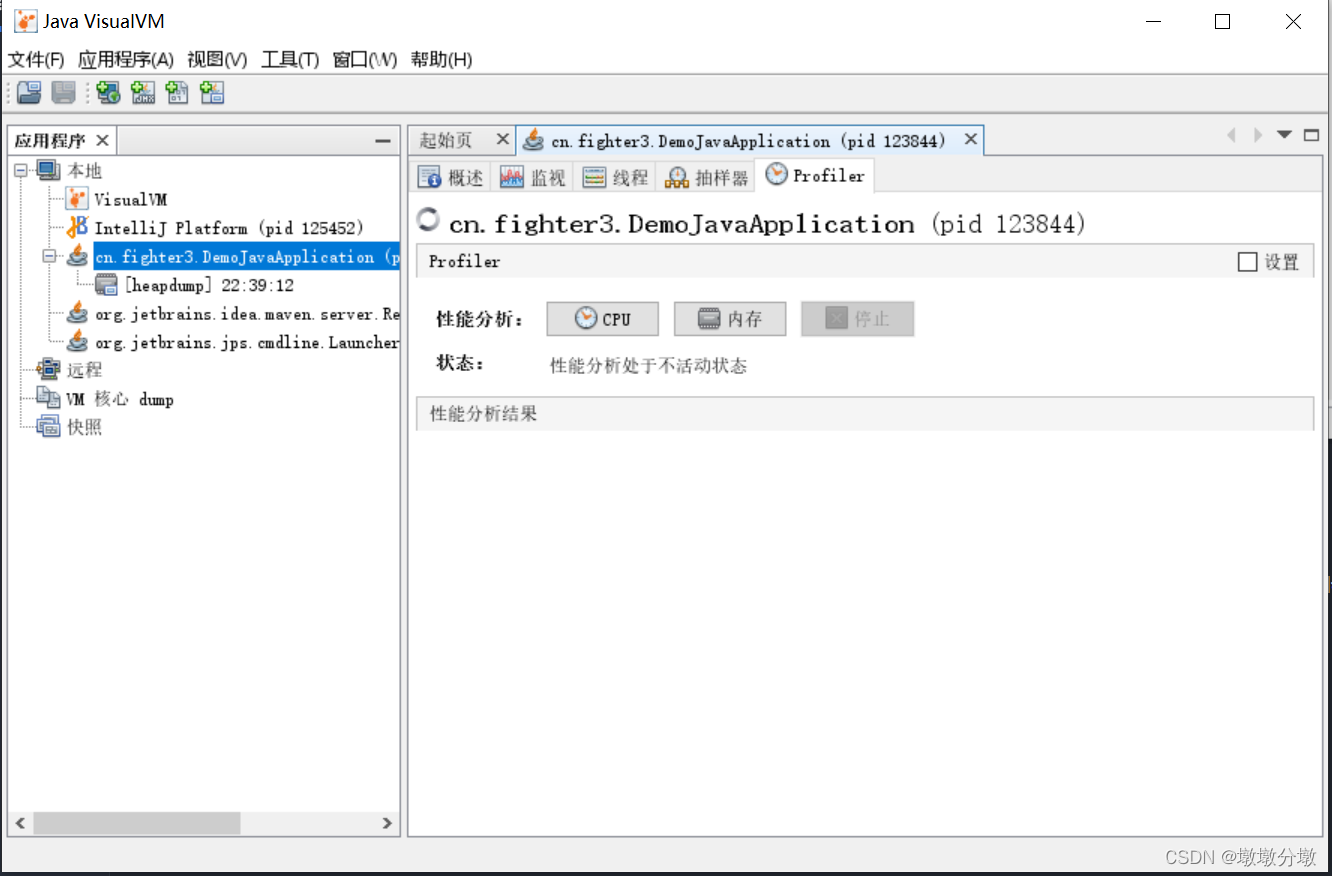
3.分析程序性能
性能分析,先选择“CPU”和“内存”按钮中的一个,然后切换到应用程序中对程序进行操作,VisualVM会记录这段时间中应用程序执行过的所有方法
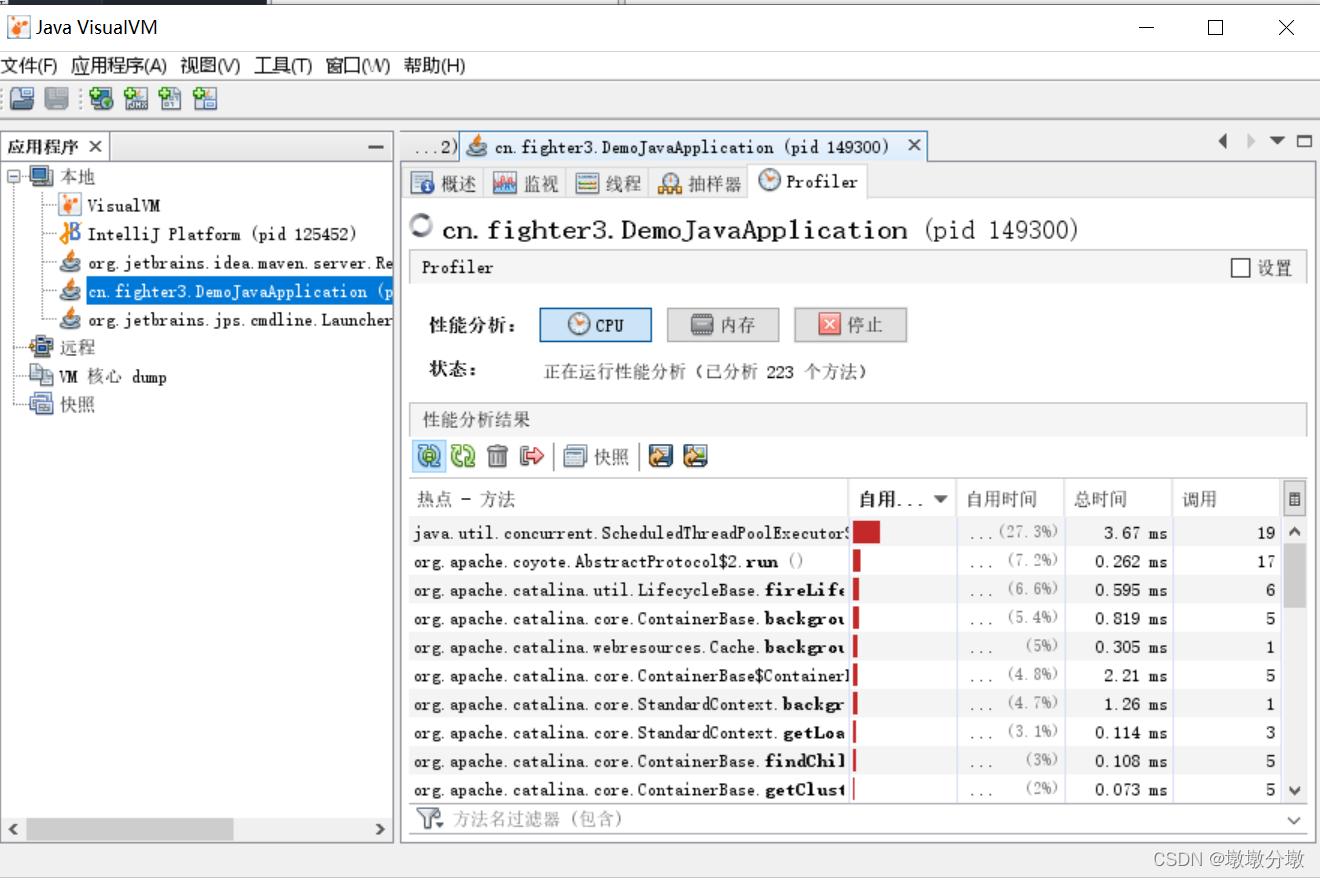
如果是CPU执行时间分析,将会统计每个方法的执行次数、执行耗时;
如果是内存分析,则会统计每个方法关联的对象数以及这些对象所占的空间。
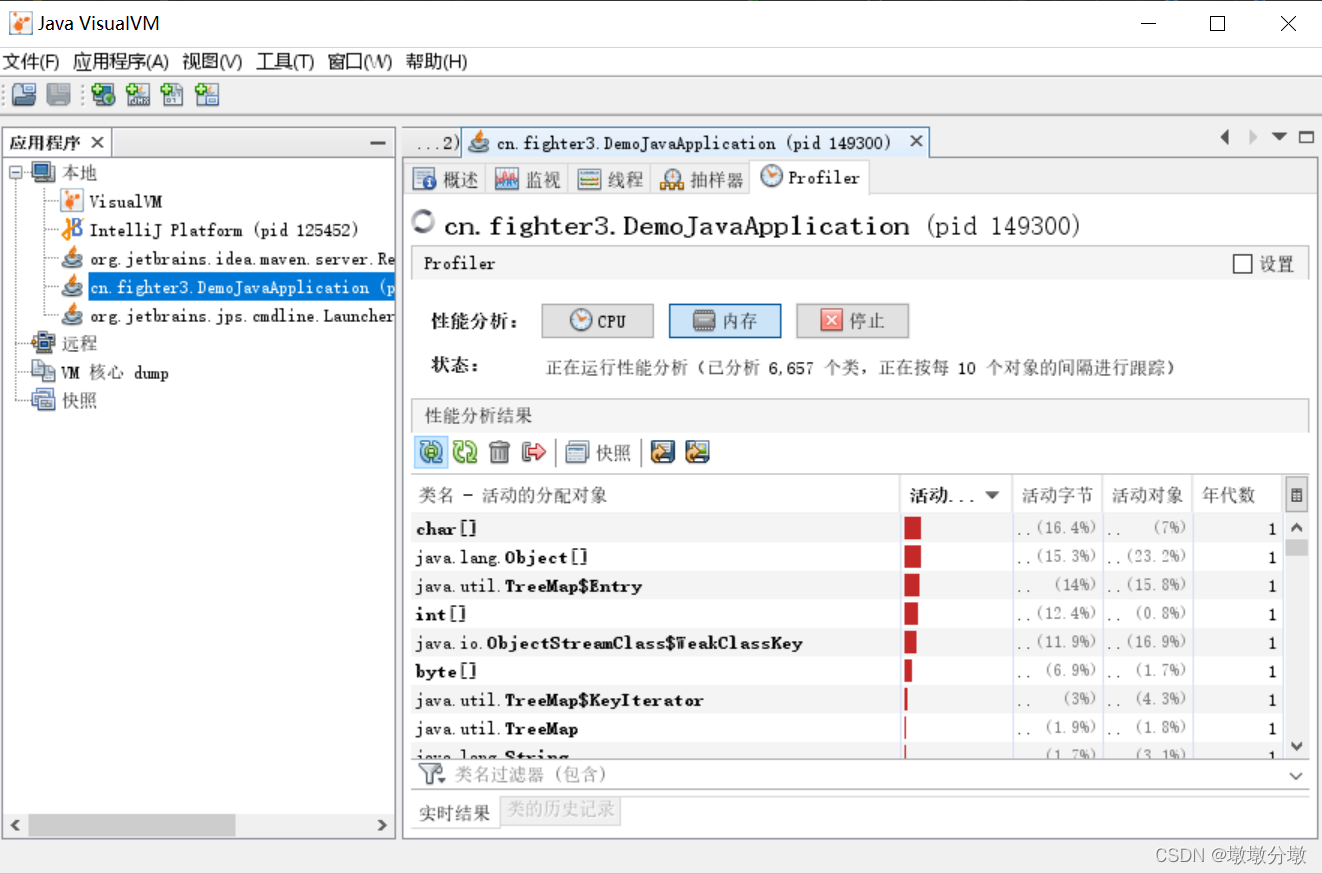
等要分析的操作执行结束后,点击“停止”按钮结束监控过程。
4.BTrace动态日志跟踪
BTrace是个很有意思的插件,它可以在不停机的情况下,通过字节码注入动态监控系统的运行情况。
-
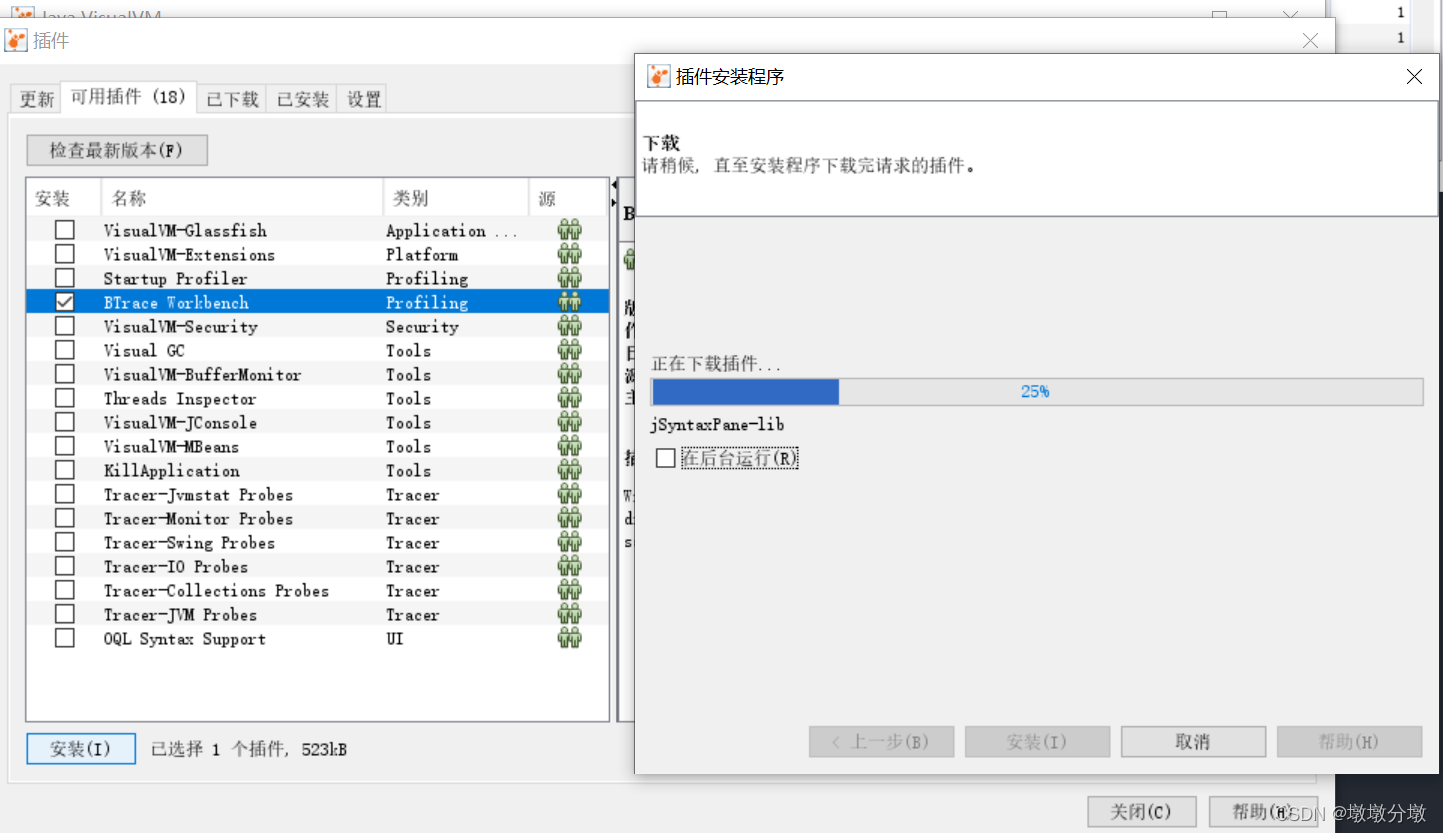
Btrace自动安装如下,到github的网络可能存在不稳定的问题,可以重试,或者手动安装
-
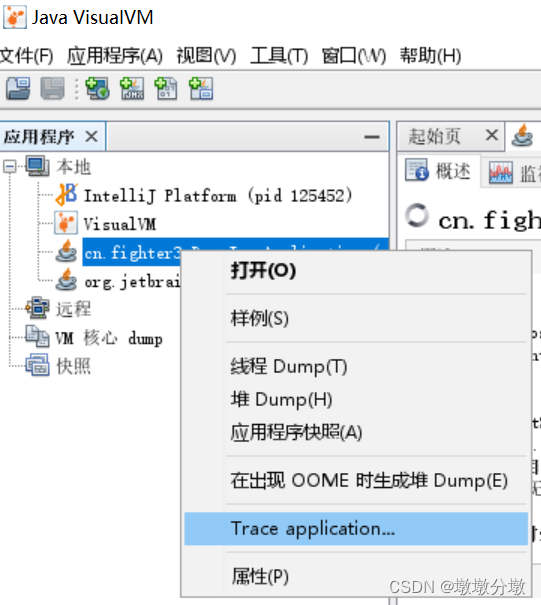
安装BTrace插件后,
右击要调试的程序,会出现“Trace Application…”菜单:
点击将进入BTrace。这个面板看起来就像一个简单的Java程序开发环境: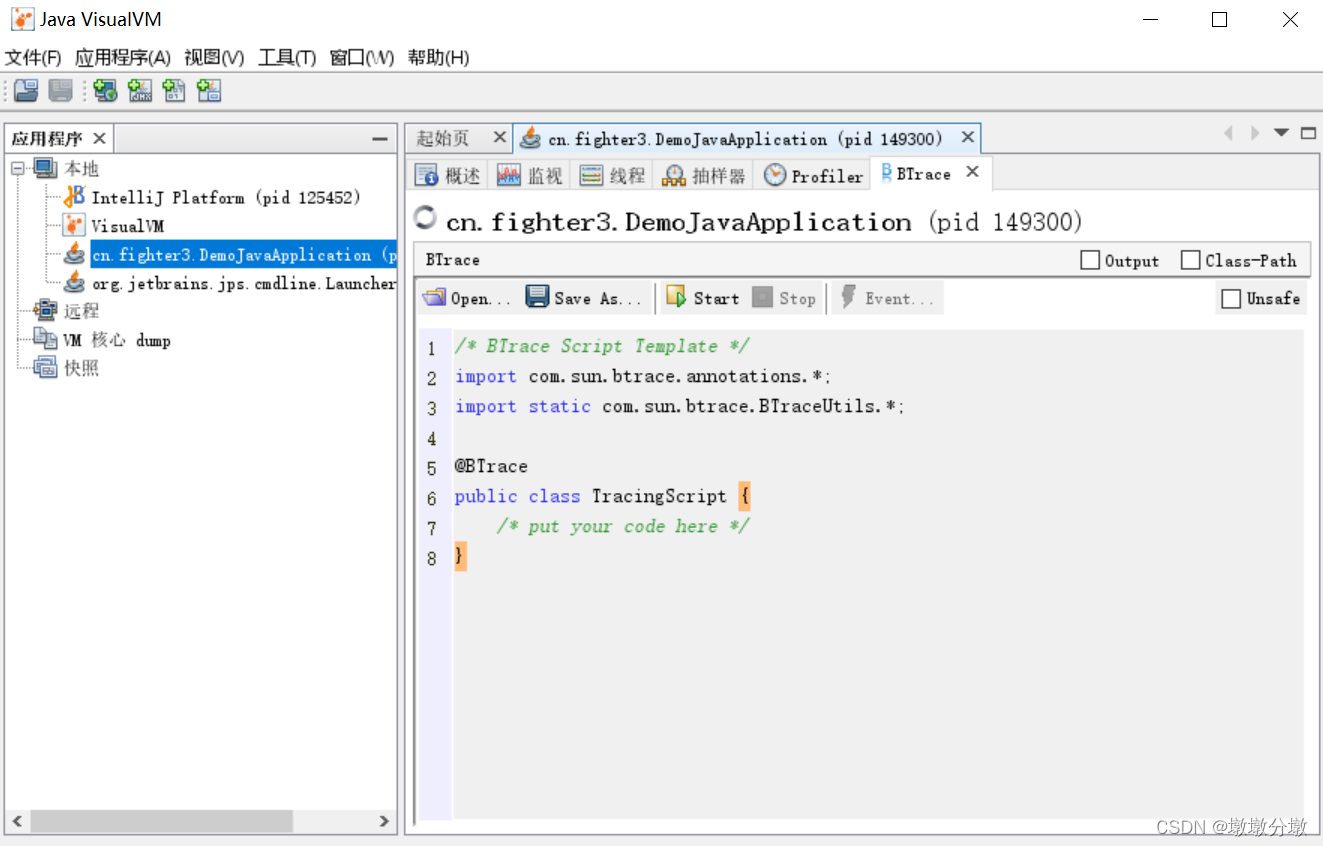
现在来尝试使用BTrace追踪正在运行的程序。- 一段简单的Java代码:产生两个1000以内的随机整数,输出这两个数字相加的结果。
public class BTraceTest {public int add(int a, int b) {return a + b;}public static void main(String[] args) throws IOException {BTraceTest test = new BTraceTest();BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));for (int i = 0; i < 10; i++) {reader.readLine();int a = (int) Math.round(Math.random() * 1000);int b = (int) Math.round(Math.random() * 1000);System.out.println(test.add(a, b));}}
}
运行程序,现在需要在不停止程序的情况下,监控程序中生成的两个随机数。在VisualVM中打开该程序的监视,在BTrace页签填充TracingScript的内容,输入调试代码:
/* BTrace Script Template */
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;@BTrace
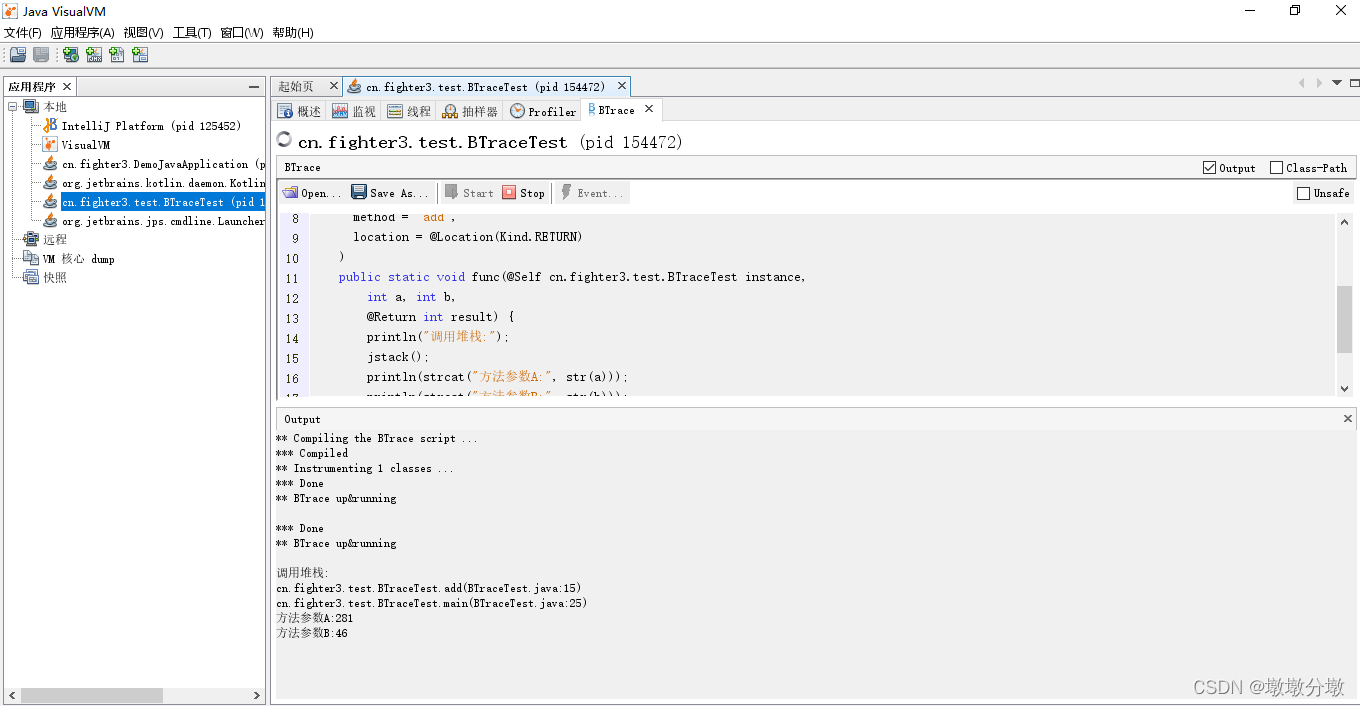
public class TracingScript {@OnMethod(clazz = "cn.fighter3.test.BTraceTest", method = "add", location = @Location(Kind.RETURN))public static void func(@Self cn.fighter3.test.BTraceTest instance, int a, int b,@Return int result) {println("调用堆栈:");jstack();println(strcat("方法参数A:", str(a)));println(strcat("方法参数B:", str(b)));println(strcat("方法结果:", str(result)));}
}
点击start按钮,当程序运行时将会在Output面板输出调试信息:
- BTrace的用途很广泛,
打印调用堆栈、参数、返回值只是它最基础的使用形式,更多应用可以查看官方仓库
3.3.Java Mission Control
JMC最初是JRockit虚拟机提供的一款诊断工具。在Oracle JDK7 Update 40以后,它就绑定在Oracle JDK中发布。
- JMC位置
%JAVA_HOME%/bin/jmc.exe,打开软件界面:
- 在左侧的“
JVM浏览器”面板中自动显示了通过JDP协议(Java Discovery Protocol)找到的本机正在运行的HotSpot虚拟机进程。
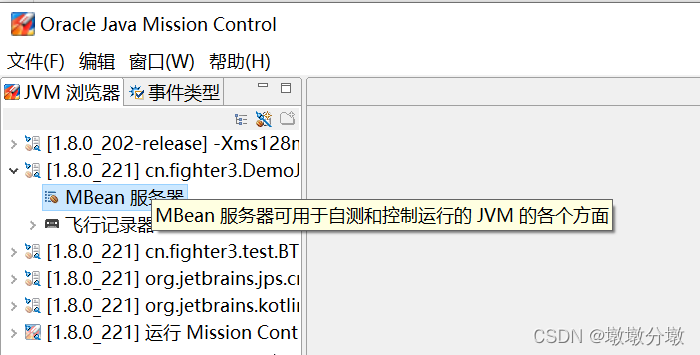
1.MBean服务器
点击本地进程的MBean服务器:
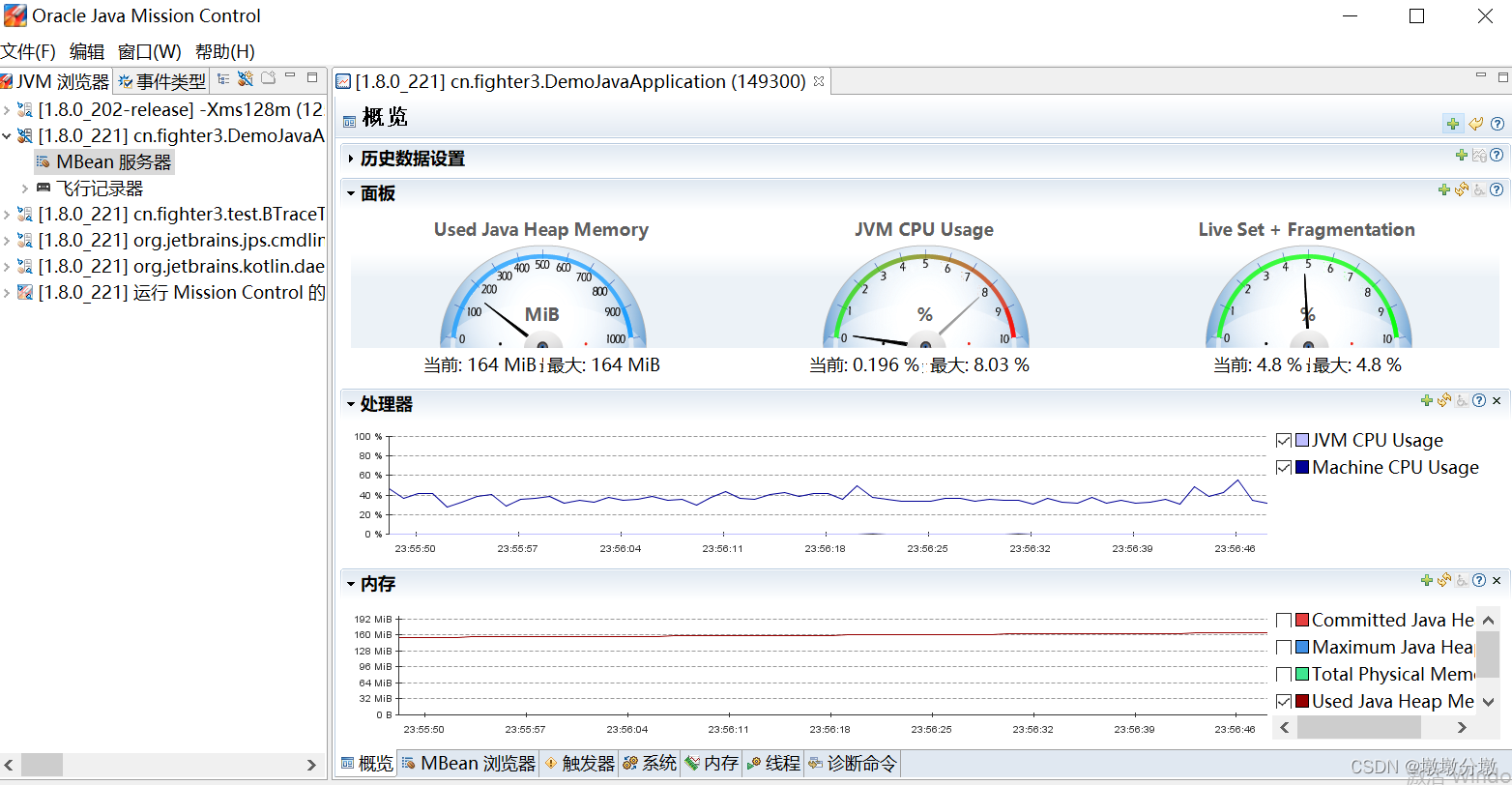
可以看到,以飞行仪表的视图显示了Java堆使用率,CPU使用率和 Live Set+Fragmentation。
2.飞行记录器(Flight Recorder)
-
飞行记录器它通过
记录程序在一段时间内的运行情况,将记录结果进行分析和展示,可以更进一步对系统的性能进行分析和诊断。-
要使用JFR,程序启动需要带以下参数:
-XX:+UnlockCommercialFeatures -XX:+FlightRecorder
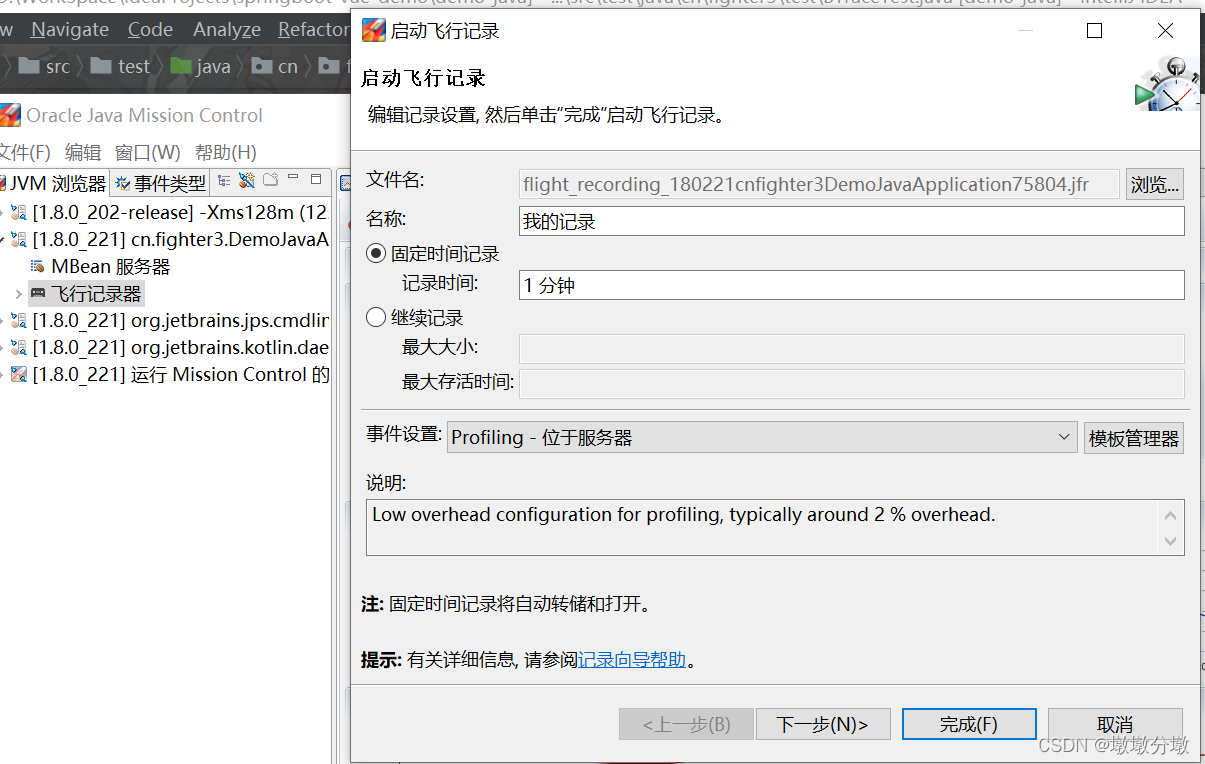
-
连接加了相关参数启动的程序,启动飞行记录,进行一分钟的性能记录:
记录结束后,JMC会自动打开刚才的记录:
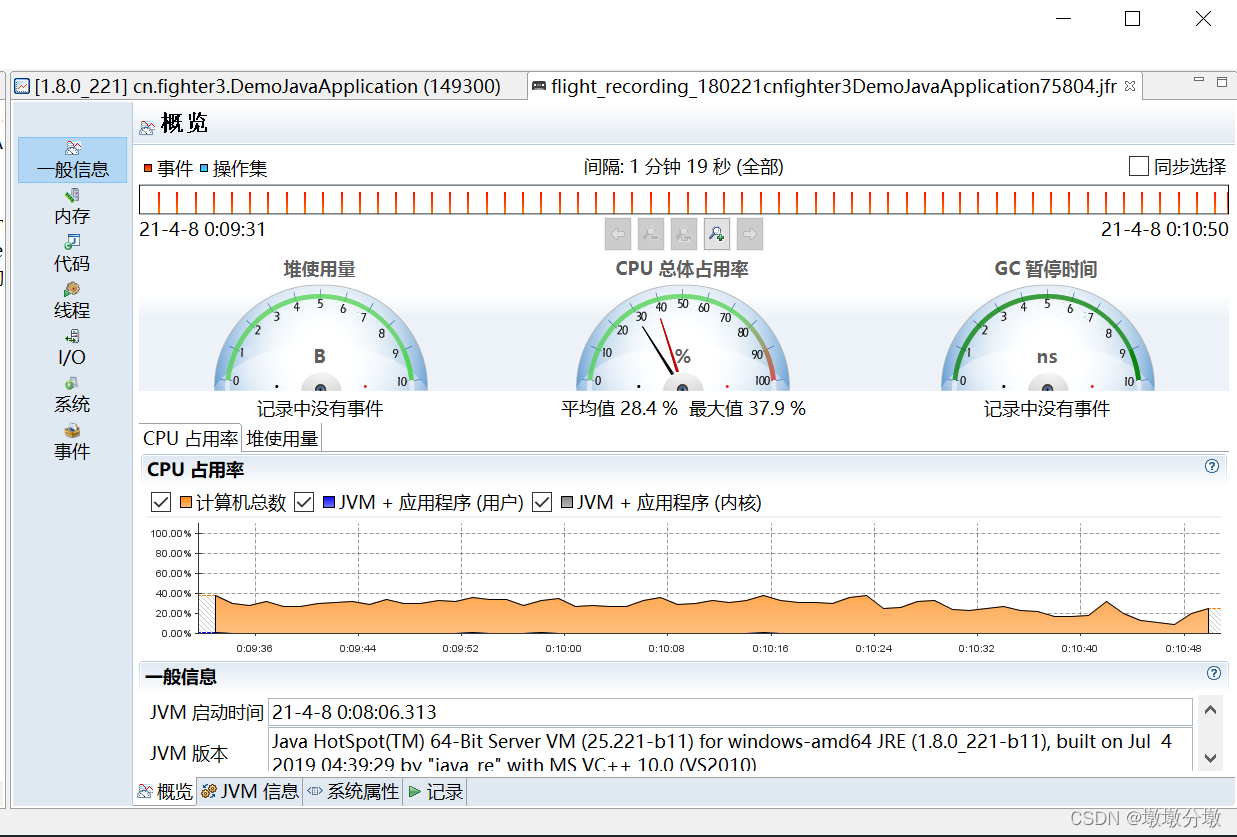
JFR提供的数据质量通常也要比其他工具通过代理形式采样获得或者从MBean中取得的数据高得多。
- 以垃圾收集为例,HotSpot的MBean中一般有
各个分代大小、收集次数、时间、占用率等数据(根据收集器不同有所差别),这些都属于“结果”类的信息- 而JFR中还可以看到内存中这段时间
分配了哪些对象、哪些在TLAB中(或外部)分配、分配速率 和压力大小如何、分配归属的线程、收集时对象分代晋升的情况等。
- 而JFR中还可以看到内存中这段时间
4.第三方工具
以上三个都是JDK自带的性能监控工具,除此之外还有一些第三方的性能监控工具。
-
MAT:Java 堆内存分析工具。
-
GChisto:GC 日志分析工具。
-
GCViewer:GC 日志分析工具。
GC日志可视化分析工具GCeasy和GCViewer
-
JProfiler:商用的性能分析利器。
-
arthas:阿里开源诊断工具。
-
async-profiler:Java 应用性能分析工具,开源、火焰图、跨平台。