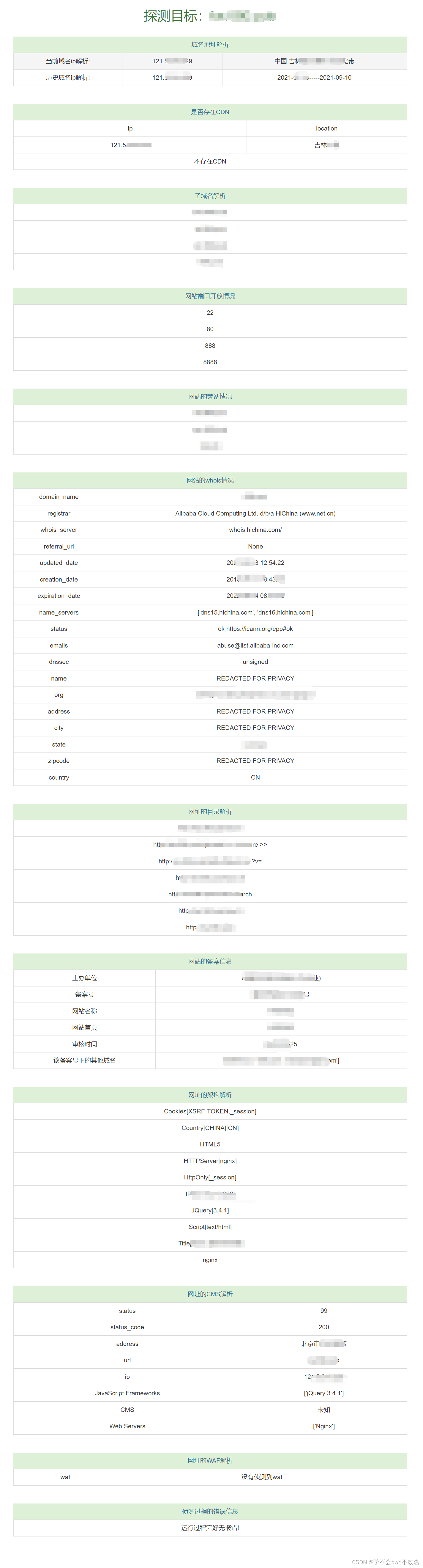
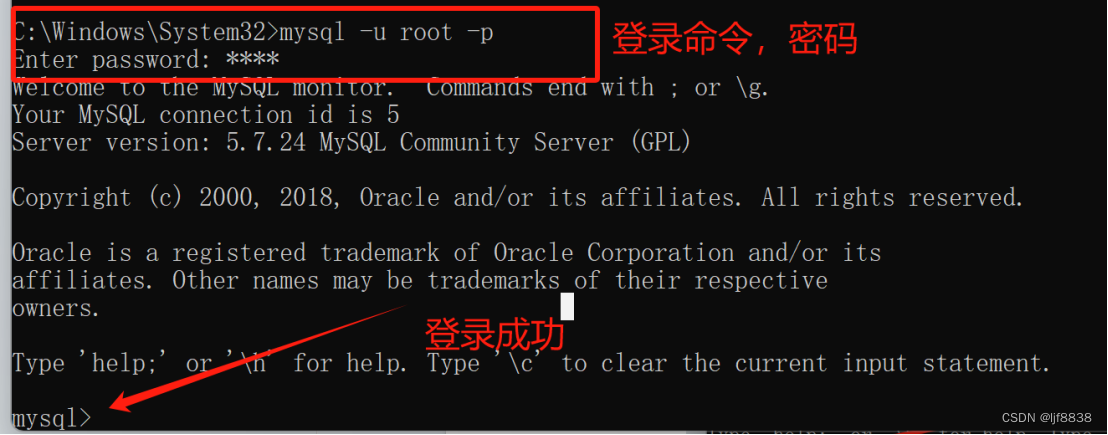
Lecture 5: Monte Carlo Learning
The simplest MC-based RL algorithm: MC Basic
理解MC basic算法的关键是理解如何将policy iteration算法迁移到model-free的条件下。
Policy iteration算法在每次迭代过程中有两步:
{ Policy evaluation: v π k = r π k + γ P π v π k Policy improvement: π k + 1 = argmax π ( r π + γ P π v π k ) \begin{cases} \text{Policy evaluation: } \mathbf{v}_{\pi_k} = \mathbf{r}_{\pi_k} +\gamma \mathbf{P}_{\pi} \mathbf{v}_{\pi_k} \\ \text{Policy improvement: } \mathbf{\pi}_{k+1} = \text{argmax}_{\pi} (\mathbf{r}_{\pi} + \gamma \mathbf{P}_{\pi} \mathbf{v}_{\pi_k}) \end{cases} {Policy evaluation: vπk=rπk+γPπvπkPolicy improvement: πk+1=argmaxπ(rπ+γPπvπk)
Policy improvement阶段的元素表现形式为:
π k + 1 ( s ) = argmax π ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) ] = argmax π ∑ a π ( a ∣ s ) q π k ( s , a ) \begin{align*} \pi_{k+1}(s) &= \text{argmax}_{\pi} \sum_a \pi(a | s) \left[ \sum_r p(r | s, a) + \gamma \sum_{s'}p(s' | s, a) v_{\pi_k}(s') \right] \\ &= \text{argmax}_{\pi} \sum_a \pi(a | s)q_{\pi_k}(s, a) \end{align*} πk+1(s)=argmaxπa∑π(a∣s)[r∑p(r∣s,a)+γs′∑p(s′∣s,a)vπk(s′)]=argmaxπa∑π(a∣s)qπk(s,a)
其中,关键是 q π k ( s , a ) q_{\pi_k}(s, a) qπk(s,a)。
action value 的两种表达形式:
Expression 1: model-based 方法
q π k ( s , a ) = ∑ r p ( r ∣ s , a ) + γ ∑ s ′ p ( s ′ ∣ s , a ) v π k ( s ′ ) q_{\pi_k}(s, a) = \sum_r p(r | s, a) + \gamma \sum_{s'}p(s' | s, a) v_{\pi_k}(s') qπk(s,a)=r∑p(r∣s,a)+γs′∑p(s′∣s,a)vπk(s′)
Expression 2: model-free方法
q π k ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_{\pi_k}(s, a) = \mathbb{E}[G_t | S_t = s, A_t = a] qπk(s,a)=E[Gt∣St=s,At=a]
因此,对于model-free的RL算法,可以直接利用数据(samples或experiences)使用expression 2的方法计算 q π k ( s , a ) q_{\pi_k}(s, a) qπk(s,a)。
action values的Monte Carlo estimation步骤:
-
从 ( s , a ) (s, a) (s,a)开始,按照policy π k \pi_k πk,生成一个episode。
-
计算episode的return g ( s , a ) g(s, a) g(s,a)
-
对不同的 g ( s , a ) g(s, a) g(s,a)采用,计算 G t G_t Gt
q π k ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_{\pi_k}(s, a) = \mathbb{E}[G_t | S_t = s, A_t = a] qπk(s,a)=E[Gt∣St=s,At=a] -
假设已经获得一个episode集合,那么即拥有 { g ( j ) ( s , a ) } \{ g^{(j)}(s, a) \} {g(j)(s,a)},则
q π k ( s , a ) = E [ G t ∣ S t = s , A t = a ] ≈ 1 N ∑ i = 1 N g ( j ) ( s , a ) q_{\pi_k}(s, a) = \mathbb{E}[G_t | S_t = s, A_t = a] \approx \frac{1}{N} \sum_{i=1}^N g^{(j)}(s, a) qπk(s,a)=E[Gt∣St=s,At=a]≈N1i=1∑Ng(j)(s,a)
上述算法的基本理念是:当model不可获得时,可以使用data。
MC Basic algorithm:
对于给定的初始policy π 0 \pi_0 π0,在第 k k k次迭代中,有两个主要的步骤
step 1: policy evaluation。对所有的 ( s , a ) (s, a) (s,a)获取 q π k ( s , a ) q_{\pi_k}(s, a) qπk(s,a) 。具体来说,对每一个action-state对,运行得到无限数量(或足够多)的episode。它们的平均return即是 q π k ( s , a ) q_{\pi_k}(s, a) qπk(s,a)的估计。
step 2: policy improvement。对所有 s ∈ S s \in \mathcal{S} s∈S,计算 π k + 1 ( s ) = argmax π ∑ a π ( a ∣ s ) q π k ( s , a ) \pi_{k+1}(s) = \text{argmax}_{\pi} \sum_a \pi(a | s)q_{\pi_k}(s, a) πk+1(s)=argmaxπ∑aπ(a∣s)qπk(s,a)。当 a k ∗ = argmax a q π k ( s , a ) a^*_k = \text{argmax}_a q_{\pi_k}(s,a) ak∗=argmaxaqπk(s,a)时,贪心optimal policy为 π k + 1 ( a k ∗ ∣ s ) = 1 \pi_{k+1}(a^*_k|s)=1 πk+1(ak∗∣s)=1。
注意,MC Basic算法与policy iteration算法是一致的,除了:
MC Basic算法直接估计 q π k ( s , a ) q_{\pi_k}(s, a) qπk(s,a)而不是计算 v π k ( s ) v_{\pi_k}(s) vπk(s)

- MC Basic是policy iteration算法的一种变体。
- model-free算法是在model-based算法的基础上建立的。 因此,在研究model-free算法之前,有必要先了解model-based算法
- MC Basic对于揭示基于 MC 的model-free强化学习的核心思想很有用,但由于效率低而不实用。
- 为什么 MC Basic 估计的是action value 而不是state value? 这是因为state value不能直接用来改进policy。 当模型不可用时,应该直接估计action value。
- 由于policy iteration是收敛的,因此在给定足够的episode的情况下,MC Basic也保证是收敛的。
Example:

Task:上图展示的是初始policy,使用MC Basic算法寻找最优policy。
r boundary = − 1 r_{\text{boundary}} = -1 rboundary=−1, r forbidden = − 1 r_{\text{forbidden}} = -1 rforbidden=−1, r target = 1 r_\text{target}=1 rtarget=1, γ = 0.9 \gamma=0.9 γ=0.9
Outline:对于给定的policy π k \pi_k πk
step 1:policy evaluation。计算 q π k ( s , a ) q_{\pi_k}(s,a) qπk(s,a)。共有
9 states × 5 actions = 45 state-action pairs 9 \text{ states} × 5 \text{ actions} =45 \text{ state-action pairs} 9 states×5 actions=45 state-action pairs
step2: policy improvement。贪心的选择action
a ∗ ( s ) = argmax a i q π k ( s , a ) a^*(s) = \text{argmax}_{a_i}q_{\pi_k}(s, a) a∗(s)=argmaxaiqπk(s,a)
以计算 q π k ( s 1 , a ) q_{\pi_k}(s_1, a) qπk(s1,a)为例:
step 1: policy evaluation。
-
由于当前的policy是确定性的,一个episode就足以得到action value。
-
如果当前policy是随机的,则需要无限数量的episode(或至少许多)。
-
从 ( s 1 , a 1 ) (s_1, a_1) (s1,a1)开始,episode是 s 1 → a 1 s 1 → a 1 s 1 → a 1 ⋯ s_1 \xrightarrow[]{a_1} s_1 \xrightarrow[]{a_1} s_1\xrightarrow[]{a_1} \cdots s1a1s1a1s1a1⋯,action value为:
q π 0 ( s 1 , a 1 ) = − 1 + γ ( − 1 ) + γ 2 ( − 1 ) + ⋯ q_{\pi_0}(s_1, a_1) = -1 + \gamma (-1) + \gamma^2 (-1) + \cdots qπ0(s1,a1)=−1+γ(−1)+γ2(−1)+⋯ -
从 ( s 1 , a 2 ) (s_1, a_2) (s1,a2)开始,episode是 s 1 → a 2 s 2 → a 3 s 5 → a 3 ⋯ s_1 \xrightarrow[]{a_2} s_2 \xrightarrow[]{a_3} s_5\xrightarrow[]{a_3} \cdots s1a2s2a3s5a3⋯,action value为:
q π 0 ( s 1 , a 2 ) = 0 + γ 0 + γ 2 0 + γ 3 ( 1 ) + γ 4 ( 1 ) + ⋯ q_{\pi_0}(s_1, a_2) = 0 + \gamma 0 + \gamma^2 0 + \gamma^3(1) + \gamma^4(1) + \cdots qπ0(s1,a2)=0+γ0+γ20+γ3(1)+γ4(1)+⋯ -
从 ( s 1 , a 3 ) (s_1, a_3) (s1,a3)开始,episode是 s 1 → a 3 s 4 → a 2 s 5 → a 3 ⋯ s_1 \xrightarrow[]{a_3} s_4 \xrightarrow[]{a_2} s_5\xrightarrow[]{a_3} \cdots s1a3s4a2s5a3⋯,action value为:
q π 0 ( s 1 , a 2 ) = 0 + γ 0 + γ 2 0 + γ 3 ( 1 ) + γ 4 ( 1 ) + ⋯ q_{\pi_0}(s_1, a_2) = 0 + \gamma 0 + \gamma^2 0 + \gamma^3(1) + \gamma^4(1) + \cdots qπ0(s1,a2)=0+γ0+γ20+γ3(1)+γ4(1)+⋯ -
从 ( s 1 , a 4 ) (s_1, a_4) (s1,a4)开始,episode是 s 1 → a 4 s ‘ → a 1 s 1 → a 1 ⋯ s_1 \xrightarrow[]{a_4} s_` \xrightarrow[]{a_1} s_1\xrightarrow[]{a_1} \cdots s1a4s‘a1s1a1⋯,action value为:
q π 0 ( s 1 , a 4 ) = − 1 + γ ( − 1 ) + γ 2 ( − 1 ) + ⋯ q_{\pi_0}(s_1, a_4) = -1 + \gamma (-1) + \gamma^2 (-1) + \cdots qπ0(s1,a4)=−1+γ(−1)+γ2(−1)+⋯ -
从 ( s 1 , a 5 ) (s_1, a_5) (s1,a5)开始,episode是 s 1 → a 5 s 1 → a 1 s 1 → a 1 ⋯ s_1 \xrightarrow[]{a_5} s_1 \xrightarrow[]{a_1} s_1\xrightarrow[]{a_1} \cdots s1a5s1a1s1a1⋯,action value为:
q π 0 ( s 1 , a 5 ) = 0 + γ ( − 1 ) + γ 2 ( − 1 ) + ⋯ q_{\pi_0}(s_1, a_5) = 0 + \gamma (-1) + \gamma^2 (-1) + \cdots qπ0(s1,a5)=0+γ(−1)+γ2(−1)+⋯
step 2: policy improvement。
-
通过观察action value,可得:
q π 0 ( s 1 , a 2 ) = q π 0 ( s 1 , a 3 ) q_{\pi_0}(s_1, a_2) = q_{\pi_0}(s_1, a_3) qπ0(s1,a2)=qπ0(s1,a3)
是最大的。 -
因此,policy可以被提高为:
π 1 ( a 2 ∣ s 2 ) = 1 or π 1 ( a 3 ∣ s 1 ) = 1 \pi_1(a_2 | s_2) = 1 \;\;\; \text{or} \;\;\; \pi_1(a_3 | s_1) = 1 π1(a2∣s2)=1orπ1(a3∣s1)=1
无论哪种方式, s 1 s_1 s1 的新policy都变得最优。
对于这个简单的例子来说,一次迭代就足够了!
检查episode长度的影响:
使用 MC Basic 搜索不同episode长度的最优policy。




- 当episode长度很短时,只有接近目标的state才具有非零的state value。
- 随着episode长度的增加,离target较近的state比较远的state更早具有非零值。
- episode长度应该足够长。
- episode长度不必无限长。
Use date more efficiently: MC Exploring Starts
MC Basic 算法:
- 优点:核心思想清晰可见。
- 缺点:太简单而不实用。
考虑一个grid-world的例子,遵循policy π \pi π,可以得到一个episode,例如
s 1 → a 2 s 2 → a 4 s 1 → a 2 s 2 → a 3 s 5 → a 1 ⋯ s_1 \xrightarrow[]{a_2} s_2 \xrightarrow[]{a_4} s_1 \xrightarrow[]{a_2} s_2 \xrightarrow[]{a_3} s_5 \xrightarrow[]{a_1} \cdots s1a2s2a4s1a2s2a3s5a1⋯
visit:每次state-action对出现在episode中,就称为该state-action对的访问
使用数据的方法:Initial-visit method
- 只计算return并估计 q π ( s 1 , a 2 ) q_{\pi}(s_1, a_2) qπ(s1,a2)
- MC Basic算法
- 不能充分利用数据
episode也visit其他state-action对

其可以估计 q π ( s 1 , a 2 ) q_{\pi}(s_1, a_2) qπ(s1,a2), q π ( s 2 , a 4 ) q_{\pi}(s_2, a_4) qπ(s2,a4), q π ( s 2 , a 3 ) q_{\pi}(s_2, a_3) qπ(s2,a3), q π ( s 5 , a 1 ) q_{\pi}(s_5, a_1) qπ(s5,a1), ⋯ \cdots ⋯
Data-efficient方法:
- first-visit方法
- every-visit方法
基于 MC 的 RL 的另一个方面是何时更新policy。 有两种方法:
-
第一种方法是,在policy evaluation步骤中,收集从state-action对开始的所有episode,然后使用平均return来近似action value。
- 这是MC Basic算法采用的
- 这种方法的问题是agent必须等到所有episodes都收集完毕。
-
第二种方法使用单个episode的return来近似action value。
这样就可以episode-by-episode完善policy。
对第二种方法分析:
- 也许,单episode的return并不能准确地近似对应的action value。
- 但是,在上一章介绍的truncated policy iteration算法中已经做到了这一点。
Generalized policy iteration:
- 不是一个特定的算法
- 它是指policy-evaluation和policy-improvement过程之间切换的总体思路或框架。
- 许多model-based和model-free的强化学习算法都属于这个框架。
如果想要更有效地使用数据和更新估计,就可以得到一种称为 MC Exploring Starts 的新算法:

What is exploring starts?
- Exploring starts意味着我们需要从每个state-action对开始生成足够多的episode。
- MC Basic 和 MC Exploring Starts 都需要这个假设。
Why do we need to consider exploring starts?
- 理论上,只有充分探索每个state的每个action value,才能正确选择最优动作。
相反,如果没有探索某个action,则该action可能恰好是最佳action,因此会被错过。 - 在实践中,exploring starts是很难实现的。 对于许多应用程序,尤其是那些涉及与环境的物理交互的应用程序,很难从每个state-action对开始收集episode。
因此理论与实践存在差距!
那么可以取消exploring starts的要求吗? 接下来将展示可以通过使用soft policy来做到这一点。
MC without exploring starts: MC ε \varepsilon ε-Greedy
如果采取任何action的概率为正,则policy被称为soft policy。
Why introduce soft policies?
- 通过soft policy,一些足够长的episode可以访问每个state-action对足够多次。
- 然后,不需要从每个state-action对开始都有大量的episode。 因此,可以消除exploring starts的要求。
ε \varepsilon ε-greedy policies
π ( a ∣ s ) = { 1 − ε ∣ A ( s ) ∣ ( ∣ A ( s ) ∣ − 1 ) for the greedy action ε ∣ A ( s ) ∣ for other ∣ A ( s ) ∣ − 1 actions \pi(a|s) = \begin{cases} 1 - \frac{\varepsilon }{|\mathcal{A}(s)|}(|\mathcal{A}(s)| - 1) & \text{for the greedy action} \\ \frac{\varepsilon }{|\mathcal{A}(s)|} & \text{for other } |\mathcal{A}(s)| - 1 \text{ actions} \end{cases} π(a∣s)={1−∣A(s)∣ε(∣A(s)∣−1)∣A(s)∣εfor the greedy actionfor other ∣A(s)∣−1 actions
其中, ε ∈ [ 0 , 1 ] \varepsilon \in [0, 1] ε∈[0,1]并且 A ( s ) \mathcal{A}(s) A(s)是 s s s的action的数量。
选择贪婪action的机会总是大于其他action。因为:
1 − ε ∣ A ( s ) ∣ ( ∣ A ( s ) ∣ − 1 ) = 1 − ε + ε ∣ A ( s ) ∣ ≥ ε ∣ A ( s ) ∣ 1 - \frac{\varepsilon }{|\mathcal{A}(s)|}(|\mathcal{A}(s)| - 1) = 1 - \varepsilon + \frac{\varepsilon }{|\mathcal{A}(s)|} \ge \frac{\varepsilon }{|\mathcal{A}(s)|} 1−∣A(s)∣ε(∣A(s)∣−1)=1−ε+∣A(s)∣ε≥∣A(s)∣ε
Why use ε-greedy?
平衡利用(exploitation)与探索(exploration)。
- 当 ε = 0 \varepsilon = 0 ε=0时,变得贪婪。更少的探索(exploration),更多的利用(exploitation)。
- 当 ε = 1 \varepsilon = 1 ε=1时,变为均匀分布。更多探索(exploration),更少利用(exploitation)。
How to embed ε − \varepsilon - ε−greedy into the MC-based RL algorithms?
原本,MC Basic 和 MC Exploring Starts 中的policy improvement步骤是为了解决:
π k + 1 ( s ) = argmax x ∈ Π ∑ a π ( a ∣ s ) q π k ( s , a ) \pi_{k+1}(s) = \text{argmax}_{x \in \Pi} \sum_a \pi(a | s)q_{\pi_k}(s, a) πk+1(s)=argmaxx∈Πa∑π(a∣s)qπk(s,a)
其中, Π \Pi Π代表所有可能的policy。其中,最优的policy为:
π k + 1 ( a ∣ s ) = { 1 a = a k ∗ 0 a ≠ s k ∗ \pi_{k+1}(a | s) = \begin{cases} 1 & a = a^*_k\\ 0 & a \ne s^*_k \end{cases} πk+1(a∣s)={10a=ak∗a=sk∗
其中, a k ∗ = argmax a q π k ( s , a ) a^*_k = \text{argmax}_a q_{\pi_k}(s, a) ak∗=argmaxaqπk(s,a)。
现在,policy improvement步骤改变为计算:
π k + 1 ( s ) = argmax x ∈ Π ε ∑ a π ( a ∣ s ) q π k ( s , a ) \pi_{k+1}(s) = \text{argmax}_{x \in \Pi_\varepsilon } \sum_a \pi(a | s)q_{\pi_k}(s, a) πk+1(s)=argmaxx∈Πεa∑π(a∣s)qπk(s,a)
其中, Π ε \Pi_\varepsilon Πε 表示所有具有固定值 ε \varepsilon ε 的 ε \varepsilon ε-greedy policy的集合。
最优的policy为:
π k + 1 ( a ∣ s ) = { 1 − ε ∣ A ( s ) ∣ ( ∣ A ( s ) ∣ − 1 ) a = a k ∗ ε ∣ A ( s ) ∣ a ≠ a k ∗ \pi_{k+1}(a|s) = \begin{cases} 1 - \frac{\varepsilon }{|\mathcal{A}(s)|}(|\mathcal{A}(s)| - 1) & a = a^*_k \\ \frac{\varepsilon }{|\mathcal{A}(s)|} & a \ne a^*_k \end{cases} πk+1(a∣s)={1−∣A(s)∣ε(∣A(s)∣−1)∣A(s)∣εa=ak∗a=ak∗
- MC ε \varepsilon ε-Greedy 与 MC Exploring Starts 相同,只是前者使用 $\varepsilon $-greedy 策略。
- 它不需要exploring starts,但仍然需要以不同的形式访问所有state-action对。

Can a single episode visit all state-action pairs?
当 ε \varepsilon ε=1时,policy(均匀分布)的探索能力最强。

当 ε \varepsilon ε较小时,策略的探索能力也较小。

Compared to greedy policies:
- 优点是 ε \varepsilon ε-greedy policy的具有更强的探索能力,因此不需要exploring starts条件。
- 缺点是 ε \varepsilon ε-greedy policy一般来说不是最优的(我们只能证明总是存在最优的greedy policy)。
- MC ε \varepsilon ε-greedy算法给出的最终policy仅在所有 ε \varepsilon ε-greedy policy的集合 Π ε \Pi_\varepsilon Πε中是最优的。
- ε \varepsilon ε不能太大
Example:
r boundary = − 1 r_{\text{boundary}} = -1 rboundary=−1, r forbidden = − 10 r_{\text{forbidden}}=-10 rforbidden=−10, r target = 1 r_{\text{target}} = 1 rtarget=1, γ = 0.9 \gamma=0.9 γ=0.9。


当 ε \varepsilon ε增大时,policy的最优性能变得更差!最优 ε \varepsilon ε-greedy policy与greedy policy不一致。
Summary
- Mean estimation by the Monte Carlo methods
- Three algorithms:
- MC Basic
- MC Exploring Starts
- MC ε \varepsilon ε-Greedy
- Relationship among the three algorithms
- Optimality vs exploration of ε \varepsilon ε-greedy policies
以上内容为B站西湖大学智能无人系统 强化学习的数学原理 公开课笔记。