一、上章原理回顾
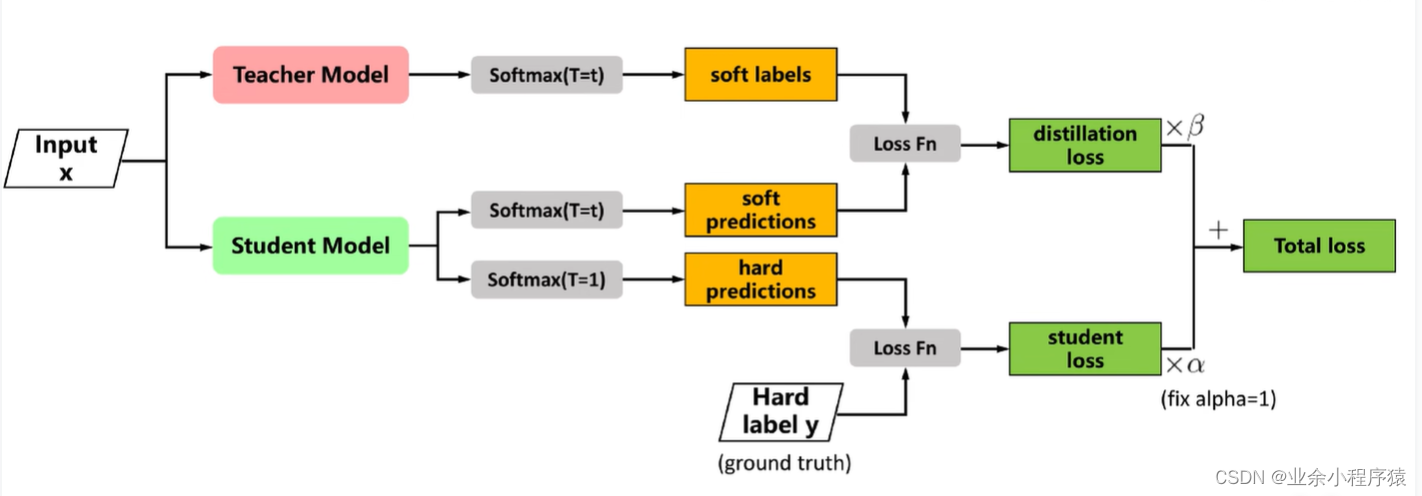
具体过程:
(1)首先我们要先训练出较大模型既teacher模型。(在图中没有出现)
(2)再对teacher模型进行蒸馏,此时我们已经有一个训练好的teacher模型,所以我们能很容易知道teacher模型输入特征x之后,预测出来的结果teacher_preds标签。
(3)此时,求到老师预测结果之后,我们需要求解学生在训练过程中的每一次结果student_preds标签。
(4)先求hard_loss,也就是学生模型的预测student_preds与真实标签targets之间的损失。
(5)再求soft_loss,也就是学生模型的预测student_preds与教师模型teacher_preds的预测之间的损失。
(6)求出hard_loss与soft_loss之后,求和总loss=a*hard_loss + (1-a)soft_loss,a是一个自己设置的权重参数,我在代码中设置为a=0.3。
(7)最后反向传播继续迭代。
二、代码实现
1、数据集
数据集采用的是手写数字的数据集mnist数据集,如果没有下载,代码部分中会进行下载,只需要把download改成True,然后就会保存在当前目录中。该数据集将其分成80%的训练集,20%的测试集,最后返回train_dataset和test_datatset。
class MyDataset(Dataset):def __init__(self,opt):self.opt = optdef MyData(self):## mnist数据集下载0mnist = datasets.MNIST(root='../datasets/', train=True, download=False, transform=transforms.Compose([transforms.Resize(self.opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),)dataset_size = len(mnist)train_size = int(0.8 * dataset_size)test_size = dataset_size - train_sizetrain_dataset, test_dataset = random_split(mnist, [train_size, test_size])train_dataloader = DataLoader(train_dataset,batch_size=self.opt.batch_size,shuffle=True,)test_dataloader = DataLoader(test_dataset,batch_size=self.opt.batch_size,shuffle=False, # 在测试集上不需要打乱顺序)return train_dataloader,test_dataloader2、teacher模型和训练实现
(1) 首先是teacher模型构造,经过三次线性层。
import torch.nn as nn
import torchimg_area = 784class TeacherModel(nn.Module):def __init__(self,in_channel=1,num_classes=10):super(TeacherModel,self).__init__()self.relu = nn.ReLU()self.fc1 = nn.Linear(img_area,1200)self.fc2 = nn.Linear(1200, 1200)self.fc3 = nn.Linear(1200, num_classes)self.dropout = nn.Dropout(p=0.5)def forward(self, x):x = x.view(-1, img_area)x = self.fc1(x)x = self.dropout(x)x = self.relu(x)x = self.fc2(x)x = self.dropout(x)x = self.relu(x)x = self.fc3(x)return x(2)训练teacher模型
老师模型训练完成后其权重参数会保存在teacher.pth当中,为以后调用。
import torch.nn as nn
import torch## 创建文件夹
from tqdm import tqdmfrom dist.TeacherModel import TeacherModelweight_path = 'C:/Users/26394/PycharmProjects/untitled1/dist/params/teacher.pth'
## 设置cuda:(cuda:0)
cuda = True if torch.cuda.is_available() else False
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')torch.backends.cudnn.benchmark = True #使用卷积cuDNN加速class TeacherTrainer():def __init__(self,opt,train_dataloader,test_dataloader):self.opt = optself.train_dataloader = train_dataloaderself.test_dataloader = test_dataloaderdef trainer(self):# 老师模型opt = self.opttrain_dataloader = self.train_dataloadertest_dataloader = self.test_dataloaderteacher_model = TeacherModel()teacher_model = teacher_model.to(device)criterion = nn.CrossEntropyLoss()optimizer_teacher = torch.optim.Adam(teacher_model.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))for epoch in range(opt.n_epochs): ## epoch:50teacher_model.train()for data, targets in tqdm(train_dataloader):data = data.to(device)targets = targets.to(device)preds = teacher_model(data)loss = criterion(preds, targets)optimizer_teacher.zero_grad()loss = criterion(preds, targets)loss.backward()optimizer_teacher.step()teacher_model.eval()num_correct = 0num_samples = 0with torch.no_grad():for x, y in test_dataloader:x = x.to(device)y = y.to(device)preds = teacher_model(x)predictions = preds.max(1).indicesnum_correct += (predictions == y).sum()num_samples += predictions.size(0)acc = (num_correct / num_samples).item()torch.save(teacher_model.state_dict(), weight_path)teacher_model.train()print('teacher: Epoch:{}\t Accuracy:{:.4f}'.format(epoch + 1, acc))
(3)训练teacher模型
模型参数都在paras()当中设置好了,直接调用teacher_model就行,然后将其权重参数会保存在teacher.pth当中。
import argparseimport torchfrom dist.DistillationTrainer import DistillationTrainer
from dist.MyDateLoader import MyDataset
from dist.TeacherTrainer import TeacherTrainerdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def paras():## 超参数配置parser = argparse.ArgumentParser()parser.add_argument("--n_epochs", type=int, default=5, help="number of epochs of training")parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")parser.add_argument("--n_cpu", type=int, default=2, help="number of cpu threads to use during batch generation")parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")parser.add_argument("--channels", type=int, default=1, help="number of image channels")parser.add_argument("--sample_interval", type=int, default=500, help="interval betwen image samples")opt = parser.parse_args()## opt = parser.parse_args(args=[]) ## 在colab中运行时,换为此行print(opt)return optif __name__ == '__main__':opt = paras()data = MyDataset(opt)train_dataloader, test_dataloader = data.MyData()# 训练Teacher模型teacher_trainer = TeacherTrainer(opt,train_dataloader,test_dataloader)teacher_trainer.trainer()3、学生模型的构建
学生模型也是经过了三次线性层,但是神经元没有teacher当中多。所以student模型会比teacher模型小很多。
import torch.nn as nn
import torchimg_area = 784class StudentModel(nn.Module):def __init__(self,in_channel=1,num_classes=10):super(StudentModel,self).__init__()self.relu = nn.ReLU()self.fc1 = nn.Linear(img_area,20)self.fc2 = nn.Linear(20, 20)self.fc3 = nn.Linear(20, num_classes)def forward(self, x):x = x.view(-1, img_area)x = self.fc1(x)# x = self.dropout(x)x = self.relu(x)x = self.fc2(x)# x = self.dropout(x)x = self.relu(x)x = self.fc3(x)return x4、知识蒸馏训练
(1)首先读取teacher模型。
将teacher模型中的权重参数teacher.pth放入模型当中。
#拿取训练好的模型teacher_model = TeacherModel()if os.path.exists(weights):teacher_model.load_state_dict(torch.load(weights))print('successfully')else:print('not loading')teacher_model = teacher_model.to(device)(2)设置损失求解的函数
hard_loss用的就是普通的交叉熵损失函数,而soft_loss就是用的KL散度。
# hard_losshard_loss = nn.CrossEntropyLoss()# hard_loss权重alpha = 0.3# soft_losssoft_loss = nn.KLDivLoss(reduction="batchmean")(3)之后再进行蒸馏训练,温度为7
- 先求得hard_loss就是用学生模型预测的标签和真实标签进行求得损失。
- 再求soft_loss就是用学生模型预测的标签和老师模型预测的标签进行求得损失。使用softmax时候还需要进行除以温度temp。
- 最后反向传播,求解模型
for epoch in range(opt.n_epochs): ## epoch:5for data, targets in tqdm(train_dataloader):data = data.to(device)targets = targets.to(device)# 老师模型预测with torch.no_grad():teacher_preds = teacher_model(data)# 学生模型预测student_preds = model(data)# 计算hard_lossstudent_loss = hard_loss(student_preds, targets)# 计算蒸馏后的预测损失ditillation_loss = soft_loss(F.softmax(student_preds / temp, dim=1),F.softmax(teacher_preds / temp, dim=1))loss = alpha * student_loss + (1 - alpha) * ditillation_lossoptimizer.zero_grad()loss.backward()optimizer.step()model.eval()num_correct = 0num_samples = 0with torch.no_grad():for x, y in test_dataloader:x = x.to(device)y = y.to(device)preds = model(x)predictions = preds.max(1).indicesnum_correct += (predictions == y).sum()num_samples += predictions.size(0)acc = (num_correct / num_samples).item()model.train()print('distillation: Epoch:{}\t Accuracy:{:.4f}'.format(epoch + 1, acc))(4)整个蒸馏训练代码
import torch.nn as nn
import torch
import torch.nn.functional as F
import os
from tqdm import tqdmfrom dist.StudentModel import StudentModel
from dist.TeacherModel import TeacherModelweights = 'C:/Users/26394/PycharmProjects/untitled1//dist/params/teacher.pth'# D_weight_path = 'C:/Users/26394/PycharmProjects/untitled1/dist/params/distillation.pth'
## 设置cuda:(cuda:0)
cuda = True if torch.cuda.is_available() else False
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')torch.backends.cudnn.benchmark = True #使用卷积cuDNN加速class DistillationTrainer():def __init__(self,opt,train_dataloader,test_dataloader):self.opt = optself.train_dataloader = train_dataloaderself.test_dataloader = test_dataloaderdef trainer(self):opt = self.opttrain_dataloader = self.train_dataloadertest_dataloader = self.test_dataloader#拿取训练好的模型teacher_model = TeacherModel()if os.path.exists(weights):teacher_model.load_state_dict(torch.load(weights))print('successfully')else:print('not loading')teacher_model = teacher_model.to(device)teacher_model.eval()model = StudentModel()model = model.to(device)temp = 7# hard_losshard_loss = nn.CrossEntropyLoss()# hard_loss权重alpha = 0.3# soft_losssoft_loss = nn.KLDivLoss(reduction="batchmean")optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))for epoch in range(opt.n_epochs): ## epoch:5for data, targets in tqdm(train_dataloader):data = data.to(device)targets = targets.to(device)# 老师模型预测with torch.no_grad():teacher_preds = teacher_model(data)# 学生模型预测student_preds = model(data)# 计算hard_lossstudent_loss = hard_loss(student_preds, targets)# 计算蒸馏后的预测损失ditillation_loss = soft_loss(F.softmax(student_preds / temp, dim=1),F.softmax(teacher_preds / temp, dim=1))loss = alpha * student_loss + (1 - alpha) * ditillation_lossoptimizer.zero_grad()loss.backward()optimizer.step()model.eval()num_correct = 0num_samples = 0with torch.no_grad():for x, y in test_dataloader:x = x.to(device)y = y.to(device)preds = model(x)predictions = preds.max(1).indicesnum_correct += (predictions == y).sum()num_samples += predictions.size(0)acc = (num_correct / num_samples).item()model.train()print('distillation: Epoch:{}\t Accuracy:{:.4f}'.format(epoch + 1, acc))(5)蒸馏训练的主函数
该部分大致与teacher模型训练类似,只是调用不同。
import argparseimport torchfrom dist.DistillationTrainer import DistillationTrainer
from dist.MyDateLoader import MyDataset
from dist.TeacherTrainer import TeacherTrainerdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def paras():## 超参数配置parser = argparse.ArgumentParser()parser.add_argument("--n_epochs", type=int, default=5, help="number of epochs of training")parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")parser.add_argument("--n_cpu", type=int, default=2, help="number of cpu threads to use during batch generation")parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")parser.add_argument("--channels", type=int, default=1, help="number of image channels")parser.add_argument("--sample_interval", type=int, default=500, help="interval betwen image samples")opt = parser.parse_args()## opt = parser.parse_args(args=[]) ## 在colab中运行时,换为此行print(opt)return optif __name__ == '__main__':opt = paras()data = MyDataset(opt)train_dataloader, test_dataloader = data.MyData()# 训练Teacher模型# teacher_trainer = TeacherTrainer(opt,train_dataloader,test_dataloader)# teacher_trainer.trainer()distillation_trainer = DistillationTrainer(opt,train_dataloader,test_dataloader)distillation_trainer.trainer()三、总结
总的来说,知识蒸馏是一种有效的模型压缩技术,可以通过在模型训练过程中引入额外的监督信号来训练简化的模型,从而获得与大型复杂模型相近的性能,但具有更小的模型尺寸和计算开销。