目录
一.项目介绍
二.项目流程详解
2.1.引入所需的工具包
2.2.数据读取和预处理
2.3.加载resnet152模型
2.4.初始化模型
2.5.设置需要更新的参数
2.6.训练模块设置
2.7.再次训练所有层
2.8.测试网络效果
三.完整代码
一.项目介绍
使用PyTorch工具包调用经典网络架构resnet训练图像分类模型,用于分辨不同类型的花


二.项目流程详解
2.1.引入所需的工具包
import os
import matplotlib.pyplot as plt
# %matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
# pip install torchvision
from torchvision import transforms, models, datasets # 使用transforms包中的方法进行数据增强,models引入经典网络,datasets包处理数据
# https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image
2.2.数据读取和预处理
# 指定数据路径
data_dir = './flower_data/' # 数据父文件夹
# 数据子文件夹
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'# 创建一个字典结构的数据类型来进行图像预处理操作:key - value
data_transforms = {# 对训练集的预处理'train': transforms.Compose([transforms.Resize([96, 96]), # 卷积神经网络处理的数据大小必须相同,通过Resize来设置# 数据增强transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选transforms.CenterCrop(64), # 从中心开始裁剪,将原本96x96大小的图片数据裁剪为64x64大小的图片数据,可以获取更多的参数transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率,50%的概率进行水平翻转transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转,50%的概率进行竖直翻转transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1), # 参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相transforms.RandomGrayscale(p=0.025), # 概率转换成灰度率,3通道就是R=G=B(三颜色通道转为单一颜色通道,很少进行此处理)# 将数据转为Tensor类型transforms.ToTensor(),# 标准化transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 设置均值,标准差,分别对应R、G、B三个颜色通道的三个均值和标准差值,(x-μ)/σ]),# 对验证集的预处理(不需要进行数据增强)'valid': transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])# 均值和标准差数值的设置和训练集的相同(验证集的数据对我们来说是未知的,不能利用其中的数据再计算出相关的均值和标准差)]),
}batch_size = 128 # 一次性读取的数据数量为128# 获取数据并进行预处理操作: 通过ImageFolder进行处理,传入两个参数:os.path.join(data_dir,x)获取数据的路径,此处data_dir是父文件夹的路径,x是子文件夹的名字。data_transfroms[x]是对取得的数据进行预处理操作。
# image_datasets也是一个字典数据类型:key-value
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}# 设置加载数据的方式,参数分别为:数据,batch_size的大小,是否洗牌
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}# 获取数据的总数,为了后续准确率等的计算做准备
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}# 设置标签,也就是类别名
class_names = image_datasets['train'].classes# 获取标签对应的实际名字,通过外部定义好的json文件来获取实际名字
with open('cat_to_name.json', 'r') as f:cat_to_name = json.load(f)1.创建一个字典结构的数据类型来进行图像预处理操作:key - value。
2.若是输入数据较少,可以通过数据增强来获得更多的特征。
# 数据增强
transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选
transforms.CenterCrop(64), # 从中心开始裁剪,将原本96x96大小的图片数据裁剪为64x64大小的图片数据,可以获取更多的参数
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率,50%的概率进行水平翻转
transforms.RandomVerticalFlip(p=0.5), # 随 机垂直翻转,50%的概率进行竖直翻转3.连接一个json配置文件,赋予标签实际名字。
{"21": "fire lily", "3": "canterbury bells", "45": "bolero deep blue", "1": "pink primrose", "34": "mexican aster", "27": "prince of wales feathers", "7": "moon orchid", "16": "globe-flower", "25": "grape hyacinth", "26": "corn poppy", "79": "toad lily", "39": "siam tulip", "24": "red ginger", "67": "spring crocus", "35": "alpine sea holly", "32": "garden phlox", "10": "globe thistle", "6": "tiger lily", "93": "ball moss", "33": "love in the mist", "9": "monkshood", "102": "blackberry lily", "14": "spear thistle", "19": "balloon flower", "100": "blanket flower", "13": "king protea", "49": "oxeye daisy", "15": "yellow iris", "61": "cautleya spicata", "31": "carnation", "64": "silverbush", "68": "bearded iris", "63": "black-eyed susan", "69": "windflower", "62": "japanese anemone", "20": "giant white arum lily", "38": "great masterwort", "4": "sweet pea", "86": "tree mallow", "101": "trumpet creeper", "42": "daffodil", "22": "pincushion flower", "2": "hard-leaved pocket orchid", "54": "sunflower", "66": "osteospermum", "70": "tree poppy", "85": "desert-rose", "99": "bromelia", "87": "magnolia", "5": "english marigold", "92": "bee balm", "28": "stemless gentian", "97": "mallow", "57": "gaura", "40": "lenten rose", "47": "marigold", "59": "orange dahlia", "48": "buttercup", "55": "pelargonium", "36": "ruby-lipped cattleya", "91": "hippeastrum", "29": "artichoke", "71": "gazania", "90": "canna lily", "18": "peruvian lily", "98": "mexican petunia", "8": "bird of paradise", "30": "sweet william", "17": "purple coneflower", "52": "wild pansy", "84": "columbine", "12": "colt's foot", "11": "snapdragon", "96": "camellia", "23": "fritillary", "50": "common dandelion", "44": "poinsettia", "53": "primula", "72": "azalea", "65": "californian poppy", "80": "anthurium", "76": "morning glory", "37": "cape flower", "56": "bishop of llandaff", "60": "pink-yellow dahlia", "82": "clematis", "58": "geranium", "75": "thorn apple", "41": "barbeton daisy", "95": "bougainvillea", "43": "sword lily", "83": "hibiscus", "78": "lotus lotus", "88": "cyclamen", "94": "foxglove", "81": "frangipani", "74": "rose", "89": "watercress", "73": "water lily", "46": "wallflower", "77": "passion flower", "51": "petunia"}2.3.加载resnet152模型
# 选择经典模型
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
# 是否用人家训练好的特征来做
feature_extract = True# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()if not train_on_gpu:print('CUDA is not available. Training on CPU ...')
else:print('CUDA is available! Training on GPU ...')device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 迁移学习:设置模型参数要不要更新
# 对于迁移学习:样本数据较小,则只对输出的全连接层进行参数更新;样本数据中等大小,则部分修改网络中的参数进行训练;样本数据较大,则需要修改整个网络中的参数进行训练
# 传入的参数为model模型和是否需要更新的一个bool值
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:for param in model.parameters():param.requires_grad = False # 先将参数的requires_grad值(是否需要进行梯度更新)设置为False,如果需要更新参数,再于后续步骤中将该值改为Truemodel_ft = models.resnet152() # 从model中获取152层的resnet模型
# 存在全局平局池化层,在全连接层前设置该层,将NxN的特征图池化层1x1的特征值,不再需要reshape拉长处理。此处涉及到一个迁移学习的概念:即使用经典模型中训练好的权重参数作为初始化参数,只根据需求更新部分的参数。
本项目的样本数据较小,所以只对全连接FC层进行参数的更新,即冻结除FC层以外的所有层。
第一次使用需要下载参数到本地:
![]()
2.4.初始化模型
根据不同的需求和模型对相关参数进行更改,此处只对resnet的全连接层进行更改
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):# 选择合适的模型,不同模型的初始化方法稍微有点区别model_ft = Noneinput_size = 0# 输出的全连接层需要更改out_features数量,将其改为项目中的分类数量if model_name == "resnet":""" Resnet152"""model_ft = models.resnet152(pretrained=use_pretrained) # pretrained = true 表示使用该网络训练好的权重参数等set_parameter_requires_grad(model_ft, feature_extract) # 将参数中的所有梯度是否更新设置为false# 重新定义全连接层(相关参数的更新可以先输出上述使用的网络,在网络中找到参数对应的名字) -- 同时也就重置了requires_grad的值为true,即需要更新梯度num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Sequential(nn.Linear(num_ftrs, num_classes))input_size = 224elif model_name == "alexnet":""" Alexnet"""model_ft = models.alexnet(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier[6].in_featuresmodel_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)input_size = 224elif model_name == "vgg":""" VGG11_bn"""model_ft = models.vgg16(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier[6].in_featuresmodel_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)input_size = 224elif model_name == "squeezenet":""" Squeezenet"""model_ft = models.squeezenet1_0(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))model_ft.num_classes = num_classesinput_size = 224elif model_name == "densenet":""" Densenet"""model_ft = models.densenet121(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier.in_featuresmodel_ft.classifier = nn.Linear(num_ftrs, num_classes)input_size = 224elif model_name == "inception":""" Inception v3Be careful, expects (299,299) sized images and has auxiliary output"""model_ft = models.inception_v3(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)# Handle the auxilary netnum_ftrs = model_ft.AuxLogits.fc.in_featuresmodel_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)# Handle the primary netnum_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Linear(num_ftrs,num_classes)input_size = 299else:print("Invalid model name, exiting...")exit()return model_ft, input_size1.使用经典模型中训练好的权重参数作为初始化参数
model_ft = models.resnet152(pretrained=use_pretrained) # pretrained = true 表示使用该网络训练好的权重参数等2.将所有参数均设置为不需要更新梯度
et_parameter_requires_grad(model_ft, feature_extract) # 将参数中的所有梯度是否更新设置为false3.重新定义全连接层,此操作会使requires_grad的值为重置为true,即需要更新梯度
# 重新定义全连接层(相关参数的更新可以先输出上述使用的网络,在网络中找到参数对应的名字) -- 同时也就重置了requires_grad的值为true,即需要更新梯度
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, num_classes))
input_size = 224print网络模型查看结构,根据结构更改参数:
print(model_ft)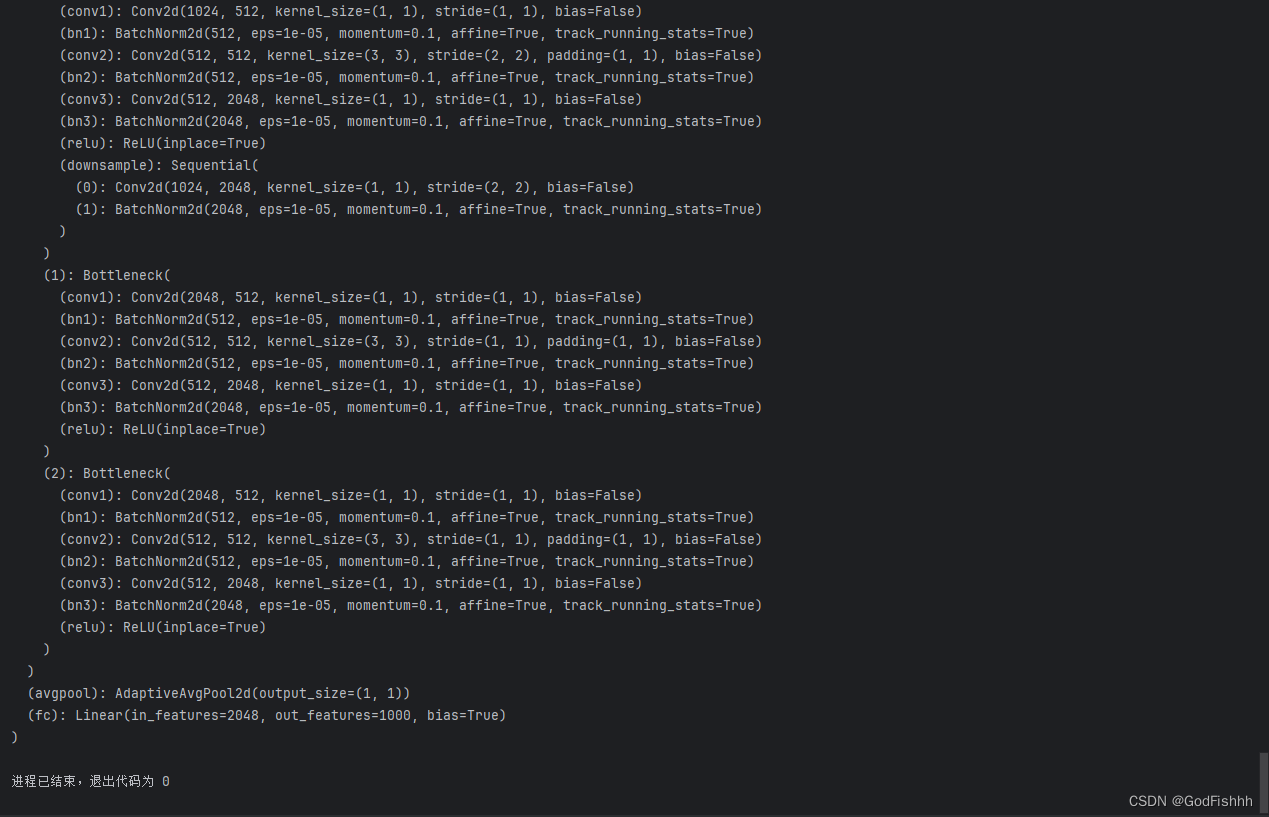
找到最后的全连接层,根据项目要求修改resnet设置的默认参数
avgpool是全局平局池化层,在全连接层前设置该层,将NxN的特征图池化层1x1的特征值,不再需要reshape拉长处理。
2.5.设置需要更新的参数
model_ft, input_size = initialize_model("resnet", 102, True, True) # 模型初始化函数返回两个值,分别为设置好的模型和input_size,传入的参数分别为网络模型名字,输出类别数,设置所有参数梯度不更新,设置使用该网络训练好的权重参数# 设置使用GPU计算(将模型放入GPU的cuda当中)
model_ft = model_ft.to(device) # 模型保存
filename='checkpoint.pth'# 是否训练所有层
params_to_update = model_ft.parameters() # 首先获得所有的参数print("Params to learn:")
if feature_extract: # 如果feature_extract为trueparams_to_update = [] # 需要更新的参数归零for name,param in model_ft.named_parameters():if param.requires_grad == True: # 如果需要更新梯度,则将该参数放到params_to_update中,后续通过优化器进行更新(重新定义网络中的结构层时会同时将requires_grad值重置为true)params_to_update.append(param)print("\t",name)
else: # 如果feature_extract为false,则输出所有需要更新梯度的参数名字for name,param in model_ft.named_parameters():if param.requires_grad == True:print("\t",name)2.6.训练模块设置
# 优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2) # 参数为需要更新的参数和学习率
# 学习率衰减
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) # 学习率每7个epoch衰减成原来的1/10# 损失函数设置
criterion = nn.CrossEntropyLoss()def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False, filename=filename):# 记录当前的时间since = time.time()# 记录准确率最好的情况best_acc = 0"""checkpoint = torch.load(filename)best_acc = checkpoint['best_acc']model.load_state_dict(checkpoint['state_dict'])optimizer.load_state_dict(checkpoint['optimizer'])model.class_to_idx = checkpoint['mapping']"""# 把模型放到GPU中model.to(device)# 保存训练过程中打印的各种参数val_acc_history = []train_acc_history = []train_losses = []valid_losses = []# 初始学习率LRs = [optimizer.param_groups[0]['lr']]# 初始化best_model_wts,后续用来保存最好的模型best_model_wts = copy.deepcopy(model.state_dict()) # model.state_dict()是模型当前的权重参数,通过copy.deepcopy()来初始化best_model_wts# 开始epoch循环for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 训练和验证for phase in ['train', 'valid']:if phase == 'train':model.train() # 训练else:model.eval() # 验证running_loss = 0.0running_corrects = 0# 把数据都取个遍for inputs, labels in dataloaders[phase]: # dataloaders是一个字典结构的数据,其中的value值调用Dataloader函数,得到输入数据和标签# 把数据和标签放到GPU中inputs = inputs.to(device)labels = labels.to(device)# 清零optimizer.zero_grad()# 只有训练的时候计算和更新梯度# 前向传播(调用模型得到预测值)with torch.set_grad_enabled(phase == 'train'):if is_inception and phase == 'train':outputs, aux_outputs = model(inputs)loss1 = criterion(outputs, labels)loss2 = criterion(aux_outputs, labels)loss = loss1 + 0.4 * loss2else: # resnet执行的是这里outputs = model(inputs)loss = criterion(outputs, labels) # 参数为预测值和真实值_, preds = torch.max(outputs, 1) # 得到最大的预测值,用于后续计算corrects数# 训练阶段更新权重if phase == 'train':# 反向传播更新权重参数 backward() + step()loss.backward()optimizer.step()# 计算损失running_loss += loss.item() * inputs.size(0) # input.size(0)得到的是input第一个维度的大小running_corrects += torch.sum(preds == labels.data) # 预测值和真实值做相等的判断# 迭代完一个epoch后,对得到的累加loss和corrects值进行平均计算epoch_loss = running_loss / len(dataloaders[phase].dataset)epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)time_elapsed = time.time() - sinceprint('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# 得到最好那次的模型if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())state = {'state_dict': model.state_dict(),'best_acc': best_acc,'optimizer': optimizer.state_dict(),}torch.save(state, filename) # 保存到本地当中# 储存结果到训练集和验证集的对应位置中if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)scheduler.step(epoch_loss)if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))# 保存训练完的学习率LRs.append(optimizer.param_groups[0]['lr'])print()scheduler.step() # 学习率衰减(累加到一定数量的epoch衰减一次)# 结束epoch循环# 计算出跑完整个网络花费的时间time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))# 训练完后用最好的一次当做模型最终的结果model.load_state_dict(best_model_wts)return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs # 开始训练
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))2.7.再次训练所有层
在只训练全连接层之后,解冻FC层之前的所有层并进行训练(此时全连接层训练的已经比较好)
# 在只训练全连接层之后,解冻FC层之前的所有层并进行训练(此时全连接层训练的已经比较好)
for param in model_ft.parameters():param.requires_grad = True# 再继续训练所有的参数,学习率调小一点
optimizer = optim.Adam(model_ft.parameters(), lr=1e-4) # 对所有参数进行更新
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)# 损失函数
criterion = nn.CrossEntropyLoss()# Load the checkpointcheckpoint = torch.load(filename)
best_acc = checkpoint['best_acc']# 获取之前保存的最好的模型的参数
model_ft.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
#model_ft.class_to_idx = checkpoint['mapping']model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer, num_epochs=10, is_inception=(model_name=="inception"))2.8.测试网络效果
# 得到一个batch的测试数据
dataiter = iter(dataloaders['valid'])
images, labels = next(dataiter)model_ft.eval()if train_on_gpu:output = model_ft(images.cuda())
else:output = model_ft(images)# 得到概率最大的预测值
_, preds_tensor = torch.max(output, 1)# 在GPU中训练的数据格式为tensor,而后续用matplob画图需要的格式为numpy,所以需要进行一次数据类型的转换:cpu中训练则直接转换numpy类型即可;gpu训练则需要先转换为cpu再转换为numpy类型
preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())def im_convert(tensor):""" 展示数据"""# 将数据转到cpu中image = tensor.to("cpu").clone().detach()# 将数据转为numpy类型image = image.numpy().squeeze()image = image.transpose(1, 2, 0) # 通过transpose函数交换数据的维度 此处是由 AxBxC -> BxCxAimage = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406)) # 数据还原 (x-μ)/σ -> x = x*σ + μimage = image.clip(0, 1)return image# 设置输出图片格式
fig=plt.figure(figsize=(20, 20))
columns =4
rows = 2for idx in range (columns*rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[]) # 通过add_subplot设置布局plt.imshow(im_convert(images[idx]))# 设置图片的title为预测的类型和实际的类型,并且如果判断正确则为绿色,反之则为红色ax.set_title("{} ({})".format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),color=("green" if cat_to_name[str(preds[idx])]==cat_to_name[str(labels[idx].item())] else "red"))
plt.show()在GPU中训练的数据格式为tensor,而后续用matplob画图需要的格式为numpy,所以需要进行一次数据类型的转换:cpu中训练则直接转换numpy类型即可;gpu训练则需要先转换为cpu再转换为numpy类型
三.完整代码
import os
import matplotlib.pyplot as plt
# %matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
# pip install torchvision
from torchvision import transforms, models, datasets # 使用transforms包中的方法进行数据增强,models引入经典网络,datasets包处理数据
# https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image# 指定数据路径
data_dir = './flower_data/' # 数据父文件夹
# 数据子文件夹
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'# 创建一个字典结构的数据类型来进行图像预处理操作:key - value
data_transforms = {# 对训练集的预处理'train': transforms.Compose([transforms.Resize([96, 96]), # 卷积神经网络处理的数据大小必须相同,通过Resize来设置# 数据增强transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选transforms.CenterCrop(64), # 从中心开始裁剪,将原本96x96大小的图片数据裁剪为64x64大小的图片数据,可以获取更多的参数transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率,50%的概率进行水平翻转transforms.RandomVerticalFlip(p=0.5), # 随 机垂直翻转,50%的概率进行竖直翻转transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1), # 参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相transforms.RandomGrayscale(p=0.025), # 概率转换成灰度率,3通道就是R=G=B(三颜色通道转为单一颜色通道,很少进行此处理)# 将数据转为Tensor类型transforms.ToTensor(),# 标准化transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 设置均值,标准差,分别对应R、G、B三个颜色通道的三个均值和标准差值,(x-μ)/σ]),# 对验证集的预处理(不需要进行数据增强)'valid': transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])# 均值和标准差数值的设置和训练集的相同(验证集的数据对我们来说是未知的,不能利用其中的数据再计算出相关的均值和标准差)]),
}batch_size = 128 # 一次性读取的数据数量为128# 获取数据并进行预处理操作: 通过ImageFolder进行处理,传入两个参数:os.path.join(data_dir,x)获取数据的路径,此处data_dir是父文件夹的路径,x是子文件夹的名字。data_transfroms[x]是对取得的数据进行预处理操作。
# image_datasets也是一个字典数据类型:key-value
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}# 设置加载数据的方式,参数分别为:数据,batch_size的大小,是否洗牌
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}# 获取数据的总数,为了后续准确率等的计算做准备
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}# 设置标签,也就是类别名
class_names = image_datasets['train'].classes# 获取标签对应的实际名字,通过外部定义好的json文件来获取实际名字
with open('cat_to_name.json', 'r') as f:cat_to_name = json.load(f)# 选择经典模型
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
# 是否用人家训练好的特征来做
feature_extract = True# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()if not train_on_gpu:print('CUDA is not available. Training on CPU ...')
else:print('CUDA is available! Training on GPU ...')device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 迁移学习:设置模型参数要不要更新
# 对于迁移学习:样本数据较小,则只对输出的全连接层进行参数更新;样本数据中等大小,则部分修改网络中的参数进行训练;样本数据较大,则需要修改整个网络中的参数进行训练
# 传入的参数为model模型和是否需要更新的一个bool值
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:for param in model.parameters():param.requires_grad = False # 先将参数的requires_grad值(是否需要进行梯度更新)设置为False,如果需要更新参数,再于后续步骤中将该值改为Truemodel_ft = models.resnet152() # 从model中获取152层的resnet模型
# 存在全局平局池化层,在全连接层前设置该层,将NxN的特征图池化层1x1的特征值,不再需要reshape拉长处理。# print(model_ft)def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):# 选择合适的模型,不同模型的初始化方法稍微有点区别model_ft = Noneinput_size = 0# 输出的全连接层需要更改out_features数量,将其改为项目中的分类数量if model_name == "resnet":""" Resnet152"""model_ft = models.resnet152(pretrained=use_pretrained) # pretrained = true 表示使用该网络训练好的权重参数等set_parameter_requires_grad(model_ft, feature_extract) # 将参数中的所有梯度是否更新设置为false# 重新定义全连接层(相关参数的更新可以先输出上述使用的网络,在网络中找到参数对应的名字) -- 同时也就重置了requires_grad的值为true,即需要更新梯度num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Sequential(nn.Linear(num_ftrs, num_classes))input_size = 224elif model_name == "alexnet":""" Alexnet"""model_ft = models.alexnet(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier[6].in_featuresmodel_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)input_size = 224elif model_name == "vgg":""" VGG11_bn"""model_ft = models.vgg16(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier[6].in_featuresmodel_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)input_size = 224elif model_name == "squeezenet":""" Squeezenet"""model_ft = models.squeezenet1_0(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1, 1), stride=(1, 1))model_ft.num_classes = num_classesinput_size = 224elif model_name == "densenet":""" Densenet"""model_ft = models.densenet121(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.classifier.in_featuresmodel_ft.classifier = nn.Linear(num_ftrs, num_classes)input_size = 224elif model_name == "inception":""" Inception v3Be careful, expects (299,299) sized images and has auxiliary output"""model_ft = models.inception_v3(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)# Handle the auxilary netnum_ftrs = model_ft.AuxLogits.fc.in_featuresmodel_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)# Handle the primary netnum_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Linear(num_ftrs, num_classes)input_size = 299else:print("Invalid model name, exiting...")exit()return model_ft, input_sizemodel_ft, input_size = initialize_model("resnet", 102, True, True) # 模型初始化函数返回两个值,分别为设置好的模型和input_size,传入的参数分别为网络模型名字,输出类别数,设置所有参数梯度不更新,设置使用该网络训练好的权重参数# 设置使用GPU计算(将模型放入GPU的cuda当中)
model_ft = model_ft.to(device)# 模型保存
filename='checkpoint.pth'# 是否训练所有层
params_to_update = model_ft.parameters() # 首先获得所有的参数print("Params to learn:")
if feature_extract: # 如果feature_extract为trueparams_to_update = [] # 需要更新的参数归零for name,param in model_ft.named_parameters():if param.requires_grad == True: # 如果需要更新梯度,则将该参数放到params_to_update中,后续通过优化器进行更新(重新定义网络中的结构层时会同时将requires_grad值重置为true)params_to_update.append(param)print("\t",name)
else: # 如果feature_extract为false,则输出所有需要更新梯度的参数名字for name,param in model_ft.named_parameters():if param.requires_grad == True:print("\t",name)# 优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2) # 参数为需要更新的参数和学习率
# 学习率衰减
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) # 学习率每7个epoch衰减成原来的1/10# 损失函数设置
criterion = nn.CrossEntropyLoss()def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False, filename=filename):# 记录当前的时间since = time.time()# 记录准确率最好的情况best_acc = 0"""checkpoint = torch.load(filename)best_acc = checkpoint['best_acc']model.load_state_dict(checkpoint['state_dict'])optimizer.load_state_dict(checkpoint['optimizer'])model.class_to_idx = checkpoint['mapping']"""# 把模型放到GPU中model.to(device)# 保存训练过程中打印的各种参数val_acc_history = []train_acc_history = []train_losses = []valid_losses = []# 初始学习率LRs = [optimizer.param_groups[0]['lr']]# 初始化best_model_wts,后续用来保存最好的模型best_model_wts = copy.deepcopy(model.state_dict()) # model.state_dict()是模型当前的权重参数,通过copy.deepcopy()来初始化best_model_wts# 开始epoch循环for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 训练和验证for phase in ['train', 'valid']:if phase == 'train':model.train() # 训练else:model.eval() # 验证running_loss = 0.0running_corrects = 0# 把数据都取个遍for inputs, labels in dataloaders[phase]: # dataloaders是一个字典结构的数据,其中的value值调用Dataloader函数,得到输入数据和标签# 把数据和标签放到GPU中inputs = inputs.to(device)labels = labels.to(device)# 清零optimizer.zero_grad()# 只有训练的时候计算和更新梯度# 前向传播(调用模型得到预测值)with torch.set_grad_enabled(phase == 'train'):if is_inception and phase == 'train':outputs, aux_outputs = model(inputs)loss1 = criterion(outputs, labels)loss2 = criterion(aux_outputs, labels)loss = loss1 + 0.4 * loss2else: # resnet执行的是这里outputs = model(inputs)loss = criterion(outputs, labels) # 参数为预测值和真实值_, preds = torch.max(outputs, 1) # 得到最大的预测值,用于后续计算corrects数# 训练阶段更新权重if phase == 'train':# 反向传播更新权重参数 backward() + step()loss.backward()optimizer.step()# 计算损失running_loss += loss.item() * inputs.size(0) # input.size(0)得到的是input第一个维度的大小running_corrects += torch.sum(preds == labels.data) # 预测值和真实值做相等的判断# 迭代完一个epoch后,对得到的累加loss和corrects值进行平均计算epoch_loss = running_loss / len(dataloaders[phase].dataset)epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)time_elapsed = time.time() - sinceprint('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))# 得到最好那次的模型if phase == 'valid' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())state = {'state_dict': model.state_dict(),'best_acc': best_acc,'optimizer': optimizer.state_dict(),}torch.save(state, filename) # 保存到本地当中# 储存结果到训练集和验证集的对应位置中if phase == 'valid':val_acc_history.append(epoch_acc)valid_losses.append(epoch_loss)scheduler.step(epoch_loss)if phase == 'train':train_acc_history.append(epoch_acc)train_losses.append(epoch_loss)print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))# 保存训练完的学习率LRs.append(optimizer.param_groups[0]['lr'])print()scheduler.step() # 学习率衰减(累加到一定数量的epoch衰减一次)# 结束epoch循环# 计算出跑完整个网络花费的时间time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:4f}'.format(best_acc))# 训练完后用最好的一次当做模型最终的结果model.load_state_dict(best_model_wts)return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs# 开始训练
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))# 在只训练全连接层之后,解冻FC层之前的所有层并进行训练(此时全连接层训练的已经比较好)
for param in model_ft.parameters():param.requires_grad = True# 再继续训练所有的参数,学习率调小一点
optimizer = optim.Adam(model_ft.parameters(), lr=1e-4) # 对所有参数进行更新
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)# 损失函数
criterion = nn.CrossEntropyLoss()# Load the checkpointcheckpoint = torch.load(filename)
best_acc = checkpoint['best_acc']# 打印检查parameter是否匹配
# print(model_ft.state_dict().keys())
# print(optimizer.state_dict()["state"].keys())# 获取之前保存的最好的模型的参数
model_ft.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
# model_ft.class_to_idx = checkpoint['mapping']model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer, num_epochs=10, is_inception=(model_name=="inception"))# 得到一个batch的测试数据
dataiter = iter(dataloaders['valid'])
images, labels = next(dataiter)model_ft.eval()if train_on_gpu:output = model_ft(images.cuda())
else:output = model_ft(images)# 得到概率最大的预测值
_, preds_tensor = torch.max(output, 1)# 在GPU中训练的数据格式为tensor,而后续用matplob画图需要的格式为numpy,所以需要进行一次数据类型的转换:cpu中训练则直接转换numpy类型即可;gpu训练则需要先转换为cpu再转换为numpy类型
preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())def im_convert(tensor):""" 展示数据"""# 将数据转到cpu中image = tensor.to("cpu").clone().detach()# 将数据转为numpy类型image = image.numpy().squeeze()image = image.transpose(1, 2, 0) # 通过transpose函数交换数据的维度 此处是由 AxBxC -> BxCxAimage = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406)) # 数据还原 (x-μ)/σ -> x = x*σ + μimage = image.clip(0, 1)return image# 设置输出图片格式
fig=plt.figure(figsize=(20, 20))
columns =4
rows = 2for idx in range (columns*rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[]) # 通过add_subplot设置布局plt.imshow(im_convert(images[idx]))# 设置图片的title为预测的类型和实际的类型,并且如果判断正确则为绿色,反之则为红色ax.set_title("{} ({})".format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),color=("green" if cat_to_name[str(preds[idx])]==cat_to_name[str(labels[idx].item())] else "red"))plt.savefig('result.png')





![[计算机网络]---UDP协议](https://img-blog.csdnimg.cn/direct/0ae9c96e2be34572b3f51203ac4bc6bf.png)