文章目录
- CCEdit
- 1. 核心特性
- 1.1 三叉戟网络结构
- 1.2 精细的外观控制
- 1.3 高度的自适应性
- 2. 三叉戟结构
- 2.1 结构分支(ControlNet架构)
- 2.2 外观分支
- 2.3 主分支
- 3. 数据集——BalanceCC benchmark dataset
- 4. 训练
- 5. 长视频编辑
- 6. 使用场景
- 7. 评估指标
CCEdit
CCEdit是一个基于扩散模型的多功能视频编辑框架,它通过一个创新的三叉戟网络结构,分别控制视频的结构和外观,从而实现精确和创造性的编辑能力。这个框架不仅维持了视频内容的结构完整性,还允许用户对编辑的关键帧进行细粒度的外观调整,确保了编辑内容的个性化和多样性。
1. 核心特性
1.1 三叉戟网络结构
CCEdit采用了一个独特的网络架构,包括控制分支、外观分支和主分支。这种设计使得CCEdit能够在保持视频结构的同时,提供高度的创造性和个性化编辑能力。
1.2 精细的外观控制
通过外观分支,用户可以对颜色、纹理、光照等外观属性进行调整,实现个性化的视觉效果。
1.3 高度的自适应性
CCEdit支持多种结构表示和个性化文本到图像(T2I)模型的选择,以及提供编辑关键帧的选项,展现了其框架的多功能性。
2. 三叉戟结构
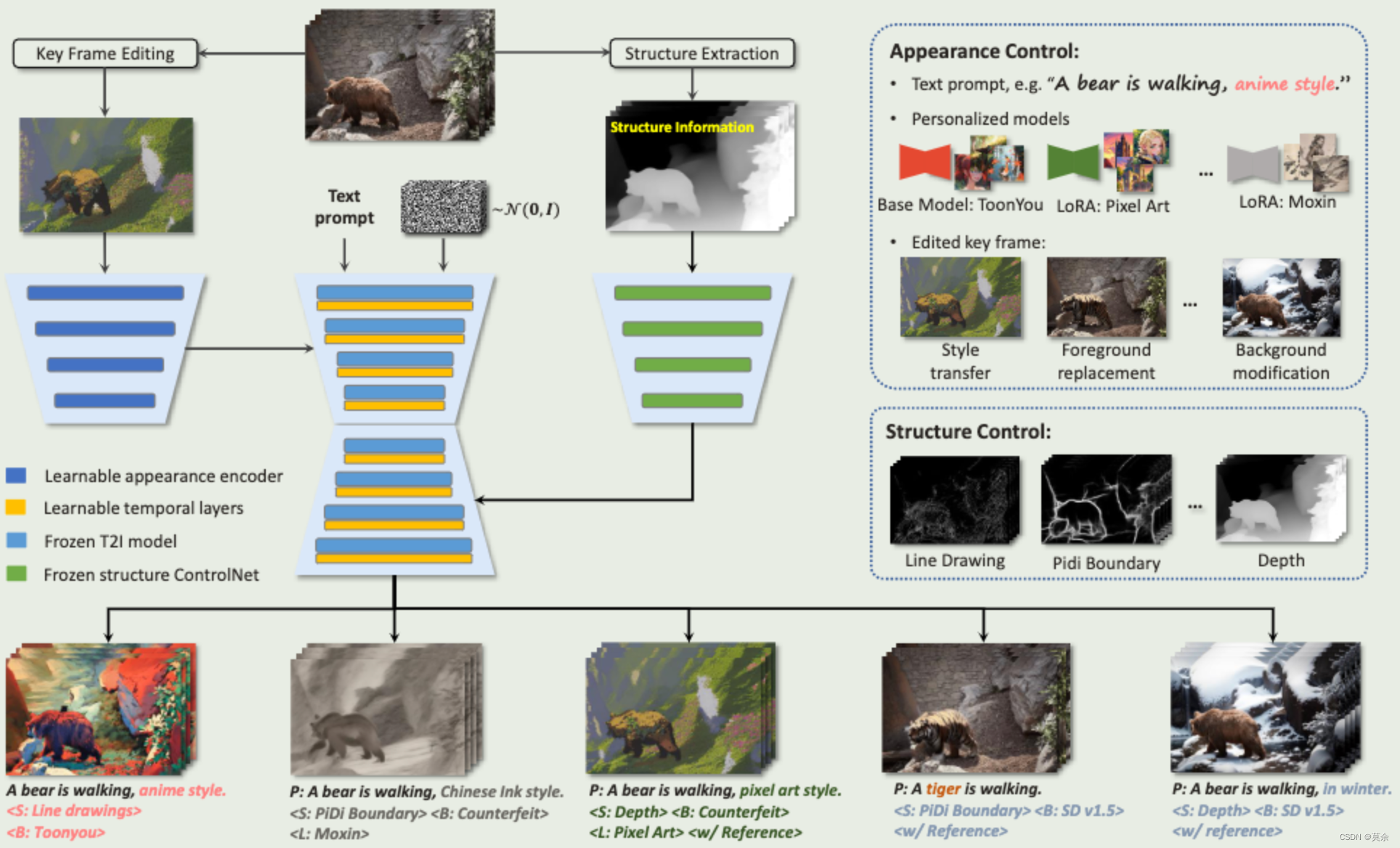
2.1 结构分支(ControlNet架构)
这个分支负责维持视频编辑过程中的结构完整性,消化从输入视频的每一帧中提取的结构信息,并将其无缝地注入到主分支中。它是整个网络的基础,确保在编辑时,视频的基本结构不会被破坏,从而保持了视频内容的连贯性和真实性。
CCEdit模型中结构分支的引入,是为了满足视频编辑任务中保持非编辑或风格转移片段的帧结构的常见需求。在保持忠实的帧结构和允许生成模型有足够创造自由之间找到一个微妙的平衡,是一个重大的挑战。结构分支使用预训练的ControlNet来实现。为了适应不同程度的结构控制需求,该分支采用了多种类型的结构表示方法,包括线条图、PiDi边界和深度图,确保能够在不同程度上控制结构。具体来说,从所有帧中分别提取结构表示,并将其注入到主分支中。每一帧都经过预处理来派生出一种结构表示,而ControlNet的权重在训练过程中保持冻结状态,以强调保留学习到的结构特征。
形式上,让 F ( ⋅ ; Φ c ) F(·; \Phi_c) F(⋅;Φc)表示将结构信息映射成特征的ControlNet, Z ( ⋅ ; Φ z 1 ) Z(·; \Phi_{z1}) Z(⋅;Φz1)和 Z ( ⋅ ; Φ z 2 ) Z(·; \Phi_{z2}) Z(⋅;Φz2)表示中的两个零卷积实例。那么向3D感知特征 v v v添加结构控制的过程可以表示为 v s = v + Z ( F ( z t + Z ( c s ; Φ z 1 ) ; Φ c ) ; Φ z 2 ) v_s = v + Z(F(z_t + Z(c_s; \Phi_{z1}); \Phi_c); \Phi_{z2}) vs=v+Z(F(zt+Z(cs;Φz1);Φc);Φz2),其中 z t z_t zt表示潜在空间中的噪声输入, c s c_s cs表示视频序列的结构条件, v s v_s vs表示具有结构信息感知的特征。
结构分支的目的是在不损害视频原有结构的情况下,为视频编辑和风格转换提供更精细的控制。通过使用不同类型的结构表示和保持ControlNet权重的冻结状态,结构分支能够在编辑过程中保留视频的结构特征,同时还能够根据需求调整结构的控制程度。这样,即使在进行创造性编辑时,也能确保视频内容的结构完整性不受影响。
2.2 外观分支
这个分支允许用户对编辑的关键帧进行细粒度的外观控制。通过这个分支,用户可以调整颜色、纹理、光照等外观属性,实现个性化的视觉效果。
外观分支是CCEdit模型中的一个创新设计,用于增加外观控制的精细度,并允许将编辑过的帧作为详细参考融入视频编辑的上下文中。这种架构创新提供了一种先锋的方法,用于实现精细的外观控制,通过整合一个编辑过的帧,使得框架能够在视频编辑中引入更大的创造性和可控性。关键帧的编辑可以通过精确的用户编辑或使用先进的现成图像编辑算法来完成,外观分支的引入使得我们的框架能够实现更高的创造性和控制力。
具体来说,一个关键帧最初由编码器E分配给潜变量。随后,一个与主分支的编码器具有相似架构的神经网络提取多尺度特征。这些提取的特征被整合到主分支中。通过这种设计,编辑过的关键帧的外观信息通过时间模块传播到所有帧中,有效地在输出视频中实现所需的创造性控制。
形式上,假设 F ( ⋅ ; Ψ ) F(·; Ψ) F(⋅;Ψ)是将关键帧的逐像素外观映射到特征的编码器, Z ( ⋅ ; Ψ z ) Z(·; Ψ_z) Z(⋅;Ψz)表示零卷积投影输出层, v j v_j vj表示第 j j j帧的特征, c j a c_j^a cja是关键帧。那么添加外观控制到特征的过程可以表示为 v j a = v j + Z ( F ( E ( c j a ) ; Ψ ) ; Ψ z ) v_j^a = v_j + Z(F(E(c_j^a); Ψ); Ψ_z) vja=vj+Z(F(E(cja);Ψ);Ψz),其中 v j a v_j^a vja是意识到编辑外观的第 j j j帧特征。
外观分支通过编码器处理编辑过的关键帧,提取其外观特征,并将这些特征融合到视频的每一帧中,从而实现对视频整体外观的精细调控。这样的设计使得用户可以精确地控制视频中各帧的外观,包括色彩、纹理等元素,以匹配编辑过的关键帧,实现高度个性化和创造性的视频编辑结果。
2.3 主分支
这个分支整合了上述两个分支的功能,并建立在现有的文本到图像(T2I)生成模型之上。通过学习性的时序层(learnable temporal layers),插入时间模块将其转换为文本到视频(T2V)模型,这个分支能够处理和生成视频内容,确保编辑后的视频在视觉上的连贯性和动态效果。
该模型通过在编码器和解码器的空间层中加入时间层,被转变为文本到视频的变体。具体来说,这包括在每个已有的空间层之后添加一个与之类型相同的一维时间层,例如卷积块和注意力块。此外,为了实现稳定和逐步的更新,还使用了跳过连接和每个新增加时间层的零初始化投影输出层,这种方法已被证明是有效的。
零初始化投影输出层被实例化为一个线性层。形式上,设 F ( ⋅ ; Θ s ) F(·; Θ_s) F(⋅;Θs)为2D空间块, F ( ⋅ ; Θ t ) F(·; Θ_t) F(⋅;Θt)为1D时间块, Z ( ⋅ ; Θ z ) Z(·; Θ_z) Z(⋅;Θz)为零初始化投影输出层,其中 Θ s \Theta_s Θs、 Θ t \Theta_t Θt和 Θ z \Theta_z Θz分别代表相应的网络参数。将输入特征 u u u映射到输出特征 v v v的完整过程可以写成 v = F ( u ; Θ s ) + Z ( F ( F ( u ; Θ s ) ; Θ t ) ; Θ z ) v = F(u; \Theta_s) + Z(F(F(u; \Theta_s); \Theta_t); \Theta_z) v=F(u;Θs)+Z(F(F(u;Θs);Θt);Θz),其中 u u u和 v v v都是3D特征图,即 u ∈ R l × h × w × c u ∈ R^{l×h×w×c} u∈Rl×h×w×c,这里的 l , h , w , c {l, h, w, c} l,h,w,c分别代表帧数、高度、宽度和通道数。
主分支通过在传统的文本到图像模型中加入时间维度的处理,使得模型能够理解和生成视频序列。这样的设计让模型不仅能够处理每一帧的空间信息(即图像内容),还能够理解帧与帧之间的时间关系,从而生成连贯的视频内容。通过这种方式,模型可以根据文本描述生成具有一定时间长度的视频,每一帧都是根据文本描述精心构造的,而且整个视频在视觉上是连贯的。
3. 数据集——BalanceCC benchmark dataset
该数据集包含100个视频,每个视频4个prompts。
- 视频的持续时间从 2 到 20 秒不等
- 每个视频的帧速率约为 30 fps
- 对于每个视频,GPT-4V(ision) 提供描述
- 使用中心帧作为参考为场景分配复杂性分数,评级从 1(简单)到 3(复杂)
- 摄像机运动、物体运动和分类内容,运动评级范围从 1(静止)到 3(快速),类别包括人类、动物、物体和风景
- 幻想级别:指示目标提示的想象力和创造力程度

4. 训练
我们使用预先训练的 ControlNet 进行结构信息指导。 训练数据集结合了WebVid-10M 和自行收集的私有数据集。 我们针对各种类型的结构信息训练时间一致性模块和外观 ControlNet,包括线条图、PiDi 边界 、Midas 检测到的深度图和人类涂鸦。 默认情况下使用深度图。 控制尺度设置为1。对于时间插值模型,我们仅在深度图上训练它,采用较小的控制尺度0.5。 采用这种方法是因为它对结构信息的要求相对其他模型来说较少。 在训练过程中,我们首先将短边调整为384像素,然后随机裁剪以获得尺寸为384×576的视频片段。从每个视频中采样17帧4fps。 批量大小为 32,学习率为 3e − 5。我们对每个模型进行 100K 次迭代训练。 在推理过程中,我们采用 DDIM 采样器,具有 30 个步骤,无分类器指导,幅度为 9。
在训练CCEdit模型之前,我们采取以下步骤来初始化模型的权重和进行训练设置:
-
主分支空间权重初始化:主分支的空间权重使用预训练的文本到图像(T2I)模型进行初始化,这有助于模型更好地理解和生成图像内容。
-
时间权重初始化:时间权重采用随机初始化,而投影输出层(projection out layers)则进行零初始化。这样的初始化方法旨在为模型的时间处理能力提供一个起点,同时保持一定的灵活性。
-
结构分支模型实例化:结构分支使用预训练的ControlNet模型来实现,这有助于模型准确地控制和保持视频帧的结构信息。
-
外观分支设置:外观分支复制了预训练的文本到图像模型的编码器,并移除了文本交叉注意力层,以便于专注于处理外观信息。
在训练过程中,给定一个输入视频片段 x 0 x_0 x0的潜变量 z 0 = E ( x 0 ) z_0 = E(x_0) z0=E(x0)。扩散算法逐步向其添加噪声,产生噪声输入 z t z_t zt。给定时间步 t t t、文本提示 c t c_t ct、结构信息 c s c_s cs和关键帧的外观信息 c j a c_j^a cja,整体优化目标是:
E z 0 , t , c t , c s , c j a , ϵ ∼ N ( 0 , I ) [ ∥ ϵ − ϵ θ ( z t , t , c t , c s , c j a ) ∥ 2 2 ] E_{z_0,t,c_t,c_s,c_j^a,\epsilon\sim N(0,I)}[\|\epsilon - \epsilon_\theta (z_t, t, c_t, c_s, c_j^a)\|^2_2] Ez0,t,ct,cs,cja,ϵ∼N(0,I)[∥ϵ−ϵθ(zt,t,ct,cs,cja)∥22]
这里 ϵ θ \epsilon_\theta ϵθ表示整个网络预测添加到噪声输入 z t z_t zt上的噪声。在训练期间,我们固定主分支的空间权重和结构分支的权重,同时更新主分支中新加入的时间层的参数,以及外观分支的权重。默认情况下,外观分支使用视频片段的中心帧作为输入。
简而言之,训练过程中通过结合预训练模型和专门设计的初始化方法,以及通过逐步添加噪声和根据给定条件优化网络预测的方式,CCEdit模型能够学习如何根据文本描述、结构和外观信息生成高质量的视频内容。这种方法使得模型在保持视频结构的同时,也能够在外观上进行精细的调整和创新。
5. 长视频编辑
CCEdit面对的一个挑战是如何在跨越数十秒的视频片段中保持一致的外观和感觉,这相当于数百帧。由于内存限制,生成模型一次只能处理十几帧,这带来了结果上的变异性,在CCEdit模型中,"L + 1"表示模型一次能够处理的最大帧数。
为了处理超过这个数量的帧,CCEdit采用了一种策略,通过选择关键帧、扩展模式和插值模式来确保整个视频的编辑结果保持一致性和连贯性。
具体来说,设 L + 1 L + 1 L+1代表CCEdit一次能处理的帧数。对于超过 L + 1 L + 1 L+1帧的视频,我们每 L L L帧选择一个关键帧。在初始运行中,前 L + 1 L+1 L+1个关键帧进行编辑。在后续的扩展模式运行中,将上一次运行的最后一个编辑帧作为第一帧。编辑结果作为外观分支的参考。这个过程一直重复,直到所有关键帧都被处理。转到插值模式时,两个相邻帧成为一个推断运行的第一帧和最后一帧,以编辑 L − 1 L - 1 L−1个中间帧,且两个编辑过的帧作为外观分支的参考。这一过程持续进行,直到所有帧都被编辑。这一细致的过程确保了整个视频的编辑结果保持一致。
-
关键帧选择:对于超过"L + 1"帧的视频,我们会每隔L帧选择一个关键帧进行编辑。这些关键帧作为视频编辑的基准点,帮助确保编辑效果的一致性。
-
扩展模式:在初始运行中处理了第一组"L + 1"帧之后,接下来的运行会将上一次运行的最后一帧作为新的起始帧,这样做是为了在视频的连续帧之间保持编辑效果的连贯性。这个过程会一直重复,直到所有的关键帧都被处理完毕。
-
插值模式:在处理完所有关键帧之后,为了确保整个视频帧之间的平滑过渡,CCEdit会使用插值模式来编辑那些没有被直接编辑的中间帧。这种方式通过在两个已编辑的关键帧之间进行插值,来编辑中间的"L - 1"帧,确保编辑效果在整个视频中的一致性。
这个过程确保了,即便是在长视频中,每个片段都能够以一种连贯和一致的方式被编辑,从而提高了整个视频的质量和观感。这种方法特别适用于处理大量帧的视频内容,能够有效地解决内存限制问题,并保持编辑的高质量结果。
6. 使用场景
CCEdit适用于各种视频编辑任务,包括但不限于以下几种:
- 内容修改
- 风格转换
- 颜色调整
- 动态效果的创造
无论是需要精确编辑特定帧的专业视频制作人员,还是希望给自己的社交媒体内容添加创意效果的短视频博主,CCEdit都能满足他们的需求。
7. 评估指标
- 平均意见得分(Mean Opinion Score, MOS)