目录
一、说明
二、实现Transformer的过程
第 1 步:代币化(Tokenization)
第 2 步:对每个单词进行标记嵌入
第 3 步:对每个单词进行位置嵌入
第 4 步:输入嵌入
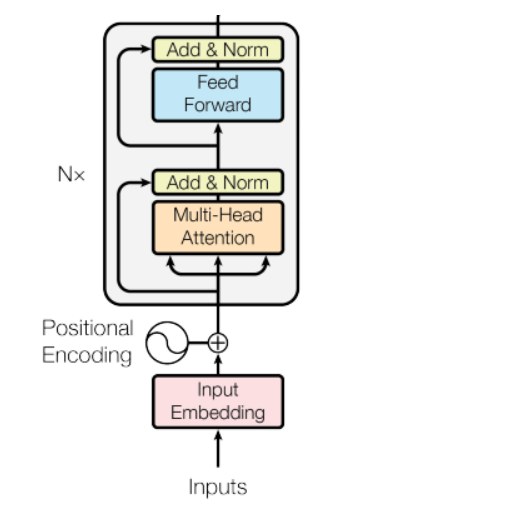
第 5 步:编码器层
2.5.1 多头自注意力
2.5.2 剩余连接(添加)
2.5.3 层归一化
2.5.4 前馈神经网络
第6步:解码器层
三、小结
一、说明
本文对transformer的体系进行系统梳理,总的来说,transformer实现分五个步骤,除了一般化处理,token、词法、句法、词嵌入式,编码、解码过程。

二、实现Transformer的过程
涉及的步骤是:
第 1 步:代币化(Tokenization)
输入序列“how are you”被标记为单个单词或子单词。我们假设它被标记为以下标记:[“how”、“are”、“you”]。
第 2 步:对每个单词进行标记嵌入
- 嵌入“如何”:[0.5, 0.2, -0.1]
- “are”的嵌入:[-0.3, 0.8, 0.4]
- 嵌入“你”:[0.6,-0.5,0.3]

model_name = 'gpt2' # Replace with the specific transformer model you want to use
model = GPT2Model.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)# Example input text
input_text = "Hello, how are you today?"# Tokenize input text
tokens = tokenizer.tokenize(input_text)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
input_tensor = torch.tensor([input_ids])# Generate token embeddings
token_embeddings = model.transformer.wte(input_tensor)
第 3 步:对每个单词进行位置嵌入
位置输入嵌入是基于变压器的模型的关键组成部分,包括用于会话聊天机器人的模型。它们提供有关序列中标记相对位置的信息,使模型能够理解输入的顺序。
在 Transformer 中,位置输入嵌入被添加到令牌嵌入中以对位置信息进行编码。
生成位置嵌入有不同的方法。一种常见的方法是使用正弦函数来创建具有固定模式的嵌入。序列中每个标记的位置被映射到一个唯一的向量,其中向量的值对应于不同频率的正弦和余弦函数。这些频率控制每个位置嵌入对令牌的最终表示的贡献程度。
# Generate positional embeddings
position_ids = torch.arange(input_tensor.size(1), dtype=torch.long)
position_ids = position_ids.unsqueeze(0)
position_embeddings = model.transformer.wpe(position_ids)第 4 步:输入嵌入
输入嵌入是令牌嵌入和位置嵌入的总和。
# Sum token embeddings and positional embeddings
input_embeddings = token_embeddings + position_embeddings第 5 步:编码器层
2.5.1 多头自注意力
a.含义
编码器层中的第一个子层是多头自注意力机制。它允许输入序列中的每个位置关注所有其他位置,捕获序列的不同元素之间的依赖关系。
b.自注意力机制
自注意力机制通过考虑每个元素与所有其他元素的关系来计算每个元素的注意力权重。例如:
输入:“你好吗”
在自注意力机制中,每个元素的权重都是相对于其他元素计算的。这就是找到“如何”与“是”、“你”和“做”的关系。这种机制被并行地(头向)多次应用以捕获不同类型的依赖关系。
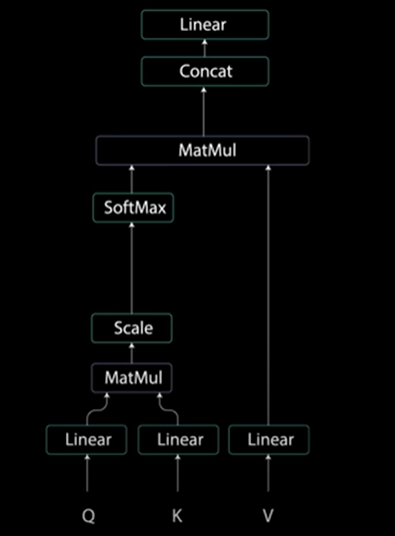
问→查询
K → 键
V→值
步骤a:为每个输入嵌入找到查询、键和值
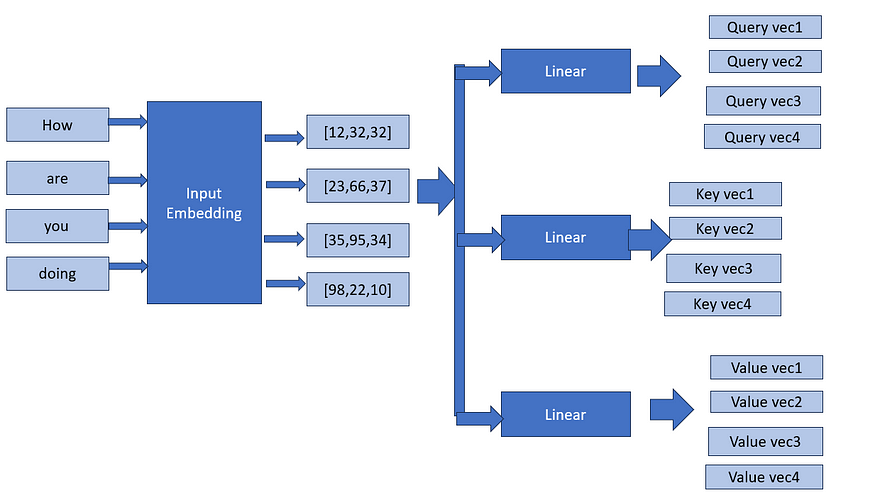
在自注意力中,从每个输入单词导出三个向量:查询向量、键向量和值向量。这些向量用于计算注意力权重。单词的注意力权重表示在对特定单词进行编码时应该注意多少。
这里的查询、键和值就像 YouTube 搜索引擎一样。给出查询(在搜索框中),像视频标题、描述这样的键用于查找值(这里是视频)。
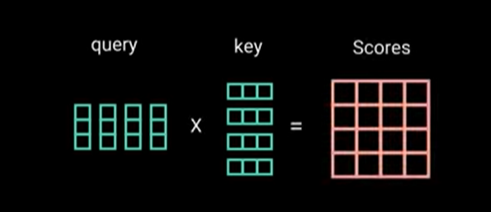
步骤b.注意力权重计算(Scores)
使用 Matmul 找到注意力权重或分数
分数矩阵将决定每个单词对另一个单词的重要性。分数越高,越受关注。
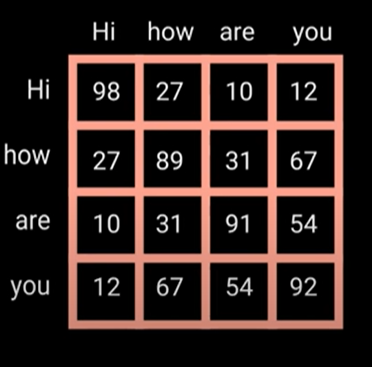
每个词都会影响另一个词
步骤c:在分数矩阵上进行缩放
步骤 d:对分数矩阵进行 Softmax
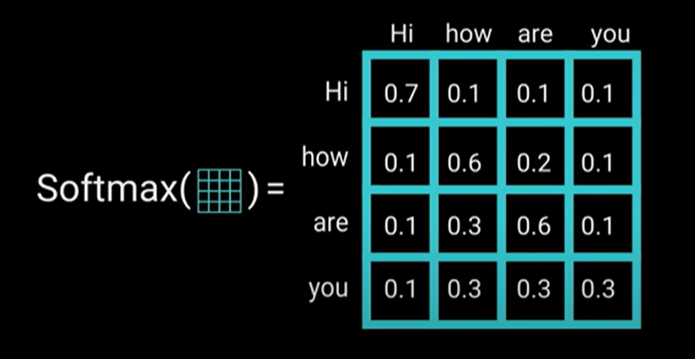
经过softmax之后,较高的分数会得到提高,较低的分数会受到抑制。这使得重要的分数在下一步中被削弱
步骤 e:MatMul,其中注意力权重与值向量相乘

将注意力权重与值相乘得到输出
步骤f: 找到每个单词的上下文向量
当涉及的向量数量较多时。它们连接成一个向量
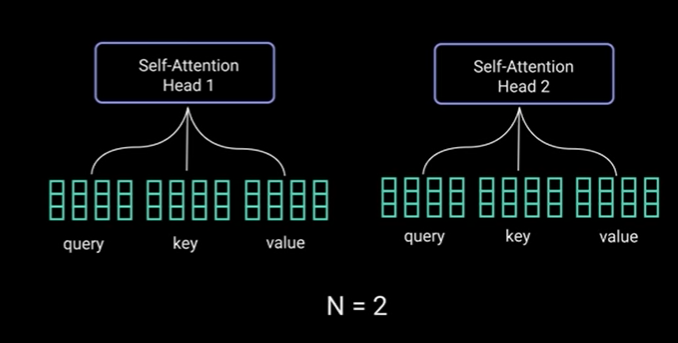
创建各种自注意力头
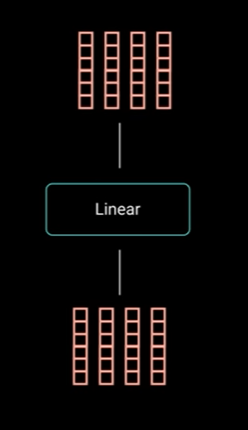
自注意力头被连接起来并发送到线性块中。
连接的输出被送入线性层进行处理,并找到每个单词的上下文向量。
2.5.2 剩余连接(添加)
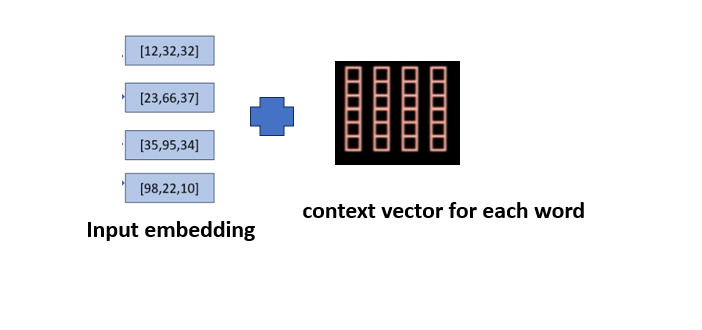
添加输入嵌入和上下文向量
2.5.3 层归一化
剩余连接的输出进入层归一化。分层归一化有助于稳定网络。
“你好吗”的输出向量:
- “如何”的上下文向量:[0.9,-0.4,0.2]
- “are”的上下文向量:[-0.2, 0.6, -0.3]
- “你”的上下文向量:[0.3,0.1,0.5]
2.5.4 前馈神经网络
现在,上下文向量通过位置前馈神经网络传递,该网络独立地对每个位置进行操作。
我们将前馈网络的权重和偏差表示如下:
- 第一个线性变换权重:W1 = [[0.1, 0.3, -0.2], [0.4, 0.2, 0.5], [-0.3, 0.1, 0.6]]
- 第一个线性变换偏差:b1 = [0.2, 0.1, -0.3]
- 第二次线性变换权重:W2 = [[0.2, -0.4, 0.1], [-0.3, 0.5, 0.2], [0.1, 0.2, -0.3]]
- 第二个线性变换偏差:b2 = [0.1, -0.2, 0.3]
对于每个上下文向量,具有Relu 激活函数的位置前馈神经网络应用以下计算:

位置前馈神经网络将上下文向量转换为每个单词的新表示。
- 编码器可以堆叠n次,以便每个单词可以学习每个单词的不同表示。
描述编码器的代码:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass EncoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff, dropout):super(EncoderLayer, self).__init__()self.self_attention = nn.MultiheadAttention(d_model, num_heads)self.norm1 = nn.LayerNorm(d_model)self.feed_forward = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):# Multi-head self-attentionattn_output, _ = self.self_attention(x, x, x)x = x + self.dropout(attn_output)x = self.norm1(x)# Feed-forward networkff_output = self.feed_forward(x)x = x + self.dropout(ff_output)x = self.norm2(x)return x第6步:解码器层
转换器解码器从编码器获取编码表示并处理输出序列(“我很好”)以生成相应的序列。
在解码的每个步骤中,解码器都会关注:
- 之前生成的单词
- 使用自注意力和编码器-解码器注意力机制的编码输入表示。
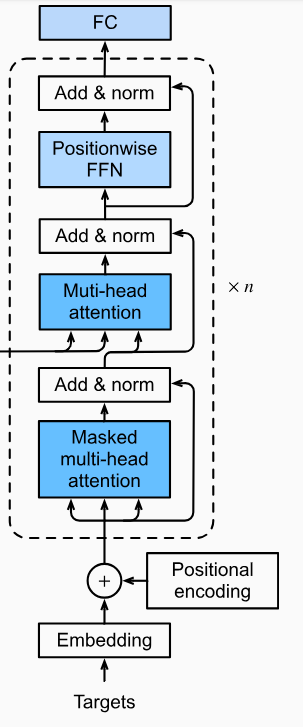
解码器
目标:“<开始>I am
步骤 1:解码器接收序列开始标记“<start>”作为其初始输入。
步骤 2:解码器使用编码器-解码器注意机制关注编码的输入表示。这有助于解码器与输入中的相关信息保持一致。
步骤 3:解码器使用自注意力机制关注其之前生成的单词,并考虑到目前为止生成的嵌入。
步骤 4:解码器应用位置前馈神经网络来细化表示。
步骤5:解码器根据细化的表示生成第一个单词“I”。
步骤6-8:解码器对后续单词“am”和“fine”重复该过程,根据之前的上下文、自注意力和前馈网络生成它们。
(代码较为复杂,整理以后给出---更新中.... )
三、小结
以上概括第给出transformer的实现提纲,至于每一个步骤还有更多细节,可以在此文的引导下继续细化完成。