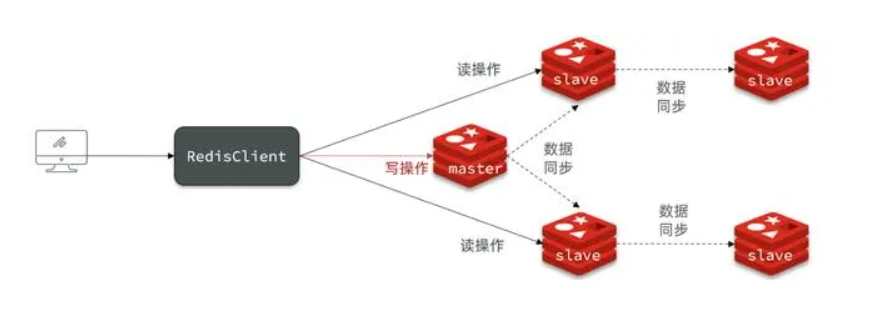
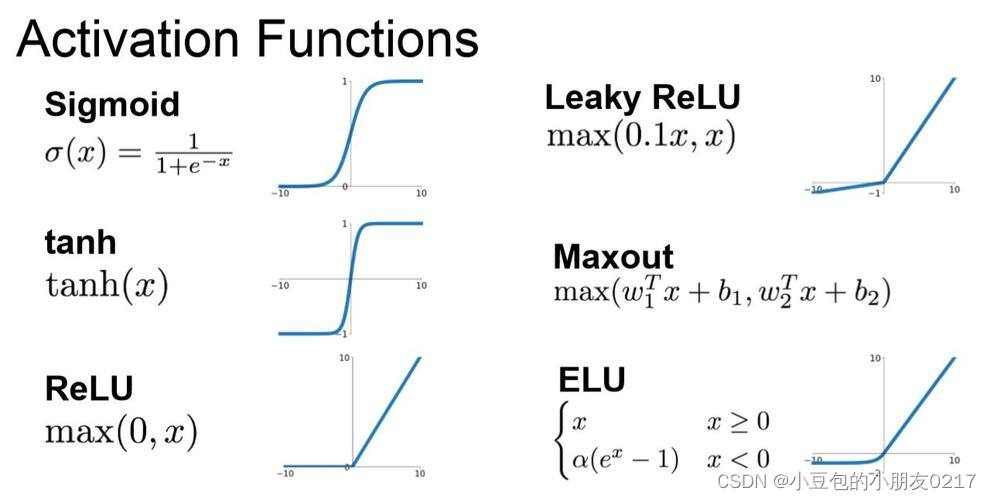
1 请问人工神经网络中为什么 ReLU 要好过于 tanh 和 Sigmoid function?

-
采⽤Sigmoid 等函数,算激活函数时(指数运算),计算量⼤,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对⼤,⽽采⽤ReLU 激活函数,整个过程的计算量节省很多。
-
对于深层⽹络,Sigmoid 函数反向传播时,很容易就会出现梯度消失
的情况(在 Sigmoid 接近饱和区时,变换太缓慢,导数趋于 0,这种情况会造成信息丢失),这种现象称为饱和,从而无法完成深层网络的训练。而ReLU 就不会有饱和倾向,不会有特别小的梯度出现,求导后都为1。 -
ReLU 会使⼀部分神经元的输出为 0,这样就造成了⽹络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发⽣,当然现在也有⼀些对 ReLU 的改进,比如 PReLU,random ReLU等,在不同的数据集上会有⼀些训练速度上或者准确率上的改进。
现在主流的做法,会多做⼀步 batch normalization,尽可能保证每⼀层网络的输⼊具有相同的分布 。⽽较新的 paper ,他们在加⼊bypass connection 之后,发现改变 batch normalization 的位置会有更好的效果。
2 能写一下逻辑回归的损失函数吗?为什么不用 MSE(L2 loss)作为损失函数
推荐博客 https://zhuanlan.zhihu.com/p/670167066
https://blog.csdn.net/m0_52447591/article/details/129796877

不用 MSE 做损失函数的原因:
- 损失函数的角度:逻辑回归预测函数是非线性的,采用 MSE 得到的损失
函数是非凸函数,会存在很多局部极小值,梯度下降法可能无法获得全局最优解。 - 极大似然的角度: 采用极大似然法估计逻辑回归模型的参数,最终得到的
对数似然函数形式与对数损失函数一致。
3 逻辑回归用梯度下降优化,学习率对结果有什么影响?
- 学习率过低则模型训练速度会慢
- 学习率过高则模型训练会在全局最优点附近震荡,甚至不收敛
4 逻辑回归中样本不均衡我们怎么处理?
- 调整分类阈值,不统一使用 0.5,根据样本中类别的比值进行调整。
- 多类样本负采样。进一步也可将多类样本负采样构建多个训练集,最后聚
合多个模型的结果。 - 少类样本过采样。过采样的方法大致有三种:
c1: 随机复制
c2: 基于聚类的过采样
c3: SMOTE - 改变性能指标,推荐采用 ROC AUC、F1 Score,等综合考虑,不单单使用精度。
- 模型训练增加正负样本惩罚权重,少类样本权重加大,增大损失项。
5(百度)Kmeans 的流程方法停止条件
流程:
(1)K 如何确定
(2)初始质心的选取
(3)距离的度量
(4)质心的计算
(5)算法停止条件
(6)空聚类的处理
停止条件:
目标函数达到最优,对于不同的距离度量,目标函数往往不同。我们往往认
为簇的质心到各个点的距离越小,簇越紧凑。
采用欧式距离时:目标函数一般为最小化对象到其簇质心的距离的平方和。
采用余弦相似度时,目标函数一般为最大化对象到其质心的余弦相似度和。