*> 文|曾力 众安保险大数据开发高级专家
编辑整理| 曾辉*
前言
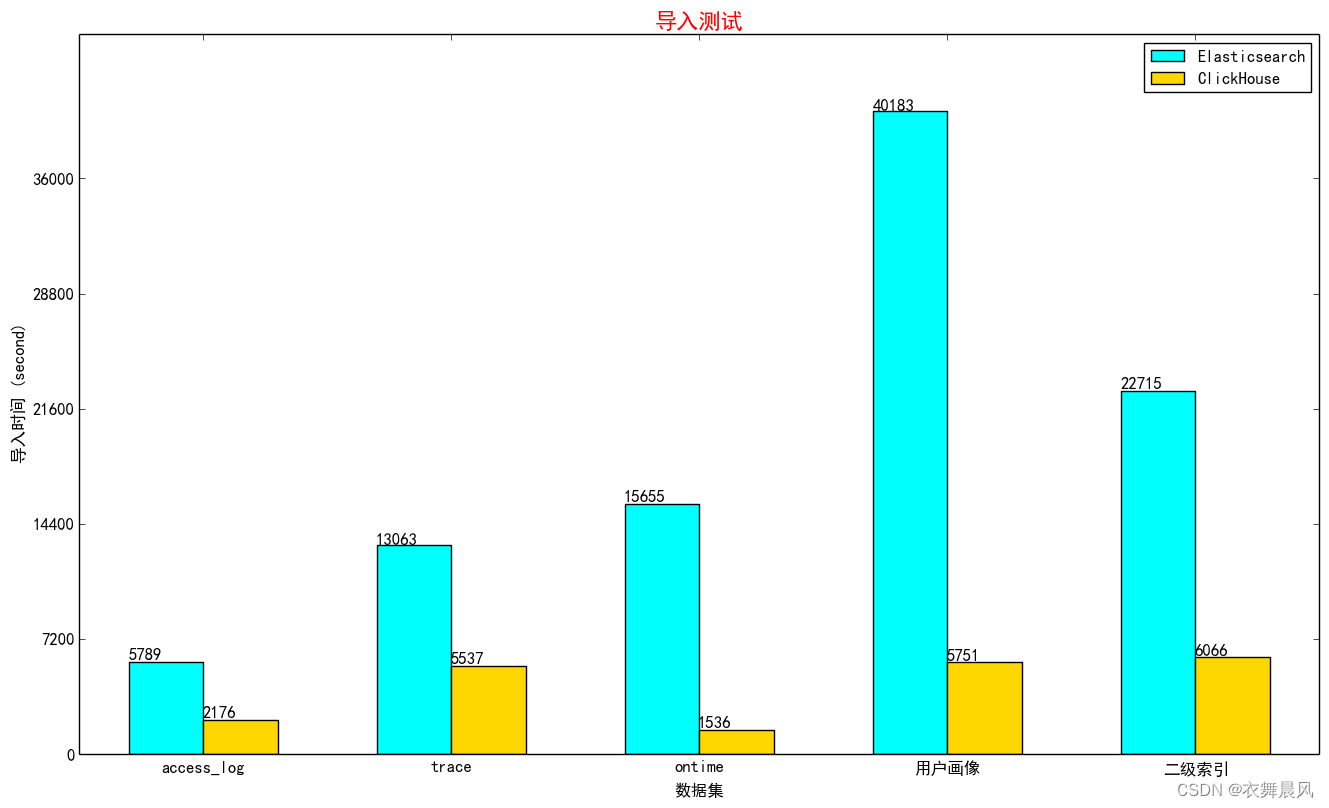
众安保险从2023年4月就开始了数据集成服务的预研工作,意在通过该服务解决当前数据同步场景下的两大痛点,服务化能力薄弱和无分布式同步能力。我们对多种开源数据同步中间件的调研和性能测试,最终选择Apache SeaTunnel 及其新的Zeta引擎,进行服务化包装。
2023年10月,我们 基于2.3.3版本,开始进行二次开发。主要是完善服务化接口、适配连接器特性相关工作。2024年元旦前后,我们完成了数据集成服务的开发,并开始基于MaxCompute到ClickHouse的同步场景开始批量替换存量DataX作业,目前已切换数百个,作业平稳运行,并达到预期的性能提升效果。
后续我们将在实际应用中不断收集反馈、优化和完善服务,并向社区提交迭代和优化建议。
数据集成的痛点
众安保险在2015年左右就开始通过DataX来作为数据集成的同步工具,从淘宝内部的2.0版本到后续社区的3.0版本,其稳定性和效率得到了验证。
但随着时间的推移,我们每日的数据同步作业量由最初的几千个提升3.4万个,面对每天20TB的数据入仓数据量和15TB的数据出仓数据量,以及与流媒体交互场景下单日最大40亿条记录的增量同步场景,DataX展现出了其局限性。
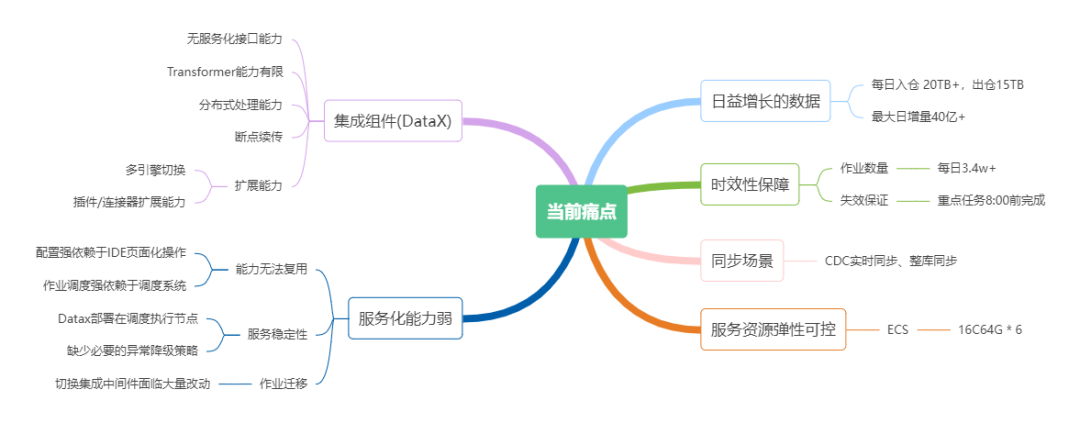
DataX作为一款经典单机多线程的数据集成工具,其作业配置化、多并发、插件可插拔、内存数据传递的设计思想是优秀的,为后续很多集成中间件的设计指明了道路。但是其缺乏服务化及分布式处理能力,这限制了其在大规模数据同步场景下的应用。
降低耦合:内部场景中,DataX服务化的局限性,导致其与内部研发、调度平台的严重耦合。 这导致DataX作业运行时的资源消耗(CPU),会严重影响服务性能。
能力扩展:面对未来存算分离和云原生等技术趋势,我们意识到需要一种能够提供服务化能力,支持不同的集成中间件,并适配快速的配置替换。
资源隔离及弹性扩展:我们期望数据同步资源能够更加弹性地被控制和管理,特别是面对我们的3.4万个DataX任务,这些任务被部署在6台配置为16核64GB内存的ECS上,通过逻辑上的三个集群实现部门与子公司之间的隔离。然而,资源使用的不均匀性,尤其是在夜间任务高峰期资源负载可能极高的情况下,强化了对资源弹性可控使用的需求。
面对未来存算分离和云原生等技术趋势,我们意识到需要一种能够提供服务化能力,支持不同执行中间件,并能适应快速发展需求的数据集成工具。
Apache SeaTunnel正是在这样的背景下被选中,它不仅能帮助我们解决现有的数据集成挑战,还能为我们提供一个平滑迁移的路径,确保数据同步任务的高效和稳定执行。此外,Apache SeaTunnel在CDC实时同步方面的能力,以及减少数据同步回流时间的特性,也是我们选择它的重要考虑因素。
为什么选择Zeta
简单易用
- 多模式部署:支持单进程/集群两种模式,支持容器化Kubernetes/Docke部署;
- 连接器丰富:社区已提供几十种类型的连接器,并提供了相对完善的功能。社区经过几个版本的迭代,已经能够覆盖DataX的主要功能;
- 转换器:提供DAG级别的转换器,相对于DataX行级转换器是一个很大的进步;
- 服务化能力:提供系统RestApi、客户端代理等多种模式接入服务;
- 支持场景:离线/实时同步,整库同步等;
- 依赖较少:zeta standalone模式可以不依赖第三方组件实现分布式数据同步;
扩展性
- 连接器:可插拔设计,能够轻松地支持更多的数据源,并且可以根据需要扩展模式;
- 多引擎:同时支持Zeta、Flink、Spark三种引擎,并提供统一的翻译层进行对接扩展;众安目前的基础架构主要是基于MaxCompute,我们没有Hadoop这类的大数据集群,因此Zeta的分布式能力可以很好的解决该问题。同时若未来进行大数据基座迁移(迁移其他云EMR或自建集群),可以实现作业的无缝衔接。
- Zeta多资源管理器:目前仅支持Standalone,未来社区会支持yarn/k8s模式;
高效稳定
- 更快速:在相同资源配置下,相比于DataX能够提供15%~30%的性能提升;
- 资源节省:我们尝试通过优化配置极限压榨内存资源,结果发现在保持同步速度不变的情况下,相比DataX,SeaTunnel可以节省30%到40%以上的内存。这意味着一旦SeaTunnel支持在Kubernetes上运行,对内存的总体消耗将大大减少。SeaTunnel利用共享线程技术减少了上下文切换的开销,从而进一步提高了数据同步的速度。
- 容错恢复:作业级别实现了pipeline级别的checkpoint,集群级别实现了Hazecast内存网络IMAP的异常恢复。基于内部oss存储场景,我们扩展了相关插件。
社区活跃度
Apache SeaTunnel的社区活跃度非常高,作为一个由国内开发者主导的社区,我们与社区的其他成员,包括高老师和海林老师等,有着非常顺畅的交流和合作,他们提供的及时指导和问题分析对我们帮助巨大。社区还定期举办周会,为大家提供了一个讨论设计模式、分享问题解决方案的平台。
统一数据集成服务
当前设计
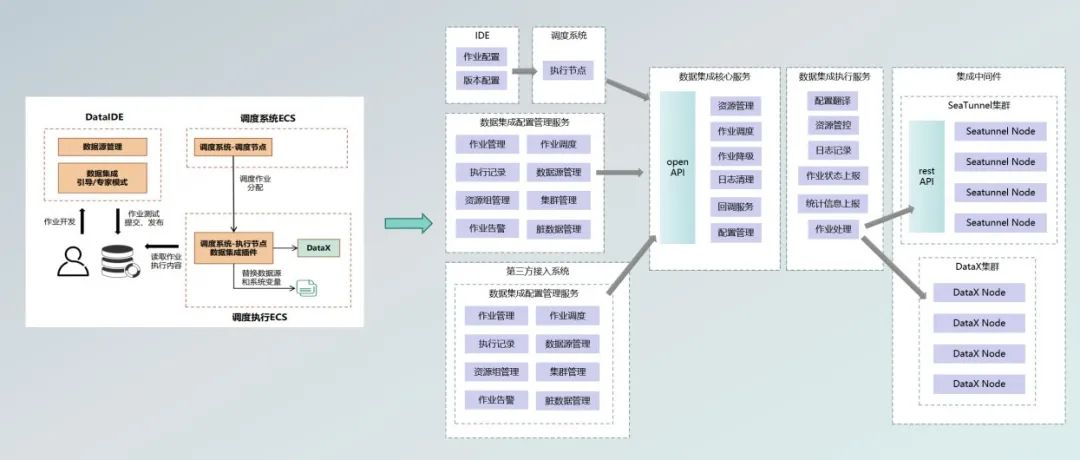
我们打造了一个统一的数据服务平台,这一平台将数据源管理和数据集成的配置过程简化,支持数据开发流程从开发到测试再到发布的全过程。我们通过在IDE中管理数据源和集成配置,然后通过调度系统在夜间分配作业到执行节点,进一步提高了数据处理的自动化和效率。
这种方式虽然有效,但我们意识到在服务化方面还有提升空间,特别是考虑到在高负载情况下CPU资源的高消耗和对监控和作业管理的需求。
服务化设计
为了解决这些挑战,我们决定将部分功能从调度系统中独立出来,使得调度更加纯粹和高效。我们的目标是将数据集成服务转变为SaaS模式,以便更好地集成进我们内部的各种系统中,并快速接入集成服务能力(例如如CDP系统和自助报表平台)。
该服务类似于Apache SeaTunnel Web,能够配置作业、设置调度模式、查看执行记录以及管理数据源。为了提高灵活性和方便未来的集群升级,我们引入了名为“quota”的虚拟资源组概念,我们的设计包括两种集群:主执行集群和备用执行集群,用以支持作业的自动降级。
在理想情况下,主执行集群使用SeaTunnel,而在备用执行集群中使用Data X。这种设计模仿了如B站等公司内部采用的Data X和Apache SeaTunnel并行系统,目的是在单一系统内实现作业的无缝降级,例如当SeaTunnel作业失败时,系统会尝试在Data X集群上重新调度执行该作业。
为了管理这一复杂的流程,我们设计了核心服务和执行服务。核心服务负责作业的调度、降级、日志清理、回调服务以及配置和资源管理。执行服务则专注于作业的实际执行和监控,包括作业执行线程和协调线程。
在作业执行前,我们会根据作业配置和集群资源情况来决定作业在哪个集群上执行,并确保有足够资源来执行作业。
Datax作业迁移
我们还着重进行了Data X到SeaTunnel的迁移工作。
插件兼容性
这包括对比社区提供的连接器和我们内部使用的插件功能,确保它们之间的兼容性,并对最常用的数据回流场景进行了特别关注,即从MC到ClickHouse(CK)的数据回流任务。我们有大约3.4万个任务,其中约1.4万个任务专门用于将自助分析报表的底层元数据日常推送至CK,针对这些场景我们进行了特定的兼容性开发。
作业切换接口
为了支持作业的平滑迁移和开发,我们实现了一个作业开发切换接口。这允许我们基于作业号和连接器的适配情况,灵活地进行作业迁移。迁移完成后,新任务会被注册到集成服务中,并以公共配置格式保存,从而便于在管理服务端通过脚本模式或页面引导化配置进行操作。
配置抽象
我们制定了一套内部公共配置标准,旨在兼容Apache SeaTunnel和Data X作业的配置方式。这一做法不仅简化了多环境数据源的替换过程,还增强了安全性,避免了在配置中直接暴露敏感信息如用户名和密码。
我们在作业执行前进行作业配置翻译,这种设计参考了Seatunnel的翻译层设计,包括本地变量和数据源参数的替换,以及针对不同引擎的配置翻译。这种双层翻译机制,一层负责将特定中间件插件配置转换为公共配置(Pre transform),另一层则将公共配置转换为指定引擎配置(正常的transform),极大地增强了作业配置的灵活性和兼容性。 一个公共层的存在是必要的,因为它允许在不同数据集成工具之间进行灵活的翻译和配置转换,从而实现数据服务执行在多引擎间的执行降级;
Zeta 集群资源管控
问题:Zeta资源管理Slot目前仅是逻辑隔离,若采用动态slot模式,会创建大量线程进行资源争抢,一定程度会拖慢多并发作业的整体速度,或导致集群OOM。该模式比较适合于CDC实时同步多批次,少数据量分片的场景。
解决方案
- 使用静态slot模式
对于离线批处理任务,该模式更为合适,其可以一定程度的控制资源消耗,防止因大量数据缓存导致的内存溢出(OM)问题。 根据集群的CPU/内存大小进行评估,适当的CPU超卖,并配置合适的资源槽数量,以确保数据处理作业的效率和集群资源的有效利用。
- 新增集群slot服务RestApi
通过扩展SlotService和ResourceManager,在Hazelcast中扩展存储集群全slot和已分配slot情况 ,并完善集群启动、节点上下线、作业提交、作业释放时的slot资源情况处理,并提供RestApi查询。
- 作业slot计算
早期,我们尝试根据物理执行计划来评估作业的并发度,但后来的版本变更要求我们基于作业配置来进行slot资源计算。 在并发度一致的情况下,作业资源占用计算公式如下:
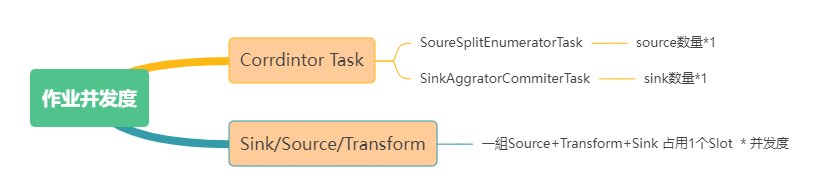
该方法可以适用于大多数端到端数据同步场景,但在更复杂的作业配置中,这种方法可能不够灵活。我们也期待社区内部实现一个类似SQL explain的API进行资源计算。
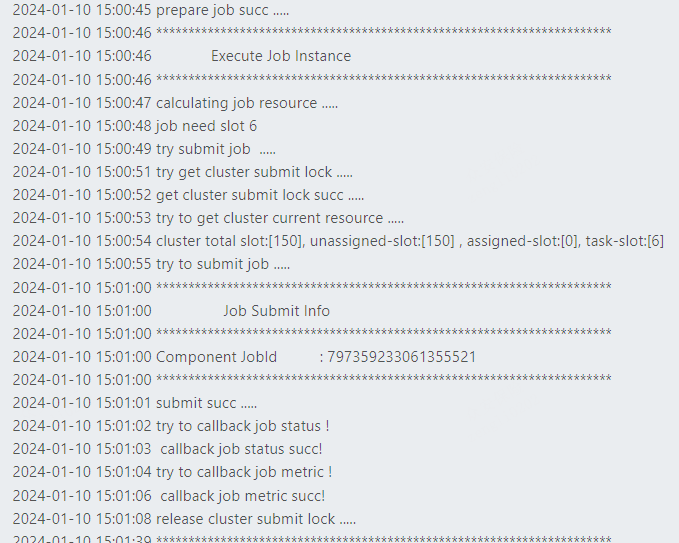
- 作业控制
作业提交前根据配置计算消耗的slot资源; 作业提交前会校验集群slot资源总数和可用资源是否可以满足作业资源消耗,若可以则通过RestApi提交;
Zeta RestAPI 对接问题
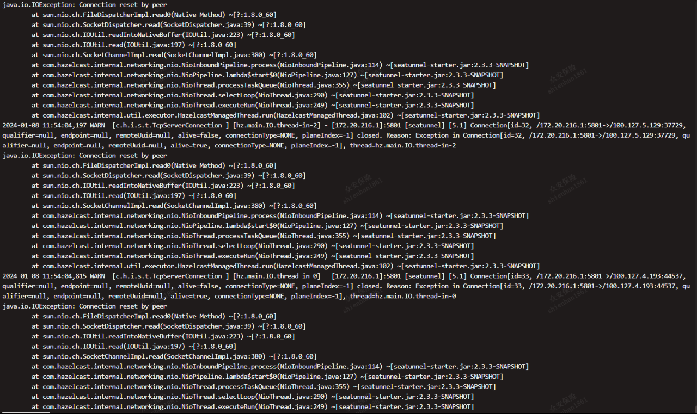
问题
集群http服务地址挂载阿里云slb之后,发现集群大量连接被远程关闭的错误。 原因:slb开启健康检查后,发起探测会发送syn包,后端响应syn+ack,然后会重置连接。 解决方案:在尝试hazelcast组网模式和slb配置均未有效的情况下,我们再服务端通过集群配置信息,在http请求前进行了一次随机路由处理;
问题
非Master节点无法处理作业提交、终止、集群slot获取等操作 原因:2.3.3版本通过HazelcastInstance在非master节点上无法获取Master服务的相关实例;
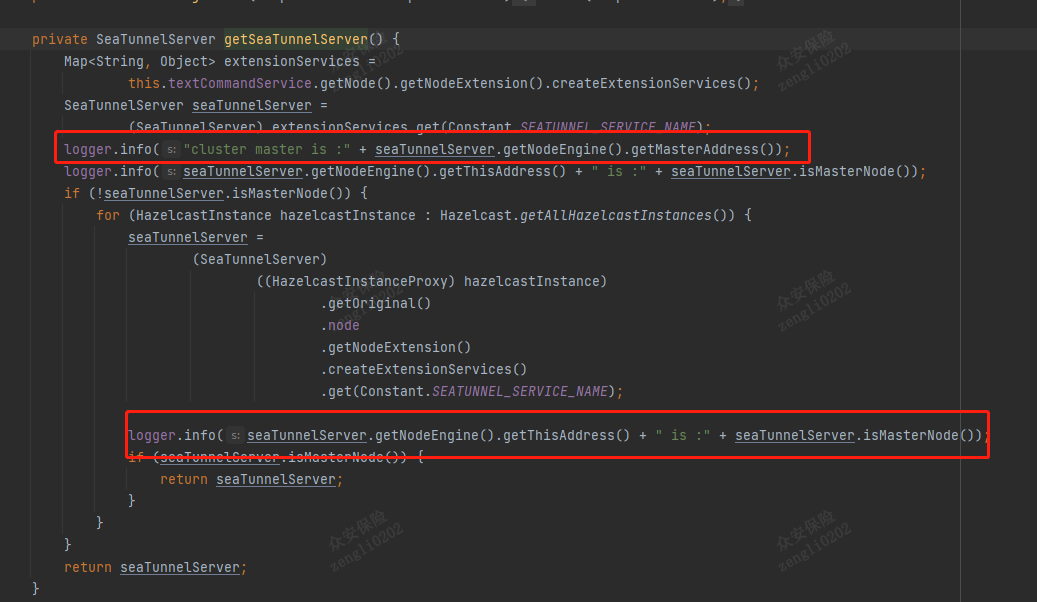
Hazelcast.getAllHazelcastInstances() 并没有多个,是还需要有额外的代码来修改么,无法跨节点提交作业。
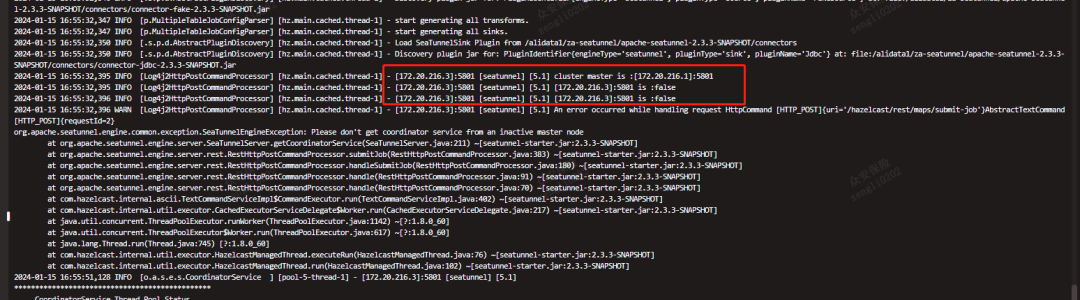
解决方案:一个通用的想法是模拟SlotService,将统计信息带给Master,通过hazelCast的Operation机制,参考HeartbeadHealthOperation机制,通过存量的GetMetricsOperation去Master节点进行获取。
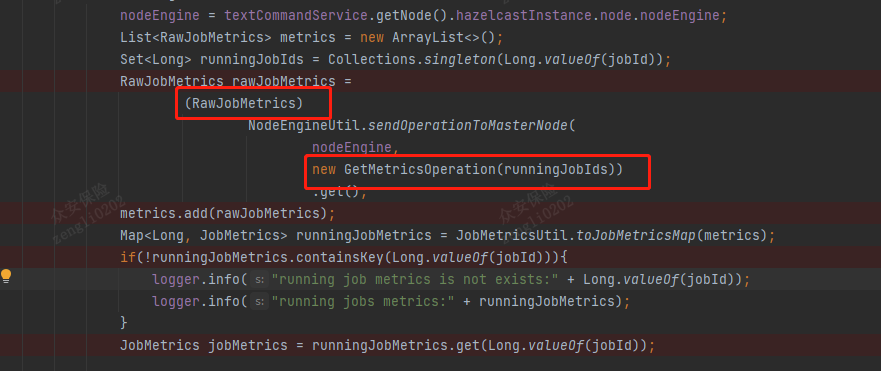
后期我们把该思路提供给了社区,社区相关同学也完善了作业提交、终止等接口的修改。
Connector 支持pre/post sql
在Apache SeaTunnel的实践中,特别是在处理ClickHouse (CK) 报表数据时,连接器的Pre和Post SQL功能展现了其对复杂数据处理场景的高度适应性。这些功能允许在数据同步任务执行前后,执行特定的SQL语句,为数据处理提供了更大的灵活性和精确控制。
使用场景
主要应用场景包括数据同步前的准备工作和同步后的清理或重组工作。例如,在推送数据到CK报表前,而不是直接覆盖或删除当前表,数据可能首先写入一个临时表中。完成数据写入后,可以通过执行Post SQL语句对local表进行重命名操作,并将其挂载到分区表中,这种方法有效避免了数据同步过程中的数据丢失或不一致问题。
PreSql实践
问题:前期版本不支持,仅能通过XxxSink中prepare方法实现,但该接口后续会被取消;
解决方案:Apache SeaTunnel社区版本2.3.4提出了schema save mode和data save mode的组合作为一种解决方案,支持在数据同步前执行SQL语句(Pre SQL)。这种方法的引入大大增强了Apache SeaTunnel在数据同步场景中的灵活性和可用性。我们通过data save mode中的CUSTOM_PROCESSING模式实现preSql执行,并扩展至可支持执行多段SQL;
PostSql实践
问题:在XxxSink或XxxSinkWriter中close方法实现,会出现多并发冲突问题;
解决方案:对于Post SQL的支持,尤其在多线程环境中保证数据完整性和一致性的挑战更为复杂。通过在二阶段提交的close方法中执行Post SQL语句,提供了一种可行的解决方案。这种方法初步实现了在数据同步任务完成后进行必要的后处理操作的能力。
我们也遇到的一个挑战是处理Post SQL执行失败的情况。这个问题在1月4日的发版前测试中被发现,测试团队仔细检查了当Post SQL执行失败时的系统行为。
发现执行失败后,Subplan的重试机制(reApache SeaTunnelore处理)导致作业状态管理存在问题,作业无法正常终止。作为临时解决方案,将Subplan的pipeline最大重试次数(Max reApache SeaTunnelore number)设置为0(默认值为3),这意味着在离线批处理场景下,一旦出现错误,系统将直接报错并终止作业。
这个措施虽然可以暂时解决问题,但需要进一步与社区合作探讨更根本的解决方案。
同时我们也期待社区会有更好的做法来实现PostSql,因为二阶段提交close方法执行SQL意味着作业checkpoint已经刷新完毕,这时出现异常,可能对现有机制产生一定影响。
Connector 列隐式转换
问题
在数据同步和集成过程中,数据源与目标存储之间的数据类型匹配和转换是一个常见的问题。Apache SeaTunnel中的连接器和框架层级可能没有进行充分的列隐式转换处理,导致无法有效地将数据写入到目标数据源的对应字段中。我们在连接器适配DataX特性改造时,发现在连接器和框架层面均未进行列隐式转换。
例如SeatunnelRowType对应的第一列是String类型,数据为2023-12-01 11:12:13,其无法写入字段为Datetime类型的Maxcompute字段当中。
解决方案
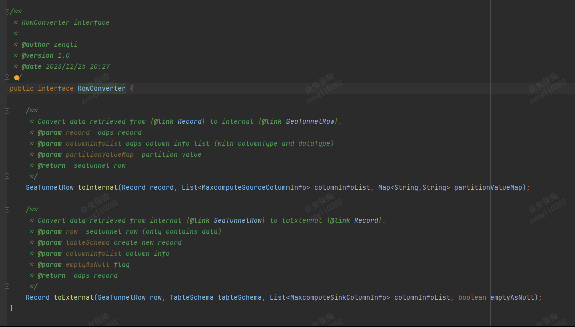
连接器级别实现了一个简单的RowConverter, 将结合SeatunnelRowType中的字段类型、对应的Maxcompute字段类型进行映射转换。后期考虑接入社区常用类型默认转换特性。
pull request地址:https://github.com/apache/seatunnel/pull/5872
Connector 部分列同步
问题
我们在连接器适配DataX特性改造时,DataX支持部分列回流及部分列写入;Seatunnel连接器目前在source端部分连接器有实现,sink端基本是全字段写入;
解决方案
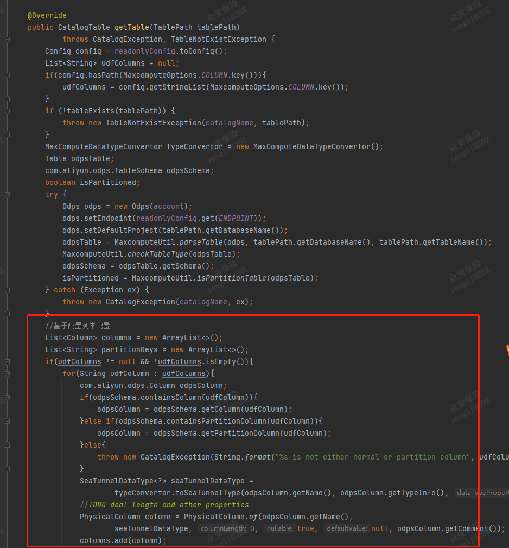
Source端:我们可以将自定义列(而非全表列)设置在CatalogTable当中,同理DataX当中类似分区列、常量列的回流也可以通过相同的方式得以实现,并透传到执行计划当中,为Sink端所获取;jdbc连接器可以通过query sql选择合适的列;
Sink端:目前可以根据SeaTunnelRow的index位置和自定义列中的index进行对齐,实现部分写入;jdbc连接器可以通过insert指定列进行处理。
随着Apache SeaTunnel的成功实施,众安保险在数据集成领域迈出了坚实的步伐。我们期待在不断变化的技术环境中继续优化我们的数据流程,以支持业务的快速发展和创新需求。
众安保险的这一实践案例,证明了开源技术在企业级应用中的潜力和价值,展示了开放合作精神对于推动行业发展的重要性,也希望能够给大家带来一些启发!
本文由 白鲸开源科技 提供发布支持!