【PyTorch修炼】用pytorch写一个经常用来测试时序模型的简单常规套路(LSTM多步迭代预测)
层数的理解:
LSTM(长短期记忆)的层数指的是在神经网络中堆叠的LSTM单元的数量。层数决定了网络能够学习的复杂性和深度。每一层LSTM都能够捕捉和记忆不同时间尺度的依赖关系,因此增加层数可以使网络更好地理解和处理复杂的序列数据。

LSTM方法:
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltimport torch
import torch.nn as nnx = torch.linspace(0, 999, 1000)
y = torch.sin(x*2*3.1415926/70)plt.xlim(-5, 1005)
plt.xlabel('x')
plt.ylabel('sin(x)')
plt.title("sin")
plt.plot(y.numpy(), color='#800080')
plt.show()x = torch.linspace(0, 999, 1000)
y = torch.sin(x * 2 * 3.1415926 / 100) + 0.3 * torch.sin(x * 2 * 3.1415926 / 25) + 0.8 * np.random.normal(0, 1.5)plt.plot(y.numpy(), color='#800080')
plt.title("Sine-Like Time Series")
plt.xlabel('Time')
plt.ylabel('Value')
plt.show()train_y= y[:-70]
test_y = y[-70:]def create_data_seq(seq, time_window):out = []l = len(seq)for i in range(l-time_window):x_tw = seq[i:i+time_window]y_label = seq[i+time_window:i+time_window+1]out.append((x_tw, y_label))return out
time_window = 60
train_data = create_data_seq(train_y, time_window)class MyLstm(nn.Module):def __init__(self, input_size=1, hidden_size=128, out_size=1):super(MyLstm, self).__init__()self.hidden_size = hidden_sizeself.lstm = nn.LSTM(input_size=input_size, hidden_size=self.hidden_size, num_layers=1, bidirectional=False)self.linear = nn.Linear(in_features=self.hidden_size, out_features=out_size, bias=True)self.hidden_state = (torch.zeros(1, 1, self.hidden_size), torch.zeros(1, 1, self.hidden_size))def forward(self, x):out, self.hidden_state = self.lstm(x.view(len(x), 1, -1), self.hidden_state)pred = self.linear(out.view(len(x), -1))return pred[-1]time_window = 60
train_data = create_data_seq(train_y, time_window)learning_rate = 0.00001
epoch = 13
multi_step = 70model=MyLstm()
mse_loss = nn.MSELoss()
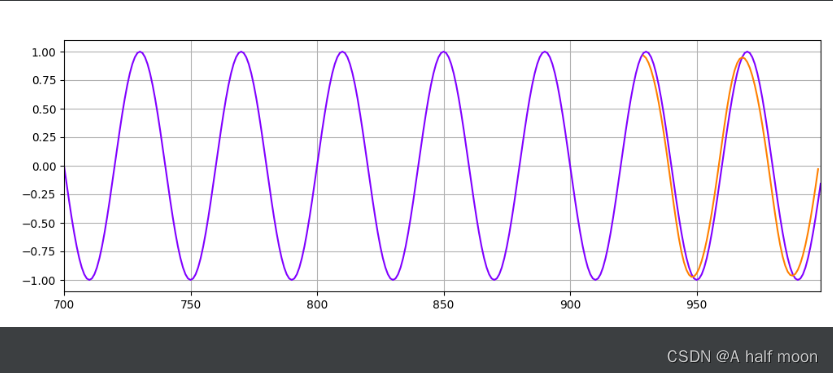
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate,betas=(0.5,0.999))for i in range(epoch):for x_seq, y_label in train_data:x_seq = x_seq y_label = y_label model.hidden_state = (torch.zeros(1, 1, model.hidden_size) ,torch.zeros(1, 1, model.hidden_size) )pred = model(x_seq)loss = mse_loss(y_label, pred)optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {i} Loss: {loss.item()}")preds = []labels = []preds = train_y[-time_window:].tolist()for j in range(multi_step):test_seq = torch.FloatTensor(preds[-time_window:]) with torch.no_grad():model.hidden_state = (torch.zeros(1, 1, model.hidden_size) ,torch.zeros(1, 1, model.hidden_size) )preds.append(model(test_seq).item())loss = mse_loss(torch.tensor(preds[-multi_step:]), torch.tensor(test_y))print(f"Performance on test range: {loss}")plt.figure(figsize=(12, 4))plt.xlim(700, 999)plt.grid(True)plt.plot(y.numpy(), color='#8000ff')plt.plot(range(999 - multi_step, 999), preds[-multi_step:], color='#ff8000')plt.show()
class SimpleMLP(nn.Module):def __init__(self, input_size=60, hidden_size=128, output_size=1):super(SimpleMLP, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, output_size)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return xmlp_model = SimpleMLP()
mse_loss = nn.MSELoss()
optimizer = torch.optim.Adam(mlp_model.parameters(), lr=0.0001)
for i in range(epoch):for x_seq, y_label in train_data:x_seq = x_seqy_label = y_labelpred = mlp_model(x_seq)loss = mse_loss(y_label, pred)optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {i} Loss: {loss.item()}")preds = []labels = []preds = train_y[-time_window:].tolist()for j in range(multi_step):test_seq = torch.FloatTensor(preds[-time_window:])with torch.no_grad():preds.append(mlp_model(test_seq).item())loss = mse_loss(torch.tensor(preds[-multi_step:]), torch.tensor(test_y))print(f"Performance on test range: {loss}")plt.figure(figsize=(12, 4))plt.xlim(700, 999)plt.grid(True)plt.plot(y.numpy(), color='#8000ff')plt.plot(range(999 - multi_step, 999), preds[-multi_step:], color='#ff8000')plt.show()生成的一个带些随机数的正弦波:y = torch.sin(x * 2 * 3.1415926 / 100) + 0.3 * torch.sin(x * 2 * 3.1415926 / 25) + 0.8 * np.random.normal(0, 1.5)
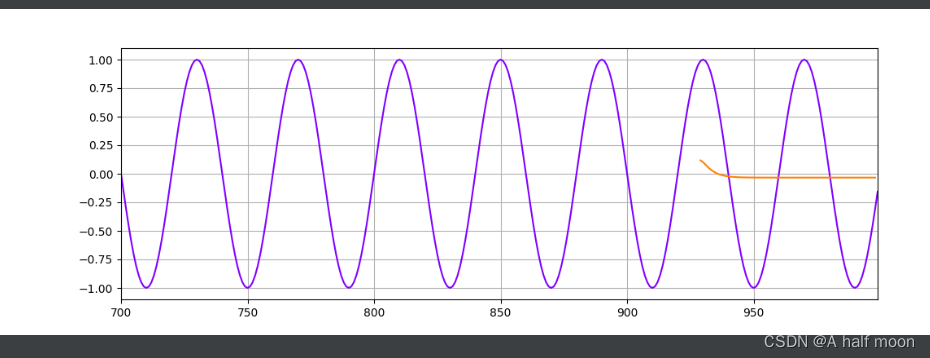
结果发现:MLP效果比LSTM好?!
MLP:
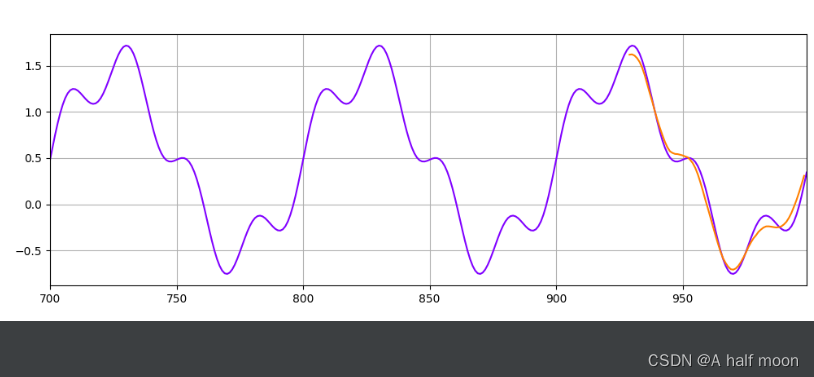
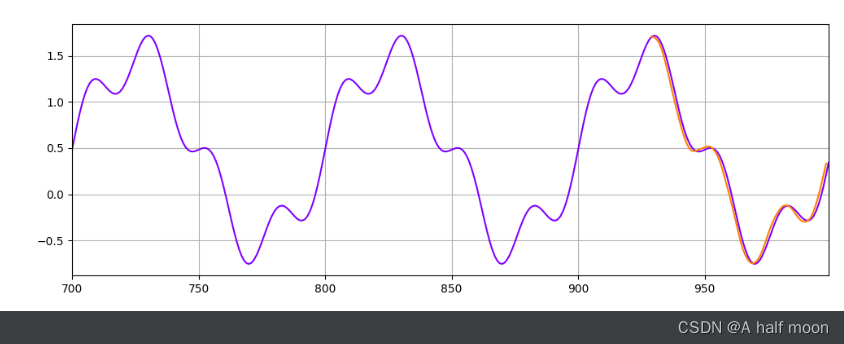
偶然有不是很准,但大部分非常准
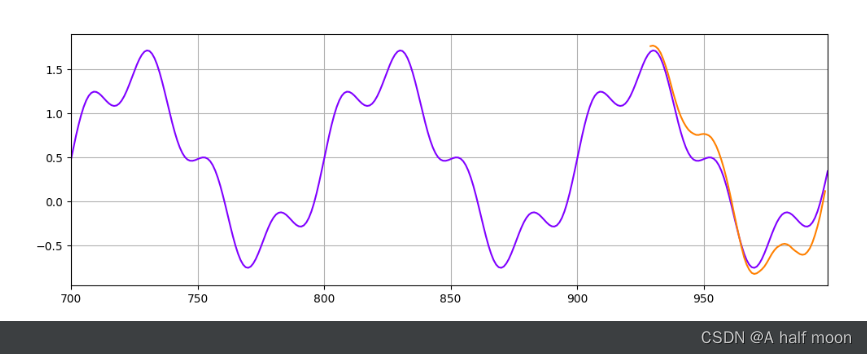
LSTM:
就很奇怪?
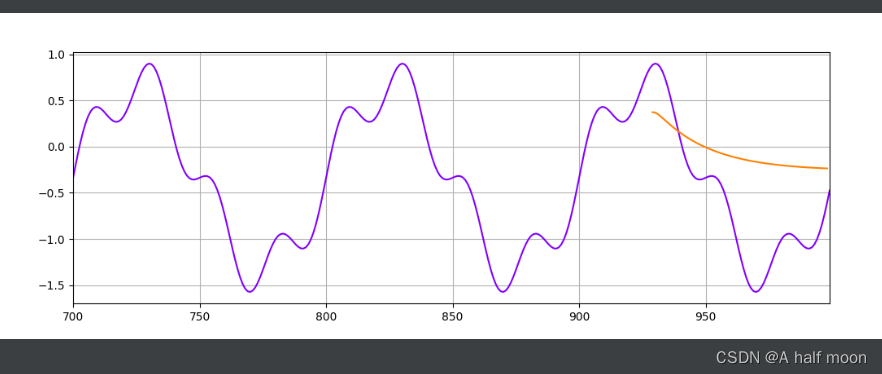
但是如果是纯正弦波 y = torch.sin(x23.1415926/70) ,规律太明显了,好像效果都还行:
MLP:
简单聪明的MLP第一轮就学会了
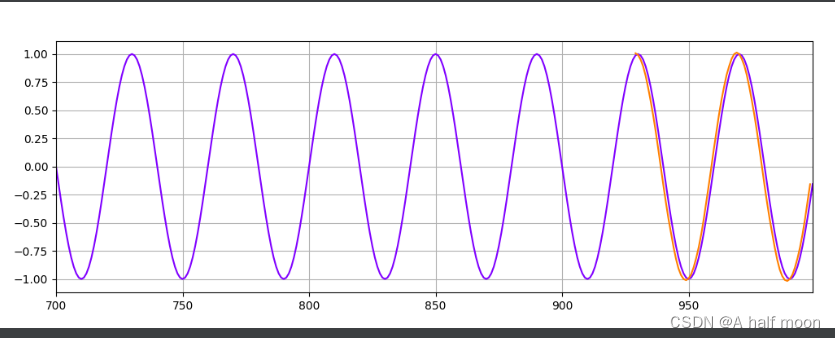
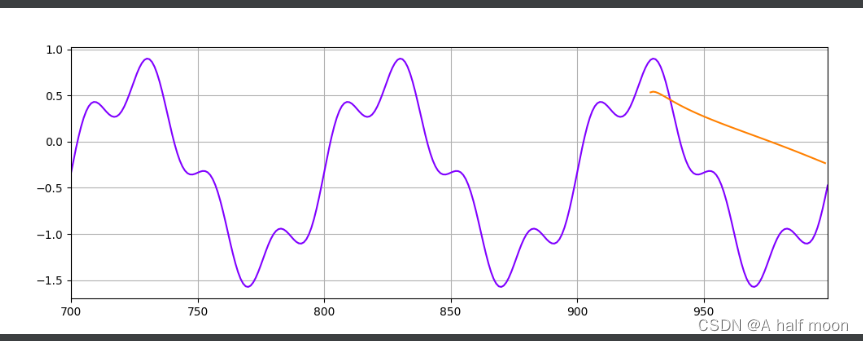
LSTM:
开始几轮还有些懵
后边就悟了