文章目录
- 1、kafka简单介绍
- 2、kafka使用场景
- 3、kafka基本概念
- 4、kafka集群
- 1、数据冗余
- 2、分区的写入
- 1、使用 Partition Key 写入特定 Partition
- 2、由 kafka 决定
- 3、自定义规则
- 3、读取分区数据
- 5、提交策略
- 6、kafka如何保证高并发
1、kafka简单介绍
kafka是一款分布式、支持分区的、多副本,基于zookeeper协调的分布式消息系统。最大的特性就是可以实时处理大量数据来满足需求。
2、kafka使用场景
- 日志收集:可以用kafka收集各种服务的日志 ,通过已统一接口的形式开放给各种消费者。
- 消息系统:解耦生产和消费者,缓存消息。
- 用户活动追踪:kafka可以记录webapp或app用户的各种活动,如浏览网页,点击等活动,这些活动可以发送到kafka,然后订阅者通过订阅这些消息来做监控。
- 运营指标:可以用于监控各种数据。
3、kafka基本概念
kafka是一个分布式的分区的消息,提供消息系统应该具备的功能。
| 名称 | 解释 |
|---|---|
| broker | 消息中间件处理节点,一个broker就是一个kafka节点,多个broker构成一个kafka集群。 |
| topic | kafka根据消息进行分类,发布到kafka的每个消息都有一个对应的topic |
| producer | 消息生产(发布)者 |
| consumer | 消息消费(订阅)者 |
| consumergroup | 消息订阅集群,一个消息可以被多个consumergroup消费,但是一个consumergroup只有一个consumer可以消费消息。 |
| partition | 分区,一个topic可以对应多个分区 |
| replica | 副本,是一个只能追加写消息的日志文件 |
| offset | 偏移量 |
kafka中的topic被分为了多个partition分区。topic实际上是一个逻辑概念,partition是最小的存储单元,存储着一个topic的部分数据。每个partition都是一个单独的log文件,每条记录都以追加的形式写入。
partition中的每条记录都会被分配一个特有的offset,当一条记录写入时,他会追加到log文件的末尾,并分配一个序号,作为一个offset。
这里需要注意顺序消费的场景。每个topic对应多个partition,这些分区是无序的,但是分区里面的数据是有序的,所以我们在做顺序消费的场景的时候,需要注意要将消息放到一个partition。
4、kafka集群
kafka支持集群化部署就是依赖于分区机制。
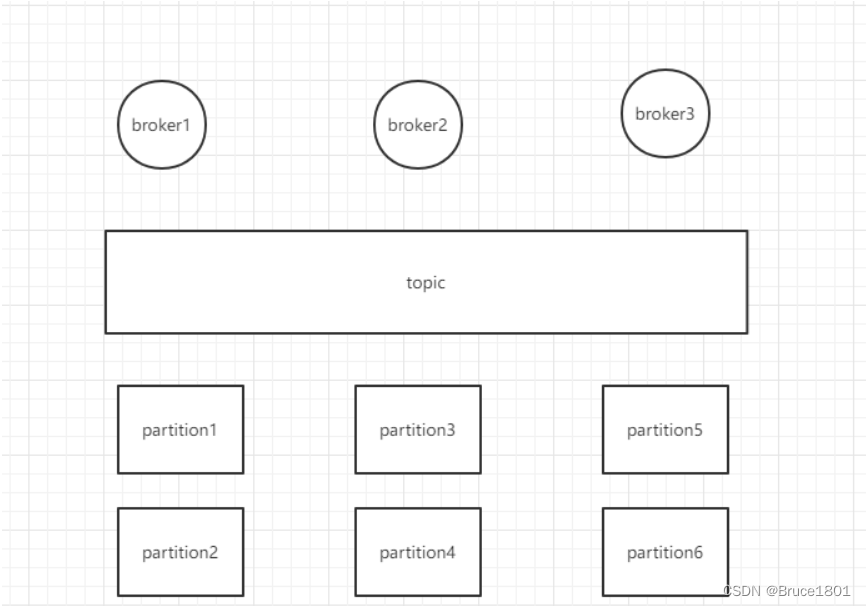
这么设计的优点:
1,如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之后,Topic 就可以水平扩展 。
2,一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持更多的 Consumer。
3,一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。
1、数据冗余
在kafka集群中,kafka为Partition做了数据冗余处理,这样即使一个broker挂了,消费者也可以在其他broker找到这个partition。
2、分区的写入
既然一个topic可以有多个Partition,那么消息进来的时候,到底该进那个Partition呢,kafka提供了三种模式
1、使用 Partition Key 写入特定 Partition
Producer 发送消息的时候,可以指定一个 Partition Key,这样就可以写入特定 Partition 了。
Partition Key 可以使用任意值,例如设备ID、User ID。
Partition Key 会传递给一个 Hash 函数,由计算结果决定写入哪个 Partition。
所以,有相同 Partition Key 的消息,会被放到相同的 Partition。
例如使用 User ID 作为 Partition Key,那么此 ID 的消息就都在同一个 Partition,这样可以保证此类消息的有序性。
这种方式需要注意 Partition 热点问题。
例如使用 User ID 作为 Partition Key,如果某一个 User 产生的消息特别多,是一个头部活跃用户,那么此用户的消息都进入同一个 Partition 就会产生热点问题,导致某个 Partition 极其繁忙。
2、由 kafka 决定
如果没有使用 Partition Key,Kafka 就会使用轮询的方式来决定写入哪个 Partition。
这样,消息会均衡的写入各个 Partition。
但这样无法确保消息的有序性。
3、自定义规则
Kafka 支持自定义规则,一个 Producer 可以使用自己的分区指定规则。
3、读取分区数据
通常Kafka产生堆积的原因都是消费速率跟不上生产速率,生产者发送消费没有什么业务逻辑,而消费者消费时需要等待业务逻辑处理。因此,我们来看看“不考虑优化业务逻辑的前提下,如何通过设置合理的Topic分区数来提高消费能力”。
1,不确定生产速率和消费速率:分区数 = 部署的服务实例数
当研发人员需要申请新的Topic但还无法预估生产者和消费者处理消息的能力时,可以先按照标准场景申请与 服务实例数 相等的分区数。
2,明确生产速率低于消费速率:分区数 = 部署的服务实例数
当业务系统稳定运行并且确定Topic的平均生产速率低于消费速率时,也应该申请与 服务实例数 相等的分区数,避免消息突增时作为消费者的服务实例负载倾斜。
3,生产速率高于消费速率(同时增加分区数和服务实例数):分区数 = 部署的服务实例数
当业务能预估到消息的生产速率高于消费速率,最直接的方式就是同时增加分区数和服务实例数,从而提高整体消费速率。但往往在非必要的情况下增加服务实例数会导致严重的资源浪费,因此在不增加服务实例数的前提下,也可以通过提高单机 并行度 来提高消费速率。
4,生产速率高于消费速率(增加分区数,服务实例数不变):分区数 = 部署的服务实例数 * N
承接上一个场景,假设服务实例数为4,需要申请12个分区,那么单机 并行度 = 3,并行度在消费者注解中添加
5、提交策略
1,自动提交:默认配置(配置中心公共配置)为自动提交,即每隔一段时间(默认5s)提交一次,自动提交可以很大程度上降低Kafka服务端的压力,并且减少客户端的网络开销,如果消费逻辑做好了业务幂等,尽可能选择自动提交。
实际上自动提交并不是严格地每间隔一段时间提交一次偏移量(旧版的客户端是有一个AutoCommitTask进行轮询提交),而是每次在调用 KafkaConsumer.poll()时判断当前时间距离上次提交时间是否超过了配置了提交间隔,如果超过了就进行提交,所以实际上的提交时间会超过配置的提交间隔。另外由于KafkaConsumer.poll()方法会返回多条消息(由配置项,max.poll.records控制),因此如果上一批消息消费耗时超过提交间隔,也会导致实际提交时间推迟。
2,手动提交:即spring.kafka.consumer.enable-auto-commit=false,设置手动提交时需要主动调用提交方法,具体方法根据使用的客户端而定。当消息量较大时使用手动提交会给Kafka服务端带来压力,并增加客户端的网络开销,不过还是建议重要消息或者是无法保证业务幂等的消费逻辑使用手动提交。
使用kafka-client:Kafka自带的客户端,需要主动调用KafkaConsumer.commitSync()或KafkaConsumer.commiAsync()进行偏移量提交。
使用spring-kafka:基于spring和kafka-client封装的高阶API,当是否自动提交设置为false时,每消费完一条消息就会自动提交一次偏移量(同步提交),无需手动调用API提交。
6、kafka如何保证高并发
kafka的高并发依赖于页缓存技术和磁盘顺序写。
有研究表名,在磁盘中的顺序读写要比在内存中的随机读写要快。
页缓存技术是操作系统级别的缓存(page cache),即先将数据写入到系统缓存中(内存),并且是只写入到内存中,由操作系统决定什么时候写入磁盘。
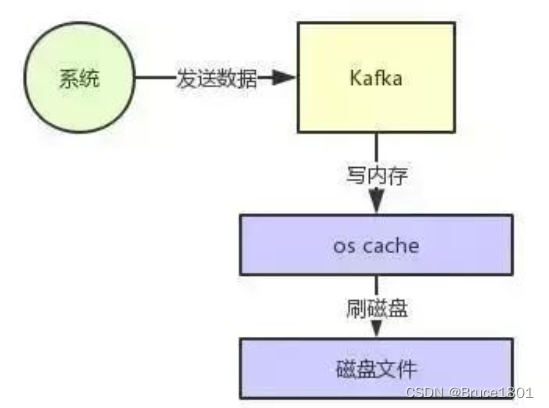
kafka在写数据的时候,是以顺序写的方式来刷盘的,即只在文件末尾来追加数据,而不是在文件的随机位置写入数据。
上面那个图里,Kafka 在写数据的时候,一方面基于 OS 层面的 Page Cache 来写数据,所以性能很高,本质就是在写内存。
另外一个,它是采用磁盘顺序写的方式,所以即使数据刷入磁盘的时候,性能也是极高的,也跟写内存是差不多的。