1. 初识http
HTTP 最新的版本应该是 HTTP/3.0,目前大规模使用的版本 HTTP/1.1;
下面来简单说明一下使用 HTTP 协议的场景:
1、浏览器打开网站 (基本上)
2、手机 APP 访问对应的服务器 (大概率)
前面的 TCP与UDP 和http不同,HTTP 的报文格式,主要分两个部分来看待:请求与响应,因为HTTP 协议,是一种"一问一答"结构模型的协议,同时请求和响应的协议格式,是有所差异的
1.1 抓包工具
1.1.1 下载和安装fiddler
我们如果要查看到 HTTP 请求和响应的格式就需要使用抓包工具,所谓的抓包就是把网卡上经过的数据获取到,并显示出来;
下面主要学习一下fiddler的下载和使用:
1.1.2 fiddler的介绍
fiddler 打开之后,是一个左右结构的程序,左侧有一个列表,列出了抓到的包有哪些,右侧则是包的详情:
点击某个包后如下图所示:
右侧上方,是请求详情
右侧下方,是响应详情:
新安装的 fiddler 需要手动开启 HTTPS 功能,并且安装证书(否则只能抓 http),主要是因为当前互联网环境上,HTTPS 为主,纯 HTTP 非常少见了,操作如下:

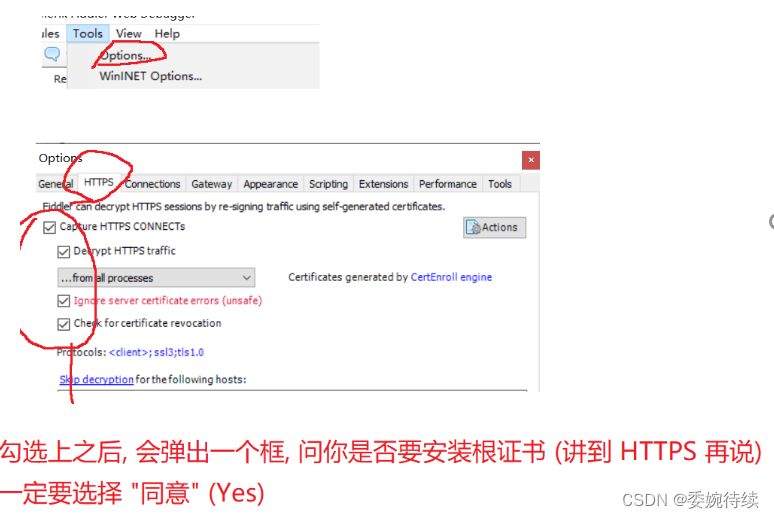
Fiddler 本质上是一个"代理”,可能会和其他的代理软件冲突;
1.1.3 fiddler 实际使用
1、 ctrl +a全选所有的请求.,delete 删除,对于左侧fiddler抓到的包,根据不同的颜色来进行简单的区分:
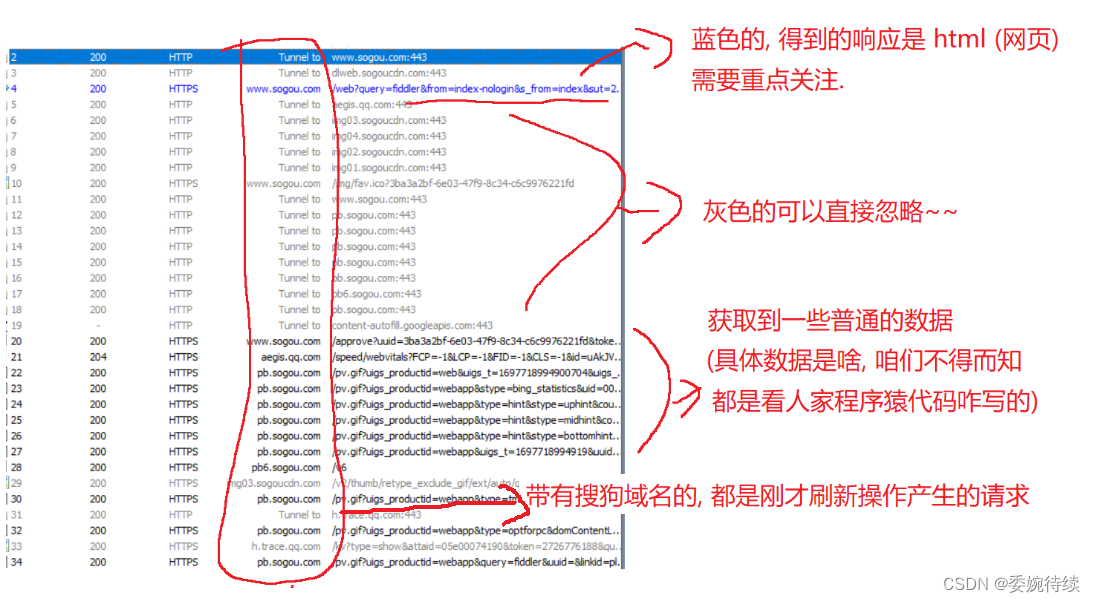
当我们打开一个网页的时候,往往不只是和服务器进行一次操作,大概率是多次操作
1、关于请求
点击左侧抓到的包,之后进行下面操作:
点击如下操作:
得到详细的请求信息:
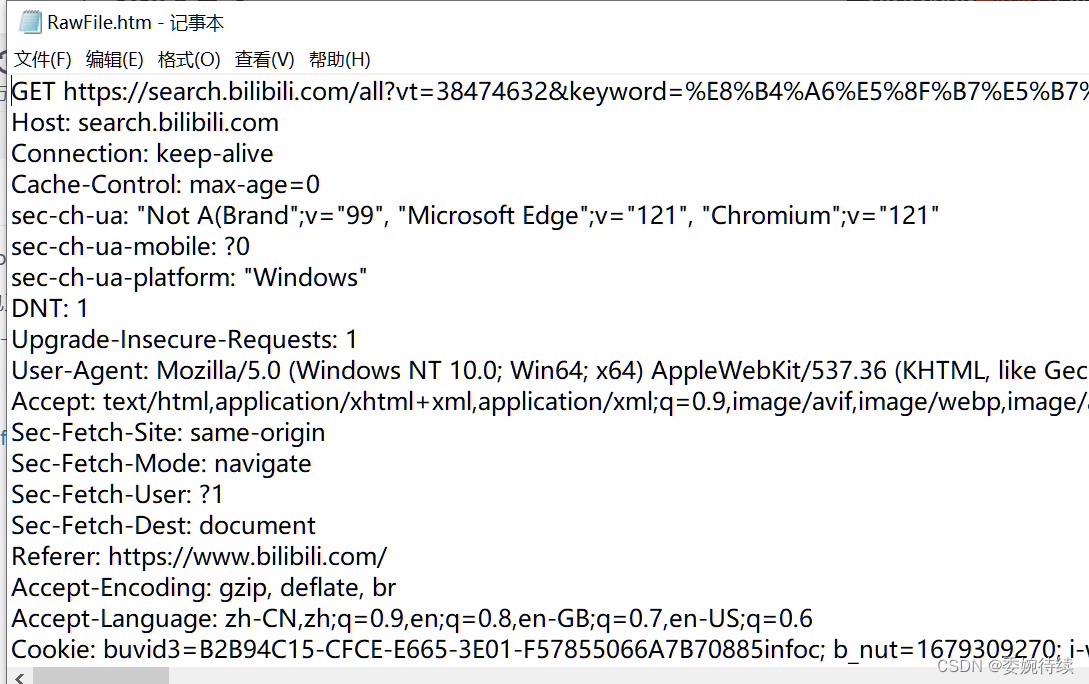
这里注意HTTP 协议是文本格式的协议(协议里的内容都是字符串);TCP,UDP,IP... 都是二进制格式的协议
2、关于响应
HTTP 响应也是文本的.直接査看,往往能看到二进制的数据(压缩后的);至于HTTP 响应经常会被压缩,且压缩之后,体积变小, 传输的时候,节省网络带宽(台服务器,最贵的硬件资源, 就是网络带宽,但是,压缩和解压缩,是需要消耗额外的 cpu 和 时间的)
下面进行解压缩操作:
查看响应信息:
解压缩之后,可以看到,响应的数据其实是 html;浏览器上显示的网页,就是 html,,往往都是浏览器先请求对应的服务器,从服务器这边拿到的页面数据 (html)
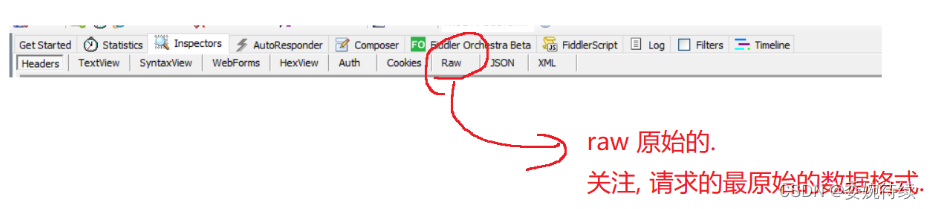

1.2 关于请求和响应
请求的格式如下:
1、首行
HTTP 请求的第一行,有三个部分信息,三个部分使用空格分割
1) 、GET, HTTP 请求的"方法”(method)
2)、URL 唯一资源定位符,描述了一个资源在网络上的位置。
3) 、版本号:HTTP/1.12、请求头 (header)
是一个键值对结构的数据.(有很多键值对),每个键值对, 都是独占一行的。键和值之间,使用 :空格来区分,这里的键值对都是属于"标准规定”的。3、空行
请求头的结束标记4、正文 (body)
有的 HTTP 请求有,有的没有。

响应的格式如下:
1、首行
1)、版本号 HTTP/1.1
2)、状态码(200) 描述了请求的结果.
3)、状态码描述(OK)2、响应头 (header)
也是键值对结构(有多个键值对),每个键值对独占一行,键和值之间使用 :空格 来区分.
键值对也是"标准规定” 的;3、空行
响应头的结束标记4、正文 (body)
正文里的内容可能比较长,也可能是多种格式包括HTML, CSS,JS,JSON,XML, 图片, 字体,视频,音频..

1.3 关于URL
URL是计算机中的非常重要的概念,不仅仅是在 HTTP 中涉及到,我们之前学习jdbc的时候就接触到的,如下所示:

同时下面就是对url的详细讲解:

#ch1 片段标识符:
有的网页内容比较长,就可以分成多个"片段”,通过片段标识符,就可以完成页面内部的跳转;
对于 query string 来说,如果 value 部分要包含一些特殊符号的话,往往需要进行 urlencode 操作。主要是因为+?:/. 这些符号在 url 中都已经有特殊用途了,如果在 value 中,也包含特殊符号,可能就会使浏览器/http服务器,对于 url 的解析就出现 bug ,urlencode 本质上是一种"转义字符",+的 ascii 就是 2B, 在前面加上 % 表示这是转义的结果,即效果如下所示:

2. 深入学习http
2.1 连接请求的方法
GET 请求,通常会把要传给服务器的数据,加到 url的 query string 中;POST 请求,通常把要传给服务器的数据,加到 body 中.
1、 关于找到html网页的分析:
蓝色字体,是获取到网页 (得到 html 的响应),如下所示:
首先刚才最开始没有抓到这里的返回页面的请求是因为命中了浏览器缓存;
其次浏览器显示的网页,其实是从服务器这边下载的 htnml,htm| 内容可能比较多,体积可能比较大,通过网络加载,消耗的时间就可能会比较多,浏览器一般都会自己带有缓存,就会把之前加载过的页面,保存在本地硬盘上,再次访问就直接读取本地硬盘的数据即可;
2、对于在网页上上传图片进行抓包;
上传头像的 body 比较长,body 就是图片本体,图片本身是二进制数据,此处把图片放到 http 请求中,往往要进行base64 转码,
所谓的base64 转码,就是针对二进制数据重新编码(转义),确保编码之后的数据就是纯文本的数据

2.2 学习http请求的方法
http的请求方法如下所示:

在当前的使用环境中,部分请求方法已经不经常使用了,大部分使用的请求方法只有三个,get,post和put,同时任何使用 POST 的场景,换成 PUT 完全可以;
q:谈一下 GET 和 POST 的区别:
a:首先, GET 和 POST 没有本质区别,(即双方可以替换对方的)
其次,虽然没有本质区别,但是在使用习惯上,还是存在一些差异的:
1、GET 请求通常会把要传给服务器的数据,加到query string 中;POST 请求则是经常放在 body 中.(使用习惯上最大的差异)(上述情况并非绝对,GET 也可以使用 body, POST 也可以使用 query string.使用的前提是客户端/服务器都得按照一样的方式来处理代码
2、语义上的差异.(虽然语义上 HTTP 的使用是比较混乱的,但是相比之下, GET 和 POST 还是比较明确的),GET 大多数还是用来获取数据,POST 大多数还是用来提交数据 (登录 + 上传)
GET 和 POST 之间的差别,有些说法,需要大家来注意:
1、 GET 请求能传递的数据量有上限, POST 传递的数据量没有上限.
这是错误的,这个说法是一个"历史遗留"问题,早期版本的浏览器(硬件资源非常匮乏),针对 GET 请求的 URL 的长度做出了限制,实际上,RFC 标准文档中并没有明确规定 URL 能有多长。目前的浏览器和服务器的实现过程中,URL 可以非常长的,(甚至说可以使用 URL 传递一些图片这样的数据);
2、GET 请求传递数据不安全.POST 请求传递数据更安全.
依据是:如果使用 GET 请求来实现登录,点击登录的时候,就会把用户名和密码放到 url 中,进一步的显示到浏览器的地址栏,会被人看到; 相比之下,POST 则是在 body 中,不会在界面上显示出来,所以就更安全.这是错误的说法,我们通常所说的“安全”指的是我们传递的数据,不容易被黑客获取或者被黑客获取到之后,不容易被破解,所谓密码的安全性安全性,和 post 无关.关键在于是否加密,能否被人获取之后破译出来;
3、GET 只能给服务器传输文本数据,POST 可以给服务器传输文本和二进制数据
这是错误的;
1)、GET 也不是不能使用 body (body 中是可以直接放二进制的)
2) 、GET 也可以把二进制的数据进行 base64 转码,放到 url 的 query string 中4、GET 请求是幂等的.POST 请求不是幂等的.[不够准确, 但是也不是完全错]
所谓幂等 ,就是输入相同的内容,输出是稳定的,
GET 和 POST 具体是否是幂等,取决于代码的实现,GET 是否幂等,也不绝对.只不过 RFC 标准文档,建议 GET 请求实现成幂等的;
5、GET 请求可以被浏览器缓存,POST 不可以被缓存(幂等性的延续. 如果请求是幂等, 自然就可以缓存)
6、.GET 请求可以被浏览器收藏夹收藏,POST 不能 (收藏的时候可能会丟失 body)
2.3 认识 Header
Header 里的键值对是很多的.下面主要是挑几个重要的介绍一下;
Host:服务器所在的ip和端口号
即Host:www.bilibili.com,这个信息在url中也存在,但是在使用代理的情况下,Host的内容是可能和url中的内容是不一样的;
content-Length:body中数据的长度
Content-Type:body 中数据的格式
请求里有 body,才会有这两个属性.通常情况下 GET 请求没有 body; POST 请求有 body;
由于TCP 涉及到粘包问题,HTTP 在传输层就是基于 TCP 的。使用同一个 TCP 连接传输多个 HTTP 数据包,就会使多个 HTTP 数据包在 TCP 接收缓冲区中挨在一起,接收方解析的时候,就需要能够清楚 HTTP 数据包之间的边界;对于 GET 这种没有 body 的请求,直接使用空行(分隔符),对于post这种有 body 的请求,就结合空行和content-Length;
body 中的格式,可以选择的方式是非常多的,如下所示:
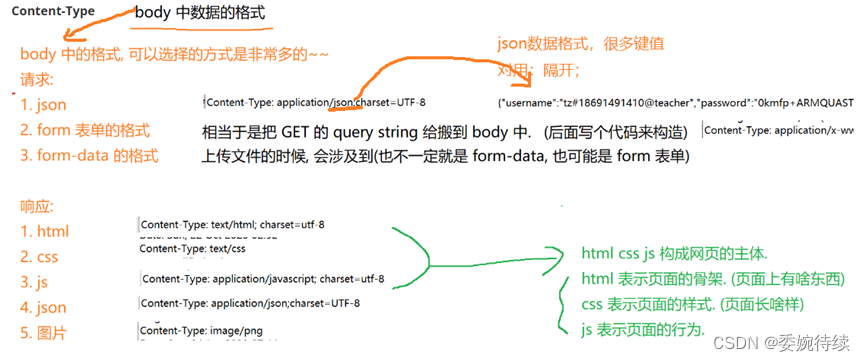
后续给服务器提交给请求,不同的 Content-Type,服务器处理数据的逻辑是不同的;服务器返回数据给浏览器,也需要设置合适的 Content-Type,浏览器也会根据不同的 Content-Type 做出不同的处理;
2.4 User-Agent(简称 UA)

上古时期,网页非常简单,就只是一些单纯的文字,浏览器功能也比较原始.后来,网页内容越来越丰富了,浏览器的功能也开始逐渐升级.
这个升级过程也是很快的.(新的浏览器出现的很快),新的浏览器诞生之后,并不是立即就占据全部市场.相当一部分时间里,新浏览器和旧浏览器是并存的;网站的开发者就遇到困难了,网站开发者就需要考虑到是否要兼容旧版本浏览器;事实上,就可以使用 User-Agent 来进行区分的.UA 中记录了浏览器的版本. 哪个版本的浏览器都支持哪些特性,哪些特性是容易获取的,网站开发者就可以看看 UA 里的内容;
现在,浏览器之间的差异非常小了.此时的UA 的作用就没那么关键了,所以UA主要是用来区分 PC端还是移动端。
ps:本次的学习内容就到这里了,如果大家感兴趣的话就请一键三连哦!!!


![[linux]进程间通信(IPC)———共享内存(shm)(什么是共享内存,共享内存的原理图,共享内存的接口,使用演示)](https://img-blog.csdnimg.cn/direct/bc619ee07ca34a1cac56b6dae55988f1.png)