目录
一、使用LinkedList实现堆栈
堆栈
LinkedList实现堆栈
二、集合框架
三、Set集合
1.特点
2.遍历方式
3.常见实现类
HashSet
LinkedHashSet
TreeSet
一、使用LinkedList实现堆栈
堆栈
堆栈(stack)是一种常见的数据结构,一端被称为栈顶,另一端被称为栈底,它遵循"先进后出"(Last In First Out,LIFO)的原则。在堆栈中,最后放入堆栈的元素将首先被移除。
堆栈具有两个主要的操作:
- 入栈(push):将元素添加到堆栈顶部。
- 出栈(pop):从堆栈顶部移除元素并返回它。
除了这两个主要操作外,堆栈还可能支持其他常用操作,例如:
- 获取栈顶元素(top):查看位于堆栈顶部的元素,而不移除它。
- 判断堆栈是否为空(isEmpty):检查堆栈是否不包含任何元素。
在Java中,可以使用数组或链表来实现堆栈。常见的实现方式包括使用Java的自带栈类(Stack类或Deque接口的实现类),或者使用LinkedList类来自行实现堆栈。
堆栈在编程中有许多实际应用,例如算术表达式求值、函数调用栈、撤销/重做操作等等。
LinkedList实现堆栈
要使用LinkedList来实现堆栈(stack),你可以按照以下步骤进行操作:
- 导入LinkedList类:在Java中,LinkedList类位于java.util包中,因此你需要在代码中导入该类
import java.util.LinkedList; - 创建堆栈类:创建一个名为Stack的类,该类将包含两个方法:push(入栈)和pop(出栈)
public class Stack {private LinkedList<Object> list;public Stack() {list = new LinkedList<Object>();}public void push(Object element) {list.addFirst(element);}public Object pop() {return list.removeFirst();} } - 使用堆栈:现在你可以在代码中实例化Stack类,并使用push(入栈)和pop(出栈)方法来操作堆栈
public class Main {public static void main(String[] args) {Stack stack = new Stack();stack.push("A");stack.push("B");stack.push("C");System.out.println(stack.pop()); // 输出 "C"System.out.println(stack.pop()); // 输出 "B"System.out.println(stack.pop()); // 输出 "A"} }
二、集合框架
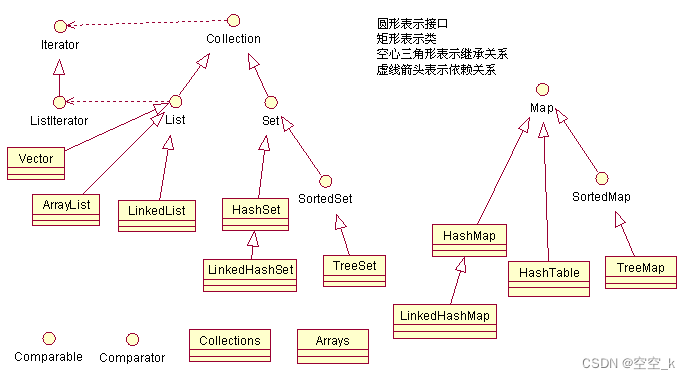
三、Set集合
Set继承于Collection接口,是一个不允许出现重复元素,并且无序的集合,主要有HashSet和TreeSet两大实现类。是一种数据结构,它是由一组唯一元素组成的集合,这意味着其中不会有重复的元素。在编程中,Set集合通常用来存储不重复的数据,可以对其中的元素进行添加、删除和查找操作。
1.特点
-
无序:Set集合数据添加的顺序和取出的顺序不一致
Set<Integer> set=new HashSet<Integer>(); set.add(2); set.add(1); set.add(5); set.add(8); System.out.println(set); -
唯一:List集合数据允许添加重复数据
Set<Integer> set=new HashSet<Integer>(); set.add(2); set.add(1); set.add(5); set.add(8); set.add(8); System.out.println(set); -
问题:存储对象,验证Set集合唯一性
Set<User> set=new HashSet<User>(); set.add(new User(1,"zs")); set.add(new User(2,"ls")); set.add(new User(1,"zs")); for (User user : set) {System.out.println(user); }查看结果:存储相同属性的User对象时,Set集合并未满足唯一性要求,打印输入了相同对象信息。 输出格式:类的全路径名+@+十六进制内存地址
User user = new User(); user.equals(null); //跳转到equals方法查看源码问题原因:判断重复元素的时候,Set集合会调用hashCode()和equal()方法来实现;而在没有重写equals方法之前默认比较的是Object(引用类型),实际上比较的是内存地址。
重写User对象中的equals方法,比较User对象中的属性。
@Override
public int hashCode() {final int prime = 31;int result = 1;result = prime * result + ((id == null) ? 0 : id.hashCode());result = prime * result + ((name == null) ? 0 : name.hashCode());return result;
}
@Override
public boolean equals(Object obj) {if (this == obj)return true;if (obj == null)return false;if (getClass() != obj.getClass())return false;User other = (User) obj;if (id == null) {if (other.id != null)return false;} else if (!id.equals(other.id))return false;if (name == null) {if (other.name != null)return false;} else if (!name.equals(other.name))return false;return true;
}当比较对象的属性相同时,已存在的对象信息不会被覆盖,而是过滤了。 结论:先比较hashcode值是否相同,再比较equals;
2.遍历方式
-
foreach
Set<String> set=new HashSet<String>(); set.add("zs"); set.add("ls"); set.add("ww"); for (String value : set) {System.out.println(value); } -
迭代器
Set<String> set=new HashSet<String>(); set.add("zs"); set.add("ls"); set.add("ww"); Iterator<String> it = set.iterator(); while(it.hasNext())System.out.println(it.next());
3.常见实现类
HashSet
-
它不允许出现重复元素;
-
不保证集合中元素的顺序
-
允许包含值为null的元素,但最多只能有一个null元素。
-
HashSet的实现是不同步的。
LinkedHashSet
-
哈希表和链表实现Set接口,具有可预测的迭代次序;
-
由链表保证元素有序,也就是说元素的存储和取出顺序是一致的。
-
由哈希值保证元素唯一,也就是说没有重复的元素
TreeSet
TreeSet 是一个有序的集合,它的作用是提供有序的Set集合。TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。
-
java.lang.Comparable自然比较接口
public class User implements Comparable<User> {private int id;private String name;...@Overridepublic int compareTo(Student b) {return this.id-b.id;} } -
java.util.Comparator比较器
public class NameComparator implements Comparator<User> {@Overridepublic int compare(User a, User b) {return a.getName()-b.getName();} }