在一台计算机中,我们可以同时打开多个软件,例如同时浏览网页、听音乐、打字等,这是再正常不过的事情。但仔细想想,为什么计算机可以同时运行这么多软件呢? 这就涉及计算机中的两个名词:多进程和多线程。
同样,在编写爬虫程序的时候,为了提高爬取效率,我们可能会同时运行多个爬虫任务,其中同样涉及多进程和多线程。
目录
一、多线程的概念
二、并发和并行
三、多线程的应用场景
四、Python多线程用途
五、threading模块
六、多线程共享全局变量的问题
(1)锁机制和threading.Lock类
(2)Condition锁
(3)Queue队列
一、多线程的概念
说起多线程,就不得不先说什么是线程。说起线程,又不得不先说什么是进程。
进程可以理解为一个可以独立运行的程序单位,例如打开一个浏览器,就开启了一个浏览器进程;打开一个文本编辑器,就开启了一个文本编辑器进程。在一个进程中,可以同时处理很多事情,例如在浏览器进程中,可以在多个选项卡中打开多个页面,有的页面播放音乐,有的页面播放视频,有的网页播放动画,这些任务可以同时运行,互不干扰。为什么能做到同时运行这么多任务呢? 这便引出了线程的概念,其实一个任务就对应一个线程。
进程就是线程的集合,进程是由一个或多个线程构成的,线程是操作系统进行运算调度的最小单位,是进程中的最小运行单元。以上面说的浏览器进程为例,其中的播放音乐就是一个线程,播放视频也是一个线程。当然,浏览器进程中还有很多其他线程在同时运行,这些线程并发或并行执行使得整个浏览器可以同时运行多个任务。
了解了线程的概念,多线程就很容易理解了。多线程就是一个进程中同时执行多个线程,上面的浏览器进程就是典型的多线程。
二、并发和并行
我们知道,在计算机中运行一个程序,底层是通过处理器运行一条条指令来实现的。
处理器同一时刻只能执行一条指令,并发(concurrency)是指多个线程对应的多条指令被快速轮换地执行。例如一个处理器,它先执行线程A的指令一段时间,再执行线程B的指令一段时间,然后再切回线程A 执行一段时间。处理器执行指令的速度和切换线程的速度都非常快,人完全感知不到计算机在这个过程中还切换了多个线程的上下文,这使得多个线程从宏观上看起来是同时在运行。从微观上看,处理器连续不断地在多个线程之间切换和执行,每个线程的执行都一定会占用这个处理器的一个时间片段,因此同一时刻其实只有一个线程被执行。
并行(parallel)指同一时刻有多条指令在多个处理器上同时执行,这意味着并行必须依赖多个处理器。不论是从宏观还是微观上看,多个线程都是在同一时刻一起执行的。
并行只能存在于多处理器系统中,因此如果计算机处理器只有一个核,就不可能实现并行。而并发在单处理器和多处理器系统中都可以存在,因为仅靠一个核,就可以实现并发。例如,系统处理器需要同时运行多个线程。如果系统处理器只有一个核,那它只能通过并发的方式来运行这些线程。而如果系统处理器有多个核,那么在一个核执行一个线程的同时,另一个核可以执行另一个线程,这样这两个线程就实现了并行执行。当然,其他线程也可能和另外的线程在同一个核上执行,它们之间就是并发执行。具体的执行方式,取决于操作系统如何调度。

三、多线程的应用场景
在一个程序的进程中,有一些操作是比较耗时或者需要等待的,例如等待数据库查询结果的返回、等待网页的响应。这时如果使用单线程,处理器必须等这些操作完成之后才能继续执行其他操作,但在这个等待的过程中,处理器明显可以去执行其他操作。如果使用多线程,处理器就可以在某个线程处于等待态的时候,去执行其他线程,从而提高整体的执行效率。
很多情况和上述场景一样,线程在执行过程中需要等待。网络爬虫就是一个非常典型的例子,爬虫在向服务器发起请求之后,有一段时间必须等待服务器返回响应,这种任务就属于IO密集型任务。对于这种任务,如果我们启用多线程,那么处理器就可以在某个线程等待的时候去处理其他线程,从而提高整体的爬取效率。

但并不是所有任务都属于IO密集型任务,还有一种任务叫作计算密集型任务,也可以称为CPU密集型任务。顾名思义,就是任务的运行一直需要处理器的参与。假设我们开启了多线程,处理器从一个计算密集型任务切换到另一个计算密集型任务,那么处理器将不会停下来,而是始终忙于计算,这样并不会节省整体的时间,因为需要处理的任务的计算总量是不变的。此时要是线程数目过多,反而还会在线程切换的过程中耗费更多时间,使得整体效率变低。

综上所述,如果任务不全是计算密集型任务,就可以使用多线程来提高程序整体的执行效率。尤其对于网络爬虫这种 IO密集型任务,使用多线程能够大大提高程序整体的爬取效率。
四、Python多线程用途
Python自带的解释器是Cpython,并不支持真正意义上的多线程。Cpython提供了多线程包,包含一个叫Global Interpreter Lock(GIL)锁,它能确保你的代码中永远只有一个线程在执行。经过GL的处理,会增加执行的开销。这就意味着如果你先要提高代码执行效率,使用threading不是一个明智的选择,当然如果你的代码是IO密集型,比如爬虫,多线程可以明显提高效率,相反如果你的代码是CPU密集型,比如大量计算类型,这种情况下多线程反而没有优势,建议使用多进程。
五、threading模块
threading模块是python中专门提供用来做多线程编程的模块。thrcading模块中最常用的类是Thread。
1.用thrcading模块直接写一个多线程程序
2.threading模块下的Thrcad类,继承自这个类,然后实现run方法,线程就会自动运行run方法中的代码
代码实例:
# 多线程案例1
import threading
import timedef singing(name,delay):print(f'{name}开始唱歌')time.sleep(delay)print('结束唱歌')def dacning(name,delay):print(f'{name}开始跳舞')time.sleep(delay)print('结束跳舞')def single_thread():singing('学友',2)dacning('潘潘',3)def multi_thread():task = []th1 = threading.Thread(target=singing,args=('学友',2))th1.start()for i in range(3):th2 = threading.Thread(target=dacning,args=('潘潘',3))th2.start()task.append(th2)task.append(th1)for t in task:t.join()if __name__ == '__main__':start_time = time.time()# single_thread()multi_thread()print(threading.enumerate())end_time = time.time()print(f'总共消耗时间:{end_time-start_time}')
结果如下:
学友开始唱歌
潘潘开始跳舞
潘潘开始跳舞
潘潘开始跳舞
结束唱歌
结束跳舞
结束跳舞
结束跳舞
[<_MainThread(MainThread, started 21676)>]
总共消耗时间:3.022017002105713这里使用了4个线程,一个线程用于打印唱歌并计时,三个线程用于打印跳舞并计时。最终消耗3秒多钟,因为使用最长时间的线程所花费的时间为3秒钟,其中还存在一些调用等之类的方法所耗费时间,一共加起来为3秒多种的时间。
六、多线程共享全局变量的问题
问题:多线程都是在同一个进程中运行的。因此在进程中的全局变量所有线程都是可共享的。这就造成了一个问题,因为线程执行的顺序是无序的,有可能会造成数据错误。
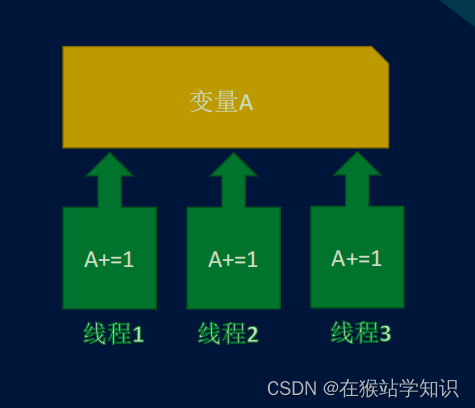
解决方法:
(1)锁机制和threading.Lock类
为了解决共享全局变量的问题。thrcading提供了一个Lock类,这个类可以在某个线程访问某个变量的时候加锁,其他线程此时就不能进来,直到当前线程处理完后,把锁释放了,其他线程才能进来处理。实例如下:
# 多线程共享全局变量
import threading
lock = threading.Lock()
a = 0
def add_value(num):global alock.acquire()for i in range(num):a += 1lock.release()print(f'A的值是:{a}')def main():for i in range(10):th = threading.Thread(target=add_value,args=(1000000,))th.start()if __name__ == '__main__':main()结果如下:
A的值是:1000000
A的值是:2000000
A的值是:3000000
A的值是:4000000
A的值是:5000000
A的值是:6000000
A的值是:7000000
A的值是:8000000
A的值是:9000000
A的值是:10000000如果不使用锁机制,则会出现A计算出的值不是按照1000000相加的得到的结果。
生产者和消费者模式
生产者和消费者模式是多线程开发中经常见到的一种模式。生产者的线程专门用来生产一些数据,然后存放到一个中间的变量中。消费者再从这个中间的变量中取出数据进行消费。通过生产者和消费者模式,程序分工更加明确,线程更加方便管理。
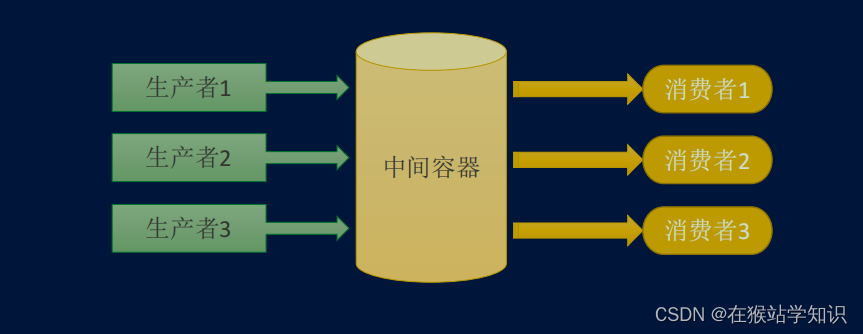
# 多线程L4-生产者和消费者-Lock版
import threading
import random
import timelock = threading.Lock()
cycle_time = 10
count = 0
total_money = 0
class Producer(threading.Thread):def run(self) -> None:global total_money,cycle_time,countwhile True:lock.acquire()if count > cycle_time:print('生产者已经完成工作了')lock.release()breakmoney = random.randint(100,5000)total_money += moneycount += 1print(f'{threading.current_thread().name}赚了{money}元')lock.release()time.sleep(0.5)class Consumer(threading.Thread):def run(self) -> None:global total_money,countwhile True:lock.acquire()money = random.randint(100,5000)if total_money >= money:total_money -= moneyprint(f'{threading.current_thread().name}消费了{money}元')else:if count > cycle_time:print(f'{threading.current_thread().name}想消费{money}元,但是余额不足,并且生产者不再生产了')lock.release()breakprint(f'{threading.current_thread().name}想消费{money}元,但是余额不足,只有{total_money}')lock.release()time.sleep(0.5)def main():for i in range(5):th1 = Producer(name=f'生产者{i}号')th1.start()for t in range(5):th2 = Consumer(name=f'消费者{t}号')th2.start()if __name__ == '__main__':main()结果如下:
生产者0号赚了2243元
生产者1号赚了1043元
生产者2号赚了1706元
生产者3号赚了3515元
生产者4号赚了1278元
消费者0号消费了4066元
消费者1号消费了4953元
消费者2号想消费3077元,但是余额不足,只有766
消费者3号想消费1452元,但是余额不足,只有766
消费者4号想消费4889元,但是余额不足,只有766
生产者2号赚了2290元
生产者1号赚了460元
生产者4号赚了2376元
生产者3号赚了3128元
生产者0号赚了4567元
消费者4号消费了1347元
消费者3号消费了4373元
消费者2号消费了3644元
消费者0号消费了2307元
消费者1号想消费3447元,但是余额不足,只有1916
生产者2号赚了1046元
生产者已经完成工作了
生产者已经完成工作了
生产者已经完成工作了
生产者已经完成工作了
消费者1号消费了2568元
消费者0号想消费2265元,但是余额不足,并且生产者不再生产了
消费者2号消费了235元
消费者3号想消费4350元,但是余额不足,并且生产者不再生产了
消费者4号想消费1287元,但是余额不足,并且生产者不再生产了
生产者已经完成工作了
消费者2号想消费3451元,但是余额不足,并且生产者不再生产了
消费者1号想消费3857元,但是余额不足,并且生产者不再生产了(2)Condition锁
threading.Condition可以在没有数据的时候处于阻塞等待状态。 一旦有合适的数据了,还可
以使用notify相关的函数来通知其他处于等待状态的线程。这样就可以不用做一些无用的上
锁和解锁的操作。可以提高程序的性能。
常用函数如下:
- acquire: 上锁。
- release: 解锁。
- wait: 将当前线程处于等待状态,并且会释放锁。可以被其他线程使用notify和notify_all函数
唤醒。被唤醒后会继续等待上锁,上锁后继续执行下面的代码。
- notify: 通知某个正在等待的线程,默认是第1个等待的线程。
- notify_all: 通知所有正在等待的线程。notify 和notfy_all 不会释放锁。并且需要在release之前
调用。
下面案例使用 threading.Condition来解决生产者和消费者问题:
# 多线程L5-生产者和消费者-Condition版import threading
import random
import timelock = threading.Condition()
cycle_time = 10
count = 0
total_money = 0class Producer(threading.Thread):def run(self) -> None:global total_money,cycle_time,countwhile True:lock.acquire()if count > cycle_time:print('生产者已经完成工作了')lock.release()breakmoney = random.randint(100,5000)total_money += moneylock.notify_all()count += 1print(f'{threading.current_thread().name}赚了{money}元')lock.release()time.sleep(0.5)class Consumer(threading.Thread):def run(self) -> None:global total_money,countwhile True:lock.acquire()money = random.randint(100,5000)while total_money < money:if count > cycle_time:print(f'{threading.current_thread().name}想消费{money}元,但是余额不足,并且生产者不再生产了')lock.release()returnlock.wait()total_money -= moneyprint(f'{threading.current_thread().name}消费了{money}元')lock.release()time.sleep(0.5)def main():for i in range(5):th1 = Producer(name=f'生产者{i}号')th1.start()for t in range(5):th2 = Consumer(name=f'消费者{t}号')th2.start()if __name__ == '__main__':main()结果如下:
生产者0号赚了1782元
生产者1号赚了4000元
生产者2号赚了174元
生产者3号赚了4387元
生产者4号赚了4438元
消费者0号消费了4504元
消费者1号消费了4909元
消费者2号消费了3572元
生产者3号赚了2507元
生产者0号赚了391元
消费者4号消费了3385元
生产者2号赚了3058元
生产者4号赚了3922元
消费者2号消费了3263元
消费者0号消费了4646元
生产者1号赚了4092元
消费者1号消费了549元
消费者3号消费了2709元
生产者3号赚了1972元
生产者已经完成工作了
消费者2号消费了1771元
生产者已经完成工作了
消费者4号想消费3128元,但是余额不足,并且生产者不再生产了
生产者已经完成工作了
消费者0号想消费3515元,但是余额不足,并且生产者不再生产了
消费者3号想消费2024元,但是余额不足,并且生产者不再生产了
消费者1号消费了863元
生产者已经完成工作了
生产者已经完成工作了
消费者2号想消费1832元,但是余额不足,并且生产者不再生产了
消费者1号想消费2619元,但是余额不足,并且生产者不再生产了(3)Queue队列
Queue是python标准库中的线程安全的队列(FIFO)实现,提供了一个适用于多线程编程的先进先出的数据结构。队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性。
初始化Queue(maxsize):创建一个先进先出的队列。
- qsize():返回队列的大小。
- empty():判断队列是否为空。
- full():判断队列是否满了。
- get():从队列中取最后一个数据。
- put():将一个数据放到队列中。
下面这篇帖子就是采取队列的方式来防止乱序问题的出现:
Python高级进阶--多线程爬取下载小说(基于笔趣阁的爬虫程序)_python多线程爬取小说-CSDN博客