这里写自定义目录标题
- 1 观察线程不安全
- 2 线程安全的概念
- 3 线程不安全的原因
- 线程调度是随机的
- 修改共享数据
- 原⼦性
- 可⻅性
- Java 内存模型 (JMM)
- 指令重排序
- 4 解决之前的线程不安全问题
1 观察线程不安全
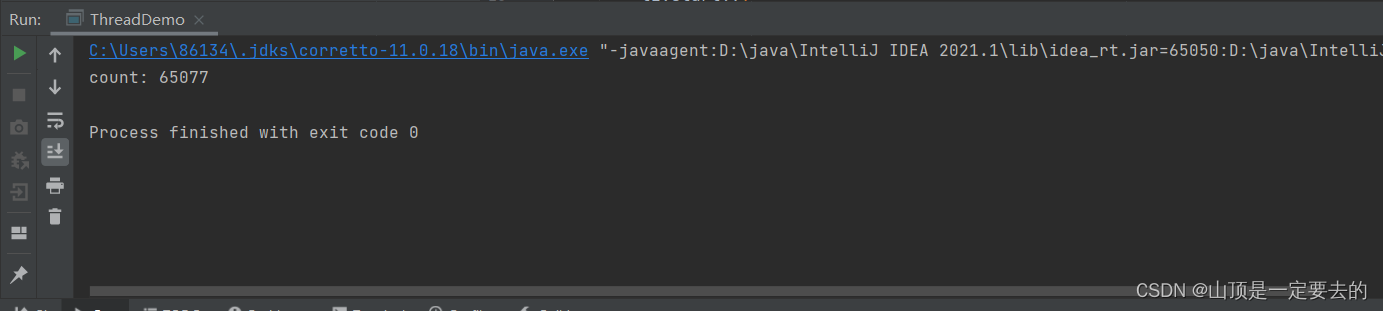
public class ThreadDemo {// 此处定义⼀个 int 类型的变量private static int count = 0;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {// 对 count 变量进⾏⾃增 5w 次for (int i = 0; i < 50000; i++) {count++;}});Thread t2 = new Thread(() -> {// 对 count 变量进⾏⾃增 5w 次for (int i = 0; i < 50000; i++) {count++;}});t1.start();t2.start();// 如果没有这俩 join, 肯定不⾏的. 线程还没⾃增完, 就开始打印了. 很可能打印出来的 cout1.join();t2.join();// 预期结果应该是 10wSystem.out.println("count: " + count);}
}⼤家观察下是否适⽤多线程的现象是否⼀致?同时尝试思考下为什么会有这样的现象发⽣呢?
2 线程安全的概念
想给出⼀个线程安全的确切定义是复杂的,但我们可以这样认为:
如果多线程环境下代码运⾏的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线程安全的。
3 线程不安全的原因
线程调度是随机的
这是线程安全问题的 罪魁祸⾸
随机调度使⼀个程序在多线程环境下, 执⾏顺序存在很多的变数.
程序猿必须保证 在任意执⾏顺序下 , 代码都能正常⼯作.
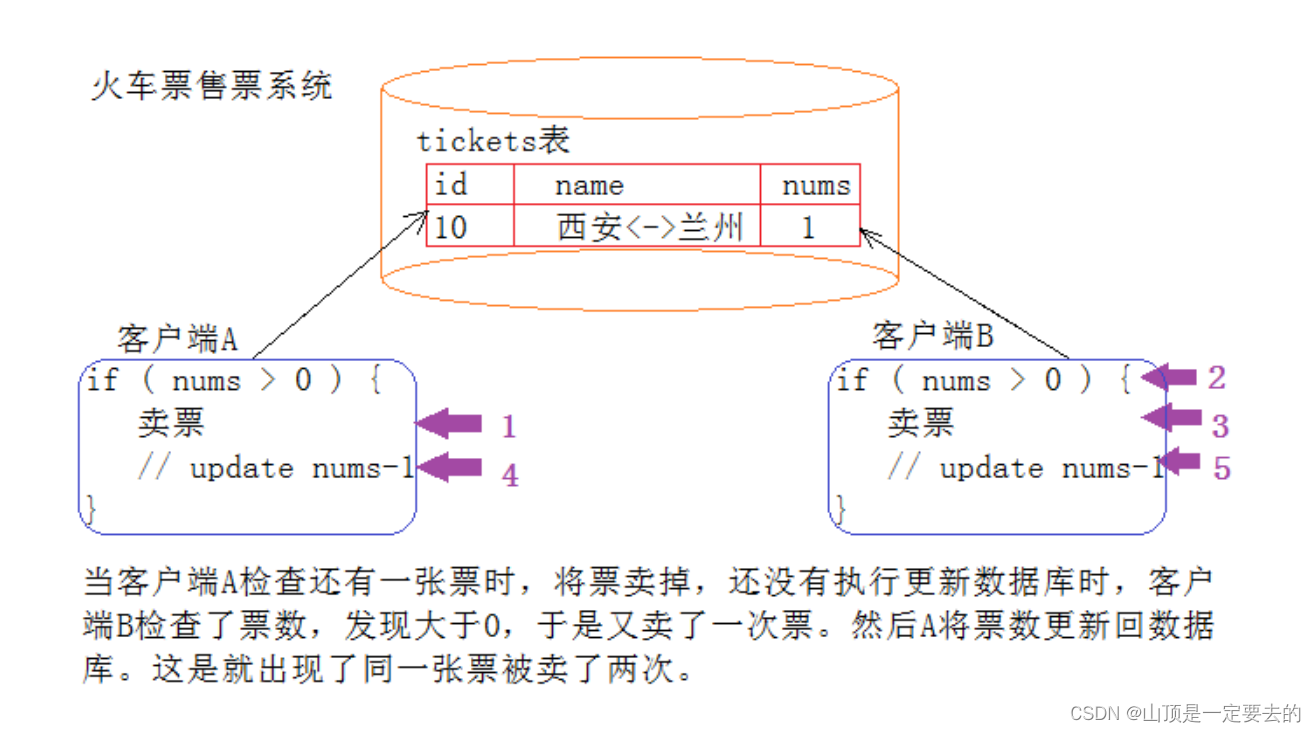
修改共享数据
多个线程修改同⼀个变量
上⾯的线程不安全的代码中, 涉及到多个线程针对 count 变量进⾏修改.
此时这个 count 是⼀个多个线程都能访问到的 “共享数据”
原⼦性
什么是原⼦性
我们把⼀段代码想象成⼀个房间,每个线程就是要进⼊这个房间的⼈。如果没有任何机制保证,A进⼊房间之后,还没有出来;B 是不是也可以进⼊房间,打断 A 在房间⾥的隐私。这个就是不具备原⼦性的。
那我们应该如何解决这个问题呢?是不是只要给房间加⼀把锁,A 进去就把⻔锁上,其他⼈是不是就进不来了。这样就保证了这段代码的原⼦性了。
有时也把这个现象叫做同步互斥,表⽰操作是互相排斥的。
⼀条 java 语句不⼀定是原⼦的,也不⼀定只是⼀条指令
⽐如刚才我们看到的 n++,其实是由三步CPU指令操作组成的:
- 从内存把数据读到 CPU
- 进⾏数据更新
- 把数据写回到 CPU
不保证原⼦性会给多线程带来什么问题
如果⼀个线程正在对⼀个变量操作,中途其他线程插⼊进来了,如果这个操作被打断了,结果就可能
是错误的。
这点也和线程的抢占式调度密切相关. 如果线程不是 “抢占” 的, 就算没有原⼦性, 也问题不⼤.
可⻅性
可⻅性指, ⼀个线程对共享变量值的修改,能够及时地被其他线程看到.
Java 内存模型 (JMM)
Java虚拟机规范中定义了Java内存模型.
⽬的是屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到⼀致的
并发效果.
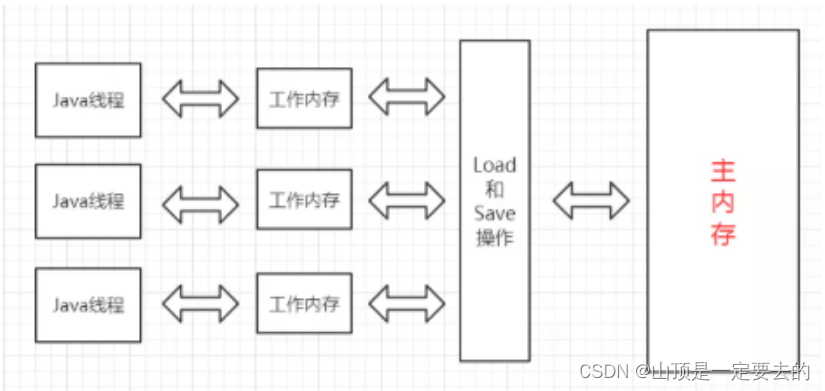
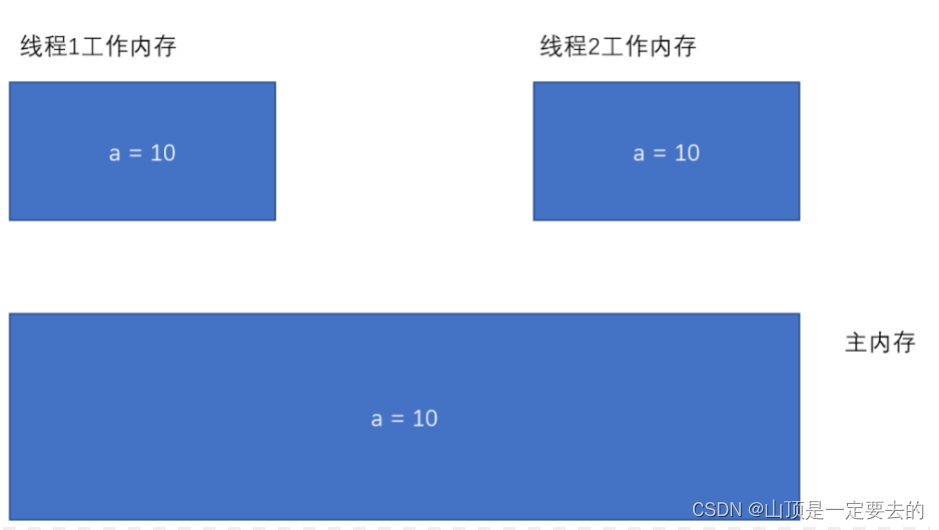
• 线程之间的共享变量存在 主内存 (Main Memory).
• 每⼀个线程都有⾃⼰的 “⼯作内存” (Working Memory) .
• 当线程要读取⼀个共享变量的时候, 会先把变量从主内存拷⻉到⼯作内存, 再从⼯作内存读取数据.
• 当线程要修改⼀个共享变量的时候, 也会先修改⼯作内存中的副本, 再同步回主内存
由于每个线程有⾃⼰的⼯作内存, 这些⼯作内存中的内容相当于同⼀个共享变量的 “副本”. 此时修改线
程1 的⼯作内存中的值, 线程2 的⼯作内存不⼀定会及时变化.
- 初始情况下, 两个线程的⼯作内存内容⼀致.
- ⼀旦线程1 修改了 a 的值, 此时主内存不⼀定能及时同步. 对应的线程2 的⼯作内存的 a 的值也不⼀定能及时同步.
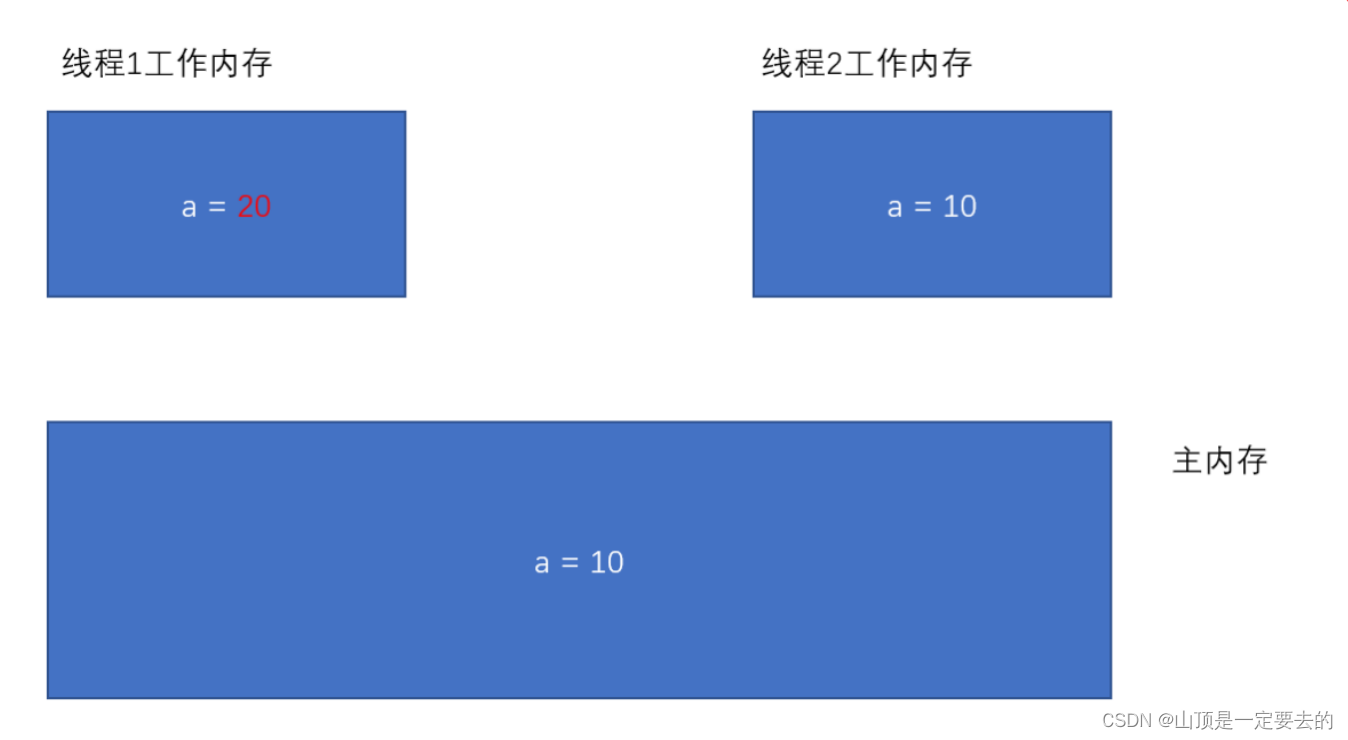
这个时候代码中就容易出现问题.
此时引⼊了两个问题:
• 为啥要整这么多内存?
• 为啥要这么⿇烦的拷来拷去?
-
为啥整这么多内存?
实际并没有这么多 “内存”. 这只是 Java 规范中的⼀个术语, 是属于 “抽象” 的叫法.
所谓的 “主内存” 才是真正硬件⻆度的 “内存”. ⽽所谓的 “⼯作内存”, 则是指 CPU 的寄存器和⾼速缓存. -
为啥要这么⿇烦的拷来拷去?
因为 CPU 访问⾃⾝寄存器的速度以及⾼速缓存的速度, 远远超过访问内存的速度(快了 3 - 4 个数量级,
也就是⼏千倍, 上万倍).
⽐如某个代码中要连续 10 次读取某个变量的值, 如果 10 次都从内存读, 速度是很慢的. 但是如果只是
第⼀次从内存读, 读到的结果缓存到 CPU 的某个寄存器中, 那么后 9 次读数据就不必直接访问内存了.
效率就⼤⼤提⾼了.
那么接下来问题⼜来了, 既然访问寄存器速度这么快, 还要内存⼲啥??
答案就是⼀个字: 贵

指令重排序
什么是代码重排序
⼀段代码是这样的:
- 去前台取下 U 盘
- 去教室写 10 分钟作业
- 去前台取下快递
如果是在单线程情况下,JVM、CPU指令集会对其进⾏优化,⽐如,按 1->3->2的⽅式执⾏,也是没问题,可以少跑⼀次前台。这种叫做指令重排序
编译器对于指令重排序的前提是 “保持逻辑不发⽣变化”. 这⼀点在单线程环境下⽐较容易判断, 但是
在多线程环境下就没那么容易了, 多线程的代码执⾏复杂程度更⾼, 编译器很难在编译阶段对代码的
执⾏效果进⾏预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价
重排序是⼀个⽐较复杂的话题, 涉及到 CPU 以及编译器的⼀些底层⼯作原理, 此处不做过多讨论
4 解决之前的线程不安全问题
这⾥⽤到的机制,我们⻢上会给⼤家解释。
// 此处定义⼀个 int 类型的变量private static int count = 0;public static void main(String[] args) throws InterruptedException {Object locker = new Object();Thread t1 = new Thread(() -> {// 对 count 变量进⾏⾃增 5w 次for (int i = 0; i < 50000; i++) {synchronized (locker) {count++;}}});Thread t2 = new Thread(() -> {// 对 count 变量进⾏⾃增 5w 次for (int i = 0; i < 50000; i++) {synchronized (locker) {count++;}}});t1.start();t2.start();// 如果没有这俩 join, 肯定不⾏的. 线程还没⾃增完, 就开始打印了. 很可能打印出来的 cout1.join();t2.join();// 预期结果应该是 10wSystem.out.println("count: " + count);}