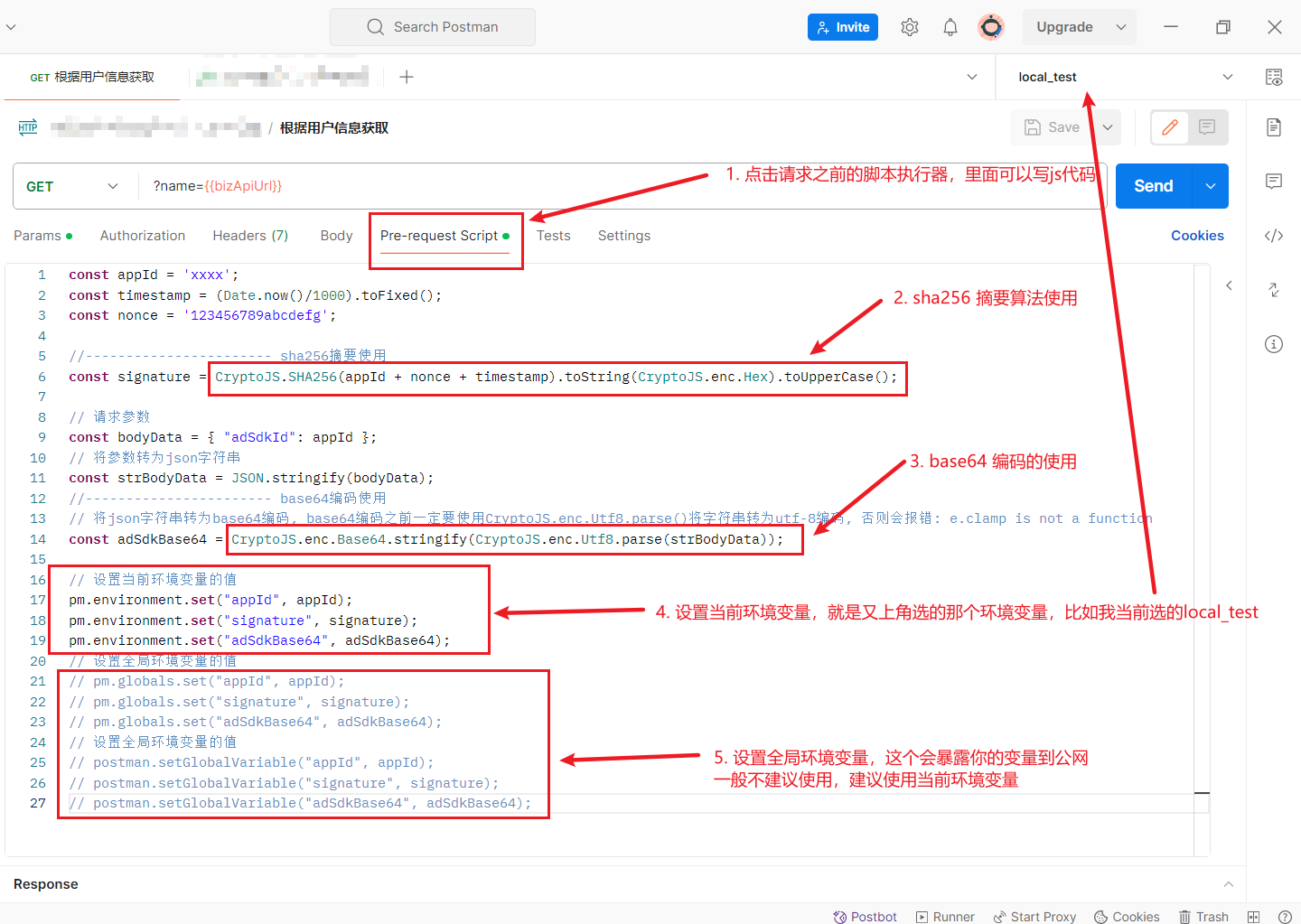
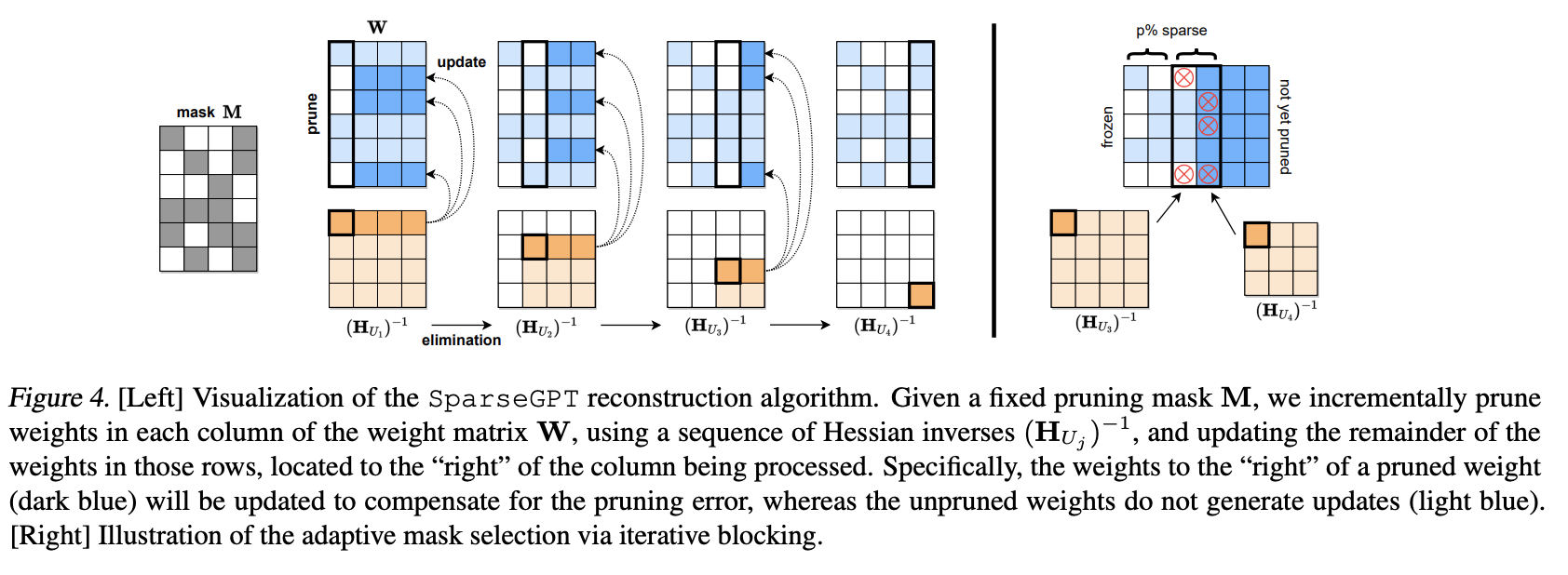
在本文中,你将学习如何在分布式环境中实现线性回归。
1. 题目背景
假设每个节点i都可以访问以下观测数据:
给定的公式 描述了每个节点观察到的线性关系,其中
是第
次观察的已知输入。
是第
次观察的已知输出。
和
分别是未知的斜率系数和截距系数。
是均值为0、方差为1的未知正态噪声。
2. 任务1
2.1 任务1问题
补全下图的代码,该代码将为每个节点生成观测数据。
var True_regressor float64 = 2
var True_intercept float64 = 5
var number_data int = 1000
x_values_node_1 := make([]float64, number_data)
y_values_node_1 := make([]float64, number_data)
x_values_node_2 := make([]float64, number_data)
y_values_node_2 := make([]float64, number_data)
x_values_node_3 := make([]float64, number_data)
y_values_node_3 := make([]float64, number_data)
s1 := rand.NewSource(time.Now().UnixNano())
r1 := rand.New(s1)
for i := 0; i < number_data; i++ {
var rnd = r1.NormFloat64()
x_values_node_1[i] = r1.Float64()
y_values_node_1[i] = //To complete
x_values_node_2[i] = //To complete
y_values_node_2[i] = //To complete
x_values_node_3[i] = //To complete
y_values_node_3[i] = //To complete
}2.2 任务1答案
var True_regressor float64 = 2var True_intercept float64 = 5var number_data int = 1000x_values_node_1 := make([]float64, number_data)y_values_node_1 := make([]float64, number_data)x_values_node_2 := make([]float64, number_data)y_values_node_2 := make([]float64, number_data)x_values_node_3 := make([]float64, number_data)y_values_node_3 := make([]float64, number_data)s1 := rand.NewSource(time.Now().UnixNano())r1 := rand.New(s1)for i := 0; i < number_data; i++ {x_values_node_1[i] = r1.Float64()y_values_node_1[i] = True_regressor*x_values_node_1[i] + True_intercept + r1.NormFloat64()x_values_node_2[i] = r1.Float64()y_values_node_2[i] = True_regressor*x_values_node_2[i] + True_intercept + r1.NormFloat64()x_values_node_3[i] = r1.Float64()y_values_node_3[i] = True_regressor*x_values_node_3[i] + True_intercept + r1.NormFloat64()} 代码循环生成每个节点的观测数据。对于每个节点,它将根据线性模型 生成x和y的值,其中a和b是已知的线性回归参数,而
是正态分布的随机噪声。
3. 任务2
3.1 任务2问题
解释如下两行代码的目的。
s1 := rand.NewSource(time.Now().UnixNano())r1 := rand.New(s1)3.2 任务2答案
s1 := rand.NewSource(time.Now().UnixNano())这行代码创建了一个随机数生成器的种子。time.Now().UnixNano()返回当前时间的纳秒表示,确保每次运行代码时种子都是不同的,从而生成不同的随机数序列。这对于模拟现实世界数据或确保实验的可重复性非常重要。
r1 := rand.New(s1)这行代码使用上一步创建的种子生成一个新的随机数生成器。这个生成器将用于生成模拟数据中的随机变量,比如正态噪声和观测输入。
4. 任务3
4.1 任务3问题
这道题目的中文翻译如下:
假设一个节点i仅使用其数据来估计a和b。那么它将解决以下优化问题:
这个优化问题的解决方案是什么?
4.2 任务3答案
要解决这个优化问题,即找到最小化均方误差函数的参数 \( a \) 和 \( b \),我们可以采用两种主要方法:闭式解和数值方法(如梯度下降)。让我们具体分析这两种方法:
4.2.1 闭式解
闭式解是通过解析方法直接求解出模型参数的方法。对于线性回归,这通常涉及到求解一组正规方程。这个方程组是通过对损失函数(在这个情况下是均方误差)关于每个参数的导数设为零而得到的。
对于函数,我们首先需要计算关于
和
的偏导数,并将它们设为零。
对的偏导数:
对 的偏导数:
接着,我们将这两个偏导数设为零并解这个方程组来找到 \( a \) 和 \( b \) 的值。
4.2.2 数值方法:梯度下降
当闭式解法不可行或不方便时(例如在非线性回归或大数据集的情况下),可以使用梯度下降等数值优化方法。
梯度下降的基本思想是从一个初始的和
的估计开始,然后迭代地调整这些参数,使得
减小。
初始化: 选择初始的 和
(通常为0或小的随机数)。
选择学习率 : 这个参数决定了在梯度下降过程中每一步的大小。
迭代更新: 在每一步,按照以下方式更新和
:
重复:重复上述步骤直到收敛到最小值或达到预定的迭代次数。
这两种方法都可以用来解决线性回归问题中的最优化问题,选择哪种方法取决于具体情况,如数据的大小和复杂性。在实际应用中,梯度下降方法由于其灵活性和适用性更广,尤其是在处理大规模数据集时。
5. 任务4
5.1 任务4问题
写出梯度下降算法的伪代码。
5.2 任务4答案
梯度下降算法是一种用于找到函数最小值的迭代方法。以下是应用于线性回归问题的梯度下降算法的伪代码:
初始化参数:初始化 a, b (比如 a = 0, b = 0)选择学习率 α (例如 0.01)设置最大迭代次数或收敛阈值重复以下步骤直到收敛或达到最大迭代次数:计算损失函数关于 a 的梯度:∇a = (-2/K) * Σ (y_i - (a*x_i + b)) * x_i计算损失函数关于 b 的梯度:∇b = (-2/K) * Σ (y_i - (a*x_i + b))更新参数:a = a - α * ∇ab = b - α * ∇b检查收敛条件(例如,参数变化很小或损失函数减少到特定阈值以下)
其中:
和
是线性模型的参数。
是学习率,控制每一步的更新大小。
是数据点的总数。
和
分别是第 i 个数据点的输入和输出。
∇a 和 ∇b是损失函数相对于和
的梯度。
Σ 表示对所有数据点的求和。
梯度下降算法的关键在于合理选择学习率和设置有效的收敛条件。学习率太大可能导致超调,太小则可能导致收敛过慢。收敛条件可以基于参数的变化量或者损失函数的降低量来确定。