目录
- 无监督对比学习:Moco
- 文章内容理解
- 代码解释
- 有监督对比学习:Supervised Contrastive Learning
- 文章内容理解
无监督对比学习:Moco
文章内容理解
以下内容全部来自于:自监督学习-MoCo-论文笔记. 侵删
论文:Momentum Contrast for Unsupervised Visual Representation Learning
CVPR 2020 最佳论文提名
用动量对比学习的方法做无监督的表征学习任务。
动量的理解即是指数移动平均(EMA),公式理解:
moco中利用动量来缓慢的更新编码器,这样处理的好处是编码器学习的特征尽可能的保持一致(一致性)。
对比学习
自监督学习中有一类方法主要就是基于对比学习的方法进行的,并取得了很好的效果,包括SimCLR和MoCo。由于是自监督学习,目的是想要学习到数据样本的好的表征,但是没有样本的标签信息或者其他信息,因此需要设计一些代理任务。一个比较常用的代理任务是instance discrimination(个体判别),它是一个对比学习的任务,这样就能够定义正样本和负样本,然后就可以使用一些对比损失函数。
关于正样本和负样本的定义,方法有很多,不同场景下,可以灵活进行处理。
摘要
动量对比学习用于无监督表征学习。moco从另外一个角度来理解对比学习,即从一个字典查询的角度来理解对比学习。moco中建立一个动态的字典,这个字典由两个部分组成:一个队列和一个移动平均的编码器。队列中的样本不需要做梯度反传,因此可以在队列中存储很多负样本,从而使这个字典可以变得很大。使用移动平均编码器的目的是使队列中的样本特征尽可能保持一致(即不同的样本通过尽量相似的编码器获得特征的编码表示)。实验研究发现,一个更大的字典对于无监督的对比学习会有很大的帮助。
moco预训练好的模型在加上一个linear protocol(一个分类头)就能够在imageNet取得很好的结果。moco学习到的特征能够很好的迁移到下游任务!(这是moco这篇文章的精髓,因为无监督学习的目的就是通过大规模无监督预训练,获得一个较好的预训练模型,然后能够部署在下游的其他任务上,这些下游任务通常可能没有那么多有标签数据可以用于模型训练)。这样,有监督和无监督之间的鸿沟在很大程度上被填平了。
Introduction
GPT和BERT在NLP中证明了无监督预训练的成功。视觉领域中还是有监督占据主导地位。语言模型和视觉模型这种表现上的差异,原因可能来自于视觉和语言模型的原始信号空间的不同。语言模型任务中,原始信号空间是离散的。这些输入信号都是一些单词或者词根词缀,能够相对容易建立tokenized的字典。(tokenize:把某一个单词变成一个特征)。有了这个字典,无监督学习能够较容易的基于它展开,(可以把字典里所有的key(条目)看成一个类别,从而无监督语言模型也能是类似有监督范式,即有一个类似于标签一样的东西来帮助模型进行学习,所以在NLP中,就相对容易进行建模,且模型相对容易进行优化)。但是视觉的原始信号是在一个连续且高维的空间中的,它不像单词那样有很强的语义信息(单词能够浓缩的很好、很简洁)。所以图像(由于原始信号连续且高维)就不适合建立一个字典,而使无监督学习不容易建模,进一步导致视觉中无监督模型打不过有监督模型。
有一些基于对别学习的无监督学习取得了不错的效果,虽然这些方法的出发点、具体做法不太一样,但可以归纳为(即对比学习可以归纳为)构造一个动态字典。
【对比学习中的一些概念:锚点-anchor-一个样本-一个图像,正样本-positive-由锚点通过transformation得到,负样本-negative-其他样本,然后把这些样本送到编码器中得到特征表示,对比学习的目标就是在特征空间中,使锚点和正样本尽可能相近,而和负样本之间尽可能远离】
【进一步,把对比学习中,正样本和负样本都放在一起,理解成一个字典,每个样本就是一个key,然后一开始选中作为锚点anchor的那个样本看作query,对比学习就转换成一个字典查询的问题,也就是说对比学习要训练一些编码器,然后进行字典的查找,查找的目的是让一个已经编码好的query尽可能和它匹配的那个特征(正样本编码得到的特征)相似,并和其他的key(负样本编码得到的特征)远离,这样整个自监督学习就变成了一个对比学习的框架,然后使用对比学习的损失函数】
【moco中把对比学习归纳为一个字典查找的问题,因此论文后面基本上用query来代替anchor,用字典来代替正负样本】
从动态字典的角度来看对比学习,要想获得比较好的学习效果,字典需要两个特性:一个是字典要尽可能大,另一个是字典中的样本表示(key)在训练过程中要尽可能保持一致。【原因分析:字典越大,就能更好的在高维视觉空间进行采样,字典中的key越多,字典表示的视觉信息越丰富,然后用query和这些key进行对比学习的时候,才更有可能学习到能够把物体区分开的更本质的特征。而如果字典很小,模型有可能会学习到一个捷径(short cut solution)。导致预训练好的模型不能很好的做泛化。关于一致性,是希望字典中的key是通过相同或者相似的编码器得到的样本特征,这样在与query进行对比时,才能尽量保证对比的有效性。反之,如果这些key是经过不同的编码器得到的,query在进行查询时,有可能会找到一个相同或者相似编码器产生的那个key。这就相当于变相的引入了一个捷径(short cut solution),使得模型学不好】以有的对比学习方法都被上述两个方面中至少一个方面所限制。
文章提出的moco方法是为了给无监督对比学习构造一个又大又一致的字典。MoCo的整体框架如下图所示:

moco中最大的一个贡献就是上图中的队列queue,
【这是在对比学习中第一次使用队列这种数据结构。队列queue主要是用来存储前面提到的字典,当字典很大时,显卡的内存就不不够用。因此希望模型每次前向过程时,字典的大小和batch size 的大小剥离开。具体的,这个队列可以很大,但是在每次更新这个队列时,是一点一点进行的,即模型训练的每个前向过程时,当前batch抽取的特征进入队列,最早的一个batch的特征出队列。因为队列的一个重要特性就是先入先出。引入队列的操作后,就可以把mini-batch的大小和字典(队列)的大小分开了,所以最后这个字典(队列)的大小可以设置的很大(论文最大设置为65536),队列中的所有元素并不是每个iteration都要更新的,这样只使用一个普通的GPU就可以训练一个很好的模型,(因为simclr这种模型会需要TPU进行训练,非常吃设备)】
moco的另一个重要的地方就是对编码器的动量更新。【分析:字典中的key最好要保持一致性,即字典中的key最好是通过同一个或者相似的编码器得到的。这个队列queue在更新时,当前batch的特征是当前编码器得到的,但是前面batch的特征并不是当前这个编码器得到的特征,他们是不同时刻的编码器得到的特征,这样就与前面说的一致性有了冲突,为了解决这个问题,因此moco中提出使用momentum encoder动量编码器,公式表示:
在模型的训练过程中,如过选用一个很大的动量m,那么这个动量编码器的更新其实是非常缓慢的,编码器 在训练过程中的更新其实是很快的,编码器后文中的实验也证明了使用较大的动量0.999会取得更好的效果。通过这个动量编码器,尽可能的保证了队列中不同batch之间抽取特征的一致性】
基于前面的两点贡献,作者总结moco通过构建一个又大又一致的队列,基于对比学习,能够去无监督的学习较好的视觉表征。
接下来是关于自监督学习中代理任务的选择。moco提供的是一种机制,它为无监督对比学习提供一个动态字典,所以还需要考虑选择什么样的代理任务。moco是非常灵活的,他可以和很多代理任务相结合。moco论文使用的一个简单的代理任务instance discrimination,但是效果很好。用预训练好的模型再结合一个线性分类器就可以在imageNet上取得和有监督相媲美的结果。【instance discrimination 个体判别任务,例子:有一个query和一个key,是同一个物体的不同视角不同的随机裁剪,这是一个正样本对,其他的都是负样本】
无监督学习最主要的目的是在大量无标注数据上,预训练一个模型,这个模型获得特征能够直接迁移到下游任务上。moco在7个下游任务上(检测、分割等)都取得了很好的结果,打平甚至超过有监督方式。【moco是无监督中第一个都做到了这么好的结果】
moco在imageNet上做了实验,该数据集有100W样本量。进一步,为了探索无监督的性能上限,moco在Instagram【facebook公司自己的,十亿级规模数据集,更偏向于真实世界,这个数据集没有像imageNet那样进行精心挑选过,每个图片只有一个物品在中间】数据集上进行了相关实验,Instagram数据集有10亿样本量,并且Instagram上训练的模型有更好的性能。Instagram数据集更偏向于真实世界,存在很多真实场景中的问题,如数据分类不均衡导致的长尾问题、一张图片含有多个物体,Instagram数据集图片的挑选和标注都没有那么严格。
因此,movo通过实验,填平了有监督和无监督之间的一个坑,取得了媲美甚至更好的结果,并且无监督预训练的模型可能会取代有监督预训练的模型。【学术界和工业界有很多基于imageNet预训练的模型进行扩展的工作,所以moco才会有很大的影响力。】
Related Work
无监督学习中,主要有两个方面做文章,一个是代理任务,一个是目标函数。代理任务的最终目的是能够获得更好的特征表示,目标函数是可以剥离代理任务进行一些设计,moco主要就是从目标函数上进行的设计与改进。moco中的框架设计最终影响的就是InfoNCE这个目标函数。
目标函数,根据代理任务,设计生成式模型(重建整张图),使用L1或者L2损失函数等都可以,如果设计一个判别式模型(eight positions,预测位置)可以通过交叉熵等损失函数的形式。
对比损失函数:在特征空间中衡量每个样本对之间的相似性,目标是让相似的物体之间的特征拉的比较近,不相似物体之间的特征尽量推开。对比损失函数与生成式或者判别式损失函数不同,后者的目标是固定的,前者(对比学习)的目标是在模型训练过程中不断改变的。即对比学习中目标是编码器抽取得到的特征(字典)决定的。
对抗性损失函数,主要衡量的是两个概率分布之间的差异,主要用来做无监督的数据生成,也有做特征学习的,迁移学习中很多方法就是通过对抗性损失函数来进行特征的学习。因为如果能够生成很理想的图像,也就意味着模型学习到了数据的底层的分布,这样的模型学习到的特征可能也会很好。
代理任务:重建整张图,重建图片的某个patch,colorization图片上色,生成伪标签,九宫格,聚类等各种各样的方法。
对比学习VS代理任务:某个代理任务可以和某个对比损失函数配对使用。CPC,预测性对比学习,利用上下文信息预测未来,CMC,利用一个物体的不同视角进行对比,和图片上色比较像。【CPC, CMC是对比学习方法早期的一些经典工作。】
【目标函数和代理任务是无监督学习中和有监督学习任务中主要不同的地方,有监督任务有标签信息,无监督学习没有标签,只能通过代理任务来生成自监督信号,来充当标签信息】
Method
之前的对比学习的工作基本上都可以总结为一个query在字典中进行查询的任务。假设有一个编码好的query,以及一些列样本key,假设字典中只有一个key(记做key+)和这个query是配对的,即这个目标key和query互为正样本对。【理论山,这里可以使用多个正样本对,之后也有一些工作证明了使用多个正样本对有可能提升任务的性能】。
有了正样本和负样本,就可以使用对比学习的目标函数,我们希望这个目标函数具有下面的性质:query和唯一正样本key+相似的时候,希望这个目标函数的值比较低,当query和其他key不相似的时候,loss的值也应该很小,【因为对比学习的目标就是拉近query和正样本key+的距离,同时拉远query和其他样本的距离,如果能达到这个目标,就说明模型训练的差不多了,此时的目标函数的值就应该尽量小,不再继续更新模型。】同样的,当query和正样本key+不相似或者query和负样本key相似时,我们希望目标函数的loss值尽量大一些,来惩罚模型,让模型继续更新参数。
moco中使用的对比损失函数是InfoNCE:
···········(1)
其中,k表示字典中的样本数
【对比损失函数
,中括号里面是softmax函数,把one-hot向量当作ground-truth时的损失函数中的计算,加上前面的-log,就是cross entropy 损失函数,这里的K表示数据集的类别数,在一个任务上是固定的数字。对比学习中理论上是可以使用cross entropy来当作目标函数的,但是在很多代理任务的具体实现上是行不通的,比如使用instance discrimination个体判别代理任务,类别数k就变成了字典中的样本数,是一个很大的数字,softmax在有巨量类别时,是工作不了的,同时exponential指数操作,在向量维度是几百万时,计算复杂度会很高,在模型训练时,每个iteration里面这样去计算,会很耗费时间。基于以上情况,有了NCE loss,noise contrastive estimation,前面说因为类别数太多,不能进行softmax计算,NCE的思路就是把这么多类别问题简化成一个二分类问题,数据类别data sample和噪声类别 noise sample,然后每次拿数据样本和噪声样本做对比。另外,如果字典的大小是整个数据集,计算复杂度还是没有降下来,为了解决这个问题,思路就是从整个数据集中选一些负样本进行loss计算,来估计整个数据集上的loss,即estimation。所以另一个问题就是,负样本如果选少了,近似的结果偏差就大了,所以字典的大小也就成了影响模型性能的一个因素,即字典越大,提供更好的近似,模型效果会越好,moco在强调希望字典能够足够大。总结就是NCE把一个超级多分类问题转成一个二分类问题,使softmax操作能够继续进行。
InfoNCE是对NCE的一个简单的变体,思路是,如果只看作二分类问题,只有数据样本和噪声样本,对模型学习不是那么友好,因为噪声样本很可能不是一个类,所以把噪声样本看作多个类别会比较合理,最终NCE就变成了上面的公式(1)InfoNCE。】
【
这个公式中,q 和 k 是模型的logits输出, 是一个温度参数, 用来控制分布的形状,
取值越大,分布越平滑smooth,取值越小,分布越尖锐peak,因此对比学习中对温度参数的设置会比较讲究,温度参数过大,对比损失对所有负样本一视同仁,导致模型的学习没有轻重,温度参数国小,导致模型只关注特别困难的负样本,而这些负样本也有可能是潜在的正样本(比如和query是同一类别的样本等),模型过多关注困难的负样本,会导致模型很难收敛,或者模型学习的特征泛化性能比较差】
公式分母中,求和是针对字典中的所有key,即一个正样本和所有负样本,InfoNCE其实就是cross entropy loss,它处理的是一个k+1的分类任务,目的是将q分成k+这个类别。moco代码实现中,目标函数实现用的就是cross entropy loss,下文伪代码中可以看到。
正负样本有了,目标函数有了,下面看输入和模型。普遍来讲,模型的输入query就是编码器得到的,key也是通过一个编码器得到的,具体的x和编码器则有具体的代理任务决定,输入x可以是图片,图片的一个patch或几个patch等,query的编码器和字典的编码器,可以同一个编码器,也可以是不同的编码器,两个编码器的架构可以一样也可以不一样,架构一样时,两个编码器参数可以共享,也可以不共享,还可以部分共享。
Momentum Contrast
通过前文的分析,对比学习是在连续高维的信号空间上,通过构建一个字典的方式来进行的。字典是一个动态字典,字典中的key都是随机采样得到的,且获得key的编码器在训练中也是在不断改变的。【有监督中的target一般是一个固定的目标,而无监督中不是,这是两者最大的区别。】作者认为,如果想学习到好的特征,字典就需要足够大,并且具有一致性。因为一个大的样本能够包含很多语义丰富的负样本,有助于学习到更有判别性的特征。一致性主要是为了模型的训练,避免模型学习到trivial solution捷径解。
队列-字典
论文的第一个贡献就是如何将一个字典看成一个队列,用队列把一个字典表示出来。【队列,这种数据结构最大的特点就是先进先出,FIFO】。整个队列就是一个字典,每个元素就是那些key。模型训练过程中,每一个batch就会有新的一批key送进来,同时最老的那批key会被移出去。用队列的好处,就是可以重复使用那些已经编码好的那些 key(之前mini-batch中得到的)。使用字典之后,就可以把字典的大小和mini-batch的大小完全剥离开。这样就可以在模型训练中使用一个比较标准的batch size,如128、256,同时字典的大小可以变得很大,并且可以作为一个超参数进行调节。字典一直都是所有数据的一个子集,(前面NCE进行近似loss时也提到了这个子集)。另外,维护队列(字典)的计算开销会很小,【字典的大小可以设置几百到几万,整体训练时间基本上差不多】。由于使用了队列,队列先进先出的特性,使得每一次移除队列的key都是最老的那批,使得字典中的key能够保持比较好的一致性,有利于对比学习。
动量更新
用队列的形式,可以让字典变得很大,但也导致队列中之前batch的key不能进行梯度回传,key的编码器不能通过反向传播来更新参数,【不能让query的编码器一直更新,而key的编码器一直不动】,为了解决这个问题,一种想法是每次把更新后的query的编码器拿给key作为编码器,但这种方式的结果并不好,作者认为这样效果不好的原因是,query的编码器q是快速更新的,直接作为编码器k,会导致队列中key的一致性降低。进一步为了解决这个问题,作者提出使用动量更新方式,来更新编码器k:
模型训练更开始时,编码器k用编码器q进行初始化,之后就通过动量更新的方式进行更新,当动量参数设置的很大时,编码器k的更新就会非常缓慢,这样即使队列中的key是通过不同的编码器k得到的,但这些编码器之间的差异很小,使得队列中key的一致性很好,实验中,动量0.999要比动量0.9的效果好得多,因此要充分利用好这个队列,就需要设置一个较大的动量参数。

Relations to previous work
之前的对比学习的方法基本都可以归纳为一个字典查找的问题,到都或多或少受限制于字典的大小或者一致性的问题。
之前对比学习的两种架构:end-to-end,端到端的学习方式,上图(a)所示,端到端的学习方式中,编码器q和编码器k都可以通过梯度回传的方式进行更新,两个编码器可以是不同的网络,也可以是相同的网络。moco中两个编码器是同样的网络架构Res50,因为query和key都是从同一个batch中获得的,通过一次前向传播就可以获得所有样本的特征,并且这些特征是高度一致的。局限性在于字典的大小受限,端到端的方式中,字典的大小和mini-batch的大小是一样,如果想让字典很大,batch size 就要很大,目前GPU加载不了这么大的batch size,另外,即使硬件条件达到,大batch size 的优化也是一个难点,处理不得当,模型会很难收敛。
【simclr(google)就是端到端的学习方式,并且使用了更多的数据增强方式,在编码器之后还有一个pojector,让学习的特征效果更好,此外还需要TPU,内存大,能够支持更大的batch size 8192,有16382个负样本。】端到端的学习方式,优点是,由于能够实时更新编码器k,字典中的key的一致性会很好,缺点是batch size很大,内存不够。
另外一个流派就是memory bank上图(b),更关注字典的大小,希望字典很大,以牺牲一定的一致性为代价。这种方法中只有一个编码器q,并能够通过梯度回传进行更新,字典的处理,则是把整个数据集的特征都存储,如ImageNet有128万个特征,每个特征128维,600M内存空间,近邻查询效率也很高,然后每次模型训练时,从memory bank中仅从随机采样key,来组成字典,memory bank相当于线下进行的,字典就可以设置的非常大,但是memory bank的特征一致性就不好,memory bank中的样本特征,每次训练时选中作为key的那些样本特征,会通过编码器q进行更新,而编码器q的更新会很快,每次更新的特征的差异性会很大,所以memory bank上特征的一致性会很差。另外,由于memory上存放了整个数据集的堂本,也就意味着,模型要训练一整个epoch,memory bank上的特征才能全部更新一次。
moco解决了上面提到的字典大小和特征一致性的问题,通过这个动态字典和动量编码器。
【moco和memory bank方法更相似,都只有一个编码器,都需要额外的内存空间存放字典,memory bank中还提出了proximal optimization损失,目的是让训练变得更加平滑,和moco中的动量更新异曲同工。memory bangk动量更新的是特征,moco动量更新的是编码器k,moco的扩展性很好,可以在亿集数据集上使用,memory bank方法在数据集很大时,还是会受限于内存大小。】
moco简单高效,扩展性好。
代理任务:为了简单起见,moco中使用简单的个体判别任务instance discrimination。
MoCo的伪代码风格非常简洁明了!伪代码如下:

moco中默认使用的batch size大小是256. 数据增强得到正样本对。memory bank中query长度(特征维数)128,为了保持一致,moco也用的128。
Shuffing BN
作者在之后的工作中,如SimSam中并没有在继续使用shuffing BN操作。使用BN之后,可能会导致当前batch中的样本信息的泄露。【因为BN要计算running mean和running variance,模型会通过泄露的信息很容易找到正样本,这样学到的可能就不是一个好的模型,模型会走一条捷径trivial solution。解决方法,在模型的训练之前,将样本的顺序打乱,在送到GPU上,提取完特征之后,再恢复顺序,计算loss。这样对最终的loss没有影响,但每个batch上BN的计算会被改变,从而避免信息泄露的问题。】
【BN在另一个自监督的重要工作BYOL中,引起了一些乌龙事件,相关的内容可以参考文章BYOL、BYOL work without BN和一个博客https://generallyintelligent.ai/blog/2020-08-24-understanding-self-supervised-contrastive-learning/,最终BYOL论文作者和博客作者达成的共识是,BYOL模型的训练依赖于一个比较合理的模型参数初始化,BN能够帮助提高模型训练过程中的稳定性。先挖个坑,之后有机会笔者会对BYOL系列的一些工作进行详细的解读】
【关于BN,BN使用的好,模型效果能够有很好的提升,但更多的情况下可能是用不好的,并且不易debug,如果换成transformer,使用LN替代BN】
Experiments
数据集:ImageNet-1M,100W数据量,Instagram-1B,10亿数据量。后者是为了验证moco模型扩展性好。由于使用个体判别的代理任务,ImageNet的类别量就是数据量。另外,Inatagram数据集更能反应真实世界的数据分布,这个数据集中的样本不是精心挑选的,有长尾、不均衡等问题,图片中物体有一个或多个。
训练:CNN模型,SGD优化器,batch size 256,8GPU,200epoch,ResNet50,53h。【相较于之后的SimCLR、BYOL等工作,moco对硬件的要求都是最低的,相对更容易实现的,affordable。并且moco、moco-v2系列工作,其泛化性能都很好,做下游任务时,预训练学习到的特征依旧非常强大。SimCLR的论文引用相对更高一些,moco的方法更平易近人一些】
Linear classification protocol
预训练模型加一个线性分类头,即一个全连接层。
作者做了一个grid search,发现分类头的最佳学习率是30,非常不可思议。一般深度学习中的工作,很少有learning rate会超过1。因此,作者认为,这么诡异的学习率的原因在于,无监督对比学习学到的特征分布,和有监督学习到的特征分布是非常不一样的。
Ablation:contrastive loss mechanisms
消融实验。三种对比学习流派之间的比较。实验结果如下图所示:

上图中,横坐标k表示负样本的数量,可以近似理解为字典的大小,纵坐标是ImageNet上的top one 准确率。end-to-end方法,受限于显卡内存,字典大小有限,32G的显卡内存,能用的最大的batch size是1024。memory bank方法整体上比end-to-end和moco效果都要差一些,主要就是因为特诊的不一致性导致的。另外,黑线的走势是不知道的,因为硬件无法支撑相关的实验,其后面结果可能会更高,也可能会变差。moco的字典大小,从16384增长到65536,效果提升已经不是很明显了,所以没有更大的字典的比较。上图结论:moco性能好、硬件要求低、扩展性好。
Ablation:momentum
消融实验,动量更新。实验结果下图所示:
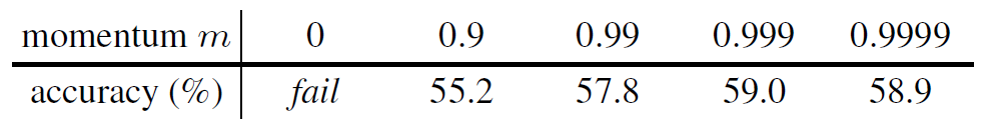
动量参数0.99-0.9999,效果会好一些。 大的动量参数,保证了字典中特征的一致性。动量参数为0,即每个iteration里面,直接把编码器q拿来作为编码器k,导致模型无法收敛,loss一致在震荡,最终模型训练失败。这个实验非常有力的证明了字典一致性的重要性。
Comparison with previous results.

上面实验结果表明:基于对比学习的方法效果更好,模型容量越大效果越好 ,moco在小模型和大模型上都能取得好的效果。
Transferring Features
无监督学习最主要的目标是要学习一个可以迁移的特征,验证moco模型得到的特征在下游任务上的表现,能不能有好的迁移学习效果。
另外,由于前面讲到,无监督学习到的特征分布和有监督学习到的特征分布是很不一样的,在将无监督预训练模型应用到下游任务时,不能每个任务的分类头都进行参数搜索,这样就失去了无监督学习的意义,解决方法是:归一化,然后整个模型进行参数微调。BN层用的是synchronized BN,即多卡训练时,把所有卡的信息都进行统计,计算总的running mean 和running variance,然后更新BN层,让特征归一化更彻底,模型训练更稳定。
Schedules.如果下游任务数据集很大,不在ImageNet上进行预训练,当训练时间足够长,模型效果依然可以很好,这样就体现不出moco的优越性了。但是下游数据集训练时间很短时,moco中预训练还是有效果的。所以moco中用的是较短的训练时间。
PASCAL VOC Object Detection,数据集PASCAL VOC,任务:目标检测,实验结果如下图:

coco数据集,实验结果如下图:

其他任务:人体关键点检测、姿态检测、实例分割、语义分割,实验结果如下图:

实验结果总结:moco在很多任务上都超过了ImageNet上有监督预训练的结果,在少数几个任务上稍微差一些,主要是实例分割和语义分割任务,【所以后面有人认为,对比学习不适合dence prediction的任务,这种任务每个像素点都需要进行预测,之后有一些相关的工作,如dence contrast,pixel contrast等】。
在所有这些任务中,在Instagram上预训练的模型要比ImageNet上的效果好一些,说明moco扩展性好,与NLP中结论相似,即自监督预训练数据量越多越好,符合无监督学习的终极目标。
Discussion and Conclusion
从imageNet到Instagram,虽然有效果上的提升,但是很小,而数据集是从100W增加到10亿,扩大了1000倍,所以大规模数据集可能还是没有被很好的利用起来,可能更好的代理任务能够解决这个问题。
自监督中,个体判别任务,还可以考虑向NLP中mask auto-encoders那样设计代理任务,完成完形填空,何凯明大神之后在2021年有了MAE这个文章。【MAE文章在2021年公布,但是思路应该至少在moco这篇文章中已经有了】
moco设计的初衷,是基于对比学习,设计一个大且一致的字典,能够让正负样本更好的进行对比。
总结
moco虽然是2020年的工作,但最近一两年自监督学习相关的工作刷新是很快的。
自监督学习第一阶段相关工作:InsDis,CPC,CMC等,百花齐放
第二阶段:moco,SimCLR双雄并立,都是基于对比学习的
第三阶段:BYOL,SimSam,不需要对比学习,不需要负样本
第四阶段:moco-v3,DINO等,基于transformer的工作,不再基于ResNet等CNN结构。
参考
MoCo 论文逐段精读【论文精读】_哔哩哔哩_bilibili
补充

代码解释
类定义:
class MoCo(nn.Module):"""Build a MoCo model with: a query encoder, a key encoder, and a queuehttps://arxiv.org/abs/1911.05722"""def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):"""dim: feature dimension (default: 128)K: queue size; number of negative keys (default: 65536)m: moco momentum of updating key encoder (default: 0.999)T: softmax temperature (default: 0.07)"""super(MoCo, self).__init__()self.K = Kself.m = mself.T = T# create the encoders# num_classes is the output fc dimensionself.encoder_q = base_encoder(num_classes=dim)self.encoder_k = base_encoder(num_classes=dim)if mlp: # hack: brute-force replacementdim_mlp = self.encoder_q.fc.weight.shape[1]self.encoder_q.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc)self.encoder_k.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc)for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):param_k.data.copy_(param_q.data) # initializeparam_k.requires_grad = False # not update by gradient# create the queueself.register_buffer("queue", torch.randn(dim, K))self.queue = nn.functional.normalize(self.queue, dim=0)self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
动量更新key编码器:
@torch.no_grad()def _momentum_update_key_encoder(self):"""Momentum update of the key encoder"""for param_q, param_k in zip(self.encoder_q.parameters(), self.encoder_k.parameters()):param_k.data = param_k.data * self.m + param_q.data * (1.0 - self.m)
forward计算对比损失 (InfoNCE loss,看成K+1类样本分类,第一个位置是正样本,其余的是负样本,使用的是个体判别任务):
def forward(self, im_q, im_k):"""Input:im_q: a batch of query imagesim_k: a batch of key imagesOutput:logits, targets"""# compute query featuresq = self.encoder_q(im_q) # queries: NxC; C这里为128q = nn.functional.normalize(q, dim=1)# compute key featureswith torch.no_grad(): # no gradient to keysself._momentum_update_key_encoder() # update the key encoder# shuffle for making use of BN# im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)k = self.encoder_k(im_k) # keys: NxCk = nn.functional.normalize(k, dim=1)# undo shuffle# k = self._batch_unshuffle_ddp(k, idx_unshuffle)# compute logits# Einstein sum is more intuitive# positive logits: Nx1l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)# negative logits: NxKl_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])# logits: Nx(1+K)logits = torch.cat([l_pos, l_neg], dim=1)# apply temperaturelogits /= self.T# labels: positive key indicatorslabels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()# dequeue and enqueueself._dequeue_and_enqueue(k)return logits, labels
T的选取,可以是0.07,0.1,0.5等
有监督对比学习:Supervised Contrastive Learning
文章内容理解
以下内容全部来自于:NIPS20 - 将对比学习用于监督学习任务《Supervised Contrastive Learning》
文章目录
-
- 原文地址
- 论文阅读方法
- 初识
- 相知
- 回顾
- 代码
原文地址
原文
论文阅读方法
三遍论文法
初识
对比学习这两年在自监督学习、无监督学习任务中非常火,取得了非常优秀的性能。这个工作就是想办法将其用在监督学习任务中,在训练过程中更有效地利用标签信息。
文章研究的点主要在于对比学习在分类任务中的应用
作者首先分析了分类任务中最常采用的交叉熵损失函数的缺点:① 对噪声数数据缺乏鲁棒性; ② 分类边界的问题(the possibility of poor margins)。这样会导致模型泛化能力下降,因此也有不少工作针对交叉熵进行改进(比如人脸领域的LargeMargin Loss, ArcFace,以及Label smoothing,知识蒸馏等),但目前大数据集上的分类任务(比如ImageNet),使用最多的仍然是交叉熵。
因此本文就探索了对比学习在ImageNet任务上的效果,提出了Supervised Contrastive Learning,并验证了其性能优越性。如下图所示,对比了在ImageNet上的实验性能。

auto-augment和rand-augment可以参考博客,简单理解的话,就是一种自动增广策略,针对数据集找到最有效的增广策略,提升模型泛化性。
相知
对比学习
对比学习的核心思想就是在特征空间将拉近achor和正样本,推远负样本。其目前主要用于无监督表征学习中,在这个任务中没有标注信息,所以正常样本通常是同一个实例的两个View(同一图像的两个增广结果),而负样本来自同一个batch中的其他样本。
可以视为在最大化数据不同视角下的互信息,这个思路最先由SimCLR提出,目前已经广泛采用。
而本文的出发点非常简单,既然有了标签信息,那我不就可以准确地找到anchor对应的正样本和负样本吗?因此Supervised Contrastive Learning的目标就是在特征空间中拉近同一类数据的特征,推远不同类之间的特征。

训练框架
采用两阶段训练的方法,第一阶段非常与SimCLR非常像。首先对batch内的图像都进行两次增广,得到两倍Batch大小(2N)的数据。
先送入Encoder网络得到2048维的特征输出,然后再进一步经过一个Project网络映射到另一个空间中(通常维度更小,本文中为128),经过归一化(normalization映射到超球面)后在这个特征空间中计算Supervised Contrastive Learning。
第一阶段训练好之后,移除掉Project网络,固定住Encoder网络,用交叉熵损失再训练一个分类head,用于后续测试。

一些细节:① 也可以不采用2阶段的方式,而是使用交叉熵联合训练分类head,效果也能差不多。但这里为了更好地体现所提出的监督学习效果(迁移任务上),选择分离训练。② 达到相同的形象,SupCon需要的学习率比交叉熵的要更大。③ 理论上温度系数越小越好,但是过小容易数值不稳定。④ 实验过程中尝试了不同的优化器(LARS,RMSProp,SGDm)。
监督对比学习形式
自监督对比学习的形式如下所示:

其中I包含了一个Batch中的所有数据(2N),·表示内积,其实在超球面上就可以表示余弦相似度, τ τ τ表示温度系数,A(i)表示I\{i},1个anchor对应1个正样本和2N-2个负样本。
根据自监督对比学习的定义,引入标签信息后,可以非常容易地对其进行更改。作者首先提出了两种监督对比学习形式:

其中,P(i)表示在当前batch内,anchor样本i所对应的所有正样本。在形式2中,会先计算所有正样本对之间的log项再求均值,而形式3会先计算求得均值再计算log项。
首先,无论是形式2还是形式3,他们都有以下几个性质:
- 可以很好地泛化到多个正样本对:也就是说对于正样本的个数没有限制;
- 负样本越多,对比性能越强:形式2和形式3在分母的负样本求和,这也保留了在原对比学习中的负样本越多越好的性质(实际上负样本越多,对比时就有更多hard negative,效果更好);
- 具有困难样本挖掘能力:不仅仅是正样本也包含了负样本,在损失中hard positive/negative的贡献远大于easy positive/negative(作者在附录中给了数学上的证明)。
但这两中形式实际上是不一样的,根据杰森不等式能得到如下关系:

Jensen’s Inequality: 过一个下凸函数上任意两点所作割线一定在这两点间的函数图象的上方
这或许推测in形式要优于out形式,但结论却恰好相反,作者经过实验表明,out的性能要更优。作者在也给出了数学上的证明,说明in形式更容易达到次优解,因此在之后的实验中均采用out形式。

部分实验
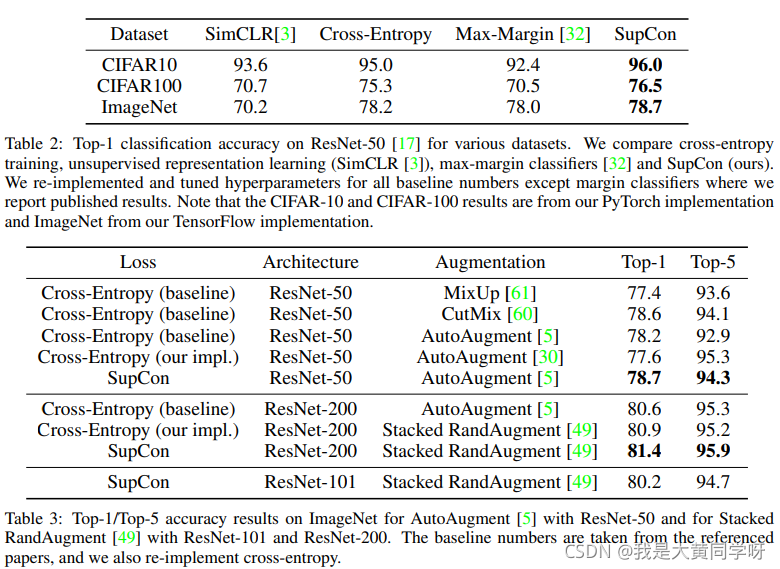
表2展示了本文提出的supervised contrastive learning要优于SimCLR,交叉熵以及Max-Margin,表3展示了其也优于其他的数据增广策略。
需要注意的是,训练过程中的batch size为6144,增广后就是12288了。
作者也尝试了MoCo这类方法,使用memory bank,memory size为8192,batch size为256,取得了79.1%的top-1准确率,效果更好(Kaiming yyds)。
但即使使用的是memory bank也需要8块V100… …
作者也在ImageNet-C数据集上进行了测试,其包含一些人造噪声,效果也很不错。这也说明了supervised contrastive learning要更鲁棒。

作者还测试了损失对超参数的稳定性以及一些消融实验,如下图所示,均优于交叉熵。

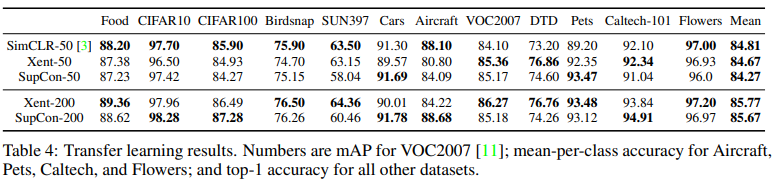
作者还验证了Supervissed Contrastive Learning的模型迁移能力。
回顾
对比学习核心在于“在特征空间拉近anchor与正样本对之间的距离,推远与负样本之间的距离”
往简单了说,对比学习就是一种损失函数类型。往深了说,就是对数据分布的一种先验假设。在无监督学习任务中,由于没有具体的标签信息,所以在对比学习任务中采用同一实例的不同增广结果作为正样本对,其他实例作为负样本。这样会受到false negative的影响,比如两张图片全是cat这一类,但你却要强行推远它们在特征空间中的距离,这样会损害特征的判别性(缺少了捕获同类特征的能力)。
因此本文引入了标签信息,在强监督学习设置下进行对比学习SupCon。提出了两种损失形式,并通过实验和数学上的证明,保留了效果最好最鲁棒的一种。
SupCon也保留了对比学习本身的一些特性,其中有一条就是随着负样本的增加,性能会越来越好。实验也证明了在大batch size下性能优于普通的交叉熵。但在batch size较小的情况下却没有给出实验结果(我觉得可能不如交叉熵)。如果只有在大batch size的情况下才能彰显SupCon的优越性显然就限制了它的应用场景,毕竟不是谁都像G家卡那么多,所以这也意味着还有很大的改进空间。
代码
官方tf代码链接:https://t.ly/supcon,torch代码链接:https://github.com/HobbitLong/SupContrast


![[HTML]Web前端开发技术28(HTML5、CSS3、JavaScript )JavaScript基础——喵喵画网页](https://img-blog.csdnimg.cn/direct/1b9dece61d314044a355d452d141db77.png)