1.下载安装包
https://celeborn.apache.org/download/
测0.4.0时出现https://github.com/apache/incubator-celeborn/issues/835

2.解压
tar -xzvf apache-celeborn-0.3.2-incubating-bin.tgz
3.修改配置文件
cp celeborn-env.sh.template celeborn-env.shcp log4j2.xml.template log4j2.xmlcp celeborn-defaults.conf.template cp celeborn-defaults.conf3.1修改celeborn-env.sh
CELEBORN_MASTER_MEMORY=2g
CELEBORN_WORKER_MEMORY=2g
CELEBORN_WORKER_OFFHEAP_MEMORY=4g3.2 修改celeborn-defaults.conf
# used by client and worker to connect to master
celeborn.master.endpoints 10.67.78.xx:9097# used by master to bootstrap
celeborn.master.host 10.67.78.xx
celeborn.master.port 9097celeborn.metrics.enabled true
celeborn.worker.flusher.buffer.size 256k# If Celeborn workers have local disks and HDFS. Following configs should be added.
# If Celeborn workers have local disks, use following config.
# Disk type is HDD by defaut.
#celeborn.worker.storage.dirs /mnt/disk1:disktype=SSD,/mnt/disk2:disktype=SSD# If Celeborn workers don't have local disks. You can use HDFS.
# Do not set `celeborn.worker.storage.dirs` and use following configs.
celeborn.storage.activeTypes HDFS
celeborn.worker.sortPartition.threads 64
celeborn.worker.commitFiles.timeout 240s
celeborn.worker.commitFiles.threads 128
celeborn.master.slot.assign.policy roundrobin
celeborn.rpc.askTimeout 240s
celeborn.worker.flusher.hdfs.buffer.size 4m
celeborn.storage.hdfs.dir hdfs://10.67.78.xx:8020/celeborn
celeborn.worker.replicate.fastFail.duration 240s# If your hosts have disk raid or use lvm, set celeborn.worker.monitor.disk.enabled to false
celeborn.worker.monitor.disk.enabled false4.复制到其他节点
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx1:/root/
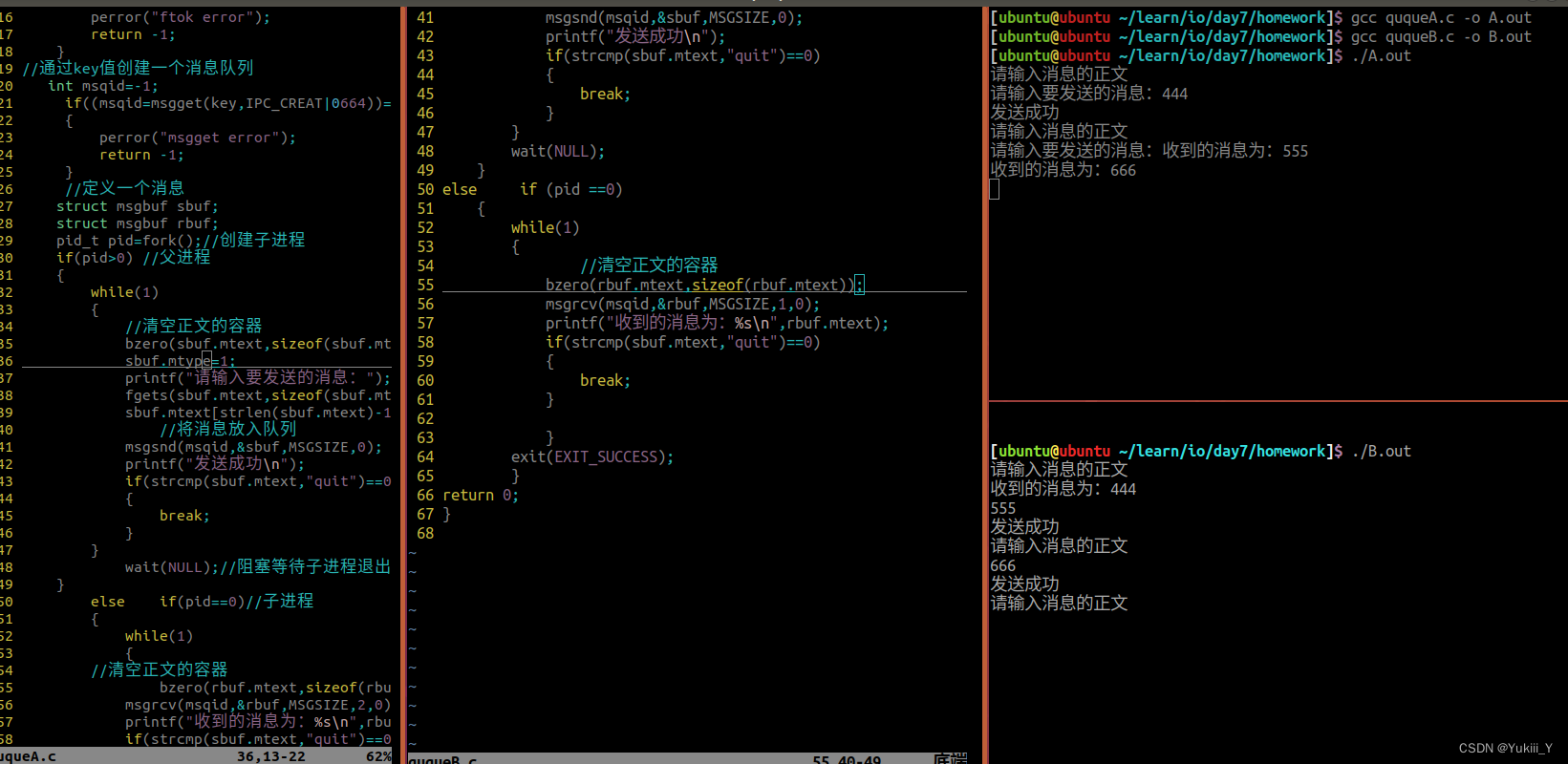
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx2:/root/因为在配置文件中已经配置了master 所以启动matster和worker即可。
5.启动master和worker
cd $CELEBORN_HOME
./sbin/start-master.sh./sbin/start-worker.sh celeborn://<Master IP>:<Master Port>之后在master的日志中看woker是否注册上
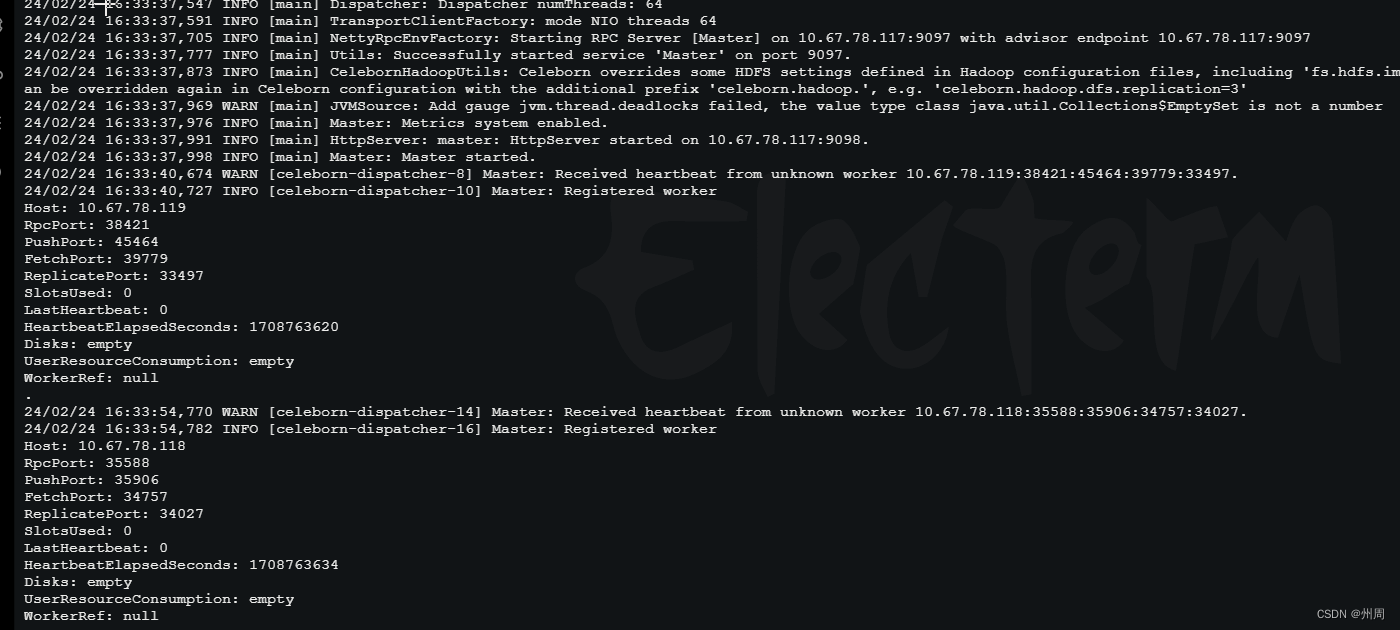
6.在 spark客户端使用
复制 $CELEBORN_HOME/spark/*.jar 到 $SPARK_HOME/jars/
修改spark-defaults.conf
# Shuffle manager class name changed in 0.3.0:
# before 0.3.0: org.apache.spark.shuffle.celeborn.RssShuffleManager
# since 0.3.0: org.apache.spark.shuffle.celeborn.SparkShuffleManager
spark.shuffle.manager org.apache.spark.shuffle.celeborn.SparkShuffleManager
# must use kryo serializer because java serializer do not support relocation
spark.serializer org.apache.spark.serializer.KryoSerializer# celeborn master
spark.celeborn.master.endpoints clb-1:9097,clb-2:9097,clb-3:9097
# This is not necessary if your Spark external shuffle service is Spark 3.1 or newer
spark.shuffle.service.enabled false# options: hash, sort
# Hash shuffle writer use (partition count) * (celeborn.push.buffer.max.size) * (spark.executor.cores) memory.
# Sort shuffle writer uses less memory than hash shuffle writer, if your shuffle partition count is large, try to use sort hash writer.
spark.celeborn.client.spark.shuffle.writer hash# We recommend setting spark.celeborn.client.push.replicate.enabled to true to enable server-side data replication
# If you have only one worker, this setting must be false
# If your Celeborn is using HDFS, it's recommended to set this setting to false
spark.celeborn.client.push.replicate.enabled true# Support for Spark AQE only tested under Spark 3
# we recommend setting localShuffleReader to false to get better performance of Celeborn
spark.sql.adaptive.localShuffleReader.enabled false# If Celeborn is using HDFS
spark.celeborn.storage.hdfs.dir hdfs://<namenode>/celeborn# we recommend enabling aqe support to gain better performance
spark.sql.adaptive.enabled true
spark.sql.adaptive.skewJoin.enabled true# Support Spark Dynamic Resource Allocation
# Required Spark version >= 3.5.0 注意spark版本是否满足
spark.shuffle.sort.io.plugin.class org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO
# Required Spark version >= 3.4.0, highly recommended to disable 注意spark版本是否满足
spark.dynamicAllocation.shuffleTracking.enabled false
7.启动spark-shell
./bin/spark-shell spark.sparkContext.parallelize(1 to 1000, 1000).flatMap(_ => (1 to 100).iterator.map(num => num)).repartition(10).count