redis介绍和安装
# 数据库:
关系型数据库:mysql、oracle、postgrasql、sqlserver、sqlite
IBM:服务器
Oracle:数据库 达梦
EMC:存储非关系型数据库: redis、mongodb、es、clickhouse、influxDB
NoSql 类型
# 如何选择:目前许多大型互联网都会选用MySql+NoSql的组合方案
关系型数据库适合存储结构化数据,比如:用户的账号、地址:
(1)这些数据通常需要做结构化查询,比如Join,这时,关系型数据库就要胜出一筹。
(2)这些数据的规模、增长的速度通常是可以预期的。
(3)事务性、一致性,适合存储比较复杂的数据。
NoSql适合存储非结构化数据,比如:文章、评论:
(1)这些数据通常用于模糊处理,如全文搜索、机器学习,适合存储较简单的数据。
(2)这些数据是海量的,并且增长的速度是难以预期的。
(3)按照key获取数据效率很高,但是对于join或其他结构化查询的支持就比较差。
# 总结:
SQL数据库依然强大,可以可靠的处理事务并且保持事务的完整性,只有你的数据非常大,操作扩展需要更加分布式的系统时,才考虑NoSql数据库
# redis是什么?
redis是一个key-value存储系统【软件】,用c语言写的,c/s架构的软件,纯内存存储,可以持久化【断电数据可以恢复】,支持很多客户端(python,go,java,c,php),速度很快
有5钟数据类型:string字符串、hash字典、list列表、set集合、zset有序集合
# redis为什么速度这么快:
qps :10w 6w左右
1、纯内存操作,避免了io
2、使用了io多路复用的网络模型--(epoll)
3、数据操作是单线程单进程---【没有锁操作,没有线程间切换】
# redis适合干什么?缓存(最多) 验证码放在redis中,有过期时间,只要过期,这个数据就没了 计数器 去重 排行榜:有序集合 地址位置信息 消息队列 ...# 安装redis
redis开源项目,社区不支持win
使用的epoll模式,不能再win上运行的
微软团队基于人家源码,修改+编译,做成安装包可以装在win上
最新:最新7.x
win平台最新只有:
最新5.x版本 https://github.com/tporadowski/redis/releases/
最新3.x版本 https://github.com/microsoftarchive/redis/releases
下载:Redis-x64-5.0.14.1.msi,一路下一步
redis配置和启动
# 配置成服务,启动停止服务即可,也可以通过命令启动停止
# 安装目录下,重要的可执行文件
redis-cli :客户端 等同于mysql 的 mysql
redis-server :服务端等同于mysql 的 mysqld
# 重要的配置文件相当于mysql 的 my.iniredis.windows-service.conf
databases 16
port 6379
bind 127.0.0.1# 启动redis:
redis-server 配置文件路径 redis-server redis.windows-service.conf# 关闭:
1、服务中点停止
2、cmd客户端链接上:执行 shutdown
# redis数据是存在内存中得
一般情况下,重启redis服务,关机,数据都会丢失
咱们不会丢 redis.windows-service.conf 已经写了持久化方案
(从内存把数据保存到硬盘上的过程称之为持久化)


redis之普通链接和连接池
# 安装:pip install redis
# 普通链接
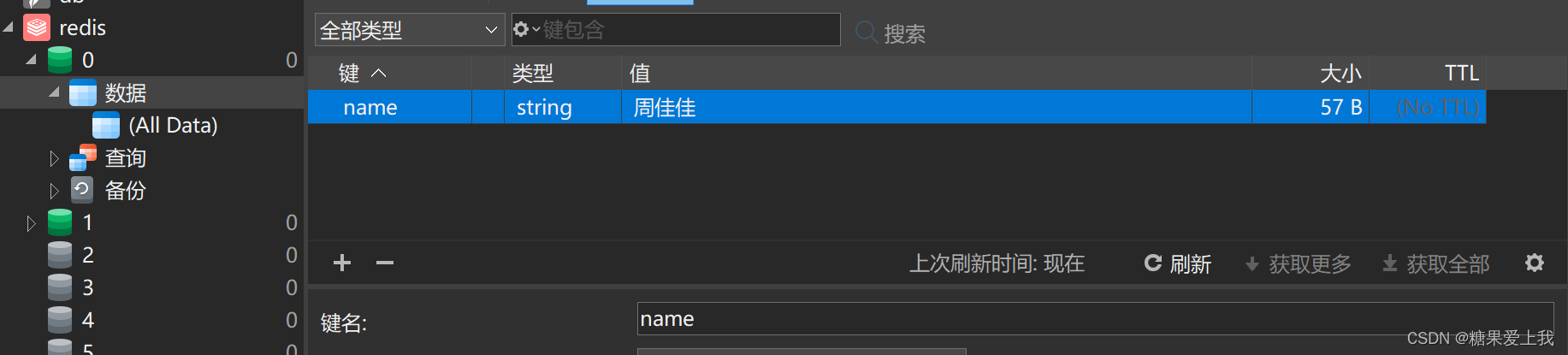
from redis import Redisconn = Redis(host='localhost', port=6379, db=0) res = conn.get('name') print(res) # b'\xe5\x91\xa8\xe4\xbd\xb3\xe4\xbd\xb3' print(res.decode(encoding='utf-8')) # 周佳佳 conn.close()
# 连接池:
# script/redis_demo/pool.py import redis # 创建池--->保证pool是单例的---》全局只有一个pool对象实例 Pool = redis.ConnectionPool(max_connections=3, host="localhost", port=6379, decode_responses=True)# 连接池链接.py import redis from threading import Thread from pool import Pool# 每次从池中取一个链接 # conn = redis.Redis(connection_pool=pool) # res = conn.get('name') # print(res) # conn.close() # 把链接放回到连接池# 起十个线程 def task():conn = redis.Redis(connection_pool=Pool)res = conn.get('name')print(res)conn.close()l = [] for i in range(3):t = Thread(target=task)t.start()l.append(t)for t in l:t.join()print('结束了')

redis字符串操作
# 对五种数据类型的操作:
字符串、字典、列表、集合、有序集合
# 主要应用场景:
1 计数器
2 做缓存,轮播图数据,json格式字符串,放到redis中# redis对字符串的操作:
from pool import POOL import redis conn = redis.Redis(connection_pool=POOL) ... # 对字符串的操作 conn.close()# 字符串操作:
1、set(name, value, ex=None, px=None, nx=False, xx=False) 设置值conn.set('hobby','篮球') # 带过期时间 conn.set('age','19',ex=3) conn.set('age','19',px=3000) # 如果key存在才设置或不存在才设置 # nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果 # xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值 conn.set('age',19,nx=True) conn.set('age',99,nx=True) conn.set('age',99,xx=True) conn.set('yy',99,xx=True)2、setnx(name, value) 存在就不改了
conn.setnx('age',999) # 等同于 conn.set('age',19,nx=True)3、psetex(name, time_ms, value) # 设置过期时间
conn.psetex('xxx',3000,'阿斯顿发')
conn.setex('xxx',3,'阿斯顿发')4、mset(*args, **kwargs) 批量设置
conn.mset({'name':'yyy','age':888,'height':180})5、get(name) # 获取
res=conn.get('name')
print(res)6、mget(keys, *args) # 批量获取
res=conn.mget(['name','age','height'])
print(res)
# ['name','age','height']-->['name','age','height']--->[name,age,height]
7、getset(name, value) # 拿完再修改完
res=conn.getset('name','彭于晏')
print(res)8、getrange(key, start, end) 数字指的是字节长度
# 字符: a b 你 中 国 # 字节: 存中文,utf-8,需要3个字节存一个字符 res=conn.getrange('name',0,2) # 前闭后闭区间 print(res) print(str(res,encoding='utf-8'))s='lqz厉害' print(len(s)) print(len(bytes(s,encoding='utf-8'))) print(len(bytes(s,encoding='gbk')))9、setrange(name, offset, value) # 设置字节,在第几个位置设置什么
conn.setrange('name',3,'eeee')# 比特位操作:
setbit(name, offset, value) print(conn.getbit('name',3)) getbit(name, offset) bitcount(key, start=None, end=None) bitop(operation, dest, *keys)10、字节长度 strlen(name)
print(conn.strlen('name'))
11、自增 incr(self, name, amount=1)
incrby
conn.incrby('age') # 文章阅读量 计数器 单线程 不会有并发安全问题12、自增小数 incrbyfloat(self, name, amount=1.0)
13、减 decr(self, name, amount=1)
conn.decrby('age',2)14、追加 append(key, value)
conn.append('age',8888)
conn.append('hobby','很好')
conn.close()
redis之hash操作
# hash形式:字典 key -value形式,都是无序的
# 应用场景: 缓存、计数器
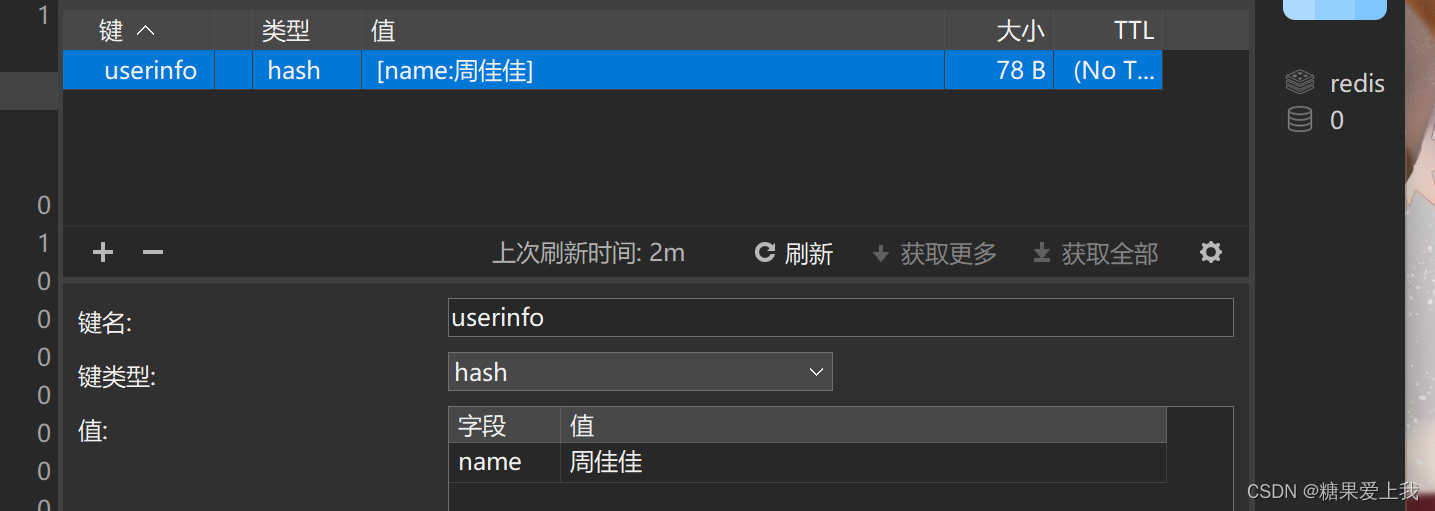
# 基本运用:from redis import Redis conn = Redis(host='127.0.0.1', port=6379, db=0) ... conn.close()1、hset(name, key, value) 设置值
conn.hset('userinfo','name','lqz')
conn.hset('userinfo','age',18)
2、hmset(name, mapping) 批量设置
conn.hmset('userinfo1',{'name':'彭于晏','age':19})
conn.hset('userinfo2', mapping={'name': '刘亦菲', 'age': 19, 'hobby': '抽烟'})3、hget(name,key) 拿值
print(conn.hget('userinfo2','hobby'))4、hmget(name, keys, *args) 批量获取值
print(conn.hmget('userinfo2','hobby','name','age'))
print(conn.hmget('userinfo2',['hobby','name','age']))5、hgetall(name) 获取所有, 慎用,可能数据多,一次性取内存会爆掉
res=conn.hgetall('userinfo2')
print(res)6、hlen(name) 统计长度
print(conn.hlen('userinfo2'))7、hkeys(name) 获取所有的key
print(conn.hkeys('userinfo2'))8、hvals(name) 获取所有value
print(conn.hvals('userinfo2'))9、hexists(name, key) 判断是否存在 T/F
print(conn.hexists('userinfo2','hobby1'))10、hdel(name,*keys) 删除
res=conn.hdel('userinfo2','hobby')
print(res)11、hincrby(name, key, amount=1) 加一,做计数器
conn.hincrby('userinfo2','age')12、hincrbyfloat(name, key, amount=1.0) 加小数
conn.hincrbyfloat('userinfo2', 'age', amount=1.2)
12、hscan(name, cursor=0, match=None, count=None) 一点点取值for i in range(1000):conn.hset('map_demo',i,'鸡蛋_%s'%i) # 一次性取出来 res=conn.hgetall("map_demo") print(res)# 一点点取---》取的数量不准确(上下相差一点点),下次取值取决于上次的结果---》不单独使用 res=conn.hscan('map_demo',cursor=0,count=20) # 从第0个位置开始取20条 print(res) # (数字,{数据}) print(len(res[1]))res=conn.hscan('map_demo',cursor=320,count=10) print(res) # (数字,{数据})conn.hscan('map_demo')13、 hscan_iter(name, match=None, count=None) 一点点取
res=conn.hscan_iter('map_demo',count=10)
# 内部通过调用 hscan实现 每次取10条,用完再继续取10条,直到所有数据都取完内部是生成器, 取出所有数据等同于 hgetall
redis之list操作
# 作用
1 跨进程间通信,消息队列
2 实现分布式
3 队列和栈# 基本运用:
from redis import Redis conn = Redis(host='127.0.0.1', port=6379, db=0) ... conn.close()1、 lpush(name, values) 从左向右插入值
conn.lpush('girls', '刘亦菲')
conn.lpush('girls', '迪丽热巴')
2、rpush(name, values) 表示从右向左操作
conn.rpush('girls','李清照')
3、lpushx(name, value) 存在才放进去,不存在不行
conn.lpushx('girls','lqz')
conn.lpushx('boys','lqz')
4、rpushx(name, value) 表示从右向左操作
conn.rpushx('girls','小红')5、llen(name) 列表长度
print(conn.llen('girls'))6、linsert(name, where, refvalue, value))
#在 刘亦菲 后面插入 上海刘亦菲
conn.linsert('girls',where='after',refvalue='刘亦菲',value='上海刘亦菲')
conn.linsert('girls', where='before', refvalue='刘亦菲', value='山东刘亦菲')
7、lset(name, index, value) 左往右第几个位置插入
conn.lset('girls',1,'lqz')
conn.lset('girls',3,'lqz')8、lrem(name, value, num) 删除
conn.lrem('girls',1 ,'lqz') # 从左往右删1个
conn.lrem('girls',-1 ,'lqz') # 从右往左删1个
conn.lrem('girls',0 ,'lqz') # 所有都删除9、lpop(name) 从左往右弹出一个
print(conn.lpop('girls'))10、rpop(name) 表示从右向左操作
print(str(conn.rpop('girls'),encoding='utf-8'))11、lindex(name, index) 按索引取值,从0开始
res=conn.lindex('girls',1)
print(str(res,encoding='utf-8'))
12、lrange(name, start, end) 取范围内的值
res=conn.lrange('girls',0,1) # 前闭后闭区间
print(res)
13、ltrim(name, start, end) 截取列表范围
conn.ltrim('girls',1,3) # 前闭后闭
14、rpoplpush(src, dst) #两个列表 ,从第一个列表的右侧弹出,放到第二个列表的左侧15、blpop(keys, timeout) # 阻塞式弹出,可以做消息队列,分布式
res=conn.blpop('boys',timeout=5) 五秒内
print(res)16、 r.brpop(keys, timeout),从右向左获取数据
17、brpoplpush(src, dst, timeout=0)
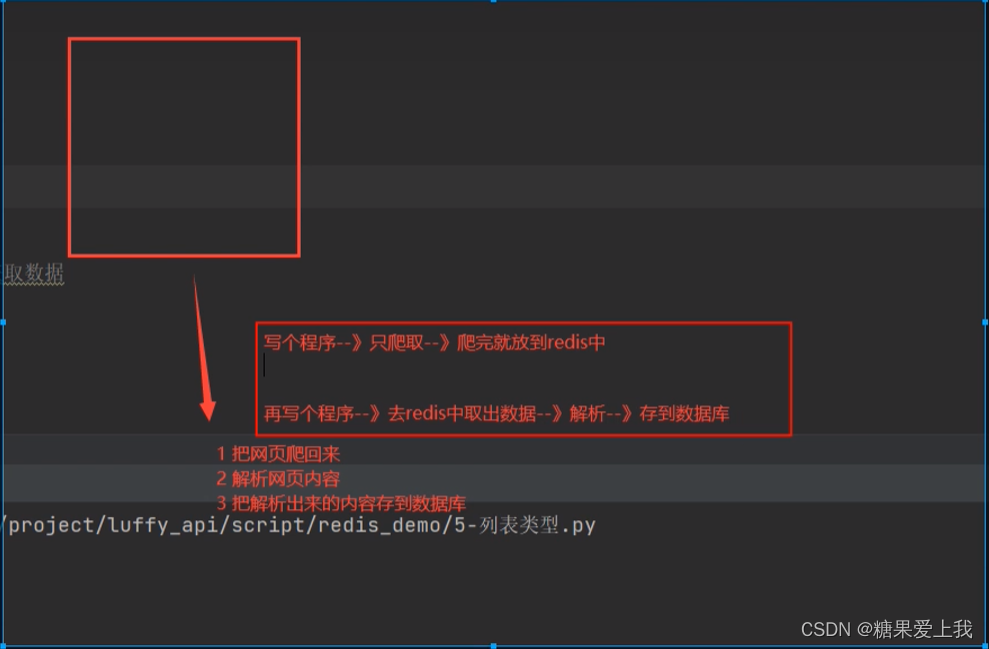
分布式:你计算一个,我计算一个







redis其他操作
# 通用操作:
delete(*names):删除
exists(name):存在几个
keys(pattern='*'):匹配key值
expire(name ,time):设置过期时间
rename(src, dst):重命名
move(name, db)):移动库
randomkey():随机弹出一个key
type(name):查看类型from redis import Redisconn = Redis(host='localhost', port=6379, db=0)# 可以删除多个 conn.delete('name','age')# redis里存在几个 res=conn.exists('userinfo1','name','height') print(res) # 2# 可以写个匹配,以u开头的所有key res=conn.keys('u*') print(res)# 设置key且有过期时间 conn.expire('girls',10)# 重命名 conn.rename('name','name1')# 移动库 conn.move('bobby1',2)# 随机弹出一个key值 print(conn.randomkey())# 查看类型 print(conn.type('height')) #string print(conn.type('map_demo')) #hashconn.close()
django中使用redis
方式一:通用方式
# 写个pool.py,然后在哪里用,导入用即可:
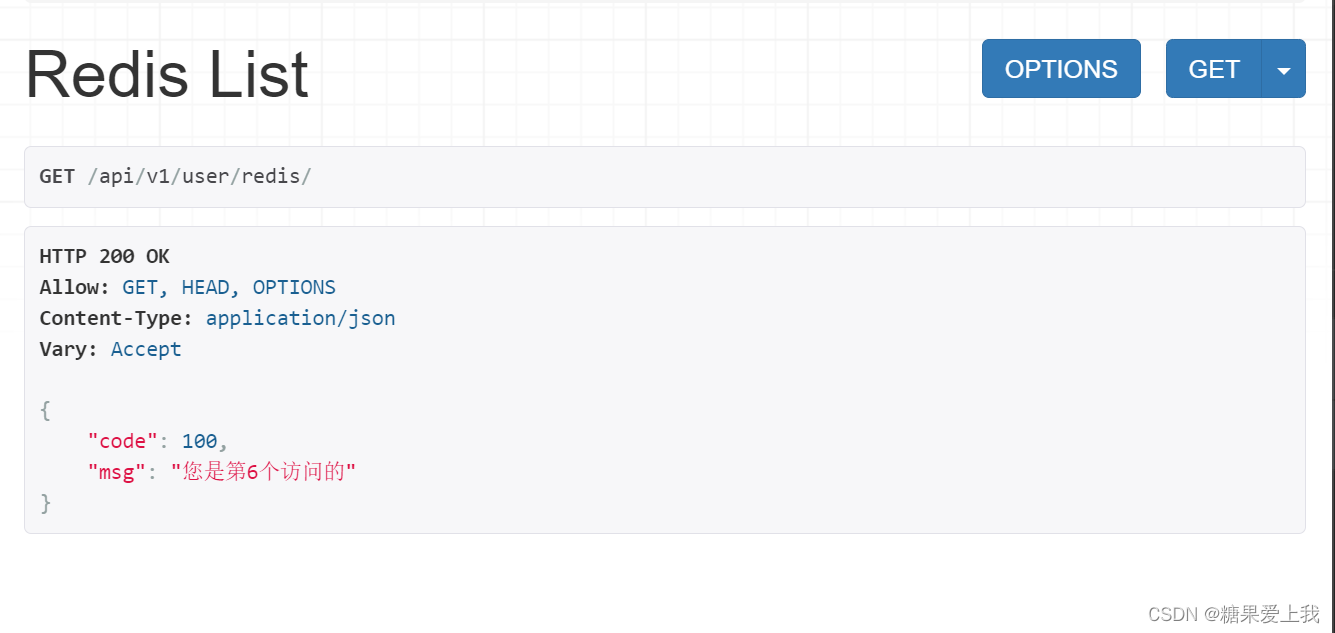
# utills/pools.py import redisPOOL = redis.ConnectionPool(host='localhost',port=6379,db=0,decode_responses=True,max_connections=10 )# apps/user/views.py # redis测试 from utills.pool import POOL import redisclass RedisView(ViewSet):def list(self, request):conn = redis.Redis(connection_pool=POOL)conn.incrby('count')count = conn.get('count')return APIResponse(msg='您是第%s个访问的' % count)方式二:配置文件配置
# settings/dev.py # 配置redis CACHES = {"default": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379","OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient","CONNECTION_POOL_KWARGS": {"max_connections": 100},# "PASSWORD": "123",}} }# apps/user/views.py # redis测试 from django_redis import get_redis_connectionclass RedisView(ViewSet):def list(self, request):conn = get_redis_connection() # 从池中获取一个链接conn.incrby('count')count = conn.get('count')return APIResponse(msg='您是第%s个访问的' % count)
django的redis缓存
# django内置的缓存:缓存的位置在内存,只要项目一重启,数据就没了
cache.set() 设置缓存
cache.get() 获取缓存
# redis:缓存放到 redis中 ,redis可以持久化,项目停止,但redis还运行,数据就不会丢如下配置,以后只要使用 cache.set 和 cache.get 通过都是去redis设置和取:
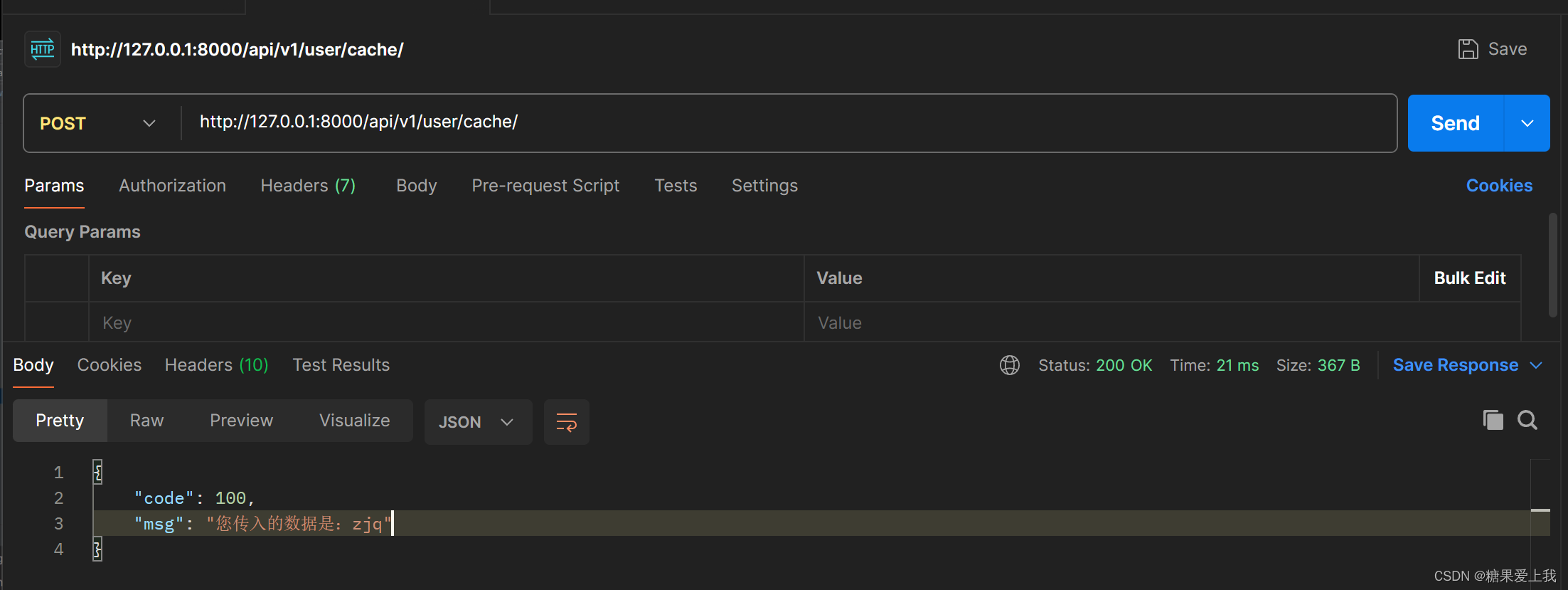
CACHES = {"default": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379","OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient","CONNECTION_POOL_KWARGS": {"max_connections": 100}# "PASSWORD": "123",}} }# redis缓存 from django.core.cache import cacheclass CacheView(ViewSet):def list(self, request):name = request.query_params.get('name')cache.set('name', name,10)return APIResponse(msg='您传入的数据已经加入缓存')def create(self,request):res=cache.get('name')return APIResponse(msg='您传入的数据是:%s'% res)
# 优势:redis 分数据类型, 只能设置5种数据类型
django的缓存来讲 ,不限制类型,可以放python的任意类型
用 cache.set()放入任意类型,取出来还是这个类型
# 底层原理:把你存储的类型,使用pickle序列化,bytes格式,当redis的字符串形式存到redis中
# 所以以后咱们做redis的操作,可以直接使用django的缓存, 不需要考虑类型

首页轮播图接口缓存
# 原因:首页轮播图接口,只要有一个用户访问一次首页,就会查询一次数据库
用户量很大,同时来访问首页,不停的查询 Banner表# 做缓存:django的cache
第一次去数据库拿,把取出来的数据,放到缓存中,以后只要访问轮播图接口,都从缓存中取,这个接口的响应速度就会非常快
# 提高速度:接口+缓存
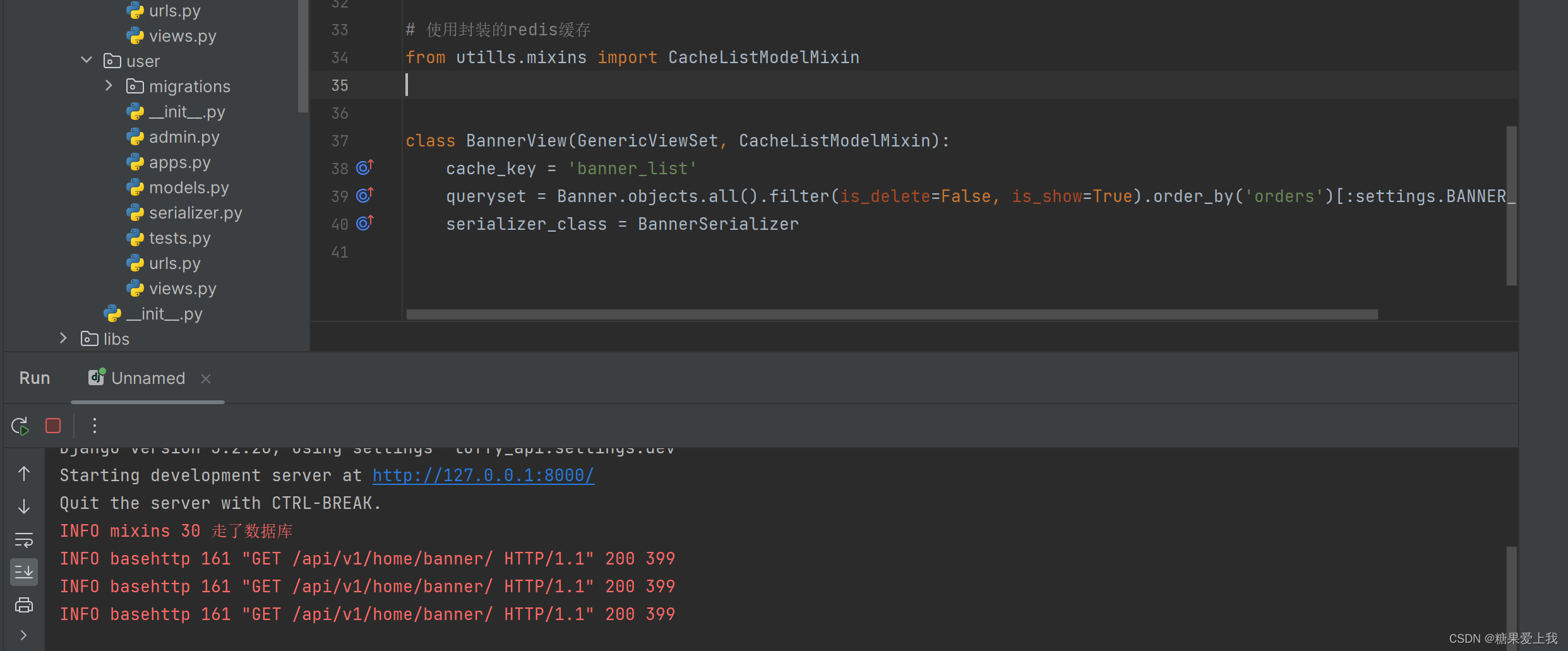
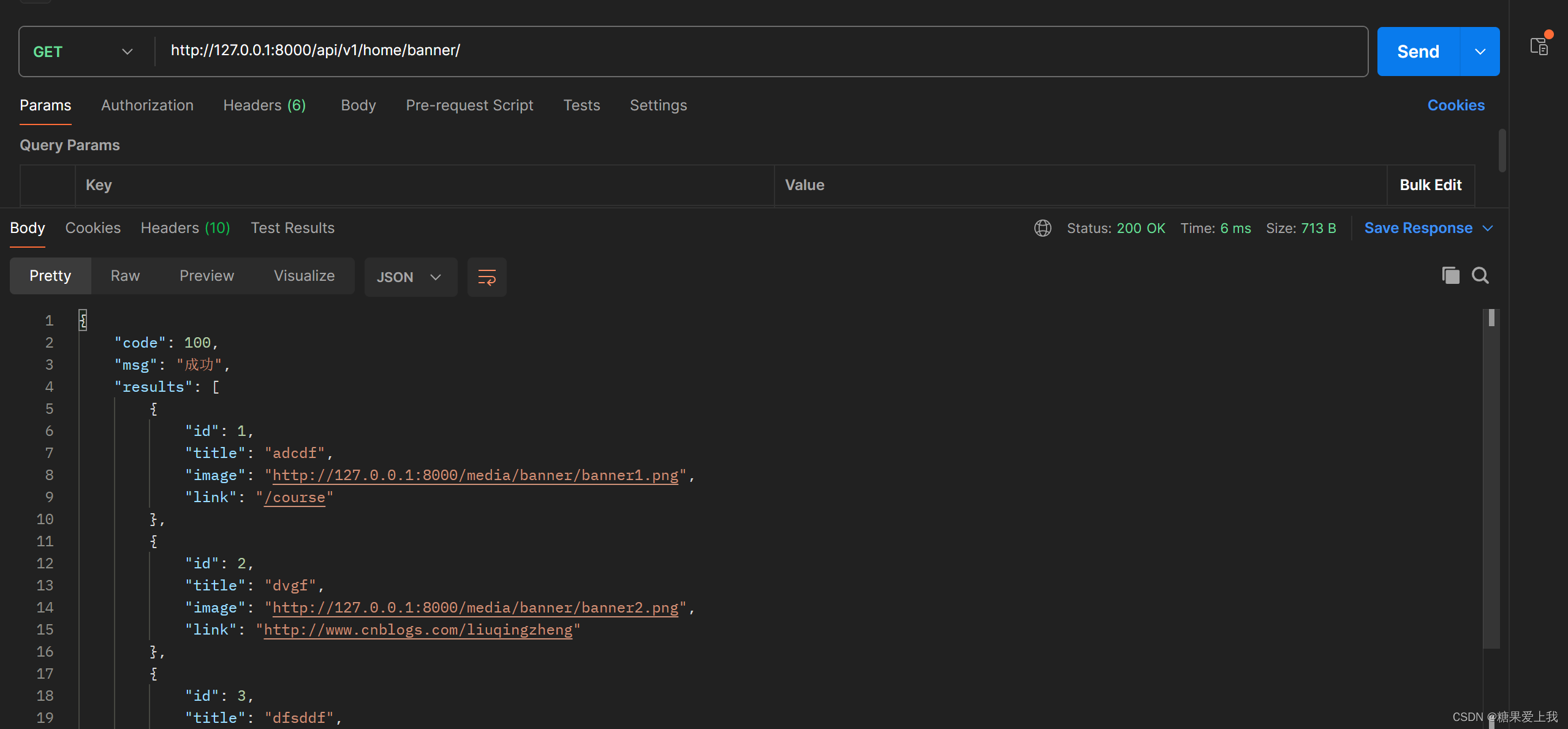
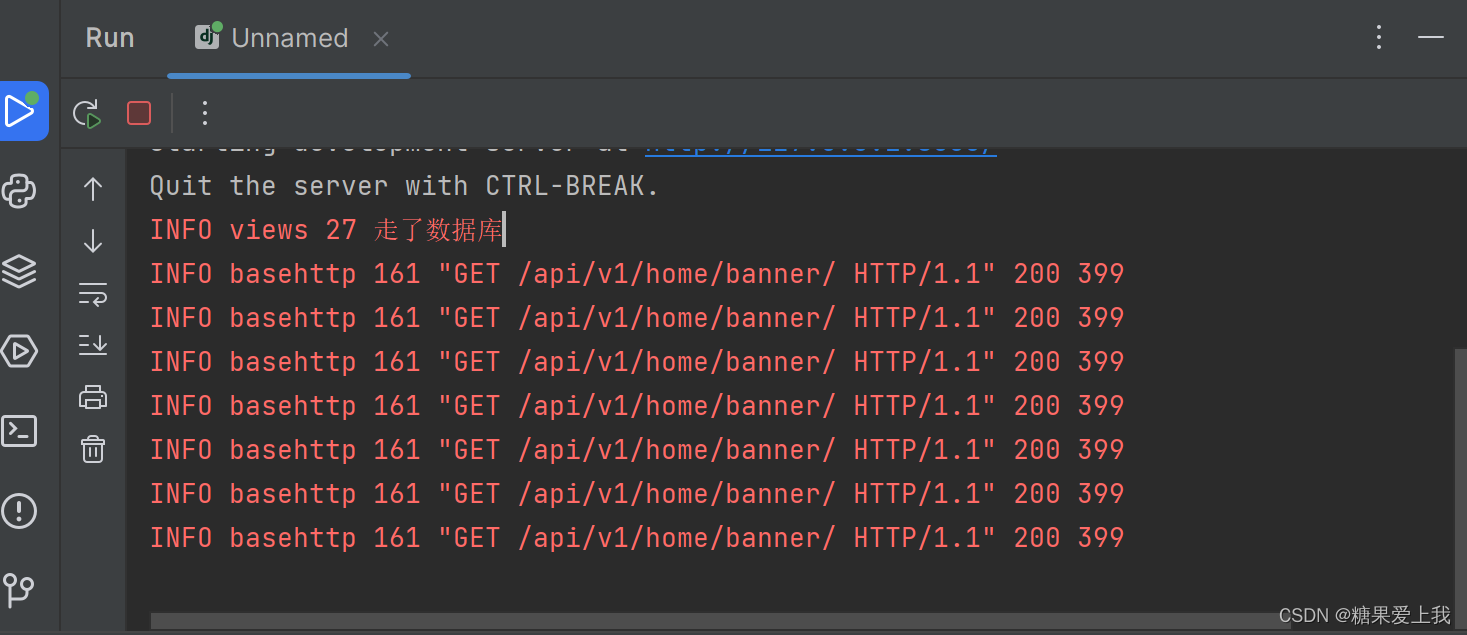
# apps/home/views.py from django.conf import settings from utills.common_response import APIResponse from utills.common_logger import logger from rest_framework.mixins import ListModelMixin# 查询所有轮播图 class BannerView(GenericViewSet, CommonListModelMixin):# qs对象可以切片,limit 2queryset = Banner.objects.all().filter(is_delete=False, is_show=True).order_by('orders')[:settings.BANNER_COUNT]serializer_class = BannerSerializerdef list(self, request, *args, **kwargs):# 先查缓存,缓存中有直接返回banner_list = cache.get('banner_list') # 列表类型# 缓存中没有:去数据库查if not banner_list:logger.info('走了数据库')res = ListModelMixin.list(self, request, *args, **kwargs)banner_list = res.datacache.set('banner_list', banner_list)return APIResponse(results=banner_list)
缓存其他
# 问题1:双写一致性
后期如果banner表中数据变了,由于一直取的是缓存数据,缓存不会变导致数据不一致
# 解决:mysql redis要同步写
# 问题2:所有查询所有或单条的接口,都可以加缓存
封装一个 mixin的类,不需要重写list方法,只需要配置一下,就能使用缓存后续只需配上cache_key就是走了缓存,没配就是走数据库:
# utills/mixins.py # 封装缓存 from utills.common_logger import logger from django.core.cache import cacheclass CacheListModelMixin(ListModelMixin):cache_key = Nonedef list(self, request, *args, **kwargs):if self.cache_key:res = cache.get(self.cache_key)if not res:logger.info('走了数据库')response = super(CacheListModelMixin, self).list(request, *args, **kwargs)cache.set(self.cache_key, response.data)res = response.datareturn APIResponse(results=res)else:res = super(CacheListModelMixin, self).list(request, *args, **kwargs)return APIResponse(results=res.data)# apps/home/views.py # 使用封装的redis缓存 from utills.mixins import CacheListModelMixinclass BannerView(GenericViewSet, CacheListModelMixin):cache_key = 'banner_list'queryset = Banner.objects.all().filter(is_delete=False, is_show=True).order_by('orders')[:settings.BANNER_COUNT]serializer_class = BannerSerializer