文章目录
- 1、FunctionalInterface注释
- 2、接口默认方法
- 3、lambda表达式
- 4、方法引用
- 5、走入函数式编程
- 6、并行流与并行排序
- 6.1、使用并行流过滤数据
- 6.2、从集合得到并行流
- 6.3、并行排序
在正式进入函数式编程之前,有必要先了解一下Java 8为支持函数式编程所做的基础性的改进。
1、FunctionalInterface注释
Java 8提出了函数式接口的概念。所谓函数式接口,简单地说,就是只定义了单一抽象方法的接口。比如下面的定义:
@FunctionalInterface
public interface IntHandler {void handle(int i);
}
注释FunctionalInterface用于表明IntHandler接口是一个函数式接口,该接口只包含一个抽象方法handle(),因此它符合函数式接口的定义要求。如果一个函数满足函数式接口的定义要求,那么即使不标注为@FunctionalInterface,编译器依然会把它看作函数式接口。这有点像@Override注释,如果你的函数符合重载的规范,无论你是否标注了@Override,编译器都会识别这个重载函数,但如果你进行了标注,而实际的代码不符合规范,那么就会得到一个编译错误的提示。下图展示了一个不符合规范却被标注为@FunctionalInterface的接口:

很显然,IntHandler接口包含两个抽象方法,因此不符合函数式接口的定义要求,又因为IntHandler接口被标注为函数式接口,产生矛盾,故编译出错。
这里需要强调的是,函数式接口只能有一个抽象方法,而不是只能有一个方法。我分两点来说明:首先,在Java 8中,接口运行存在实例方法(参见下一节的“接口默认方法”);其次,任何被java.lang.Object实现的方法都不能视为抽象方法,因为equals()方法在java.lang.Object中已经实现,所以NonFunc接口不是函数式接口。

函数式接口的实例可以由方法引用或者由lambda表达式构造,我们将在后面进一步举例说明。
2、接口默认方法
在Java 8之前,接口只能包含抽象方法。但从Java 8开始,接口也可以包含若干个实例方法。这一改进使得Java 8拥有了类似于多继承的功能。一个对象实例,将拥有来自多个不同接口的实例方法。
比如,接口IHorse的实现如下:
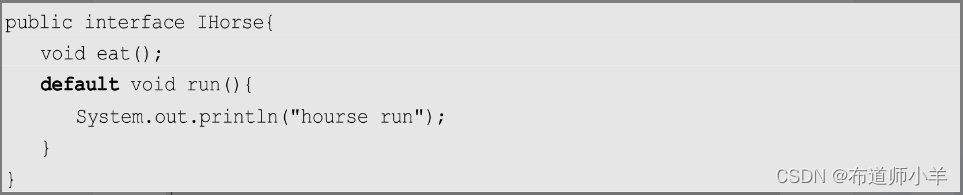
在Java 8中,使用default关键字可以在接口内定义实例方法。注意,这个方法并非抽象方法,而是拥有特定逻辑的具体实例方法。
所有的动物都能自由呼吸,所以,这里可以再定义一个IAnimal接口,它也包含一个默认方法breath():

骡是马和驴的杂交物种,因此骡(Mule)可以实现为IHorse,同时骡也是动物,因此有:

注意,上述代码中Mule实例同时拥有来自不同接口的实现方法,这在Java 8之前是做不到的。从某种程度上说,这种模式可以弥补Java单一继承的一些不便。但同时要知道,它将遇到和多继承相同的问题,如下图所示:
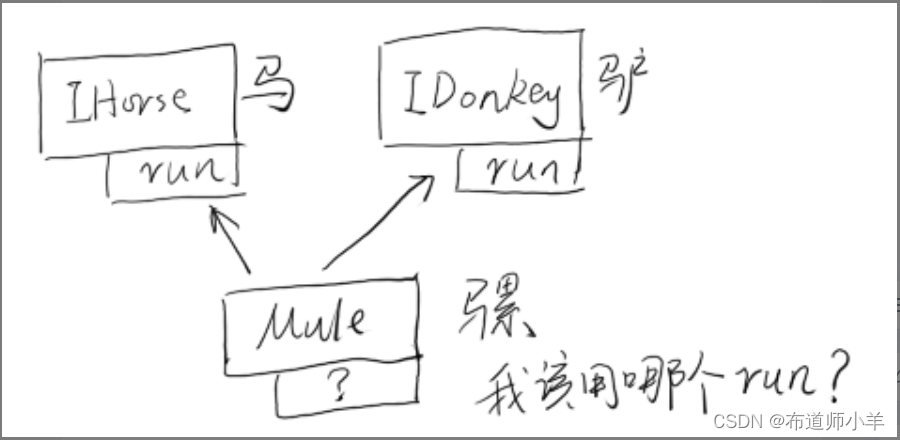
如果IDonkey也存在一个默认的run()方法,那么同时实现它们的Mule就会不知所措,因为它不知道应该以哪个方法为准。
增加一个IDonkey的实现:
public interface IDonkey {void eat();default void run(){System.out.println("Donkey run");}
}
修改Mule的实现如下,注意它同时实现了IHorse和IDonkey:
public class Mule implements IHorse,IDonkey,IAnimal{@Overridepublic void eat() {System.out.println("Mule eat");}public static void main(String[] args) {Mule mule = new Mule();mule.run();mule.breath();}
}此时,由于IHorse和IDonkey拥有相同的默认实例方法,故编译器会抛出一个错误:

为了让Mule同时实现IHorse和IDonkey,我们不得不重新实现一下run()方法,让编译器可以进行方法绑定。修改Mule的实现如下:
public class Mule implements IHorse,IDonkey,IAnimal{@Overridepublic void eat() {System.out.println("Mule eat");}@Overridepublic void run() {IHorse.super.run();}public static void main(String[] args) {Mule mule = new Mule();mule.run();mule.breath();}
}
在这里,将Mule的run()方法委托给IHorse实现,当然,大家也可以有自己的实现。
接口默认实现对于整个函数式编程的流式表达非常重要。比如,大家熟悉的java.util.Comparator接口,它在JDK 1.2时就已经被引入了,用于在排序时给出两个对象实例的具体比较逻辑。在Java 8中,Comparator接口新增了若干个默认方法,用于多个比较器的整合。其中一个常用的默认方法如下:

有了这个默认方法,在排序时,我们就可以非常方便地进行元素的多条件排序。比如,如下代码构造一个比较器,它先按照字符串长度排序,继而按照大小写不敏感的字母顺序排序:

3、lambda表达式
lambda表达式可以说是函数式编程的核心。lambda表达式即匿名函数,它是一段没有函数名的函数体,可以作为参数直接传递给相关的调用者,lambda表达式极大地增强了Java语言的表达能力。
下例展示了lambda表达式的使用方法,在forEach()方法中,传入的就是一个lambda表达式,它完成了对元素的标准输出操作。可以看到这段表达式并不像函数一样有名字,类似匿名内部类,它只是简单地描述了应该执行的代码段。

和匿名对象一样,lambda表达式也可以访问外部的局部变量,如下所示:

上述代码可以编译通过,正常执行并输出6。与匿名内部对象一样,在这种情况下,外部的num变量必须声明为final定义的,这样才能保证在lambda表达式中合法地访问它。
奇妙的是,对于lambda表达式而言,即使去掉上述的final,程序依然可以编译通过!但千万不要以为这样你就可以修改num的值了。实际上,这只是Java 8做的一个小处理,它会自动地将在lambda表达式中使用的变量视为final定义的。因此,下述代码是可以编译通过的:

但是,如果像下面这么写,就不行:

上述的num++会引起一个编译错误:

4、方法引用
方法引用是Java 8中提出的用来简化lambda表达式的一种手段。它通过类名和方法名来定位一个静态方法或者实例方法。
方法引用在Java 8中的使用非常灵活。总的来说,可以分为以下几种:
- 静态方法引用:ClassName::methodName。
- 超类上的实例方法引用:super::methodName。
- 类型上的实例方法引用:ClassName::methodName。
- 构造方法引用:Class::new。
- 数组构造方法引用:TypeName[]::new。
首先,方法引用使用“::”定义,“::”的前半部分表示类名或者实例名,后半部分表示方法名。如果是构造函数,则使用new表示。
下例展示了方法引用的基本使用方法:
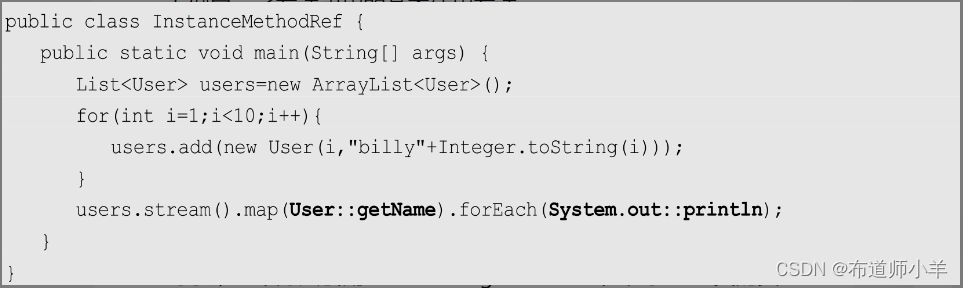
对于第一个方法引用“User::getName”,表示User类的实例方法。在执行时,Java会自动识别流中的元素(这里指User实例)是作为调用目标还是调用方法的参数。在“User::getName”中,显然流内的元素都应该作为调用目标,实际上,在这里调用了每一个User对象实例的getName()方法,并将这些User的name作为一个新的流。同时,对于这里得到的所有name,使用方法引用System.out::println处理。这里的System.out为PrintStream对象实例,因此,这里表示System.out实例的println方法。系统也会自动判断出流内的元素此时应该作为方法的参数传入,而不是调用目标。
一般来说,如果使用的是静态方法,或者调用目标明确,那么流内的元素会自动作为参数使用。如果方法引用表示实例方法,并且不存在调用目标,那么流内元素就会自动作为调用目标。
如果一个类中存在同名的实例方法和静态方法,那么编译器就会感到很困惑,因为此时它不知道应该使用哪个方法。它既可以选择同名的实例方法,将流内元素作为调用目标,也可以使用静态方法,将流内元素作为参数。
请看下面的例子:

上述代码试图将所有的Double元素转为String并将其输出,但是很不幸,在Double中同时存在以下两个方法:

此时,对方法引用的处理就出现了歧义,因此,这段代码在编译时就会抛出如下错误:

方法引用也可以直接使用构造函数。首先,查看模型类User的定义:
/*** @title User* @description 用户* @author: yangyongbing* @date: 2024/2/26 12:49*/
public class User {private int id;private String name;public User(int id, String name) {this.id = id;this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}
}下面的方法引用调用了User的构造函数:
import java.util.ArrayList;
import java.util.List;/*** @title ConstrMethodRef* @description 方法的引用* @author: yangyongbing* @date: 2024/2/26 12:51*/
public class ConstrMethodRef {interface UserFactory<U extends User> {U create(int id, String name);}static UserFactory<User> uf = User::new;public static void main(String[] args) {List<User> users = new ArrayList<>();for (int i = 0; i < 10; i++) {users.add(uf.create(i, "billy" + Integer.toBinaryString(i)));}users.stream().map(User::getName).forEach(System.out::println);}}在此,UserFactory作为User的工厂类,是一个函数式接口。当使用User::new创建接口实例时,系统会根据UserFactory.create()的签名来选择合适的User构造函数。在这里,很显然就是public User(int id, String name)。在创建UserFactory实例后,对UserFactory.create()的调用,都会委托给User的实际构造函数进行,从而创建User对象实例。
5、走入函数式编程
在了解了Java 8的一些新特性后,我们就可以正式开始走入函数式编程了。为了能让大家更快地理解函数式编程,我们先从简单的例子开始:

上述代码循环遍历了数组内的元素,并且进行了数值的打印,这也是传统的做法。如果使用Java 8中的流,那么可以写成这样:

注意:Arrays.stream()方法返回了一个流对象。类似于集合或者数组,流对象也是一个对象的集合,它将使我们可以遍历处理流内元素。
这里值得注意的是这个流对象的forEach()方法,它接收一个IntConsumer接口,用于对每个流内的对象进行处理。之所以是IntConsumer接口,因为当前流是IntStream,也就是装有Integer元素的流,因此,它自然需要一个处理Integer元素的接口。forEach()方法会依次将流内的元素送入IntConsumer接口进行处理,循环过程被封装在forEach()方法内部,也就是JDK框架内。
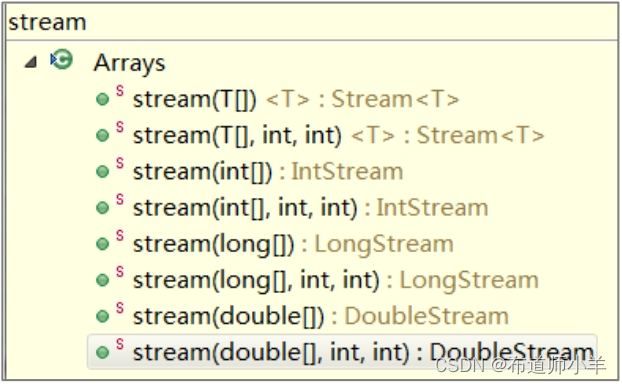
除了IntStream流,Arrays.stream()方法还支持DoubleStream、LongStream和普通的对象流Stream,这完全取决于它接收的参数。Stream流的几种类型如下图所示:
这样的写法可能还不能让人满意,代码量似乎比原先更多,而且除了引入了不必要的接口和匿名类等复杂性外,似乎也看不出来有什么太大的好处。但是,我们的脚步并未就此打住。试想,既然forEach()方法的参数是可以从上下文中推导出来的,为什么还要不厌其烦地写出来呢?这些机械的推导工作就交给编译器去做吧!
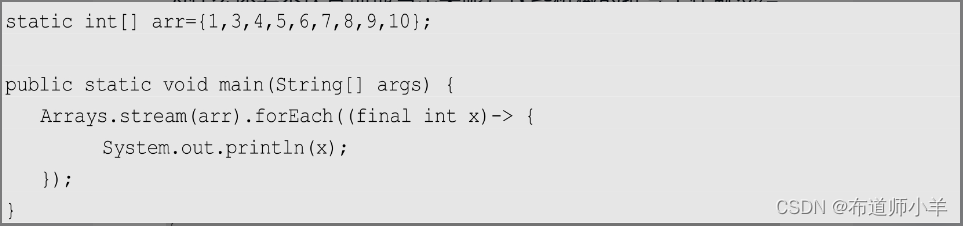
从上述代码中可以看到,IntStream接口名称被省略了,这里只使用了参数名和一个实现体,看起来简洁很多了。但是还不够,因为参数的类型也是可以推导的。既然是IntConsumer接口,参数自然是int类型的。
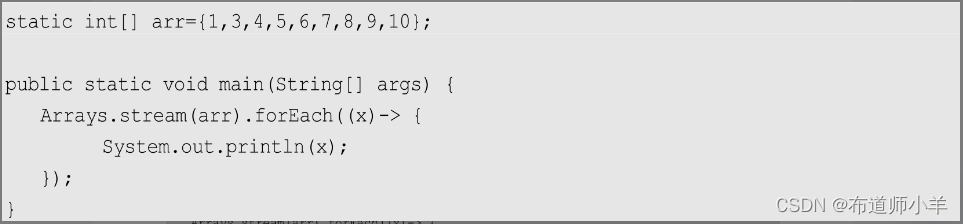
好了,现在连参数类型也省略了,但是两个花括号特别碍眼。虽然它们对程序没有什么影响,但是为了简单的一句执行语句要加上一对花括号实属多余,干脆也去掉吧!去掉花括号后,为了清晰起见,就把参数声明和接口实现放在一行吧!

这样看起来就好多了。此时,forEach()方法的参数依然是IntConsumer,但是它却以一种新的形式被定义,这就是lambda表达式。表达式由“->”分割,左半部分表示参数,右半部分表示实现体。我们可以简单地理解为:lambda表达式只是匿名对象实现的一种新的方式。实际上也是这样的。
有兴趣的读者可以使用虚拟机参数-Djdk.internal.lambda.dumpProxyClasses启动带有lambda表达式的Java小程序,该参数会将lambda表达式相关的中间类型输出,方便调试和学习。在本例中,输出了HelloFunction6$$Lambda$1.class类,使用以下命令反汇编:

在输出结果中,可以清楚地看到:
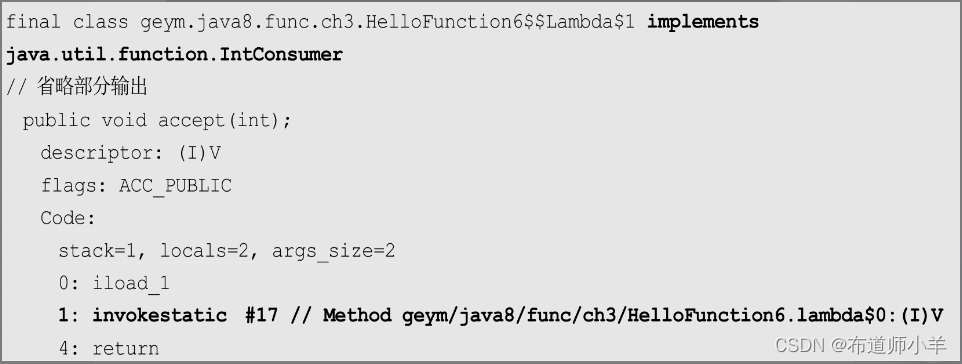
限于篇幅,这里只给出了我们关心的内容。首先,这个中间类型确实实现了IntConsumer接口。其次,在实现accept()方法时,它内部委托给了一个名为HelloFunction6.lambda$0()的方法,这个方法是编译时自动生成的。
使用以下命令查看HelloFunction6的编译结果:

我们很惊喜地找到了期待已久的lambda$0()方法,其实现如下:
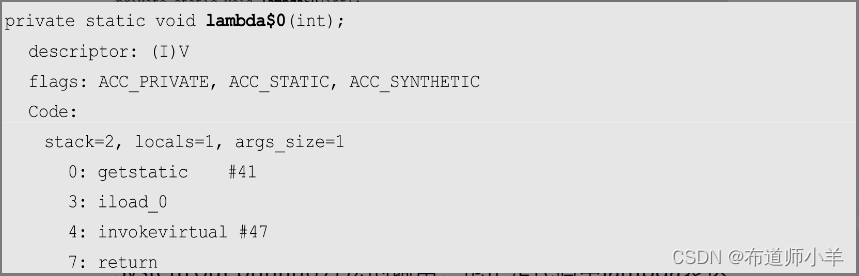
它被实现为一个私有的静态方法,实现内容就是简单地进行了System.out.println()方法的调用,也正是代码中lambda表达式的内容。
由此可见,Java 8中对lambda表达式的处理几乎等同于匿名类的实现,但是在写法上和编程范式上有明显的区别。
不过,简化代码的流程并没有结束,在上一节中已经提到,Java 8还支持方法引用,你甚至连参数声明和传递都可以省略:

至此,欢迎大家正式进入Java 8函数式编程的殿堂,那些看似玄妙的lambda表达式的解析和工作原理已经介绍完毕。
使用lambda表达式不仅可以简化匿名类的编写,与接口的默认方法相结合,还可以使用更顺畅的流式API对各种组件进行更自由的装配。
下面这个例子对集合中的所有元素进行两次输出,一次输出到标准错误中,另一次输出到标准输出中:

这里首先使用方法引用,直接定义了两个IntConsumer接口实例,一个指向标准输出,另一个指向标准错误。用接口默认方法IntConsumer.addThen()将两个IntConsumer进行组合,得到一个新的IntConsumer,新的IntConsumer会依次调用outprintln和errprintln,完成对数组中元素的处理。
其中方法IntConsumer.addThen()的实现如下:

6、并行流与并行排序
Java 8可以在接口不变的情况下,将流改为并行流。这样,就可以很自然地使用多线程进行集合中的数据处理。
6.1、使用并行流过滤数据
现在让我们考虑这么一个简单的案例,统计1~1000000内质数的数量。首先,我们需要一个判断质数的方法:
给定一个数字,如果这个数字是质数,上述方法就返回true,否则返回false。
接着,使用函数式编程统计给定范围内所有的质数:

上述代码首先生成一个1到1000000的数字流。接着使用过滤方法,只选择所有的质数,最后进行数量统计。
上述代码是串行的,将它改造成并行计算非常简单,只需要将流并行化即可:

在上述代码中,parallel()方法得到一个并行流,然后在并行流上进行过滤,此时PrimeUtil.isPrime()方法会被多线程并发调用,应用于流中的所有元素。
6.2、从集合得到并行流
在函数式编程中,我们可以从集合得到一个流或者并行流。下面这段代码试图统计集合内所有学生的平均分:

从集合对象List中,我们使用stream()方法可以得到一个流。如果希望将这段代码并行化,则可以使用parallelStream()方法:

可以看到,将原有的串行方式改造成并行方式是非常容易的。
6.3、并行排序
除了并行流,对于普通数组,Java 8也提供了简单的并行功能。比如,进行数组排序可以使用Arrays.sort()方法,当然这是串行排序方法,在Java 8中可以使用新增的Arrays.parallelSort()方法直接进行并行排序。
比如,你可以这样使用:

除了并行排序,Arrays中还增加了一些API用于数组中数据的赋值,比如:

这是一个函数式味道很浓的接口,它的第二个参数是一个函数式接口。如果我们想给数组中每一个元素都附上一个随机值,则可以这么做:

当然,以上过程是串行的。但是只要使用setAll()方法对应的并行版本,你就可以在多个CPU上执行它: