缓存一致性问题的背景和概念介绍
在一个系统中,我们通常使用数据库来存储数据,以保证数据的持久性。但是,由于数据库的读写速度相对较慢,如果每次请求都直接访问数据库,会降低系统的响应速度。为了提高系统的性能,我们通常会缓存数据库中的数据。在项目中,我们需要同时维护数据库和缓存的数据确保它们是一致的,但在多线程的场景下,会有各种各样的情况导致数据库和缓存不一致的问题。
应用场景和例子
情景一:更新操作先更新数据库,再修改缓存。
&&
情景二:更新操作先修改缓存,再更新数据库。
假设有线程1和线程2,整个程序按照时间顺序执行四步,对于情景一,假设当前数据库和缓存中的数据都是1,第一步线程1把数据库更新为2,此时缓存还没有更新;第二步切换到线程2执行,线程2把数据库更新为3;第三步线程2把缓存修改为3;第四步又切换到线程1执行,线程1执行之前未完成的工作,把缓存修改为2; 此时数据库中的数据为3,而缓存中的数据为2,出现不一致问题,对于情景二同理。

并且这样会使逻辑变得复杂,在更新的时候首先要判断缓存中是否有对应的数据,如果不存在对应的数据是不能更新的,因为这样会把很多没必要的数据塞到内存中,造成内存浪费,同时还要去保证判断和写操作之间的原子性。同时生成缓存数据的成本可能较高,如果每次更新操作都要去修改缓存的话,对于网红大V的粉丝数,写操作是远远大于读操作的,如果每次粉丝数增加都要去修改缓存,成本就很大了。
所以这里的解决方案是当数据库的数据需要更新时,直接删除缓存。而需要读取数据时,才去更新缓存,这样就引出了情景三和情景四。
情景三:更新操作先删除缓存,再更新数据库。
&&
情景四:更新操作先更新数据库,再删除缓存。
对于这两种情景,我们选择先更新数据库,再删除缓存,原因如下图。结合下图来看文字,注意只有缓存未命中的时候,才会去读数据库更新缓存,否则就直接返回缓存中读到的数据。
假设线程一先删缓存,再更新数据库,在这两个操作之间,线程二去读取数据,因为缓存已经被删了所以缓存未命中,从而去数据库读,但是此时线程一还没有完成更新数据库的操作,所以此时线程二读到的是旧数据,然后它更新了缓存。线程二执行完成后,线程一继续执行,线程一更新数据库,此时就存在了数据不一致问题,当前数据库中的数据是线程一新写的,而缓存中的数据是线程二在之前更新的。那么从现在开始到缓存过期的这段时间,这个数据都是不一致的。
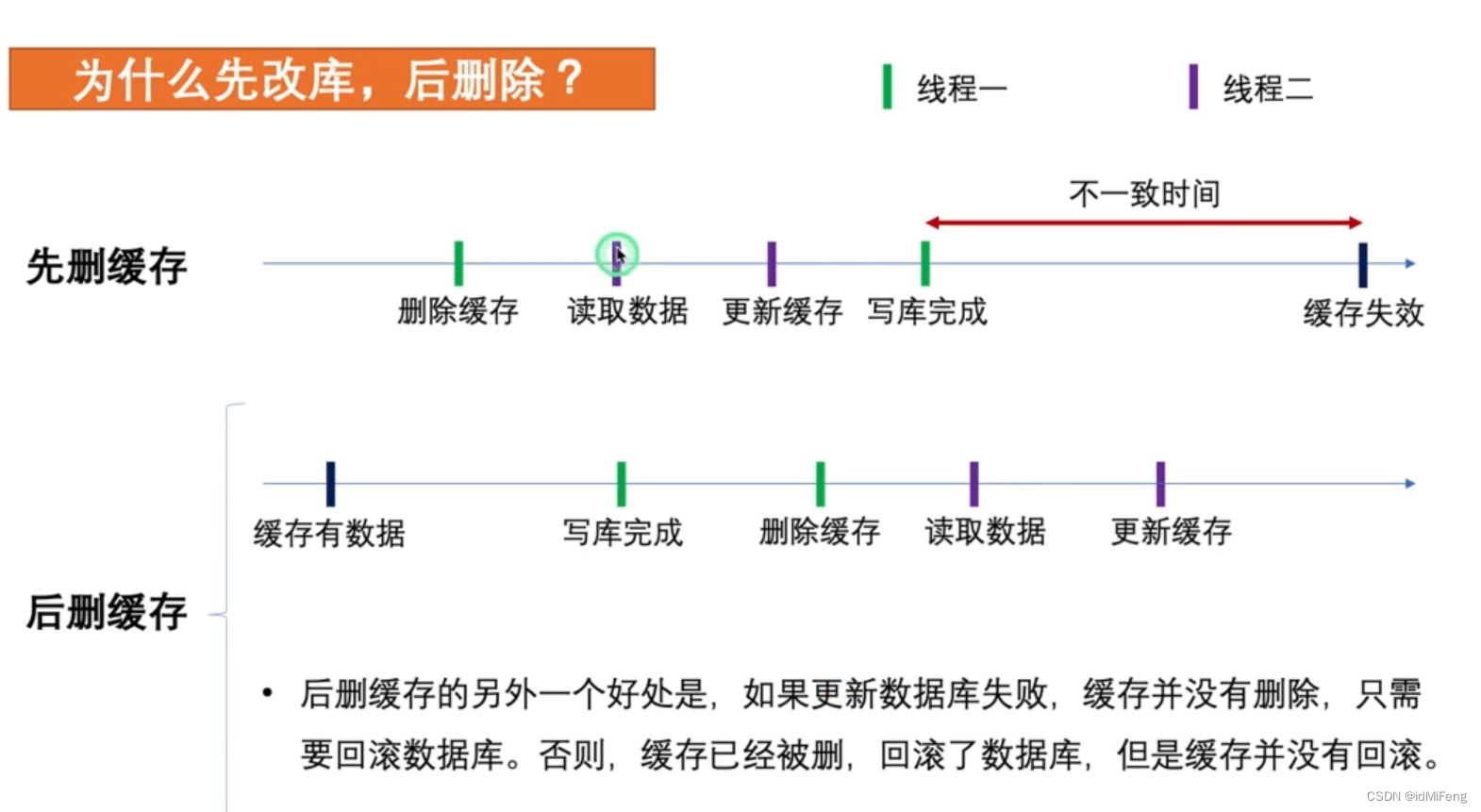
而对于先更新数据库,再删除缓存,如上图,只有当线程二的读取数据操作发生在线程一的写库和删缓存操作之间,此时线程一已经写库完成了,但是线程二读到的是之前的缓存,就存在不一致问题,不过在线程一写库完成,线程一删除缓存这两个操作之间的时间是远小于线程一删除缓存,线程一写库完成这两个操作之前的时间的,所以即使出现缓存不一致的情况,概率也远低于先删除缓存,再更新数据库的情景。
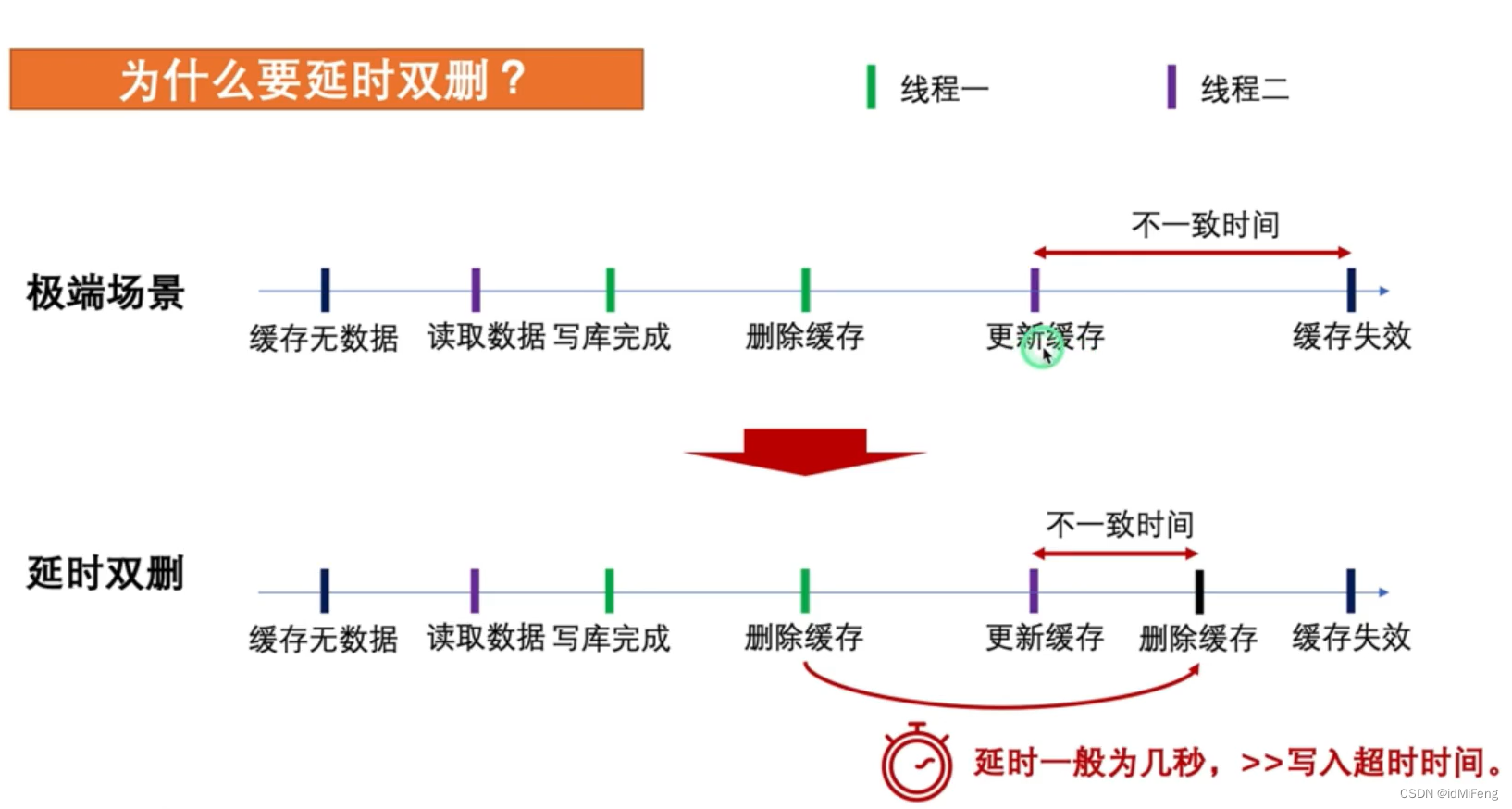
最后解法:更新操作先更新数据库,再删除缓存,并引入延时双删。
不过推进到现在仍然存在缓存不一致的情况,那么就可以引入一种叫做延时双删的策略,具体做法是,在更新数据库后,先删除缓存中的数据,并设置一个短暂的延时。在延时结束后,再次删除缓存中的数据,这样就算另一个线程把读到的旧数据写入缓存中,因为有个二次删除的操作,缓存不一致的时间也会大大降低。