前言
分布式算法的文章我早就想写了,但是一直比较忙,没有写,最近一个项目又用到了,就记录一下运用Spark部署机器学习分类算法-随机森林的记录过程,写了一个demo。
基于pyspark的随机森林算法预测客户
本次实验采用的数据集链接:https://pan.baidu.com/s/13blFf0VC3VcqRTMkniIPTA
提取码:DJNB
数据集说明
某运营商提供了不同用户3个月的使用信息,共34个特征,1个标签列,其中存在一定的重复值、缺失值与异常值。各个特征的说明如下:
MONTH_ID 月份
USER_ID 用户id
INNET_MONT 在网时长
IS_AGREE 是否合约有效客户
AGREE_EXP_DATE 合约计划到期时间
CREDIT_LEVEL 信用等级
VIP_LVL vip等级
ACCT_FEE 本月费用(元)
CALL_DURA 通话时长(秒)
NO_ROAM_LOCAL_CALL_DURA 本地通话时长(秒)
NO_ROAM_GN_LONG_CALL_DURA 国内长途通话时长(秒)
GN_ROAM_CALL_DURA 国内漫游通话时长(秒)
CDR_NUM 通话次数(次)
NO_ROAM_CDR_NUM 非漫游通话次数(次)
NO_ROAM_LOCAL_CDR_NUM 本地通话次数(次)
NO_ROAM_GN_LONG_CDR_NUM 国内长途通话次数(次)
GN_ROAM_CDR_NUM 国内漫游通话次数(次)
P2P_SMS_CNT_UP 短信发送数(条)
TOTAL_FLUX 上网流量(MB)
LOCAL_FLUX 本地非漫游上网流量(MB)
GN_ROAM_FLUX 国内漫游上网流量(MB)
CALL_DAYS 有通话天数
CALLING_DAYS 有主叫天数
CALLED_DAYS 有被叫天数
CALL_RING 语音呼叫圈
CALLING_RING 主叫呼叫圈
CALLED_RING 被叫呼叫圈
CUST_SEX 性别
CERT_AGE 年龄
CONSTELLATION_DESC 星座
MANU_NAME 手机品牌名称
MODEL_NAME 手机型号名称
OS_DESC 操作系统描述
TERM_TYPE 硬件系统类型(0=无法区分,4=4g,3=dg,2=2g)
IS_LOST 用户在3月中是否流失标记(1=是,0=否),1月和2月值为空(标签)
数据字段打印
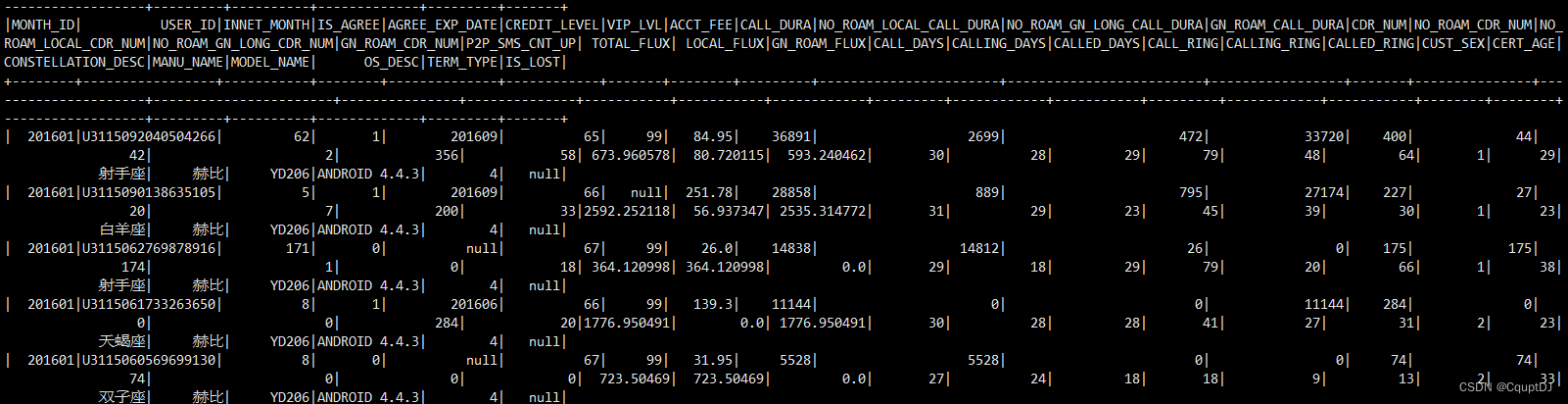
将数据集放到hadoop的HDFS中,通过Saprk读取HDFS文件里面的CSV格式的数据集,通过hadoop命令上传本地数据集到HDFS:
hadoop fs -put ./USER_INFO_M.csv /data/test/USER_INFO_M.csv
查看HDFS中的数据集CSV文件:
hadoop fs -ls /data/test

Spark中搭建分布式随机森林模型
从上面的数据集可以看到,数据是一个二分类数据,IS_LOST就是需要预测的标签,所以只需要构建一个随机森林二分类模型就可以了。Spark中提供了用于机器学习算法的库MLlib,这个库里面包含了许多机器学习算法,监督学习和无监督学习算法都有,例如线性回归、随机森林、GBDT、K-means等等(没有sklearn中提供的算法多),但是和sklearn中的随机森林模型构建有区别的是spark中程序底层是基于RDD弹性分布式计算单元,所以基于RDD的DataFrame数据结构和python中的DataFrame结构不一样,写法就不一样,python程序写的随机森林算法是不能直接在Spark中运行的,我们需要按照Spark中的写法来实现随机森林模型的构建,直接看代码:
from pyspark.sql import SparkSession
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml import Pipeline
from pyspark.sql.functions import col
import timestart_time = time.time()
# 创建SparkSession
spark = SparkSession.builder.appName("RandomForestExample").getOrCreate()# 读取数据集,数据集放在HDFS上
data = spark.read.csv("/data/test/USER_INFO_M.csv", header=True, inferSchema=True, encoding='gbk')
print('=====================================================')
data.show()
# 去除包含缺失值的行
data = data.na.drop(subset=["IS_LOST"])
# 选择特征列和标签列
data = data.select([col for col in data.columns if col not in ['MONTH_ID', 'USER_ID','CONSTELLATION_DESC','MANU_NAME','MODEL_NAME','OS_DESC']])
label_col = "IS_LOST"
feature_cols=['CONSTELLATION_DESC','MANU_NAME','MODEL_NAME','OS_DESC']data = data.fillna(-1)# 创建特征向量列
assembler = VectorAssembler(inputCols=[col for col in data.columns if col not in ["IS_LOST"]], outputCol="features")
data = assembler.transform(data)# 选择特征向量列和标签列
data = data.select("features", label_col)# 将数据集分为训练集和测试集
(trainingData, testData) = data.randomSplit([0.8, 0.2])# 创建随机森林分类器
rf = RandomForestClassifier(labelCol=label_col, featuresCol="features")# 训练模型
model = rf.fit(trainingData)# 在测试集上进行预测
predictions = model.transform(testData)# 评估模型
evaluator = MulticlassClassificationEvaluator(labelCol=label_col, predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)# 打印准确率
print("测试集准确率为: {:.2f}".format(accuracy))
end_time = time.time()
print("代码运行时间: {:.2f}".format(end_time - start_time))
# 关闭SparkSession
spark.stop()
上面是通过python代码构建的Spark中的随机森林模型,Spark支持scala、java、R和python语言,python最简洁,所以直接用pyspark进行程序实现。将上面的代码放到自己的路径下,然后通过spark-submit命令提交.py文件运行即可:
./spark-submit --master yarn --deploy-mode client --num-executors 4 /data/rf/spark_m.py
提交:

拓展:Spark中还支持提交Python环境,而不需要每个spark分布式集群节点都安装适配的python环境,spark-submit命令可以支持将python解释器连同整个配置好了的环境都提交到集群上面然后下发给其他节点,命令如下:
./spark-submit \--master yarn \--deploy-mode client\--num-executors 4\--queue default \--verbose \--conf spark.pyspark.driver.python=/anaconda/bin/python \--conf spark.pyspark.python=/anaconda/bin/python \/test.py
其中spark.pyspark.python和spark.pyspark.driver.python两个参数就是配置提交机器的python环境的路径,还可以通过将python环境打包放到HDFS路径下,Spark直接读取HDFS中的python环境包。
模型运行结果
将数据集按照2-8分为测试集和训练集,在测试集上的预测准确率为97%,运行时间80s。

同时登录集群查看提交的Spark任务运行情况,访问http://localhost:8088/cluster查看如下:
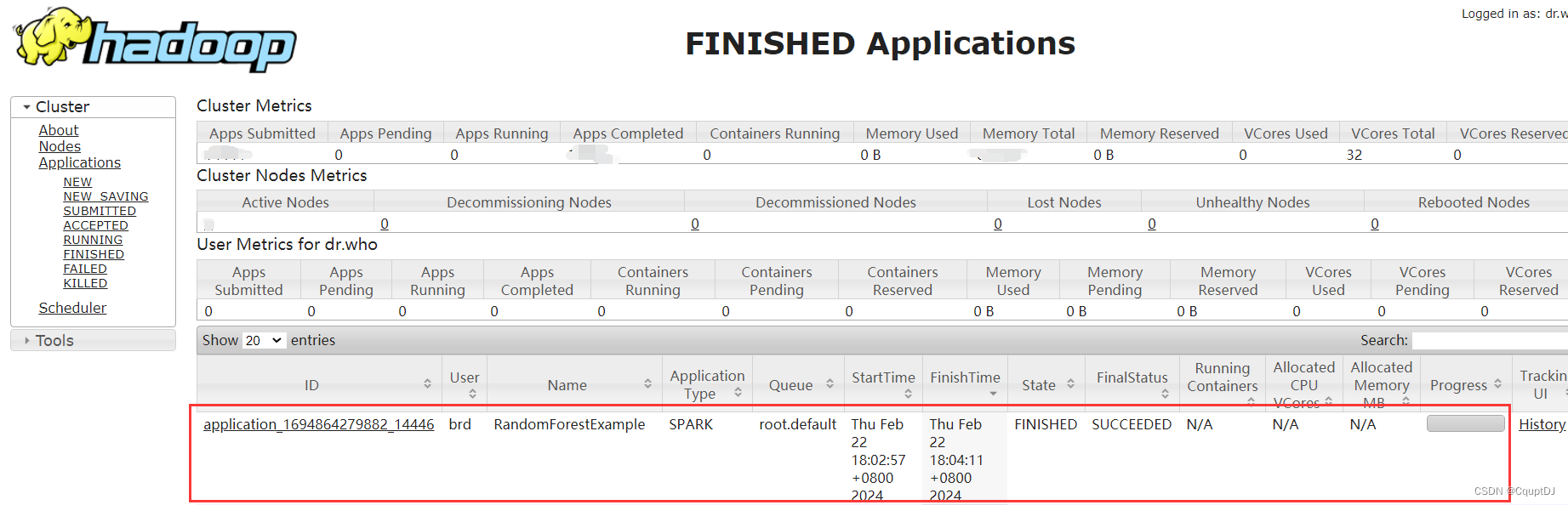
可以看到,RandomForestExample任务就是我们创建的任务,运行完成了,成功!
写在最后
在大规模数据的情况下如果需要用机器学习算法,Spark是一个很好的选择,可以大大提升任务的运行速度,工业环境中效率往往是最需要的,Spark可以解决我们的分布式算法部署需求。
本人才疏学浅,如果有不对的地方请指证!
![[设计模式Java实现附plantuml源码~行为型]算法的封装与切换——策略模式](https://img-blog.csdnimg.cn/direct/c3f715fd4cc24ea48cdb328b8abe5436.png)