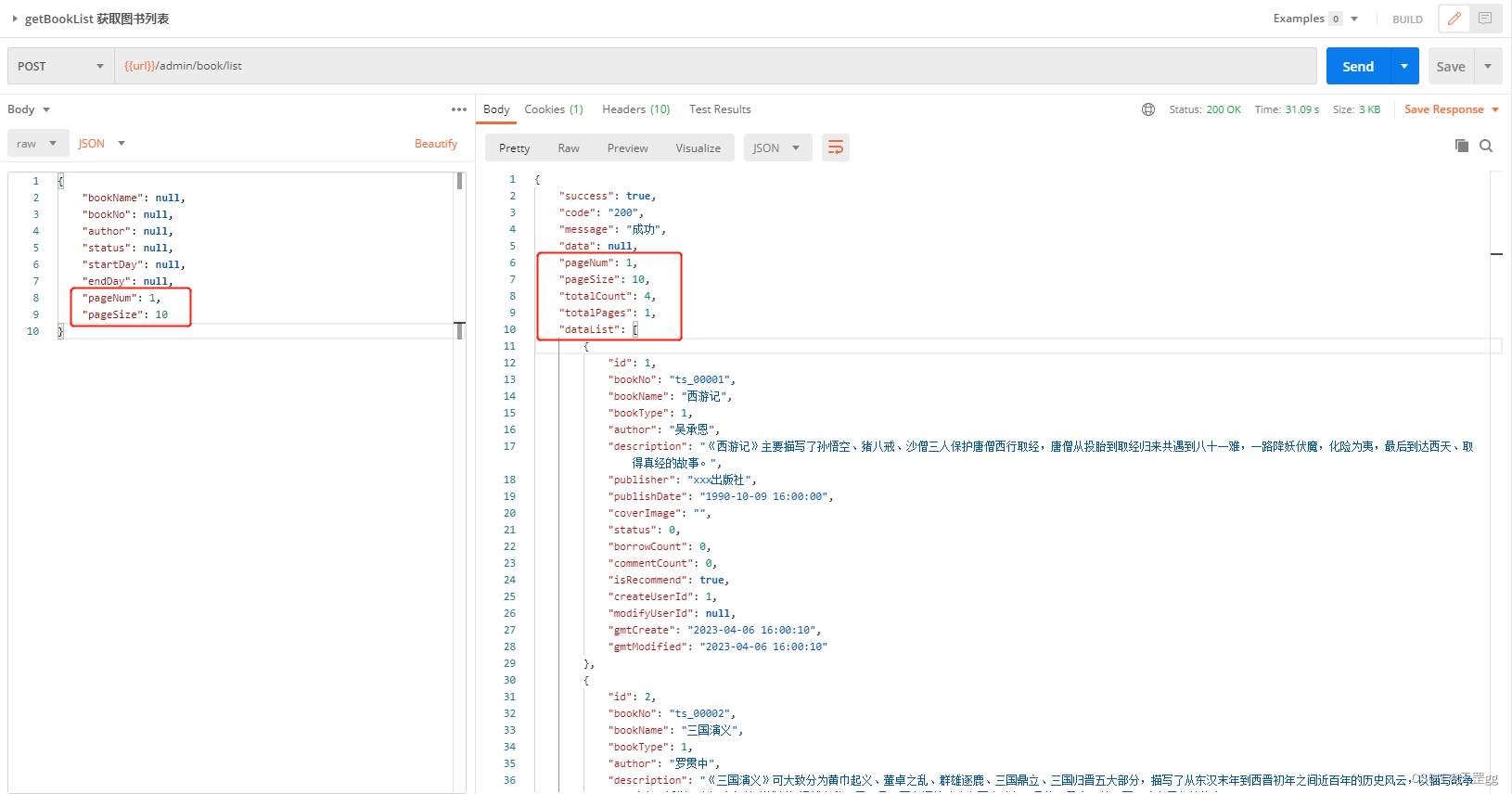
[USACO15FEB] Censoring S
题面翻译
Farmer John为他的奶牛们订阅了Good Hooveskeeping杂志,因此他们在谷仓等待挤奶期间,可以有足够的文章可供阅读。不幸的是,最新一期的文章包含一篇关于如何烹制完美牛排的不恰当的文章,FJ不愿让他的奶牛们看到这些内容。
FJ已经根据杂志的所有文字,创建了一个字符串 S S S ( S S S 的长度保证不超过 1 0 6 10^6 106 ),他想删除其中的子串 T T T ,他将删去 S S S 中第一次出现的子串 T T T ,然后不断重复这一过程,直到 S S S 中不存在子串 T T T 。
注意:每次删除一个子串后,可能会出现一个新的子串 T T T (说白了就是删除之后,两端的字符串有可能会拼接出来一个新的子串 T T T )。
输入格式:第一行是字符串 S S S ,第二行输入字符串 T T T ,保证 S S S 的长度大于等于 T T T 的长度, S S S 和 T T T 都只由小写字母组成。
输出格式:输出经过处理后的字符串,保证处理后的字符串不会为空串。
Translated by @StudyingFather
题目描述
Farmer John has purchased a subscription to Good Hooveskeeping magazine for his cows, so they have plenty of material to read while waiting around in the barn during milking sessions. Unfortunately, the latest issue contains a rather inappropriate article on how to cook the perfect steak, which FJ would rather his cows not see (clearly, the magazine is in need of better editorial oversight).
FJ has taken all of the text from the magazine to create the string S S S of length at most 10^6 characters. From this, he would like to remove occurrences of a substring T T T to censor the inappropriate content. To do this, Farmer John finds the first occurrence of T T T in S S S and deletes it. He then repeats the process again, deleting the first occurrence of T T T again, continuing until there are no more occurrences of T T T in S S S. Note that the deletion of one occurrence might create a new occurrence of T T T that didn’t exist before.
Please help FJ determine the final contents of S S S after censoring is complete.
输入格式
The first line will contain S S S. The second line will contain T T T. The length of T T T will be at most that of S S S, and all characters of S S S and T T T will be lower-case alphabet characters (in the range a…z).
输出格式
The string S S S after all deletions are complete. It is guaranteed that S S S will not become empty during the deletion process.
样例 #1
样例输入 #1
whatthemomooofun
moo
样例输出 #1
whatthefun
题目人话翻译:
删除A串中所有的B子串,包括删除后拼接成的新A串中的B串
大致思路
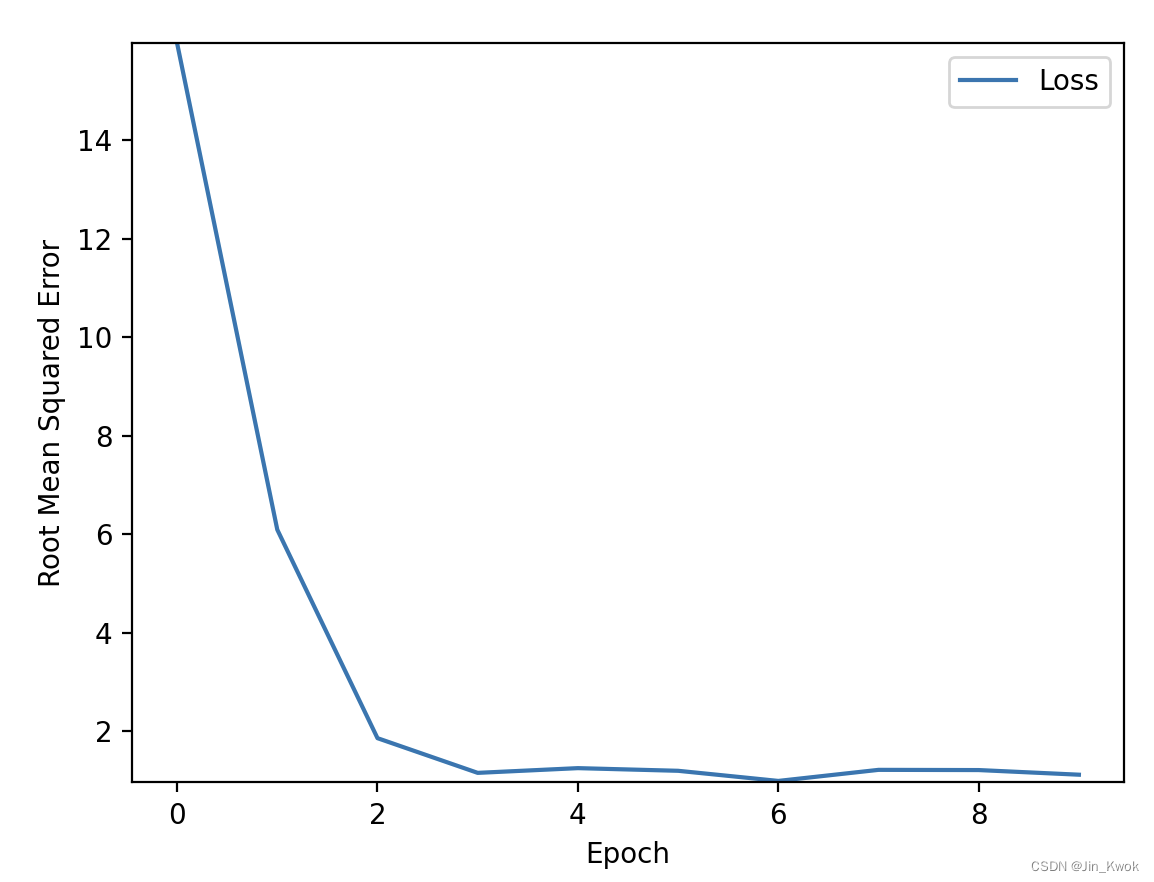
本质上还是一个字串匹配问题,所以KMP。
void pre(){int j=0;p[1]=0;for(int i=1;i<nb;i++){while(j>0&&b[i+1]!=b[j+1])j=p[j];//B串匹配模板if(b[i+1]==b[j+1])j++;p[i+1]=j;}
}
而每次的删除操作很容易就可以想到栈,而STL的栈无法较高效地实现判断新拼接成的A串,因此我们需要简单写一个手写栈。
而KMP判断过程中的主串也就变为了栈的数组,用top标记栈头,每次KMP匹配的位置也就变成了
s t a c k [ t o p ] stack[top] stack[top]
而每次找到一个B串时,top也就需要跟着减少,此时j需要更新新的值,而从头开始重新匹配肯定是不现实的,那么我们可以再用一个数组存储A与B串匹配时j的值,调用也很简单,每次j的值更新为top所在位置的j值即可
代码实现
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+99;
char a[N],b[N],astack[N];
long long int na,nb,p[N],p2[N],top=0;
void pre(){int j=0;p[1]=0;for(int i=1;i<nb;i++){while(j>0&&b[i+1]!=b[j+1])j=p[j];if(b[i+1]==b[j+1])j++;p[i+1]=j;}
}
void kmp(){int j=0;for(int i=0;i<na;i++){astack[top+1]=a[i+1];top++;while(j>0&&astack[top]!=b[j+1])j=p[j];if(astack[top]==b[j+1])j++;p2[top]=j;if(j==nb){for(int k=1;k<=nb;k++){astack[top]='F';top--;}j=p2[top];}
int main(){scanf("%s%s",a+1,b+1);na=strlen(a+1);nb=strlen(b+1);pre();kmp();for(int i=1;i<=top+1;i++){if(astack[i]!='F')cout<<astack[i];}return 0;
}
附封面