文章目录
- 一、图的概念
- 1.图概念
- 2.顶点与边的概念
- 3.有向图和无向图
- 4.完全图
- 5.邻接顶点
- 6.顶点的度
- 7.路径与路径长度
- 8.简单路径与回路
- 9.子图
- 10.连通图与强连通图
- 11.生成树
- 二、图的存储结构
- 1.邻接矩阵
- 1.1 基本概念
- 1.2 代码实现
- 2.邻接表
- 1.1 基本概念
- 1.2 代码实现
- 3.总结
一、图的概念
1.图概念
图(Graph)是由顶点(Vertex)集合及顶点间的关系(边,即edge)组成的一种数据结构:G = (V, E)
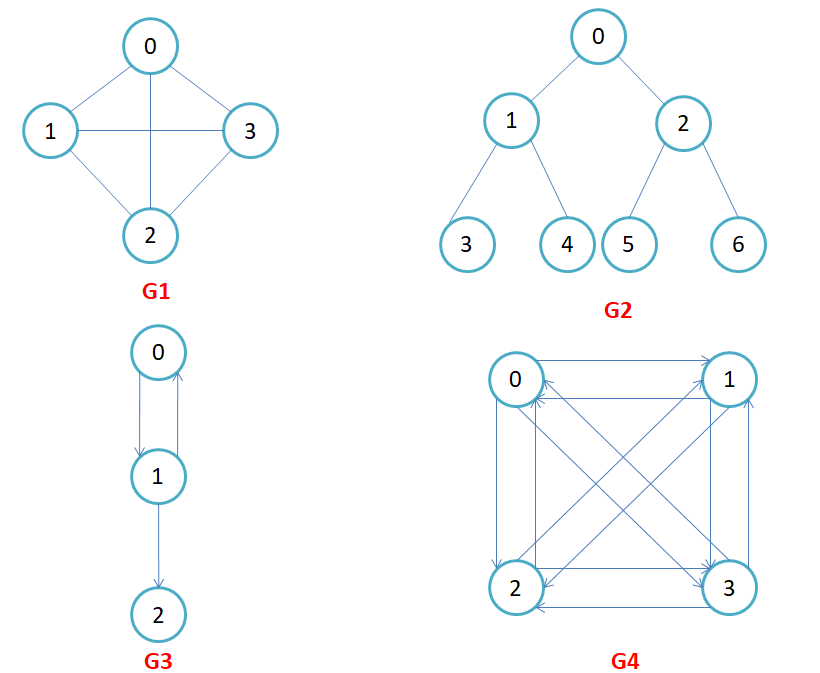
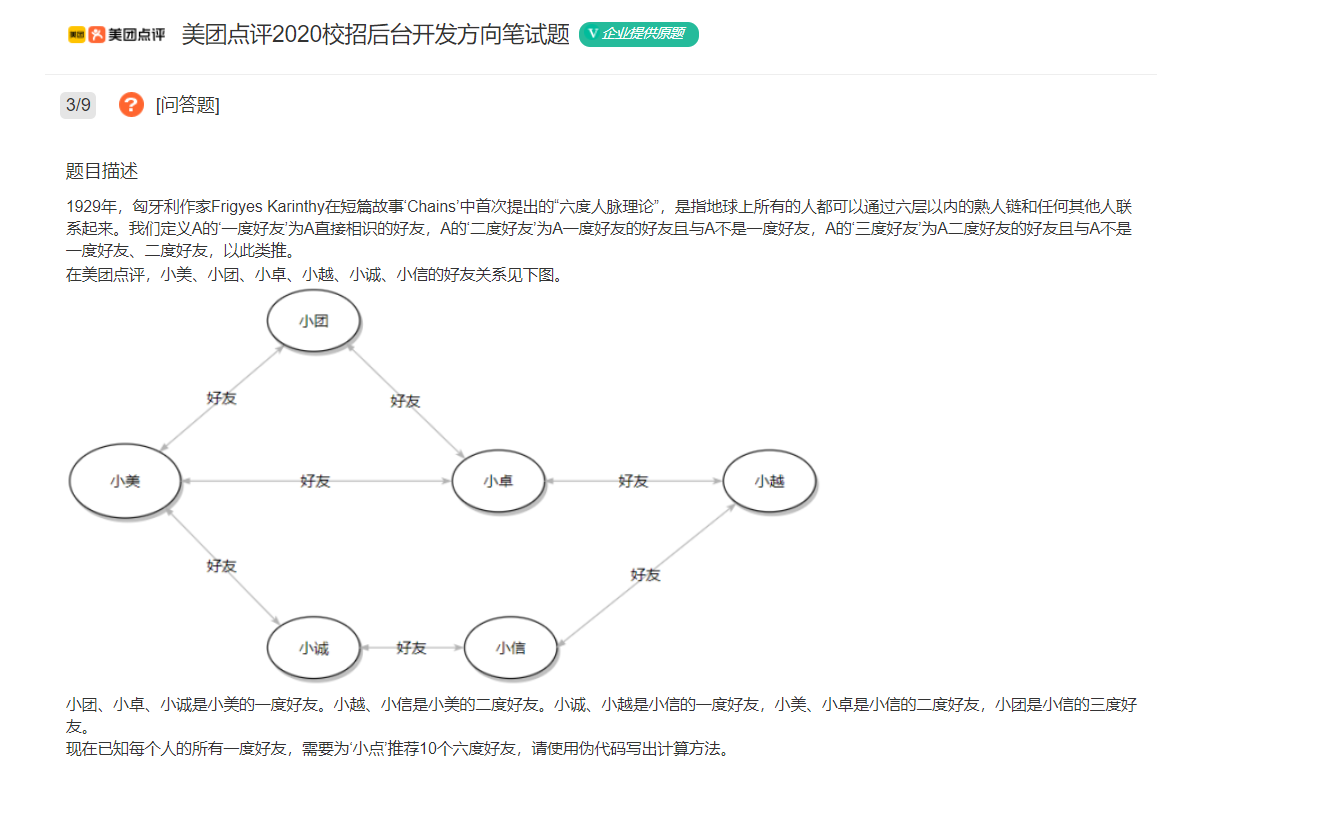
如下图所示,是一些常见的图。
其中:我们可以注意到,G2虽然是一颗二叉树,但他也是一个图
其实:树是一种特殊(无环连通的图),图不一定是树
树关注的是节点(顶点)中存的值,图关注的是顶点及边的权值
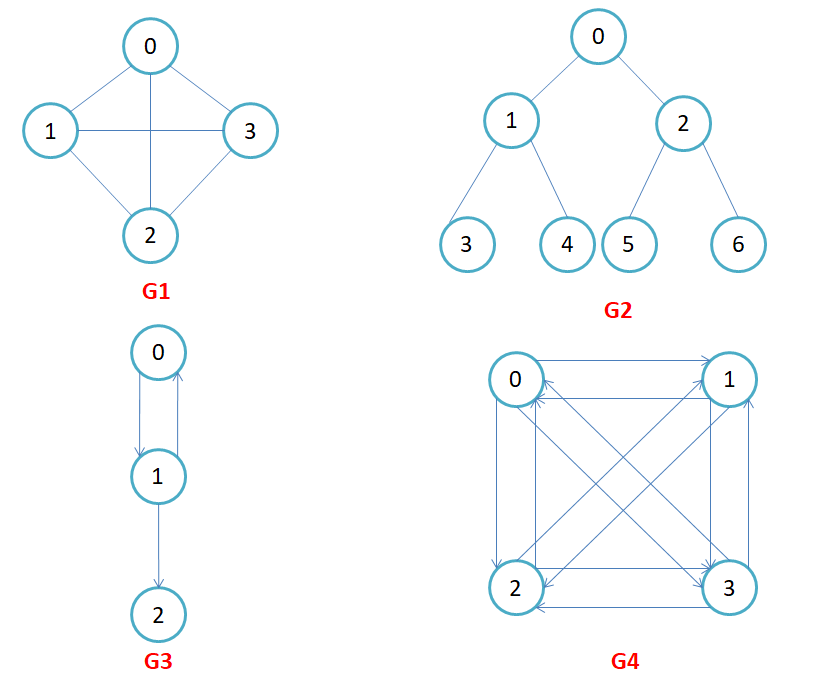
比如下面的交通网络图中
又比如在社交关系图
顶点就代表着人
边表示两个人是好友,边权值表示亲密度等
像微信、qq等,它是一种无向图,因为需要俩个人都相互添加好友。这是一种强社交关系
像微博、抖音等,它是一种有向图,因为可以单向的关注,是一种弱社交关系。

2.顶点与边的概念
顶点集合V = {x|x属于某个数据对象集}是有穷非空集合;
E = {(x,y)|x,y属于V}或者E = {<x, y>|x,y属于V && Path(x, y)}是顶点间关系的有穷集合,也叫做边的集合。
(x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path(x, y)表示从x到y的一条单向通路,即Path(x, y)是有方向的。
顶点和边:图中结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间
有一条边,图中的第k条边记作ek,ek = (vi,vj)或<vi,vj>。
3.有向图和无向图
在有向图中,顶点对<x, y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边(弧),<x, y>和<y, x>是两条不同的边,比如下图G3和G4为有向图。
在无向图中,顶点对(x, y)是无序的,顶点对(x,y)称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,比如下图G1和G2为无向图。注意:无向边(x, y)等于有向边<x, y>和<y, x>。
4.完全图
- 在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图,比如上图G1。
- 在有n个顶点的有向图中,若有n*(n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图,比如上图G4。
完全图也就是最稠密的图
5.邻接顶点
在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u和v;
在有向图G中,若<u, v>是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边<u, v>与顶点u和顶点v相关联。
6.顶点的度
- 顶点v的度是指与它相关联的边的条数,记作dev(v)。
- 在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。
- 对于无向图,顶点的度等于该顶点的入度和出度,即dev(v) = indev(v) = outdev(v)。
7.路径与路径长度
路径:
- 在图G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径。
路径长度:
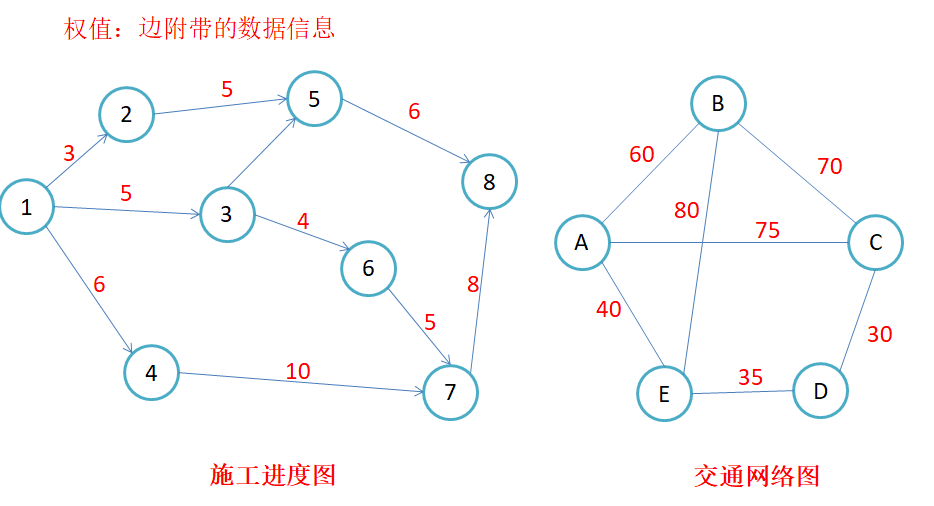
- 路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和
8.简单路径与回路
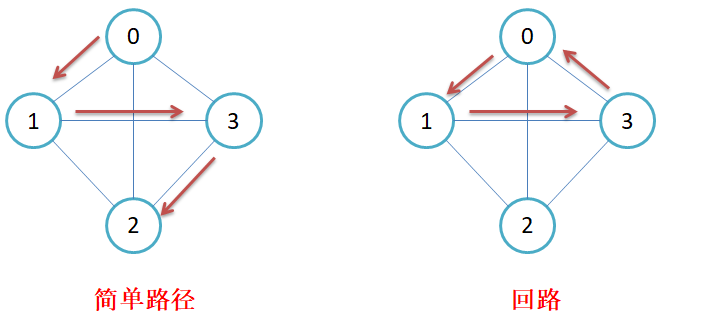
简单路径与回路:若路径上各顶点v1,v2,v3,…,vm均不重复,则称这样的路径为简单路径。
若路径上第一个顶点v1和最后一个顶点vm重合,则称这样的路径为回路或环。
9.子图
- 子图:设图G = {V, E}和图G1 = {V1,E1},若V1属于V且E1属于E,则称G1是G的子图
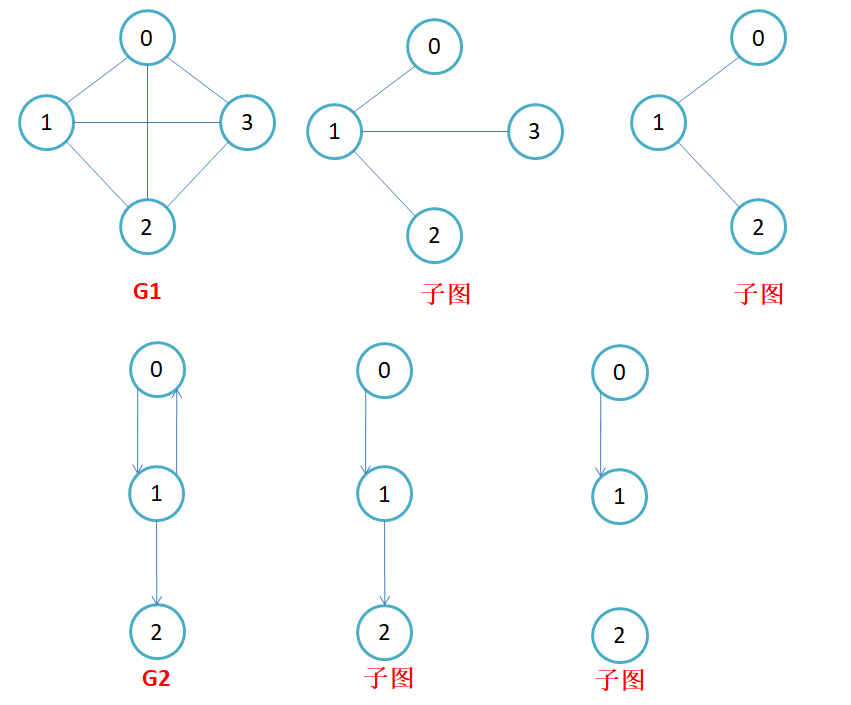
10.连通图与强连通图
连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。
强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到vi的路径,则称此图是强连通图
连通图强调的是从一个顶点可以到达图中的任何其他顶点,而并不要求所有的顶点都互相直接连接。而完全图则是一个更强的条件,它要求图中任意两个顶点之间都存在直接的边。所有的完全图一定是连通图,但并非所有的连通图都是完全图。
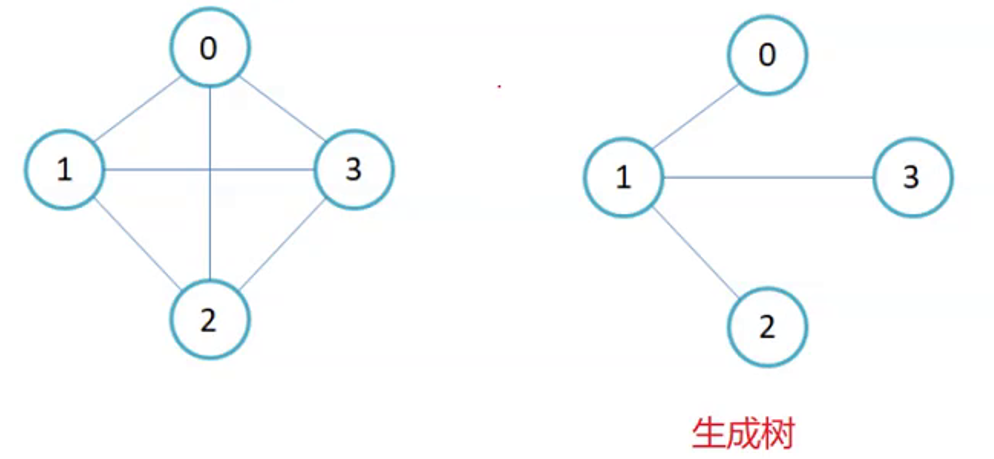
11.生成树
- 生成树:一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边
- 注意:生成树是无向图的概念,有向图没有生成树
二、图的存储结构
因为图中既有节点,又有边(节点与节点之间的关系),因此,在图的存储中,只需要保存:节点和边关系即可。节点保存比较简单,只需要一段连续空间即可,那边关系该怎么保存呢?
1.邻接矩阵
1.1 基本概念
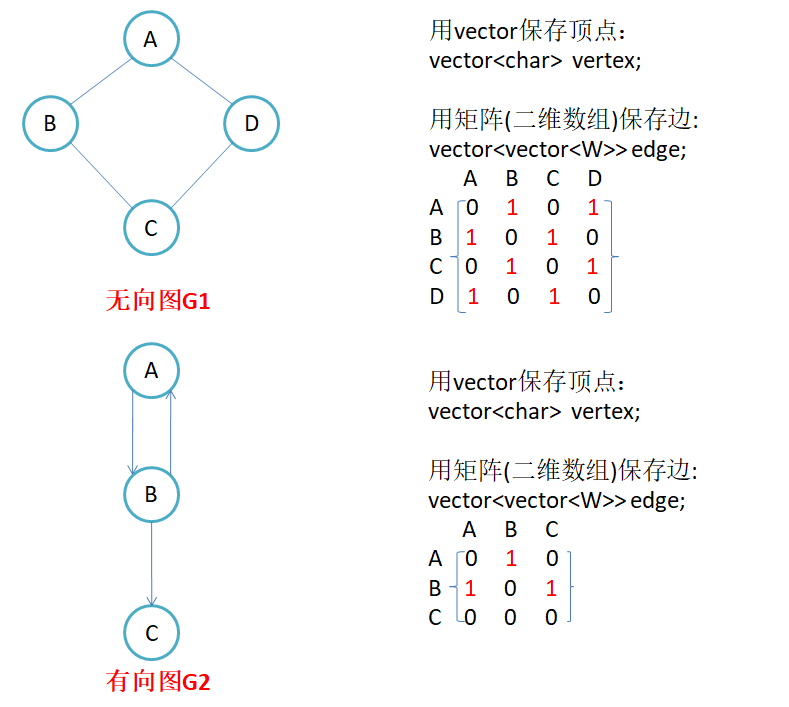
因为节点与节点之间的关系就是连通与否,即为0或者1,因此邻接矩阵(二维数组)即是:先用一个数组将定点保存,然后采用矩阵来表示节点与节点之间的关系。
不过如果要使用这个邻接矩阵,我们需要的一个步骤是通过顶点也能随时找到对应的下标, 最好是O(1),所以我们还需要一个map结构
//V代表顶点, W是weight代表权值,Direction代表是有向图还是无向图 template<class V, class W, bool Direction> class Graph { public: private:vector<V> _vertexs; //顶点集合map<V, int> _indexMap; //顶点对应的下标关系vector<vector<W>> _edge; //存储边的权值 };这样的话,两个顶点是否相连,相连权值是多少?我们都可以得知了。
但是如果用下面的结构去存储边,那么就无法得知两个顶点是否相连,相连权值是多少了!
vector<pair<V, V>> edges我们可以从上面的图中得知
- 临界矩阵存储方式非常适合稠密图(边很多的图,因为无论有多少边,始终占据那么多的内存)
- 临界矩阵O(1)判断两个顶点的连接关系,并取到权值
- 相对而言,不适合查找一个顶点连接的所有边(效率是O(1))
注意
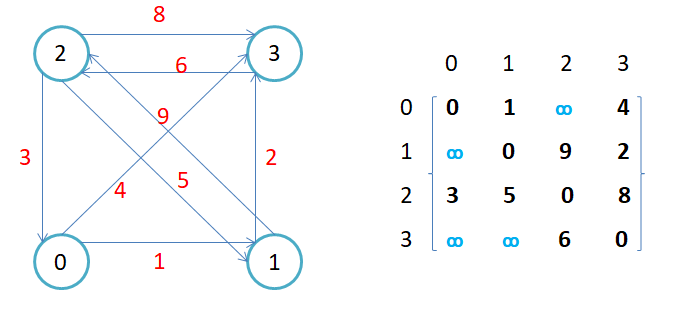
无向图的邻接矩阵是对称的,第i行(列)元素之和,就是顶点i的度。有向图的邻接矩阵则不一定是对称的,第i行(列)元素之后就是顶点i 的出(入)度。
如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通,则使用无穷大代替
- 用邻接矩阵存储图的有点是能够快速知道两个顶点是否连通,缺陷是如果顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求
1.2 代码实现
如下所示是邻接矩阵的实现代码
namespace matrix
{//V代表顶点, W是weight代表权值,MAX_W代表权值的最大值,Direction代表是有向图还是无向图,flase表示无向template<class V, class W, W Max_W = INT_MAX, bool Direction = false>class Graph{public://图的创建//1. IO输入 不方便测试//2. 图结构关系写到文件,读取文件//3. 手动添加边Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; i++){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_matrix.resize(n);for (size_t i = 0; i < _matrix.size(); i++){_matrix[i].resize(n, Max_W);}}size_t GetVertexIndex(const V& v){//return _indexMap[v];auto it = _indexMap.find(v);if (it != _indexMap.end()){return it->second;}else{//assert(false)throw invalid_argument("顶点不存在");return -1;}}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);_matrix[srci][dsti] = w;if (Direction == false){_matrix[dsti][srci] = w;}}void Print(){for (size_t i = 0; i < _vertexs.size(); i++){cout << "[" << i << "]" << "->" << _vertexs[i] << endl;}cout << endl;cout << " ";for (int i = 0; i < _vertexs.size(); i++){cout << _vertexs[i] << " ";}cout << endl;for (size_t i = 0; i < _matrix.size(); i++){cout << _vertexs[i] << " ";for (size_t j = 0; j < _matrix[i].size(); j++){if (_matrix[i][j] == INT_MAX){cout << "*" << " ";}else{cout << _matrix[i][j] << " ";}}cout << endl;}}private:vector<V> _vertexs; //顶点集合map<V, int> _indexMap; //顶点对应的下标关系vector<vector<W>> _matrix; //邻接矩阵};void TestGraph(){Graph<char, int, INT_MAX, true> g("0123", 4);g.AddEdge('0', '1', 1);g.AddEdge('0', '3', 4);g.AddEdge('1', '3', 2);g.AddEdge('1', '2', 9);g.AddEdge('2', '3', 8);g.AddEdge('2', '1', 5);g.AddEdge('2', '0', 3);g.AddEdge('3', '2', 6);g.Print();}
}
- 在上面的代码中,我们使用了四个模板参数,其中,前两个模板参数分别代表顶点的类型和权值的类型。第三个模板参数表示着权值的最大值,第四个模板参数表示该图是有向图还是无向图。我们默认为无向图
- 我们的结构中,有三个成员,首先是顶点的集合。因为我们需要知道有哪些顶点,我们可以用一个vector来进行组织,而且由于数组天然有下标,所以我们相当于对每个顶点进行了编号;其次是一个map,这个map的作用就是反映射,因为我们需要通过一个顶点快速的得知它的下标,所以我们最好以空间换时间,使用map进行映射;最后是一个邻接矩阵,根据前面的理论,图的每两个顶点之间的关系可以用邻接矩阵来描述出来。邻接数组的两个下标就代表着这两个顶点,内容代表他们的权值
- 关于图的构造函数,其实就是要创建一个图,而创建一个图,我们所需要得知的就是有哪些顶点,一共有多少个顶点,我们可以选择直接用一个vector<V>,不过我们也可以用一个const V* 和一个n一样,用c语言的方式去获得顶点的数据。得知了有哪些顶点,那么我们就可以将顶点放入我们成员变量的vector和map中了。建立好映射以后,我们现在要处理这个邻接矩阵了,这个邻接矩阵,我们可以利用第三个模板参数,将内部的所有数据全部变为权值的最大值。上面就是处理好了我们的图了,此时的图是一个个的孤立的结点,没有任何一条边的图
- 有时候,我们为了方便的获取到每个边映射出来的下标,我们可以专门写一个函数去获取。在函数内部的实现细节中,我们可以直接使用map的[]运算符,也可以自己去先判断一下顶点是否存在,如果存在,则返回,如果不存在则抛出异常
- 我们目前的图,只是一个个孤立的结点,为了将每个结点连接起来,我们需要写一个函数可以去将两个结点给连接起来。而连接的本质其实就是为邻接矩阵添加边。我们可以先获取到对应结点的下标,然后为srci到dsti先来填好一个数据,如果是无向图,那么还需要在对称位置填写数据,如果是有向图,那么已经结束了。
- 最后我们可以写一个print函数来打印这个图的顶点以及它的映射的下标,还有它的邻接矩阵,如上代码所示
上面代码的最终运行结果为

2.邻接表
1.1 基本概念
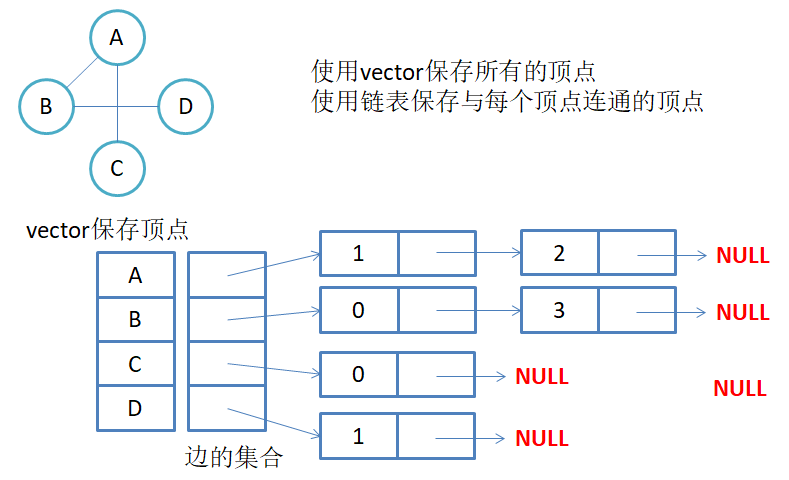
邻接表:使用数组表示顶点的集合,使用链表表示边的关系。
- 无向图邻接表存储
注意:无向图中同一条边在邻接表中出现了两次。如果想知道顶点vi的度,只需要知道顶点vi边链表集合中结点的数目即可
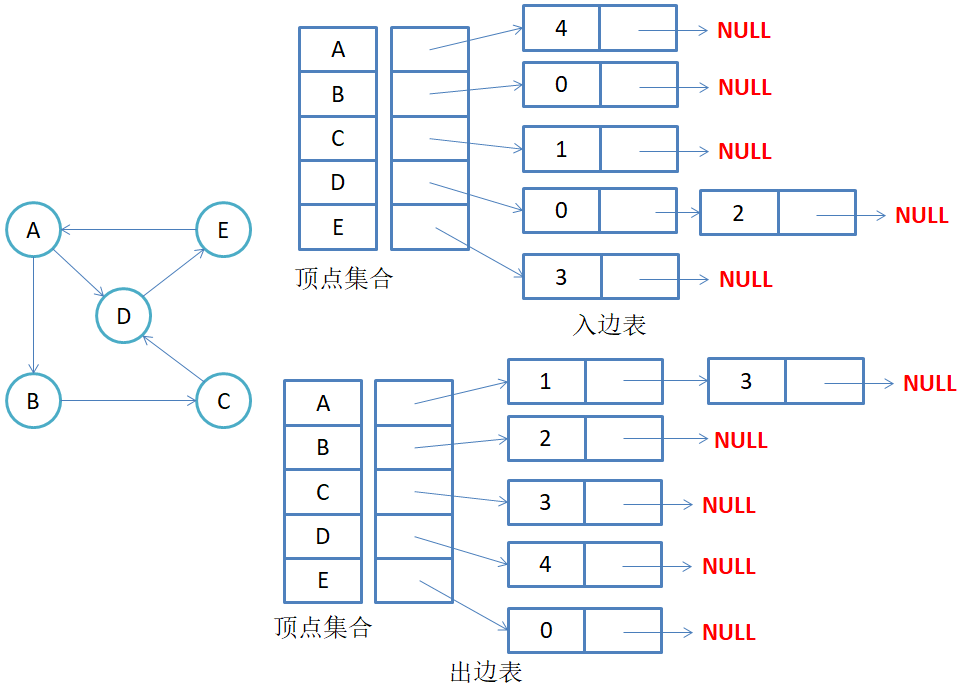
- **有向图邻接表存储 **
注意:有向图中每条边在邻接表中只出现一次,与顶点vi对应的邻接表所含结点的个数,就是该顶点的出度,也称出度表,要得到vi顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的dst取值是i。当然我们也可以在实现一个入度表,这样可以很方便的得知入度
一般来说只需要出边表即可
我们可以得知:
- 邻接表适合存储稀疏图
- 适合查找一个顶点连接出去的边
- 不适合确定两个顶点是否相连及权值
1.2 代码实现
namespace link_table
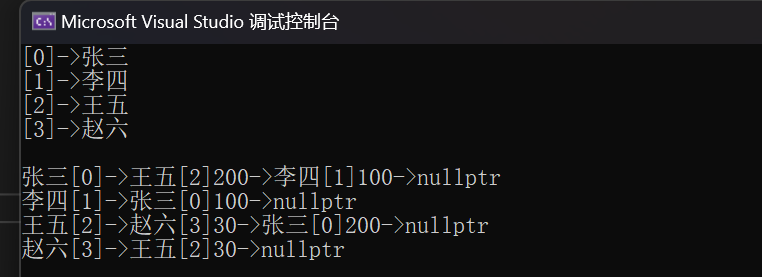
{template<class W>struct Edge{//int _srci; //来源点的下标int _dsti; //目标点的下标W _w; //权值Edge<W>* _next; //指向下一个结点Edge(int dsti, const W& w):_dsti(dsti),_w(w),_next(nullptr){}};//V代表顶点, W是weight代表权值,Direction代表是有向图还是无向图,flase表示无向template<class V, class W, bool Direction = false>class Graph{typedef Edge<W> Edge;public:Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; i++){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_tables.resize(n, nullptr);}size_t GetVertexIndex(const V& v){//return _indexMap[v];auto it = _indexMap.find(v);if (it != _indexMap.end()){return it->second;}else{//assert(false)throw invalid_argument("顶点不存在");return -1;}}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = GetVertexIndex(src);size_t dsti = GetVertexIndex(dst);Edge* eg = new Edge(dsti, w);eg->_next = _tables[srci];_tables[srci] = eg;if (Direction == false){Edge* eg = new Edge(srci, w);eg->_next = _tables[dsti];_tables[dsti] = eg;}}void Print(){for (size_t i = 0; i < _vertexs.size(); i++){cout << "[" << i << "]" << "->" << _vertexs[i] << endl;}cout << endl;for (int i = 0; i < _tables.size(); i++){cout << _vertexs[i] << "[" << i << "]" << "->";Edge* cur = _tables[i];while (cur){cout << _vertexs[cur->_dsti] << "[" << cur->_dsti << "]" << cur->_w << "->";cur = cur->_next;}cout << "nullptr" << endl;}}private:vector<V> _vertexs; //顶点集合map<V, int> _indexMap; //顶点对应的下标关系vector<Edge*> _tables; //邻接表};void TestGraph(){string a[] = { "张三", "李四", "王五", "赵六" };Graph<string, int, true> g1(a, 4);g1.AddEdge("张三", "李四", 100);g1.AddEdge("张三", "王五", 200);g1.AddEdge("王五", "赵六", 30);g1.Print();}
}
- 在上面代码中,我们为了用邻接表的结构,我们需要先创建一个邻接表的结点的类型,这里我们只实现出边表,那么我们的结点里面一定要包括的是目的地的下标,权值,以及指向下一个结点的指针。这里不需要来源的下标是因为,我们是出边表,只需要记录出到了哪里即可。在我们的成员变量有一个邻接表数组,里面其实已经包括了源头的信息。用目的地创建好边了以后,目的地下标正好就可以找到目的地名字信息了,天然的可以通过我们一开始的映射去找到。
- 关于图的创建,与前面邻接矩阵不同的是,需要为邻接表数组开辟空间。前面的都是一样的,此时形成的就是一个个孤立结点的图
- 关于图的添加边,这里需要做的就是先获取到,源头和目的地的下标,然后我们用目的地的下标可以创建一个结点,然后挂接到源头的结点即可。如果是无向图,就需要多挂接一次。
- 对于打印函数,我们需要先打印出每个源头结点的下标以及它的内容,然后我们去一次遍历每一个链表,去打印它里面的信息。
运行结果如下
3.总结
邻接矩阵和邻接表其实属于相辅相成,各有优缺点的互补结构