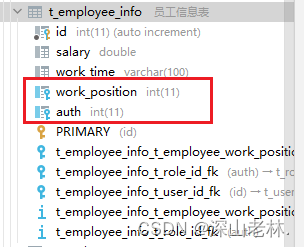
AI = RL + DL

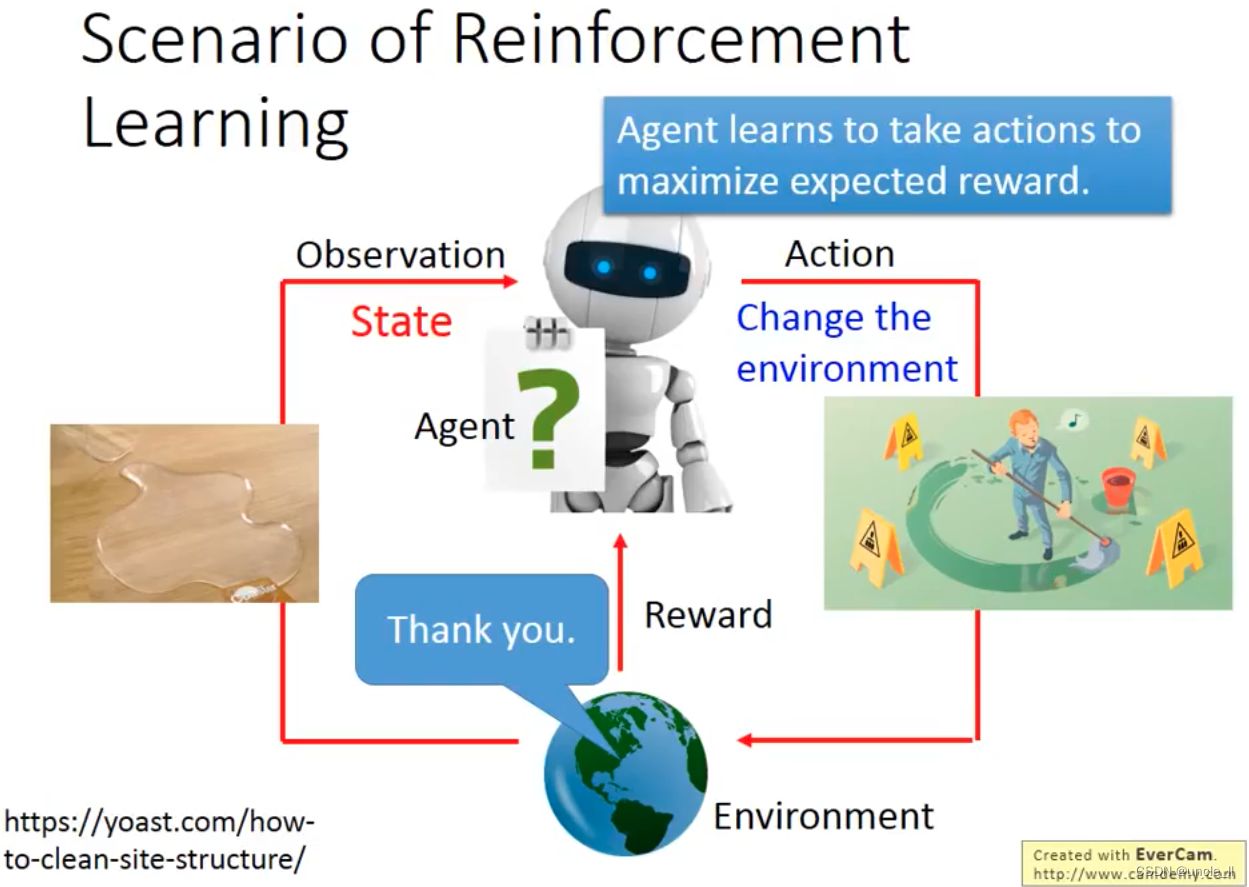
基于Action,Enviroment给予Reward

enviroment是对手

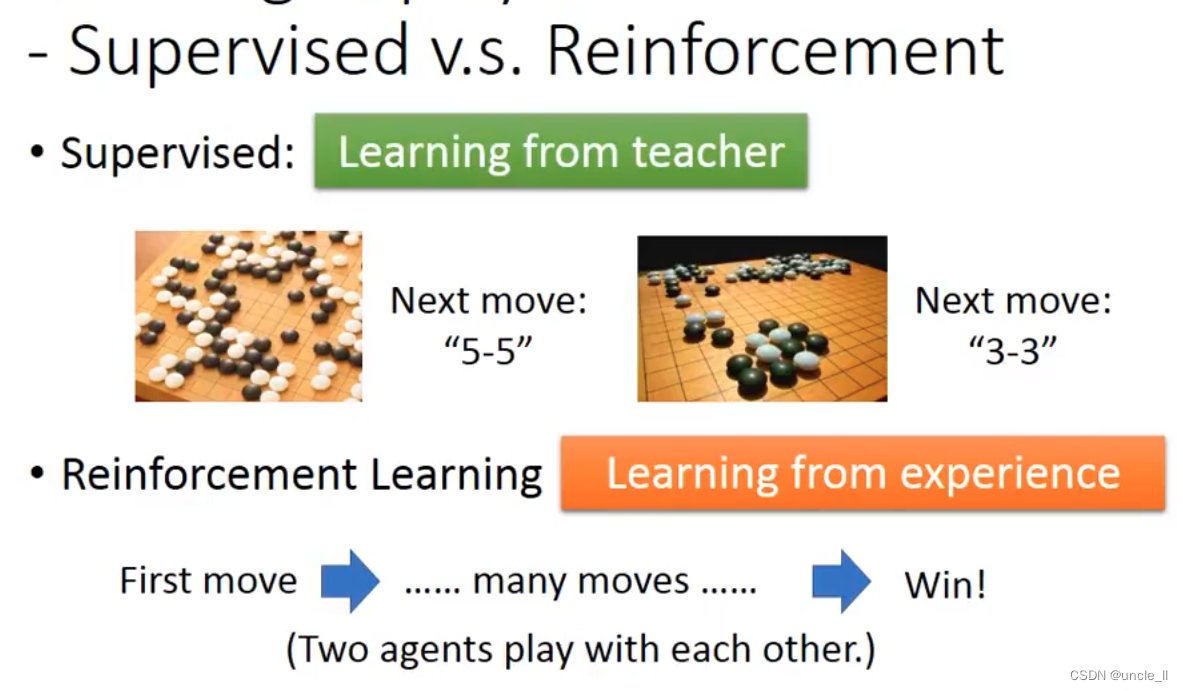
alpha go is supervised learning + reinforcement learning

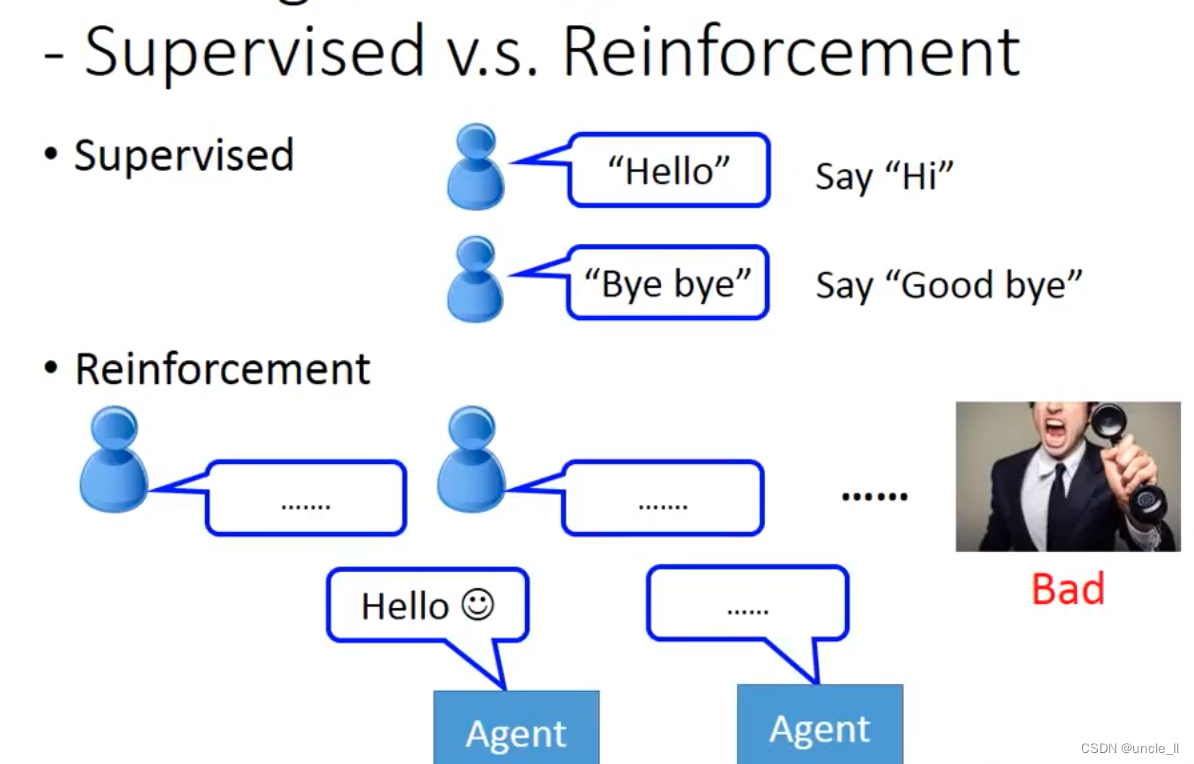
学两个agent,让两个互相沟通。


使用一些预定义的规则来判断对话的好坏。


更多应用

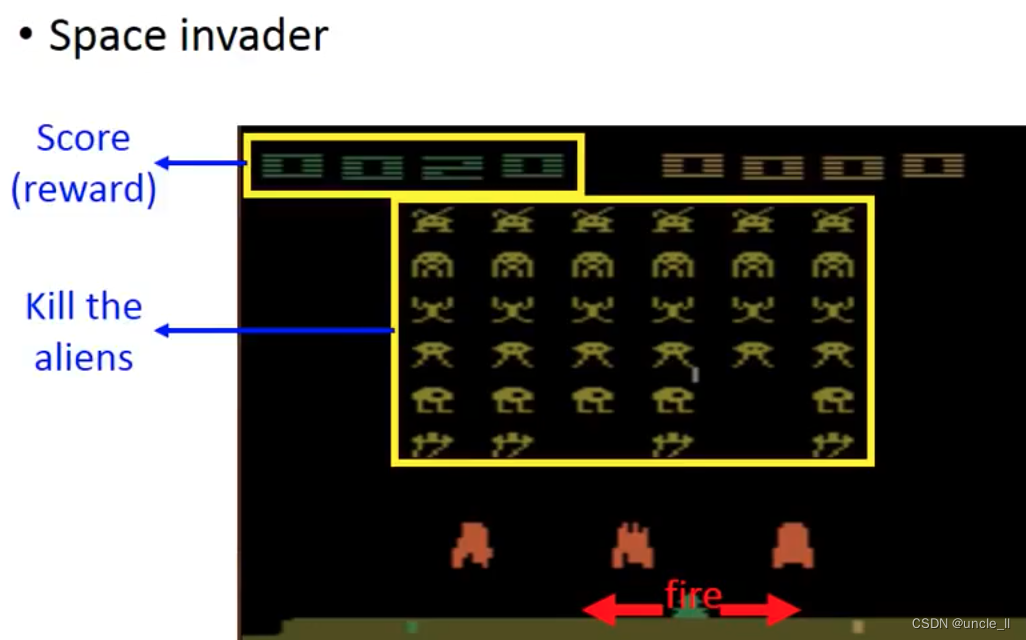
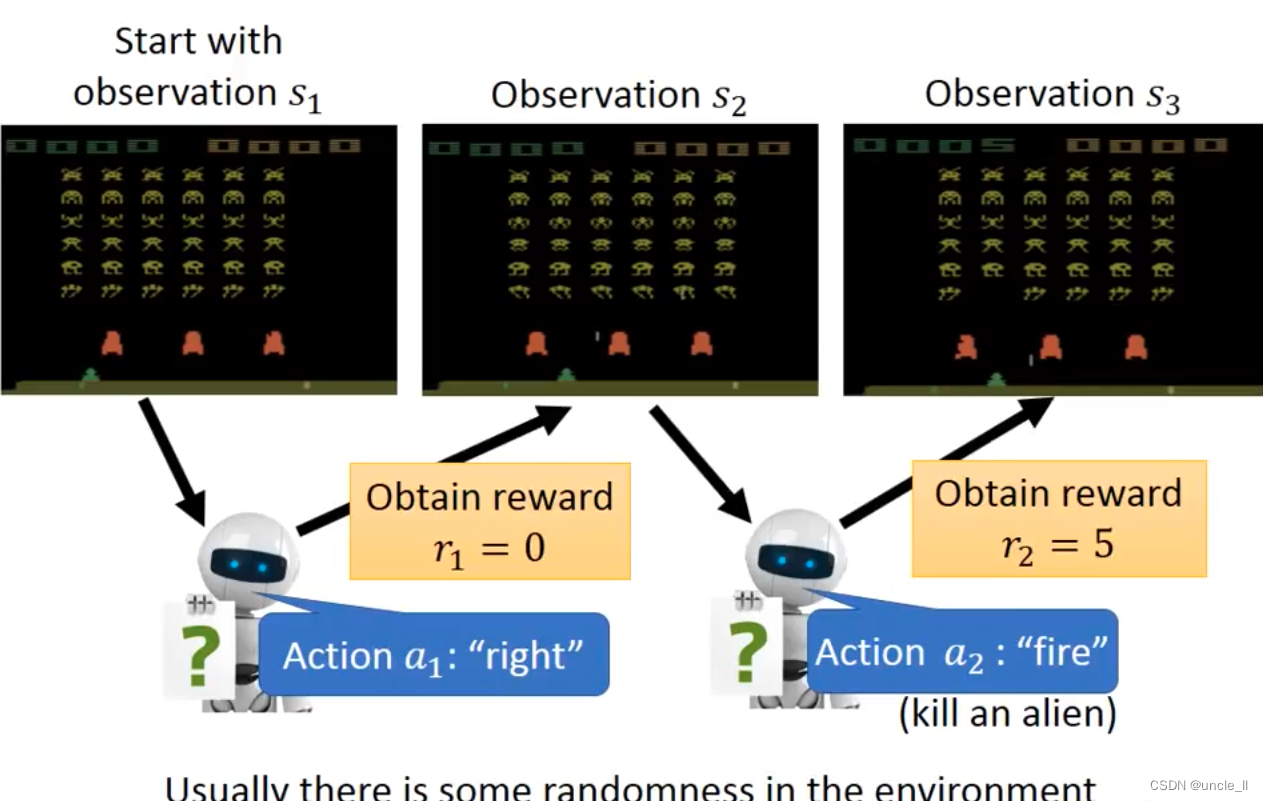
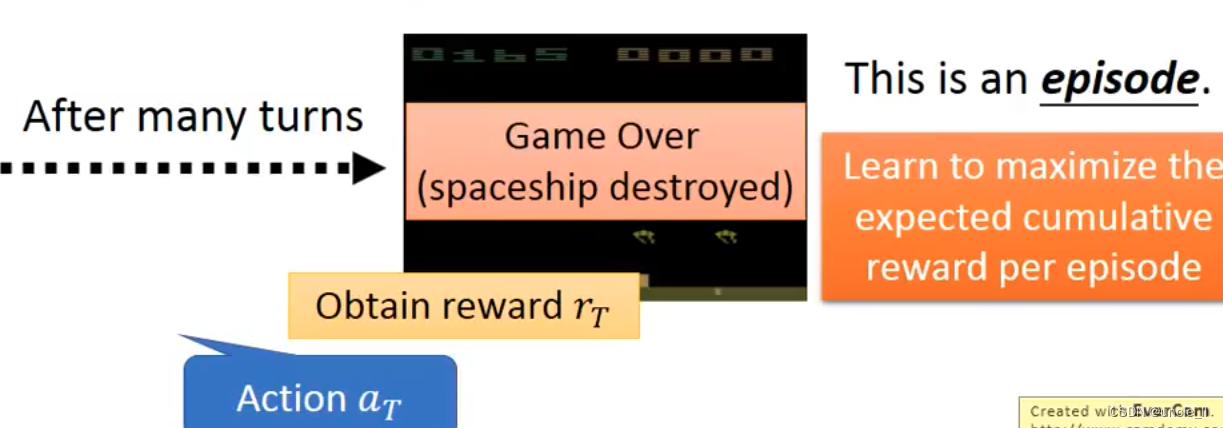

强化学习的困难就是奖励延迟,需要各种探索

alpha go:policy-based + value-based + model-based

更多学习资料
Policy-based 方法
Learning an Actor



使用神经网络代替查找表的优势是:generative 泛化能力

actor实际的去玩,来表现这个actor的好坏

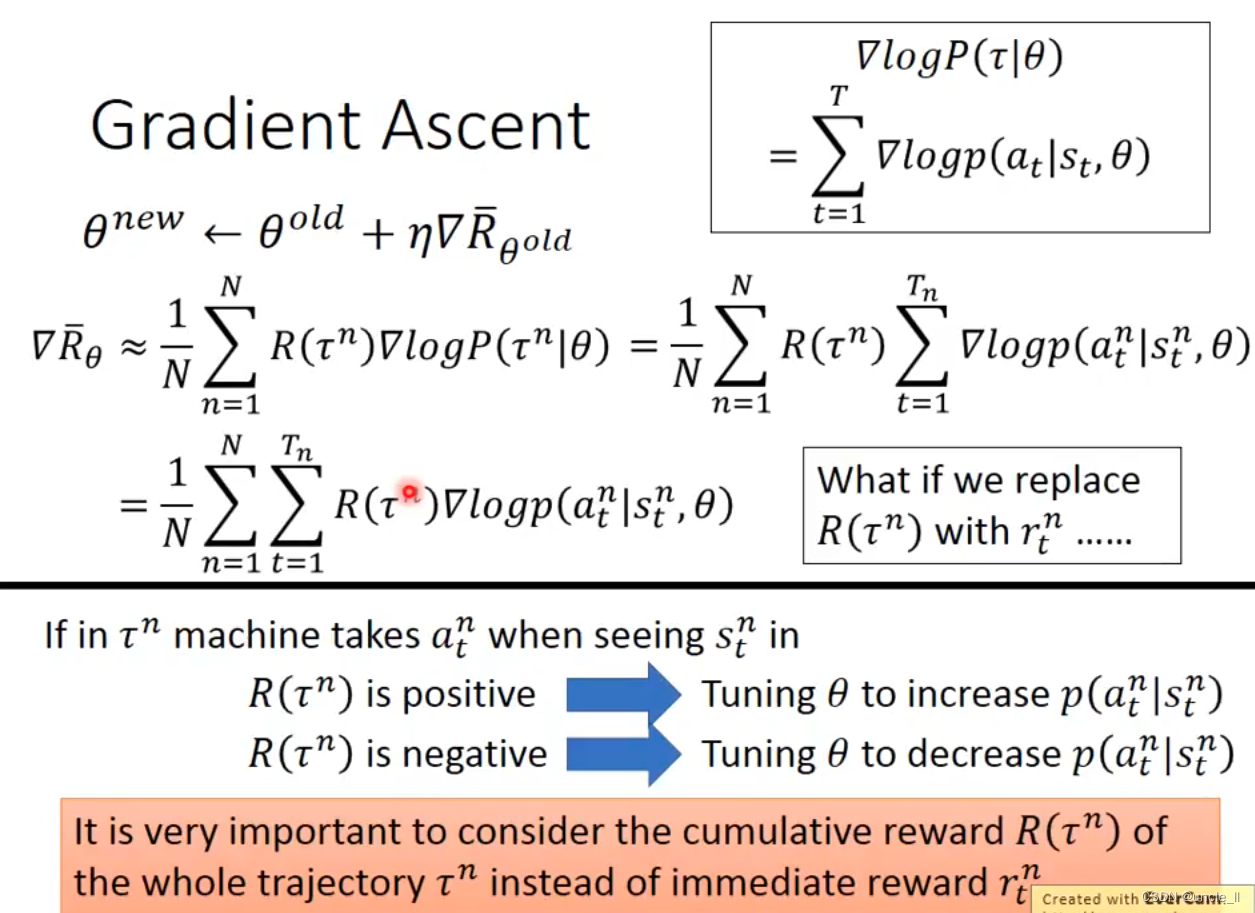
好的期望值如何计算呢?