文章目录
- 基本概念
- 什么是token?
- 如何理解token的长度?
- 使用openai tokenizer 观察token的相关信息
- open ai的模型
- token的特点
- token如何映射到数值?
- token级操作:精确地操作文本
- token 设计的局限性
- tokenization
- token 数量对LLM 的影响
- 训练模型参数量与训练数据量统计
- 影响模型效果的因素有哪些?
- 参考
基本概念
什么是token?
- 在 LLM 中,token代表模型可以理解和生成的最小意义单位,是 LLM 进行处理的最小单元。
- 根据所使用的特定标记化【Tokenization】方案,token可以表示单词、单词的一部分,甚至只表示字符。采用的方案由模型的类型和大小决定
- token被赋予数值或标识符,并按序列或向量排列,并被输入或从模型中输出,是模型的语言构件。
- 模型理解这些token之间的统计关系,并擅长做token的接龙
- token化是将输入和输出文本分割成可以由LLM AI模型处理的较小单元的过程
- token作为原始文本数据和 LLM 可以使用的数字表示之间的桥梁。LLM使用token来确保文本的连贯性和一致性,有效地处理各种任务,如写作、翻译和回答查询。
如何理解token的长度?
下面是一些有用的经验法则,可以帮助理解token的长度:
- 1 token ~= 4 chars in English
- 1 token ~= ¾ words
- 100 tokens ~= 75 words
- 1-2 句子 ~= 30 tokens
- 1 段落 ~= 100 tokens
- 1,500 单词 ~= 2048 tokens
- 一个unicode字符可以拆分为多个token
使用openai tokenizer 观察token的相关信息
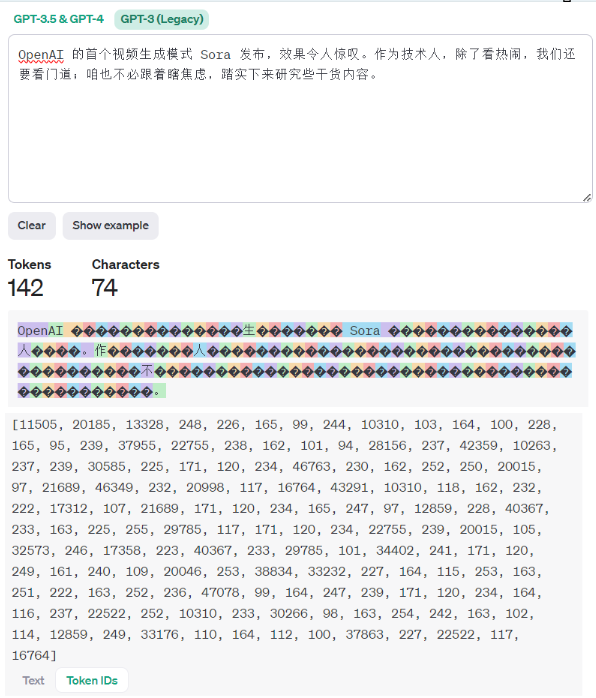
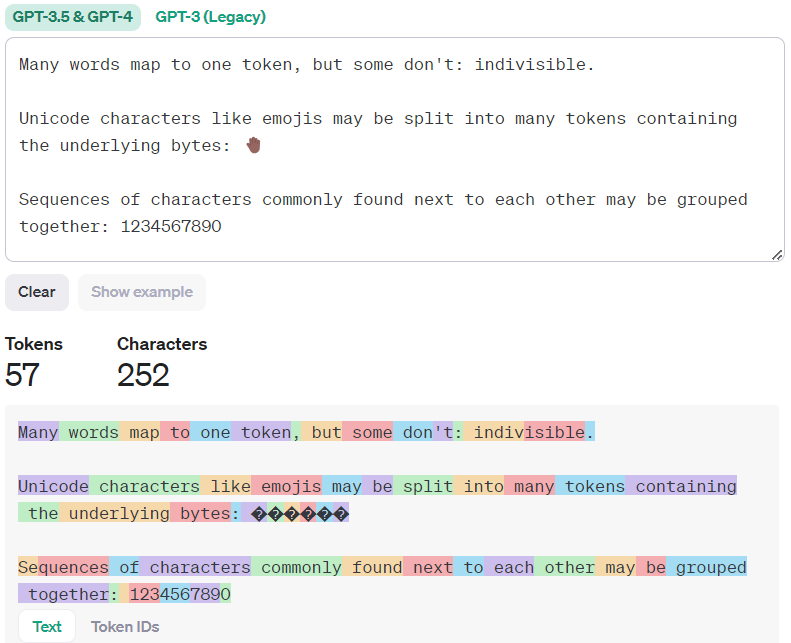
可以通过https://platform.openai.com/tokenizer 来观察token 的相关信息。
可以看到,GPT-3.5&GPT-4 与 GPT-3(Legacy) 模型tokenizer方案是不同的,前者产生的token数据量变少,针对中文的处理更加合理。

open ai的模型
OpenAI API由一组不同的模型提供支持,这些模型具有不同的功能和价位
GPT-4是一个大型多模态模型(接受文本或图像输入和输出文本),由于其更广泛的一般知识和先进的推理能力,它可以比我们以前的任何模型都更准确地解决难题。
| MODEL | DESCRIPTION |
|---|---|
| GPT-4 and GPT-4 Turbo | A set of models that improve on GPT-3.5 and can understand as well as generate natural language or code |
| GPT-3.5 Turbo | A set of models that improve on GPT-3.5 and can understand as well as generate natural language or code |
| DALL·E | A model that can generate and edit images given a natural language prompt |
| TTS | A set of models that can convert text into natural sounding spoken audio |
| Whisper | A model that can convert audio into text |
| Embeddings | A set of models that can convert text into a numerical form |
| Moderation | A fine-tuned model that can detect whether text may be sensitive or unsafe |
| GPT base | A set of models without instruction following that can understand as well as generate natural language or code |
| Deprecated | A full list of models that have been deprecated along with the suggested replacement |
token的特点
token如何映射到数值?
词汇表将token映射到唯一的数值表示。LLM 使用数字输入,因此词汇表中的每个标记都被赋予一个唯一标识符或索引。这种映射允许 LLM 将文本数据作为数字序列进行处理和操作,从而实现高效的计算和建模。
为了捕获token之间的意义和语义关系,LLM 采用token编码技术。这些技术将token转换成称为嵌入的密集数字表示。嵌入式编码语义和上下文信息,使 LLM 能够理解和生成连贯的和上下文相关的文本。像transformer这样的体系结构使用self-attention机制来学习token之间的依赖关系并生成高质量的嵌入。
token级操作:精确地操作文本
token级别的操作是对文本数据启用细粒度操作。LLM 可以生成token、替换token或掩码token,以有意义的方式修改文本。这些token级操作在各种自然语言处理任务中都有应用,例如机器翻译、情感分析和文本摘要等。
token 设计的局限性
在将文本发送到 LLM 进行生成之前,会对其进行tokenization。token是模型查看输入的方式ーー单个字符、单词、单词的一部分或文本或代码的其他部分。每个模型都以不同的方式执行这一步骤,例如,GPT 模型使用字节对编码(BPE)
token会在tokenizer发生器的词汇表中分配一个 id,这是一个将数字与相应的字符串绑定在一起的数字标识符。例如,“ Matt”在 GPT 中被编码为token编号[13448],而 “Rickard”被编码为两个标记,“ Rick”,“ ard”带有 id[8759,446],GPT-3拥有1400万字符串组成的词汇表。
token 的设计大概存在着以下的局限性:
- 大小写区分:不同大小写的单词被视为不同的标记。“ hello”是token[31373] ,“ Hello”是[15496] ,而“ HELLO”有三个token[13909,3069,46]。
- 数字分块不一致。数值“380”在 GPT 中标记为单个“380”token。但是“381”表示为两个token[“38”,“1”]。“382”同样是两个token,但“383”是单个token[“383”]。一些四位数字的token有: [“3000”] ,[“3”,“100”] ,[“35”,“00”] ,[“4”,“500”]。这或许就是为什么基于 GPT 的模型并不总是擅长数学计算的原因。
- 尾随的空格。有些token有空格,这将导致提示词和单词补全的有趣行为。例如,带有尾部空格的“once upon a ”被编码为[“once”、“upon”、“a”、“ ”]。然而,“once on a time”被编码为[“once”,“ upon”,“ a”,“ time”]。因为“ time”是带有空格的单个token,所以将空格添加到提示词将影响“ time”成为下一个token的概率。
tokenization
- 将文本划分为不同token的正式过程称为 tokenization.
tokenization是特定于模型的。根据模型的词汇表和tokenization方案,标记可能具有不同的大小和含义。
BPE 是一种将最频繁出现的字符对或字节合并到单个标记中的方法,直到达到一定数量的标记或词汇表大小为止。BPE 可以帮助模型处理罕见或不可见的单词,并创建更紧凑和一致的文本表示。BPE 还允许模型通过组合现有单词或标记来生成新单词或标记。词汇表越大,模型生成的文本就越多样化并富有表现力。但是,词汇表越大,模型所需的内存和计算资源就越多。因此,词汇表的选择取决于模型的质量和效率之间的权衡。
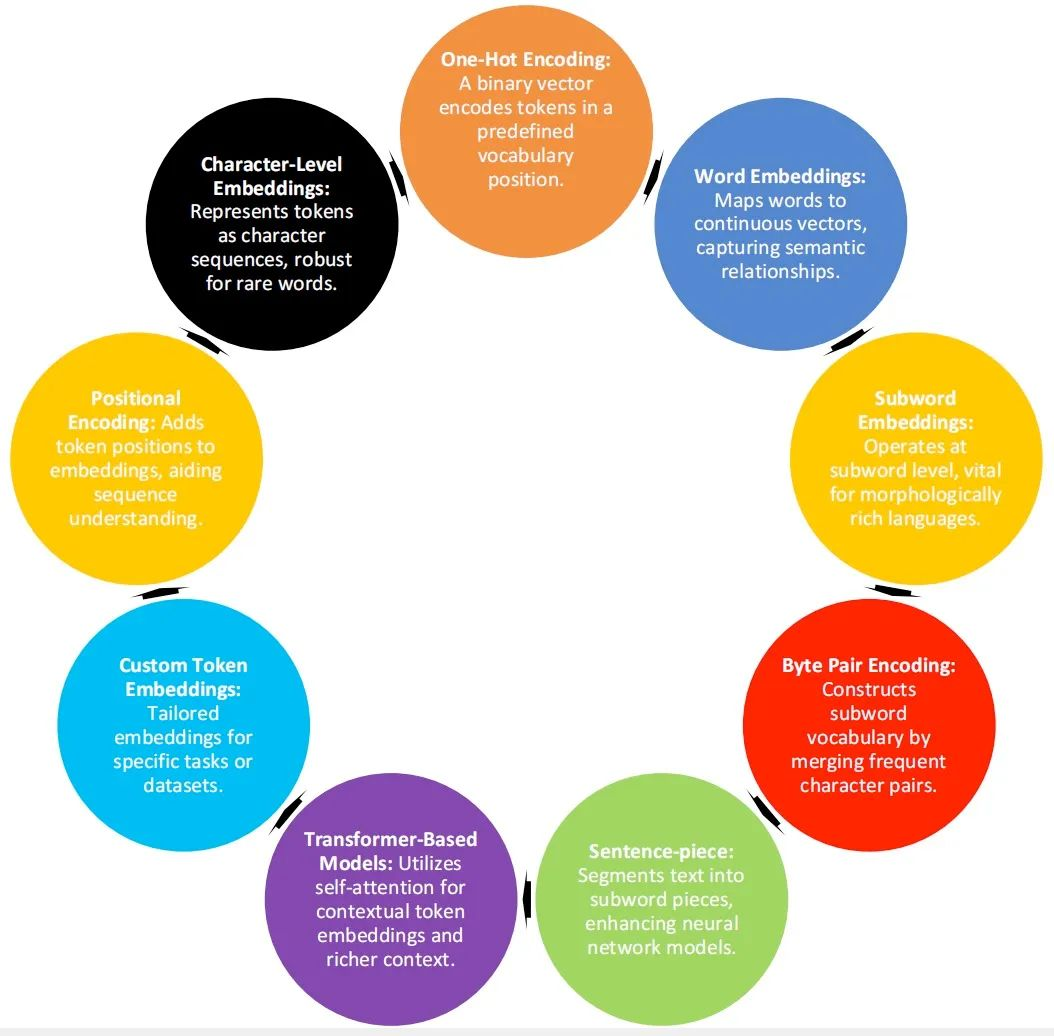
tokenization涉及到将文本分割成有意义的单元,以捕捉其语义和句法结构,可以采用各种tokenization技术,如字级、子字级(例如,使用字节对编码或 WordPiece)或字符级。根据特定语言和特定任务的需求,每种技术都有自己的优势和权衡。
- 字节对编码(BPE):为AI模型构建子词词汇,用于合并出现频繁的字符/子字对。
- 子词级tokenization:为复杂语言和词汇划分单词。将单词拆分成更小的单元,这对于复杂的语言很重要。
- 单词级tokenization:用于语言处理的基本文本tokenization。每个单词都被用作一个不同的token,它很简单,但受到限制。
- 句子片段:用习得的子词片段分割文本,基于所学子单词片段的分段。
- 分词tokenization:采用不同合并方法的子词单元。
- 字节级tokenization:使用字节级token处理文本多样性,将每个字节视为令牌,这对于多语言任务非常重要。
- 混合tokenization:平衡精细细节和可解释性,结合词级和子词级tokenization。
相关的技术参见 下图:
token 数量对LLM 的影响
训练模型参数量与训练数据量统计
2022 年 9 月,DeepMind(Chinchilla 论文)中提出Hoffman scaling laws:表明每个参数需要大约 20 个文本token进行训练。比如一个7B的模型需要140B token,若每个token使用int32(四字节)进行编码的话,就是560GB的数据。
训练模型参数量与训练数据量的统计
| 参数量 | 数据量(tokens) 1T tokens约为 2000-4000 GB 数据(与token的编码字节数相关) |
|---|---|
| llama-7B | 1.0 T |
| -13B | 1.0 T |
| -33B | 1.4 T |
| -65B | 1.4 T |
| Llama2-7B | 2.0 T |
| -13B | 2.0 T |
| -34B | 2.0 T |
| -70B | 2.0 T |
| Bloom-176B | 1.6 T |
| LaMDA-137B | 1.56 T |
| GPT-3-175B | 0.3 T |
| Jurassic-178B | 0.3 T |
| Gopher-280B | 0.3 T |
| MT-NLG 530B | 0.27 T |
| Chinchilla-70B | 1.4 T |
影响模型效果的因素有哪些?
虽然模型可以处理或已经接受过训练的token数量确实影响其性能,但其响应的一般性或详细程度更多地是其训练数据、微调和所使用的解码策略的产物。
解码策略也起着重要的作用。修改模型输出层中使用的SoftMax函数的“temperature”可以使模型的输出更加多样化(更高的温度)或者更加确定(更低的温度)。在OpenAI 的API中设置temperature的值可以调整确定性和不同输出之间的平衡。
上下文窗口: 这是模型一次可以处理的token的最大数量。如果要求模型比上下文窗口生成更多的token,它将在块中这样做,这可能会失去块之间的一致性。
不同的模型支持不同的上下文token窗口,见下表
| MODEL | DESCRIPTION | CONTEXT WINDOW | TRAINING DATA |
|---|---|---|---|
| gpt-4-0125-preview | New GPT-4 Turbo The latest GPT-4 model intended to reduce cases of “laziness” where the model doesn’t complete a task. Returns a maximum of 4,096 output tokens. Learn more. | 128,000 tokens | Up to Dec 2023 |
| gpt-4 | Currently points to gpt-4-0613. See continuous model upgrades. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-32k | Currently points to gpt-4-32k-0613. See continuous model upgrades. This model was never rolled out widely in favor of GPT-4 Turbo. | 32,768 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-1106 | GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Returns a maximum of 4,096 output tokens. Learn more. | 16,385 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-instruct | Similar capabilities as GPT-3 era models. Compatible with legacy Completions endpoint and not Chat Completions. | 4,096 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-16k | Legacy Currently points to gpt-3.5-turbo-16k-0613. | 16,385 tokens | Up to Sep 2021 |
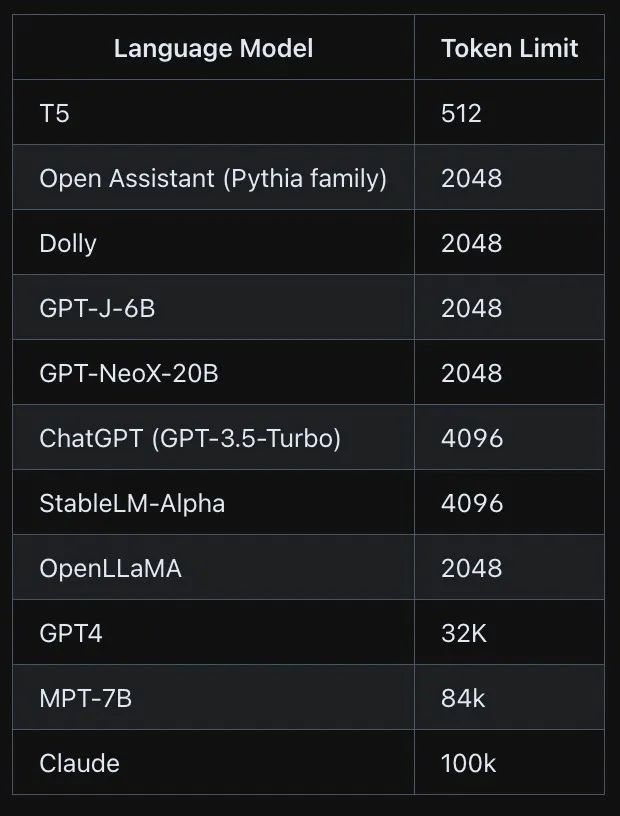
等这样的大模型有一个最大token 数量限制,超过这个限制,它们就不能接受输入或生成输出
一般地, 可以尝试以下方法来解决token长度限制的问题:
- 截断
- 抽样
- 重组
- 编解码
- 微调
参考
LLM 中 Token 的通俗解释
解读大模型(LLM)的token
大模型参数量与训练数据量关系