>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/rbOOmire8OocQ90QM78DRA) 中的学习记录博客** >- **🍖 原作者:[K同学啊 | 接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore")
#win10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")from torchtext.datasets import AG_NEWS
train_iter = AG_NEWS(split='train')#加载 AG News 数据集from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator#返回分词器
tokenizer = get_tokenizer('basic_english')def yield_tokens(data_iter):for _, text in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])#设置默认索引
print(vocab(['here', 'is', 'an', 'example']))text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: int(x) - 1
print(text_pipeline('here is an example '))
print(label_pipeline('10'))from torch.utils.data import DataLoaderdef collate_batch(batch):label_list,text_list,offsets =[],[],[0]for(_label,_text)in batch:#标签列表label_list.append(label_pipeline(_label))#文本列表processed_text =torch.tensor(text_pipeline(_text),dtype=torch.int64)text_list.append(processed_text)#偏移量,即语句的总词汇量offsets.append(processed_text.size(0))label_list =torch.tensor(label_list,dtype=torch.int64)text_list=torch.cat(text_list)offsets=torch.tensor(offsets[:-1]).cumsum(dim=0)#返回维度dim中输入元素的累计和return label_list.to(device),text_list.to(device),offsets.to(device)
#数据加载器
dataloader =DataLoader(train_iter,batch_size=8,shuffle =False,collate_fn=collate_batch)from torch import nn
class TextClassificationModel(nn.Module):def __init__(self,vocab_size,embed_dim,num_class):super(TextClassificationModel,self).__init__()self.embedding =nn.EmbeddingBag(vocab_size,#词典大小embed_dim,#嵌入的维度sparse=False)#self.fc =nn.Linear(embed_dim,num_class)self.init_weights()def init_weights(self):initrange =0.5self.embedding.weight.data.uniform_(-initrange,initrange)self.fc.weight.data.uniform_(-initrange,initrange)self.fc.bias.data.zero_()def forward(self,text,offsets):embedded =self.embedding(text,offsets)return self.fc(embedded)num_class = len(set([label for(label,text)in train_iter]))
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size,em_size,num_class).to(device)import time
def train(dataloader):model.train() #切换为训练模式total_acc,train_loss,total_count =0,0,0log_interval =500start_time =time.time()for idx,(label,text,offsets) in enumerate(dataloader):predicted_label =model(text,offsets)optimizer.zero_grad()#grad属性归零loss =criterion(predicted_label,label)#计算网络输出和真实值之间的差距,labe1为真实值loss.backward()#反向传播optimizer.step() #每一步自动更新#记录acc与losstotal_acc +=(predicted_label.argmax(1)==label).sum().item()train_loss +=loss.item()total_count +=label.size(0)if idx %log_interval ==0 and idx >0:elapsed =time.time()-start_timeprint('|epoch {:1d}|{:4d}/{:4d}batches''|train_acc {:4.3f}train_loss {:4.5f}'.format(epoch,idx,len(dataloader),total_acc/total_count,train_loss/total_count))total_acc,train_loss,total_count =0,0,0start_time =time.time()def evaluate(dataloader):model.eval() #切换为测试模式total_acc,train_loss,total_count =0,0,0with torch.no_grad():for idx,(label,text,offsets)in enumerate(dataloader):predicted_label =model(text,offsets)loss = criterion(predicted_label,label) #计算loss值#记录测试数据total_acc +=(predicted_label.argmax(1)==label).sum().item()train_loss +=loss.item()total_count +=label.size(0)return total_acc/total_count,train_loss/total_countfrom torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
#超参数
EPOCHS=10 #epoch
LR=5 #学习率
BATCH_SIZE=64 #batch size for training
criterion =torch.nn.CrossEntropyLoss()
optimizer =torch.optim.SGD(model.parameters(),lr=LR)
scheduler =torch.optim.lr_scheduler.StepLR(optimizer,1.0,gamma=0.1)
total_accu =Nonetrain_iter,test_iter =AG_NEWS()#加载数据
train_dataset =to_map_style_dataset(train_iter)
test_dataset =to_map_style_dataset(test_iter)
num_train=int(len(train_dataset)*0.95)split_train_,split_valid_=random_split(train_dataset,[num_train,len(train_dataset)-num_train])
train_dataloader =DataLoader(split_train_,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)
valid_dataloader =DataLoader(split_valid_,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)
test_dataloader=DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)for epoch in range(1,EPOCHS +1):epoch_start_time =time.time()train(train_dataloader)val_acc,val_loss =evaluate(valid_dataloader)if total_accu is not None and total_accu >val_acc:scheduler.step()else:total_accu =val_accprint('-'*69)print('|epoch {:1d}|time:{:4.2f}s|''valid_acc {:4.3f}valid_loss {:4.3f}'.format(epoch,time.time()-epoch_start_time,val_acc,val_loss))print('-'*69)print('Checking the results of test dataset.')
test_acc,test_loss =evaluate(test_dataloader)
print('test accuracy {:8.3f}'.format(test_acc))
文本构建向量的基本原理:
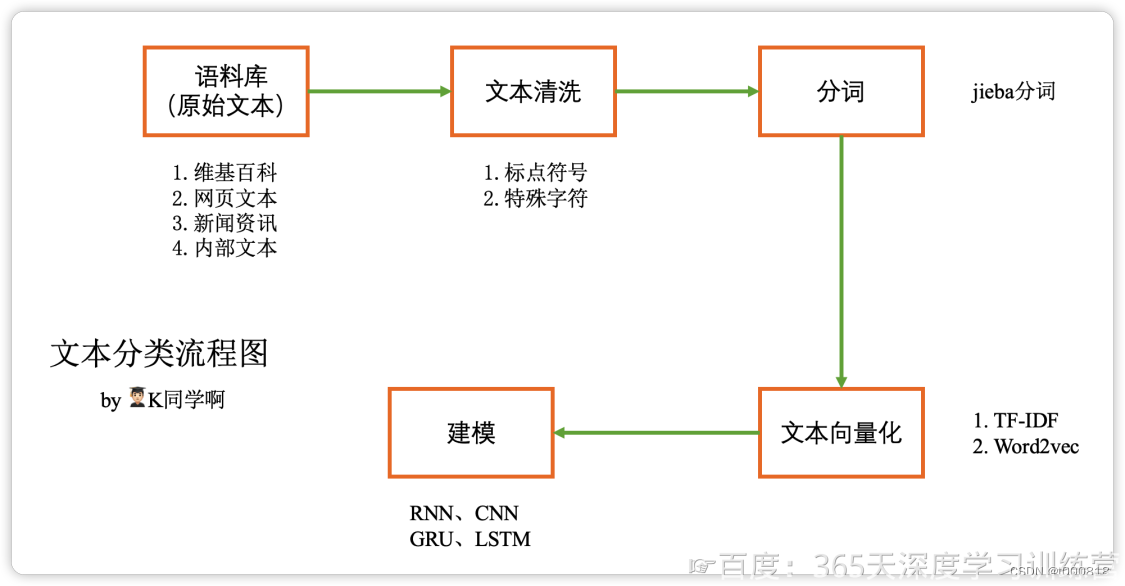
下面是运行结果:
D:\Code\pythonProject_PyTorch\venv\Scripts\python.exe D:\Code\pythonProject_PyTorch\PytorchText.py
[475, 21, 30, 5297]
[475, 21, 30, 5297]
9
|epoch 1| 500/1782batches|train_acc 0.721train_loss 0.01110
|epoch 1|1000/1782batches|train_acc 0.871train_loss 0.00606
|epoch 1|1500/1782batches|train_acc 0.877train_loss 0.00562
---------------------------------------------------------------------
|epoch 1|time:11.86s|valid_acc 0.782valid_loss 0.009
---------------------------------------------------------------------
|epoch 2| 500/1782batches|train_acc 0.903train_loss 0.00451
|epoch 2|1000/1782batches|train_acc 0.906train_loss 0.00442
|epoch 2|1500/1782batches|train_acc 0.906train_loss 0.00436
---------------------------------------------------------------------
|epoch 2|time:11.64s|valid_acc 0.845valid_loss 0.007
---------------------------------------------------------------------
|epoch 3| 500/1782batches|train_acc 0.919train_loss 0.00374
|epoch 3|1000/1782batches|train_acc 0.917train_loss 0.00383
|epoch 3|1500/1782batches|train_acc 0.915train_loss 0.00393
---------------------------------------------------------------------
|epoch 3|time:11.61s|valid_acc 0.905valid_loss 0.004
---------------------------------------------------------------------
|epoch 4| 500/1782batches|train_acc 0.927train_loss 0.00339
|epoch 4|1000/1782batches|train_acc 0.926train_loss 0.00342
|epoch 4|1500/1782batches|train_acc 0.922train_loss 0.00352
---------------------------------------------------------------------
|epoch 4|time:11.62s|valid_acc 0.870valid_loss 0.006
---------------------------------------------------------------------
|epoch 5| 500/1782batches|train_acc 0.942train_loss 0.00276
|epoch 5|1000/1782batches|train_acc 0.945train_loss 0.00268
|epoch 5|1500/1782batches|train_acc 0.945train_loss 0.00266
---------------------------------------------------------------------
|epoch 5|time:11.67s|valid_acc 0.913valid_loss 0.004
---------------------------------------------------------------------
|epoch 6| 500/1782batches|train_acc 0.946train_loss 0.00259
|epoch 6|1000/1782batches|train_acc 0.946train_loss 0.00261
|epoch 6|1500/1782batches|train_acc 0.946train_loss 0.00261
---------------------------------------------------------------------
|epoch 6|time:11.71s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
|epoch 7| 500/1782batches|train_acc 0.948train_loss 0.00255
|epoch 7|1000/1782batches|train_acc 0.946train_loss 0.00260
|epoch 7|1500/1782batches|train_acc 0.948train_loss 0.00250
---------------------------------------------------------------------
|epoch 7|time:11.68s|valid_acc 0.912valid_loss 0.004
---------------------------------------------------------------------
|epoch 8| 500/1782batches|train_acc 0.948train_loss 0.00252
|epoch 8|1000/1782batches|train_acc 0.948train_loss 0.00249
|epoch 8|1500/1782batches|train_acc 0.950train_loss 0.00244
---------------------------------------------------------------------
|epoch 8|time:11.52s|valid_acc 0.913valid_loss 0.004
---------------------------------------------------------------------
|epoch 9| 500/1782batches|train_acc 0.949train_loss 0.00249
|epoch 9|1000/1782batches|train_acc 0.950train_loss 0.00246
|epoch 9|1500/1782batches|train_acc 0.950train_loss 0.00248
---------------------------------------------------------------------
|epoch 9|time:11.57s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
|epoch 10| 500/1782batches|train_acc 0.950train_loss 0.00246
|epoch 10|1000/1782batches|train_acc 0.950train_loss 0.00243
|epoch 10|1500/1782batches|train_acc 0.949train_loss 0.00249
---------------------------------------------------------------------
|epoch 10|time:11.74s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
Checking the results of test dataset.
test accuracy 0.909Process finished with exit code 0
总结:PyTorch version、torchtext version、Supported Python version版本一定要对应,可以参考:https://blog.csdn.net/shiwanghualuo/article/details/122860521