说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

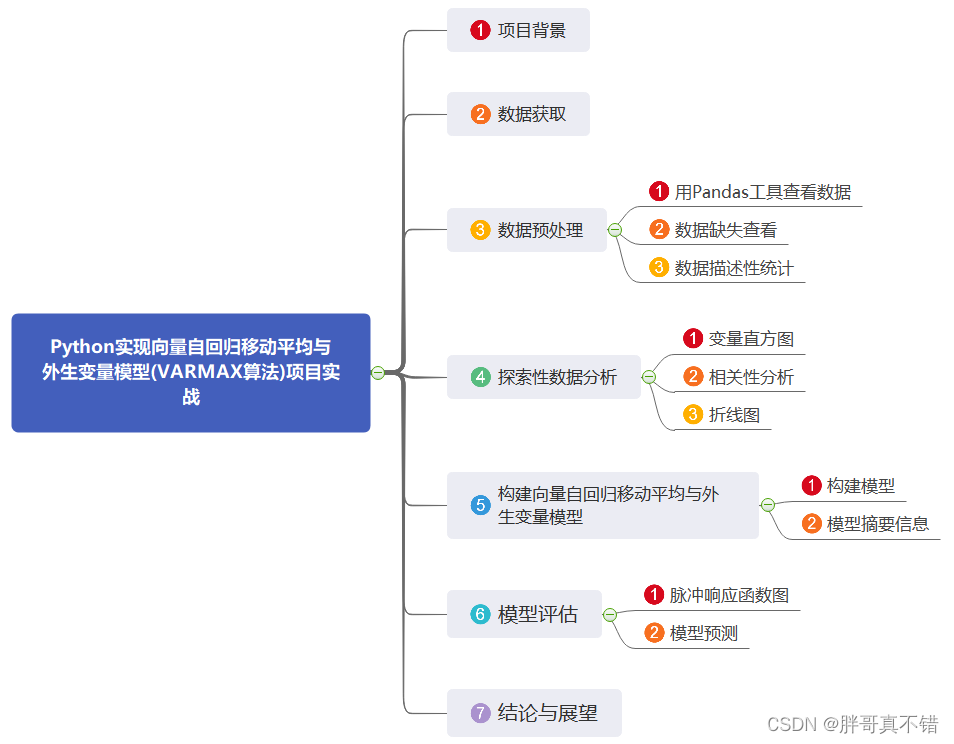
1.项目背景
向量自回归移动平均与外生变量模型(Vector Autoregression Moving Average with Exogenous Regressors,简称VARMAX)是一种扩展的多元时间序列分析模型,它结合了向量自回归(VAR)和向量移动平均(VMA)模型的特点,并且允许纳入外生变量作为模型的一部分。
在VARMAX模型中:
向量自回归(VAR):
VAR模型描述了一系列内生变量(即模型内部相互影响的时间序列变量)如何通过它们各自的滞后值以及其他内生变量的滞后值共同决定当前值。比如,一个经济系统中的多个宏观经济指标可能会相互影响并在过去的状态基础上共同决定当前状态。
向量移动平均(VMA):
VMA模型则考虑残差项(即观测值与模型预测值之间的误差)的滞后值对当前变量的影响。
外生变量(Exogenous Regressors):
在VARMAX模型中,除了内生变量的滞后效应之外,还包括了一组外生变量(或称解释变量、前定变量),这些变量不受模型内其他变量的影响,但可以影响模型内的内生变量。例如,在经济分析中,政策利率或者特定的经济政策变化等可能是模型中的外生变量。
综合起来,VARMAX模型能够同时捕捉内生变量之间的动态交互作用、残差项的历史依赖以及外生变量对内生变量的即时和滞后影响,从而提供更全面、灵活的多元时间序列分析框架。
本项目通过VARMAX算法来构建向量自回归移动平均与外生变量模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | date | 日期 |
| 2 | dln_inv | 投资(Investment)的对数增长率 |
| 3 | dln_inc | 收入(Income)的对数增长率 |
| 4 | dln_consump | 消费(Consumption)的对数增长率 |
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:

从上图可以看到,总共有3个变量,数据中无缺失值,共91条数据。
关键代码:

3.3 数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
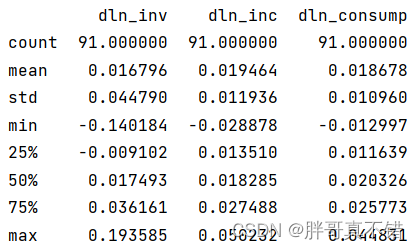
关键代码如下:

4.探索性数据分析
4.1 变量直方图
用Matplotlib工具的hist()方法绘制直方图:
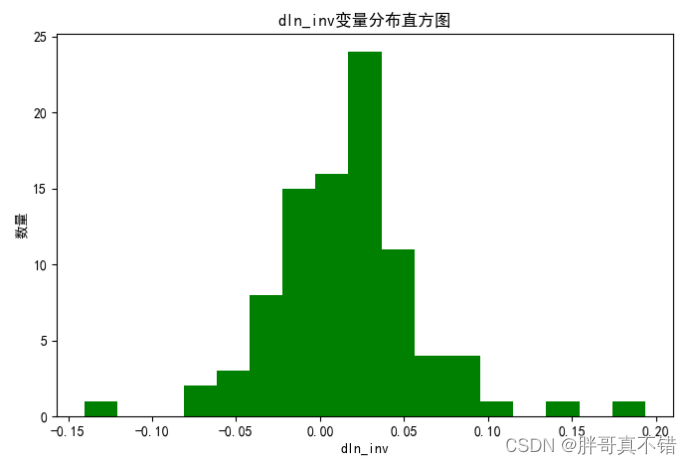
从上图可以看到,变量主要集中在-0.05~0.10之间。
4.2 相关性分析
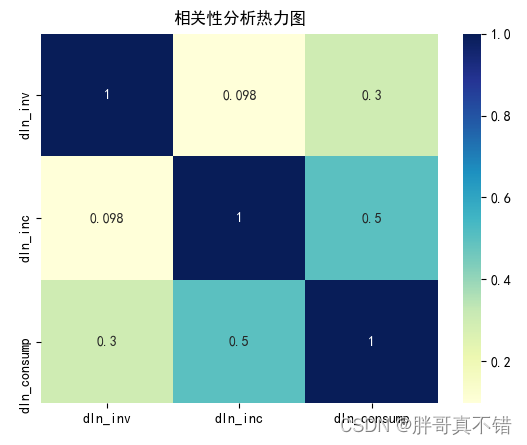
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
4.3 折线图
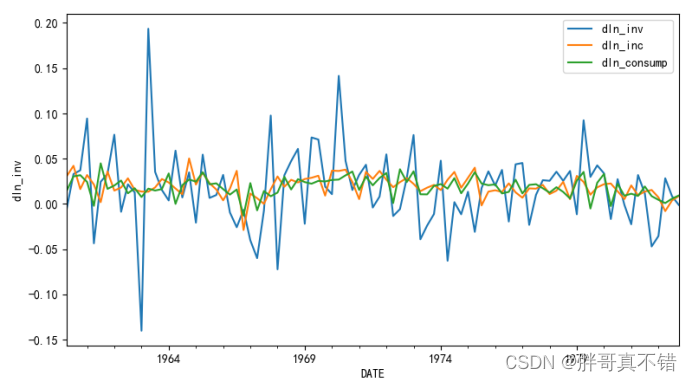
从上图中可以看到,数据是不断波动的。
5.构建向量自回归移动平均与外生变量模型
主要使用VARMAX算法,用于向量自回归移动平均与外生变量模型。
5.1 构建模型
| 编号 | 模型名称 | 参数 |
| 1 | 向量自回归移动平均与外生变量模型 | order=(2, 0) |
| 2 | trend='n' | |
| 3 | exog=exog |
5.2 模型摘要信息
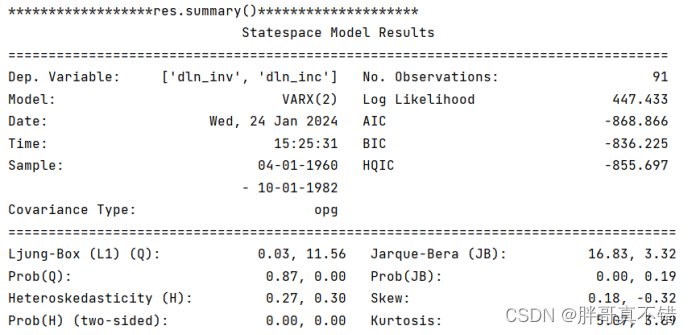
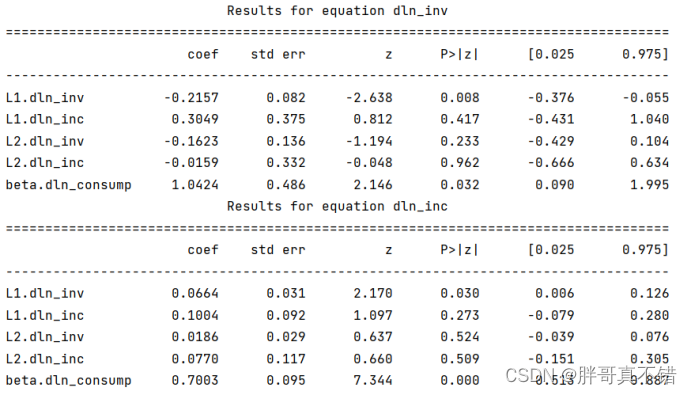
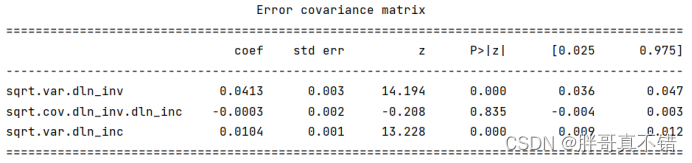
6.模型评估
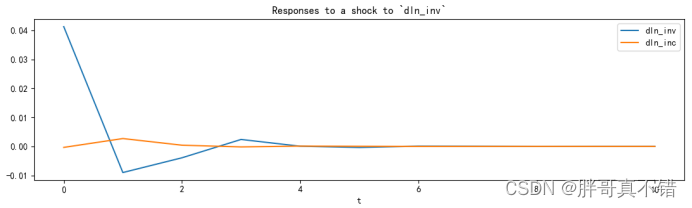
6.1 脉冲响应函数图
6.2 模型预测
预测结果及展示:

7.结论与展望
综上所述,本文采用了VARMAX算法来构建向量自回归移动平均与外生变量模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
# 本次机器学习项目实战所需的资料,项目资源如下:# 项目说明:# 获取方式一:# 项目实战合集导航:https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2# 获取方式二:链接:https://pan.baidu.com/s/1X2AKD-zOTzBJY83MGq56uA
提取码:lzli