在[[使用python批量写入ES索引数据]]中已经介绍了如何批量写入ES数据。基于该流程实际测试一下指定文档ID对ES性能的影响有多大。
一句话版
指定ID比不指定ID的性能下降了63%,且加剧趋势。
以下是测评验证的细节。
百万数据量
索引默认使用1分片和1副本。
指定ID写入
执行完写入程序,后台显示耗时:
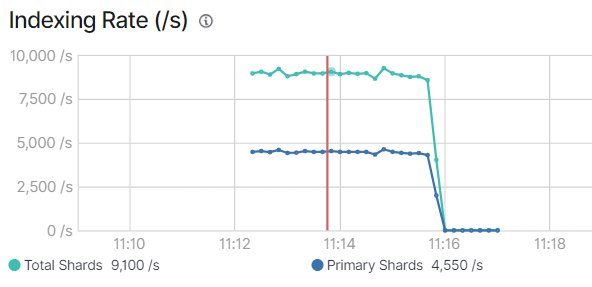
'Total Time Spent: ', 225.49,据此计算吞吐量为4444/s。
索引速度监控截图显示约4550条每秒:
不指定ID写入
执行完写入程序,后台显示耗时:
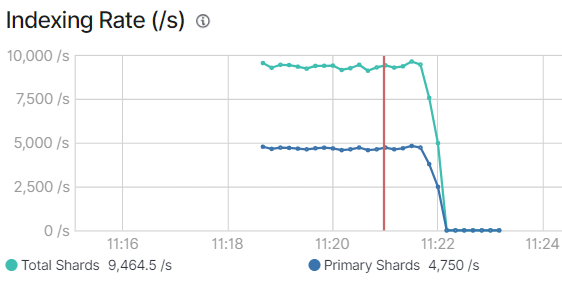
'Total Time Spent: ', 214.52,据此计算为4672/s。
后台索引的性能监控显示,写入速度约是4750条每秒,比写ID时略高5%。
千万级数据量
索引创建多个分片
此时我们指定要写入的索引为3个分片,也是1份副本。
代码里添加的内容是:
# 定义要创建的索引及其设置,包括主分片数为3
create_index_body = { "settings": { "index": { "number_of_shards": 3, # 设置主分片数为3 "number_of_replicas": 1 # 设置副本数为1,可以根据需要调整 } }
} # 创建索引
if not es.indices.exists(index="my_index"): es.indices.create(index="my_index", body=create_index_body)
指定ID
后台显示耗时:
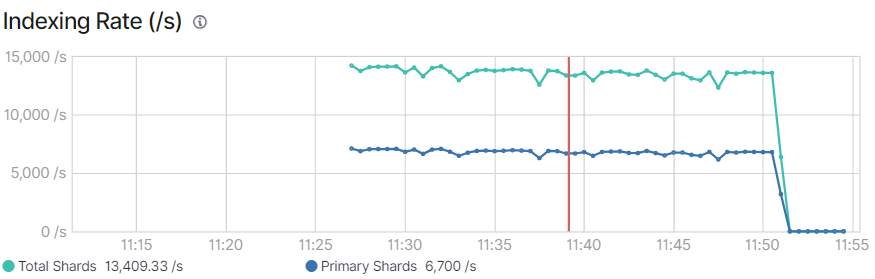
'Total Time Spent: ', 1465.45,据此计算写入速度平均6825/s。
索引速度约6700条每秒。
不指定ID
后台显示耗时:
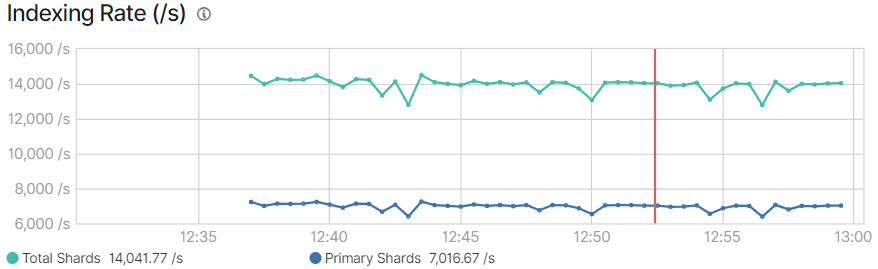
'Total Time Spent: ', 1434.30,计算为6973/s。
监控趋势展示,约7016条每秒。
优势似乎不明显。
我们继续追加1000万条数据,此时id使用随机生成的字符串。
追加1000万数据
从写入机制考虑,应该原始索引有存量数据才对性能有影响,我们追加写入1000万数据进行验证,且使用随机生成的uuid。
指定文档ID
1000万到2000万:程序耗时1778.45秒。
最终通过ES查询索引元数据观察到索引操作累计耗时是1215秒。
其余的时间多是python程序自身运行的占用。
2000万到3000万:程序耗时1904.99秒;索引累计耗时2026秒。
3000万到4000万:程序耗时1904.99秒;索引累计耗时2026秒。
4000万到5000万:程序耗时1904.99秒;索引累计耗时2026秒。
那么,最后1000万数据实际入库索引速度是11025/s。
不指定文档ID
1000万到2000万:程序耗时1446.72秒;索引操作耗时1112秒。
2000万到3000万:程序耗时1458.31秒;索引累计耗时1672秒。
3000万到4000万:程序耗时1497.03秒;索引累计耗时2232秒。
4000万到5000万:程序耗时1475.83秒;索引累计耗时2788秒。
那么,最后1000万数据的实际索引速度是17985/s。
最终,测试集群已经有一个亿的数据:
统计以上数据趋势看图。
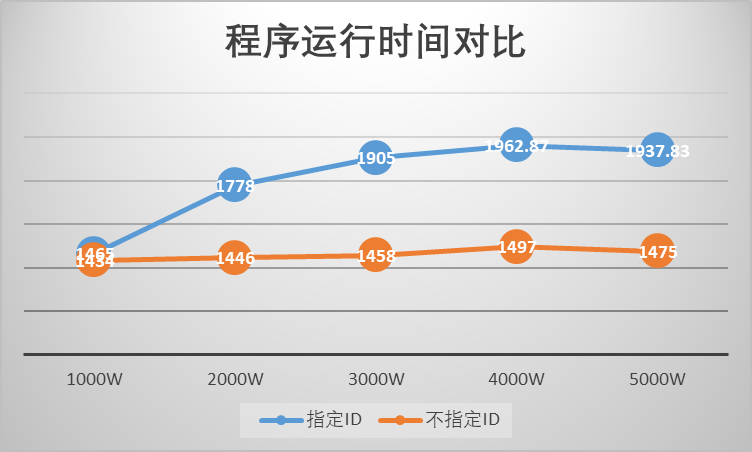
- 不指定ID的运行效率基本恒定
- 指定ID的运行效率逐步下降了约33%
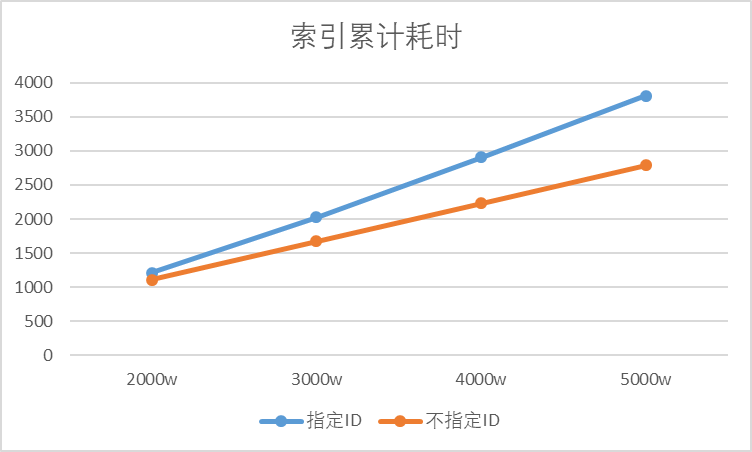
- 索引速度的差距稳步拉开!!
总结
综上,指定ID写入对性能的负面影响随着数据量增长而增大。数据显示在5000万级别性能已损失了63%。
这是虚拟机环境的模拟,具体计算指定ID对性能的影响是复杂的,因为它取决于上述多个因素以及你的软硬件环境。
据ES官方的性能调优指南:在为具有显式 id 的文档编制索引时,Elasticsearch 需要检查同一分区内是否已经存在具有相同 id 的文档,这是一项成本很高的操作,而且随着索引的增加,成本会越来越高。
可以预见的是当索引变大到某一程度时指定ID的性能可能会断崖式下跌而非缓慢下降。
与君共赏
《题西林壁》宋·苏轼
横看成岭侧成峰,远近高低各不同。
不识庐山真面目,只缘身在此山中。