基于K8S构建EFK+logstash+kafka日志平台
- 一、常见日志收集方案
- 1.1、EFK
- 1.2、ELK Stack
- 1.3、ELK +filbeat
- 1.4、其他方案
- 二、EFK组件介绍
- 2.1、Elasticsearch组件
- 2.2、Filebeat组件
- 【1】 Filebeat和beat关系
- 【2】Filebeat是什么
- 【3】Filebeat工作原理
- 【4】传输方案
- 2.3、Logstash组件
- 2.4、Fluent组件
- 2.5、fluentd、filebeat、logstash对比分析
- 三、EFK组件安装
- 3.1、安装elasticsearch
- 【1】创建headless service服务
- 【2】创建Storageclass ,实现存储类动态供给
- 【3】安装Elasticsearch集群
- 3.2、安装kibana可视化UI界面
- 3.3、安装fluentd组件
- 3.4、测试收集pod容器日志
一、常见日志收集方案
1.1、EFK
在Kubernetes集群上运行多个服务和应用程序时,日志收集系统可以帮助你快速分类和分析由Pod生成的大量日志数据。Kubernetes中比较流行的日志收集解决方案是Elasticsearch、Fluentd和Kibana(EFK)技术栈,也是官方推荐的一种方案。
Elasticsearch是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。
Elasticsearch通常与Kibana一起部署,kibana可以把Elasticsearch采集到的数据通过dashboard(仪表板)可视化展示出来。Kibana允许你通过Web界面浏览Elasticsearch日志数据,也可自定义查询条件快速检索出elasticccsearch中的日志数据。
Fluentd是一个流行的开源数据收集器,我们在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
1.2、ELK Stack
E - Elasticsearch(简称:ES)
L - Logstash
K - Kibana
Elasticsearch:日志存储和搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash:是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作。)。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
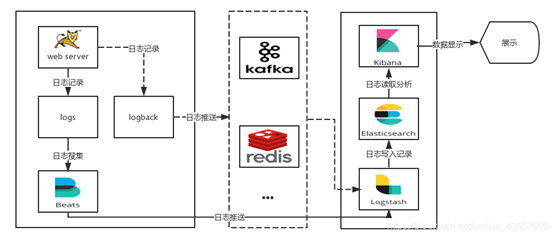
应用程序(AppServer)–>Logstash–>ElasticSearch–>Kibana–>浏览器(Browser):
Logstash收集AppServer产生的Log,并存放到ElasticSearch集群中,而Kibana则从ElasticSearch集群中查询数据生成图表,再返回给Browser。
考虑到聚合端(日志处理、清洗等)负载问题和采集端传输效率,一般在日志量比较大的时候在采集端和聚合端增加队列,以用来实现日志消峰。
1.3、ELK +filbeat
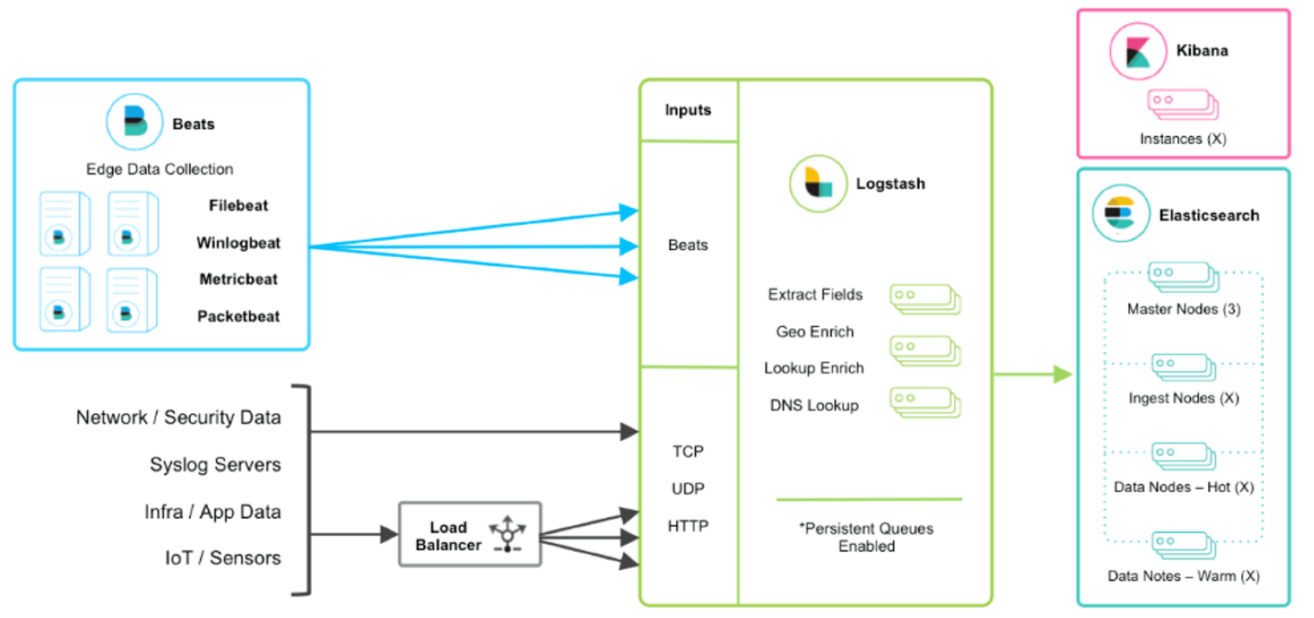
Filebeat(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示)
1.4、其他方案
ELK日志流程可以有多种方案(不同组件可自由组合,根据自身业务配置),常见有以下:
Logstash(采集、处理)—> ElasticSearch (存储)—>Kibana (展示)
Logstash(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示)
Filebeat(采集、处理)—> ElasticSearch (存储)—>Kibana (展示)
Filebeat(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示)
Filebeat(采集)—> Kafka/Redis(消峰) —> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示)
二、EFK组件介绍
2.1、Elasticsearch组件
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;
Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。
人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana)。
目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
2.2、Filebeat组件
【1】 Filebeat和beat关系
filebeat是Beats中的一员。
Beats是一个轻量级日志采集器,Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
目前Beats包含六种工具:
1、Packetbeat:网络数据(收集网络流量数据)
2、Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
3、Filebeat:日志文件(收集文件数据)
4、Winlogbeat:windows事件日志(收集Windows事件日志数据)
5、Auditbeat:审计数据(收集审计日志)
6、Heartbeat:运行时间监控(收集系统运行时的数据)
【2】Filebeat是什么
Filebeat是用于转发和收集日志数据的轻量级传送工具。Filebeat监视你指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash中。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
工作的流程图如下:
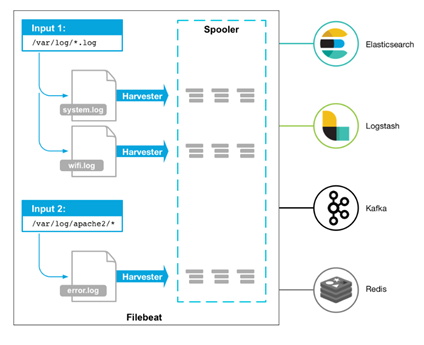
Filebeat 有两个主要组件:
harvester:一个harvester负责读取一个单个文件的内容。harvester逐行读取每个文件,并把这些内容发送到输出。每个文件启动一个harvester。
Input:一个input负责管理harvesters,并找到所有要读取的源。如果input类型是log,则input查找驱动器上与已定义的log日志路径匹配的所有文件,并为每个文件启动一个harvester。
【3】Filebeat工作原理
在任何环境下,应用程序都有停机的可能性。 Filebeat 读取并转发日志行,如果中断,则会记住所有事件恢复联机状态时所在位置。
Filebeat带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
FileBeat 不会让你的管道超负荷。FileBeat 如果是向 Logstash 传输数据,当 Logstash 忙于处理数据,会通知 FileBeat 放慢读取速度。一旦拥塞得到解决,FileBeat将恢复到原来的速度并继续传播。
Filebeat保持每个文件的状态,并经常刷新注册表文件中的磁盘状态。状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。Filebeat将每个事件的传递状态存储在注册表文件中。所以它能保证事件至少传递一次到配置的输出,没有数据丢失。
【4】传输方案
1、output.elasticsearch
如果你希望使用 filebeat 直接向 elasticsearch 输出数据,需要配置 output.elasticsearch
output.elasticsearch:
hosts: [“192.168.40.180:9200”]
2、output.logstash
如果使用filebeat向 logstash输出数据,然后由 logstash 再向elasticsearch 输出数据,需要配置 output.logstash。 logstash 和 filebeat 一起工作时,如果 logstash 忙于处理数据,会通知FileBeat放慢读取速度。一旦拥塞得到解决,FileBeat 将恢复到原来的速度并继续传播。这样,可以减少管道超负荷的情况。
output.logstash:
hosts: [“192.168.40.180:5044”]
3、output.kafka
如果使用filebeat向kafka输出数据,然后由 logstash 作为消费者拉取kafka中的日志,并再向elasticsearch 输出数据,需要配置 output.logstash
output.kafka:
enabled: true
hosts: [“192.168.40.180:9092”]
topic: elfk8stest
2.3、Logstash组件
2.4、Fluent组件
2.5、fluentd、filebeat、logstash对比分析
三、EFK组件安装
在安装Elasticsearch集群之前,我们先创建一个名称空间,在这个名称空间下安装日志收工具elasticsearch、fluentd、kibana。我们创建一个kube-logging名称空间,将EFK组件安装到该名称空间中。
kubectl create ns kube-logging
3.1、安装elasticsearch
首先,我们需要部署一个有3个节点的Elasticsearch集群。
我们使用3个Elasticsearch Pods可以避免高可用中多节点集群中发生的“脑裂”问题。
脑裂问题参考如下:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain
【1】创建headless service服务
[root@master 4]# cat elasticsearch_svc.yaml
apiVersion: v1
kind: Service
metadata:name: elasticsearchnamespace: kube-logginglabels:app: elasticsearch
spec:selector:app: elasticsearchclusterIP: Noneports:- port: 9200name: rest- port: 9300name: inter-node
在kube-logging名称空间定义了一个名为 elasticsearch 的 Service服务,带有app=elasticsearch标签,当我们将 Elasticsearch StatefulSet 与此服务关联时,服务将返回带有标签app=elasticsearch的 Elasticsearch Pods的DNS A记录,然后设置clusterIP=None,将该服务设置成无头服务。最后,我们分别定义端口9200、9300,分别用于与 REST API 交互,以及用于节点间通信。
[root@master 4]# kubectl apply -f elasticsearch_svc.yaml
service/elasticsearch created
[root@master 4]# kubectl get svc -n kube-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 20s
现在我们已经为 Pod 设置了无头服务和一个稳定的域名.elasticsearch.kube-logging.svc.cluster.local,接下来我们通过 StatefulSet来创建具体的 Elasticsearch的Pod 应用。
【2】创建Storageclass ,实现存储类动态供给
1、安装nfs
[root@master 4]# yum install nfs-utils -y
[root@node01 ~]# yum install nfs-utils -y
[root@node02 ~]#yum install nfs-utils -y[root@master 4]# systemctl start nfs
[root@node01 ~]# systemctl start nfs
[root@node02 ~]# systemctl start nfs[root@master 4]# systemctl enable nfs.service
[root@node01 ~]# systemctl enable nfs.service
[root@node02 ~]# systemctl enable nfs.service
2、master创建共享目录
[root@master 4]# mkdir /data/v1 -p
# 编辑/etc/exports文件
[root@master 4]# vim /etc/exports
/data/v1 10.32.1.0/24(rw,no_root_squash)
# 加载配置,使配置生效
[root@master 4]# exportfs -arv
exporting 10.32.1.0/24:/data/v1
[root@master 4]# systemctl restart nfs
3、创建nfs作为存储的供应商
- 创建sa
kubectl create sa nfs-provisioner - 对sa做rbac授权
[root@master 4]# cat rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: nfs-provisioner-runner
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get","list","watch","create","delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]- apiGroups: [""]resources: ["services", "endpoints"]verbs: ["get"]- apiGroups: ["extensions"]resources: ["podsecuritypolicies"]resourceNames: ["nfs-provisioner"]verbs: ["use"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: run-nfs-provisioner
subjects:- kind: ServiceAccountname: nfs-provisionernamespace: default
roleRef:kind: ClusterRolename: nfs-provisioner-runnerapiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-provisioner
rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-provisioner
subjects:
- kind: ServiceAccountname: nfs-provisionernamespace: default
roleRef:kind: Rolename: leader-locking-nfs-provisionerapiGroup: rbac.authorization.k8s.io
[root@master 4]# kubectl apply -f rbac.yaml
clusterrole.rbac.authorization.k8s.io/nfs-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-provisioner created
- 创建pod
把nfs-client-provisioner.tar.gz上传到node工作节点上,手动解压。
ctr -n=k8s.io image import nfs-client-provisioner.tar.gz
通过deployment创建pod用来运行nfs-provisioner
[root@master 4]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-provisioner
spec:selector:matchLabels:app: nfs-provisionerreplicas: 1strategy:type: Recreatetemplate:metadata:labels:app: nfs-provisionerspec:serviceAccount: nfs-provisionercontainers:- name: nfs-provisioner# 这个供应商镜像如果有问题,就换成其他的,我的最后换成了# registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner 前提是这个镜像上传到了node节点image: registry.cn-hangzhou.aliyuncs.com/open-ali/xianchao/nfs-client-provisioner:v1imagePullPolicy: IfNotPresentvolumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: example.com/nfs- name: NFS_SERVERvalue: 10.32.1.147#这个需要写nfs服务端所在的ip地址,大家需要写自己安装了nfs服务的机器ip- name: NFS_PATHvalue: /data/v1volumes:# 这个是nfs服务端共享的目录- name: nfs-client-rootnfs:server: 10.32.1.147path: /data/v1
[root@master 4]# kubectl apply -f deployment.yaml
deployment.apps/nfs-provisioner configured
[root@master 4]# kubectl get pods -owide| grep nfs
nfs-provisioner-5fb64dc877-4pzbk 1/1 Running 0 6m49s 10.244.196.143 node01 <none> <none>
- 创建storageclass
[root@master 4]# cat class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: do-block-storage
provisioner: example.com/nfs
[root@master 4]# k apply -f class.yaml
storageclass.storage.k8s.io/do-block-storage created
[root@master 4]# k get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
do-block-storage example.com/nfs Delete Immediate false 70m
【3】安装Elasticsearch集群
把elasticsearch_7_2_0.tar.gz和busybox.tar.gz
上传到工作节点node01、node02,手动解压:
[root@node01 package]# ctr -n=k8s.io image import elasticsearch_7_2_0.tar.gz
[root@node02 package]# ctr -n=k8s.io image import elasticsearch_7_2_0.tar.gz
更新和应用yaml文件
[root@master 4]# cat elasticsearch-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:name: es-clusternamespace: kube-logging
spec:serviceName: elasticsearchreplicas: 3selector:matchLabels:app: elasticsearchtemplate:metadata:labels:app: elasticsearchspec:containers:- name: elasticsearchimage: docker.elastic.co/elasticsearch/elasticsearch:7.2.0imagePullPolicy: IfNotPresentresources:limits:cpu: 1000mrequests:cpu: 100mports:- containerPort: 9200name: restprotocol: TCP- containerPort: 9300name: inter-nodeprotocol: TCPvolumeMounts:- name: datamountPath: /usr/share/elasticsearch/dataenv:- name: cluster.namevalue: k8s-logs- name: node.namevalueFrom:fieldRef:fieldPath: metadata.name- name: discovery.seed_hostsvalue: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"- name: cluster.initial_master_nodesvalue: "es-cluster-0,es-cluster-1,es-cluster-2"- name: ES_JAVA_OPTSvalue: "-Xms512m -Xmx512m"initContainers:- name: fix-permissionsimage: busyboximagePullPolicy: IfNotPresentcommand: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]securityContext:privileged: truevolumeMounts:- name: datamountPath: /usr/share/elasticsearch/data- name: increase-vm-max-mapimage: busyboximagePullPolicy: IfNotPresentcommand: ["sysctl", "-w", "vm.max_map_count=262144"]securityContext:privileged: true- name: increase-fd-ulimitimage: busyboximagePullPolicy: IfNotPresentcommand: ["sh", "-c", "ulimit -n 65536"]securityContext:privileged: truevolumeClaimTemplates:- metadata:name: datalabels:app: elasticsearchspec:accessModes: [ "ReadWriteOnce" ]storageClassName: do-block-storageresources:requests:storage: 5Gi
上面内容的解释:在kube-logging的名称空间中定义了一个es-cluster的StatefulSet。
然后,我们使用serviceName 字段与我们之前创建的headless ElasticSearch服务相关联。这样可以确保可以使用以下DNS地址访问StatefulSet中的每个Pod:,es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local,其中[0,1,2]与Pod分配的序号数相对应。
我们指定3个replicas(3个Pod副本),将selector matchLabels 设置为app: elasticseach。该.spec.selector.matchLabels和.spec.template.metadata.labels字段必须匹配。
[root@master 4]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 10m
es-cluster-1 1/1 Running 0 10m
es-cluster-2 1/1 Running 0 10m
[root@master 4]# kubectl get svc -n kube-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 6h15mpod部署完成之后,可以通过REST API检查elasticsearch集群是否部署成功,使用下面的命令将本地端口9200转发到 Elasticsearch 节点(如es-cluster-0)对应的端口:
kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
然后,在另外的终端窗口中,执行如下请求,新开一个master1终端:
[root@master 4]# curl http://localhost:9200/_cluster/state?pretty|head -50% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed10 146k 10 16294 0 0 310k 0 --:--{-- --:--:-- --:--:-- 0"cluster_name" : "k8s-logs","cluster_uuid" : "GCzlBOZnT8abADeTCJyrRg","version" : 17,"state_uuid" : "yIAM6AEzSdOCgK9FHmuriQ","master_node" : "7UL9lwt2Qa-Rx9S-5hm3tQ","blocks" : { },"nodes" : {"6FkyqeBnQ9GGJjqxmIK4OA" : {"name" : "es-cluster-2","ephemeral_id" : "T8DdDj6tQSm-mERp4rkrNg","transport_address" : "10.244.196.142:9300","attributes" : {"ml.machine_memory" : "8201035776","ml.max_open_jobs" : "20","xpack.installed" : "true"}},"7UL9lwt2Qa-Rx9S-5hm3tQ" : {"name" : "es-cluster-0","ephemeral_id" : "JFYS2bHqTD-FaxV5IpACWQ","transport_address" : "10.244.196.135:9300","attributes" : {"ml.machine_memory" : "8201035776","xpack.installed" : "true","ml.max_open_jobs" : "20"}},"QRd7XeJ5TtO-bdaru3wAkg" : {"name" : "es-cluster-1","ephemeral_id" : "uG4ZE_N8QGGNDyXnE4puSQ","transport_address" : "10.244.140.105:9300","attrib:--utes" : {"ml.machine_memory" : "8201248768",
- "ml.max_open_jobs" : "20",
- "xpack.installed" : "true"
: }
- }
- },
# 看到上面的信息就表明我们名为 k8s-logs 的 Elasticsearch 集群成功创建了3个节点:
# es-cluster-0,es-cluster-1,和es-cluster-2
# 当前主节点是 es-cluster-0
3.2、安装kibana可视化UI界面
[root@master 4]# cat kibana.yaml
apiVersion: v1
kind: Service
metadata:name: kibananamespace: kube-logginglabels:app: kibana
spec:ports:- port: 5601selector:app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:name: kibananamespace: kube-logginglabels:app: kibana
spec:replicas: 1selector:matchLabels:app: kibanatemplate:metadata:labels:app: kibanaspec:containers:- name: kibanaimage: docker.elastic.co/kibana/kibana:7.2.0imagePullPolicy: IfNotPresentresources:limits:cpu: 1000mrequests:cpu: 100menv:- name: ELASTICSEARCH_URLvalue: http://elasticsearch:9200ports:- containerPort: 5601
[root@master 4]# kubectl apply -f kibana.yaml
[root@master 4]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 41m
es-cluster-1 1/1 Running 0 41m
es-cluster-2 1/1 Running 0 40m
kibana-69f46c6bd-vm7rh 1/1 Running 0 18m
[root@master 4]# kubectl get svc -n kube-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 6h43m
kibana ClusterIP 10.109.118.117 <none> 5601/TCP 18m
# 修改service的type类型为NodePort:
[root@master 4]# kubectl edit svc kibana -n kube-logging
[root@master 4]# kubectl get svc -n kube-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 6h44m
kibana NodePort 10.109.118.117 <none> 5601:31598/TCP 20m
在浏览器中打开http://<k8s集群任意节点IP>:31598即可,如果看到如下欢迎界面证明 Kibana 已经成功部署到了Kubernetes集群之中。
3.3、安装fluentd组件
将镜像上传到各个节点(master、node节点都要上传)
然后解压
[root@master 4]# ctr -n=k8s.io images import fluentd-v1-9-1.tar.gz
[root@node01 package]# ctr -n=k8s.io images import fluentd-v1-9-1.tar.gz
[root@node02 package]# ctr -n=k8s.io images import fluentd-v1-9-1.tar.gz
[root@master 4]# cat fluentd.yaml
apiVersion: v1
kind: ServiceAccount
metadata:name: fluentdnamespace: kube-logginglabels:app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: fluentdlabels:app: fluentd
rules:
- apiGroups:- ""resources:- pods- namespacesverbs:- get- list- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: fluentd
roleRef:kind: ClusterRolename: fluentdapiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccountname: fluentdnamespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: fluentdnamespace: kube-logginglabels:app: fluentd
spec:selector:matchLabels:app: fluentdtemplate:metadata:labels:app: fluentdspec:serviceAccount: fluentdserviceAccountName: fluentdtolerations:- key: node-role.kubernetes.io/mastereffect: NoSchedulecontainers:- name: fluentdimage: fluentd:v1.9.1-debian-1.0imagePullPolicy: IfNotPresentenv:- name: FLUENT_ELASTICSEARCH_HOSTvalue: "elasticsearch.kube-logging.svc.cluster.local"- name: FLUENT_ELASTICSEARCH_PORTvalue: "9200"- name: FLUENT_ELASTICSEARCH_SCHEMEvalue: "http"- name: FLUENTD_SYSTEMD_CONFvalue: disable- name: FLUENT_CONTAINER_TAIL_PARSE_TYPE # 注意:如果是用containerd做容器运行时,就要加这4行,使用docker则不用value: "cri"- name: FLUENT_CONTAINER_TAIL_PARSE_TIME_FORMATvalue: "%Y-%m-%dT%H:%M:%S.%L%z"resources:limits:memory: 512Mirequests:cpu: 100mmemory: 200MivolumeMounts:- name: varlogmountPath: /var/log- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: trueterminationGracePeriodSeconds: 30volumes:- name: varloghostPath:path: /var/log- name: varlibdockercontainershostPath:path: /var/lib/docker/containers
[root@master 4]# kubectl apply -f fluentd.yaml
serviceaccount/fluentd unchanged
clusterrole.rbac.authorization.k8s.io/fluentd unchanged
clusterrolebinding.rbac.authorization.k8s.io/fluentd unchanged
daemonset.apps/fluentd created[root@master 4]# kubectl get pods -n kube-logging
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 17h
es-cluster-1 1/1 Running 0 17h
es-cluster-2 1/1 Running 0 17h
fluentd-8fzqg 1/1 Running 0 23s
fluentd-fjhgg 1/1 Running 0 23s
fluentd-vlhn6 1/1 Running 0 23s
kibana-69f46c6bd-vm7rh 1/1 Running 0 16h
Fluentd 启动成功后,我们可以前往 Kibana 的 Dashboard 页面中,点击左侧的Discover,可以看到如下配置页面:

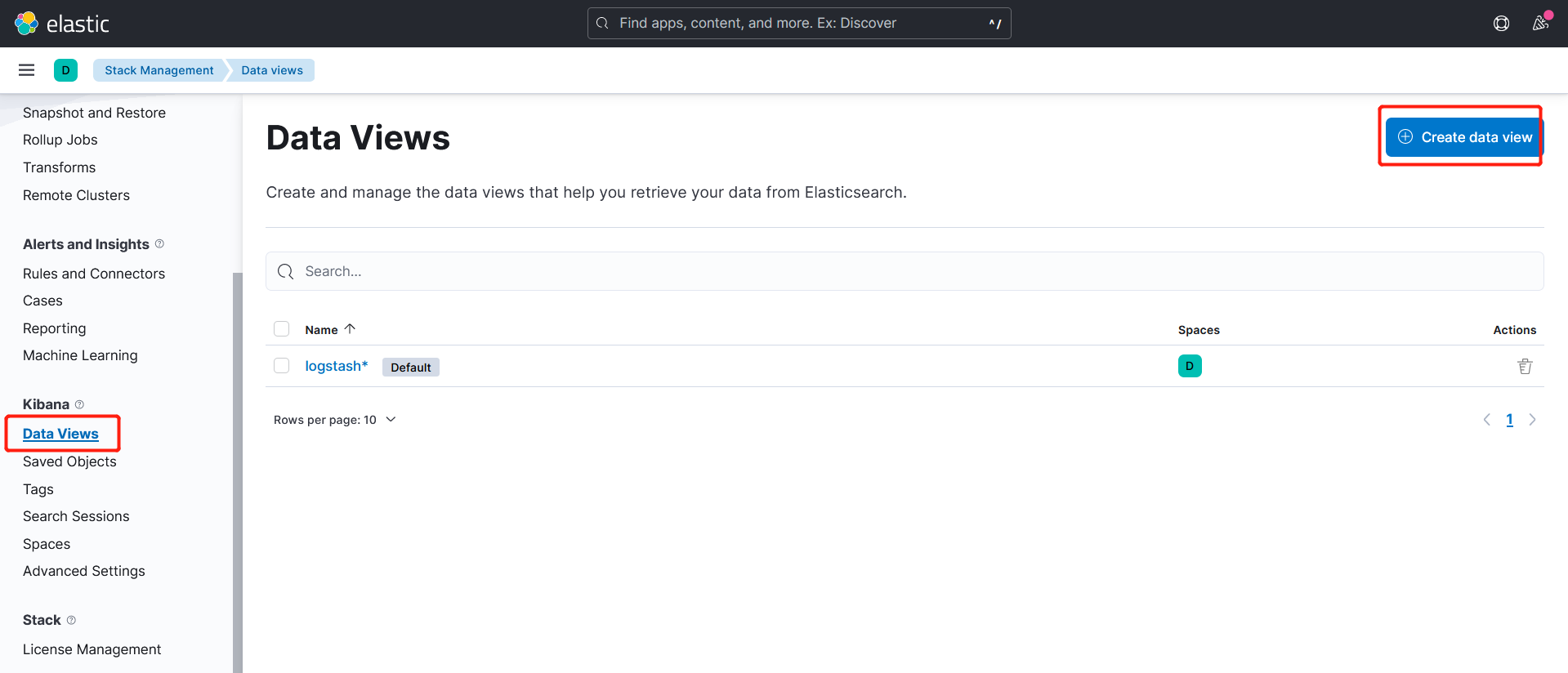
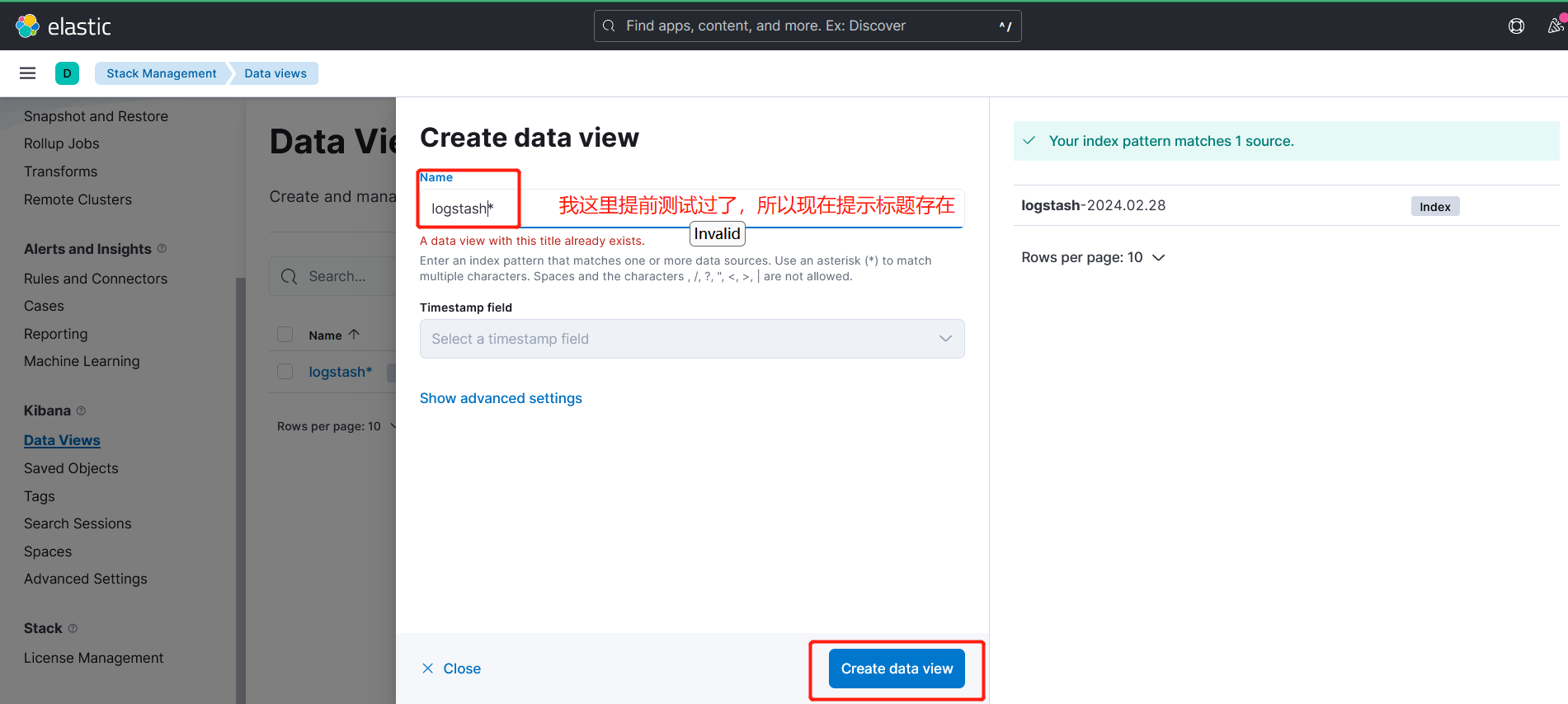
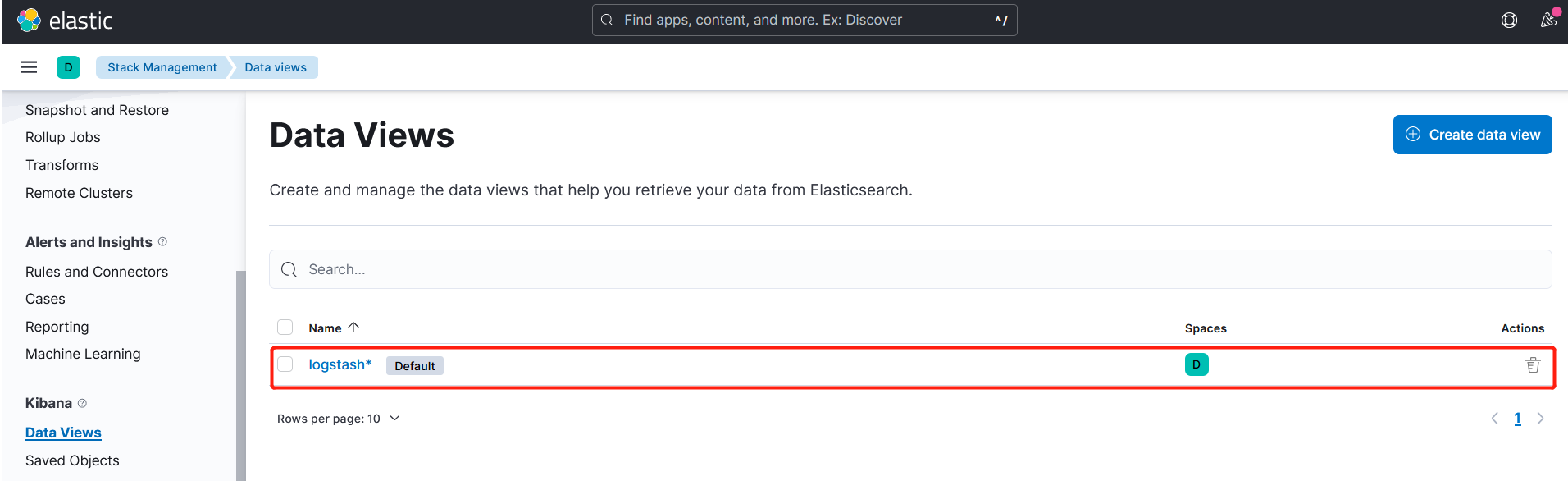
点击左侧的discover,可看到如下:
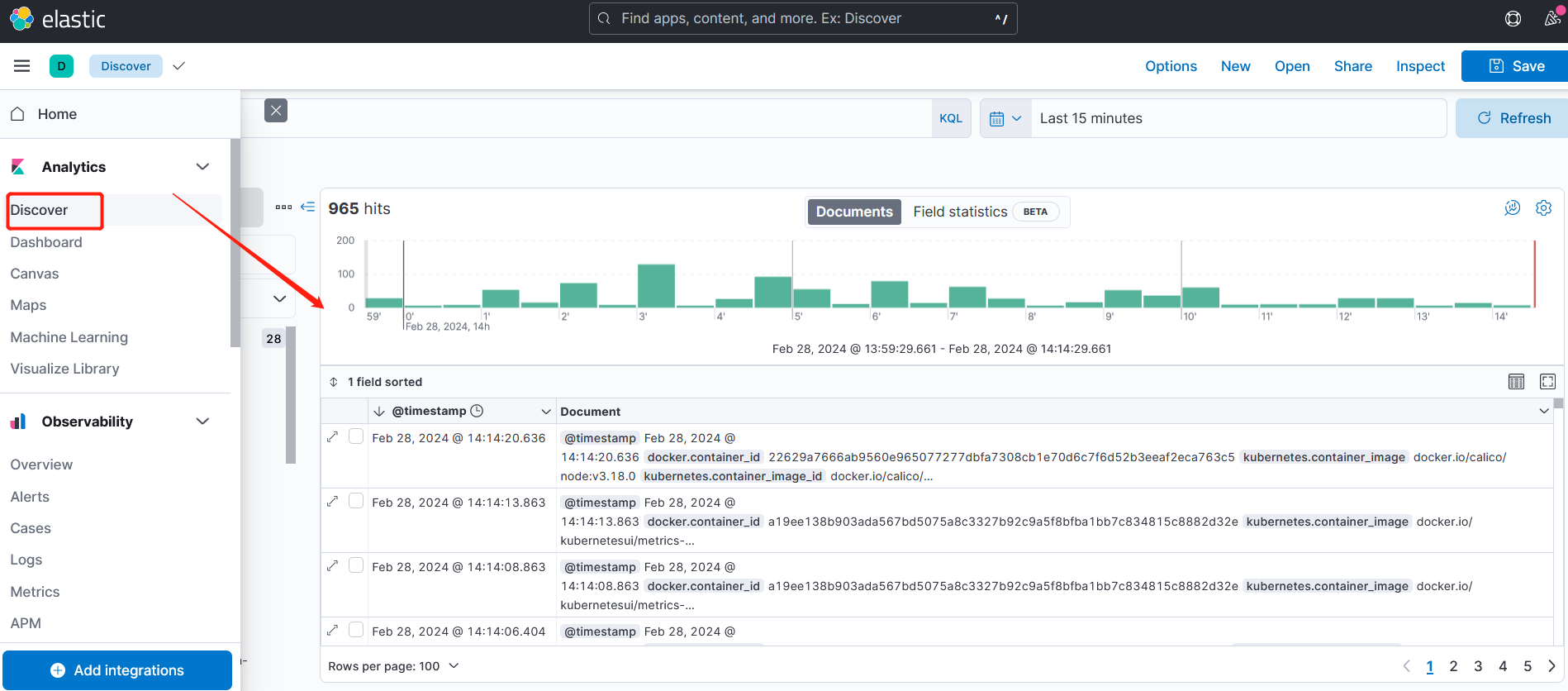
3.4、测试收集pod容器日志
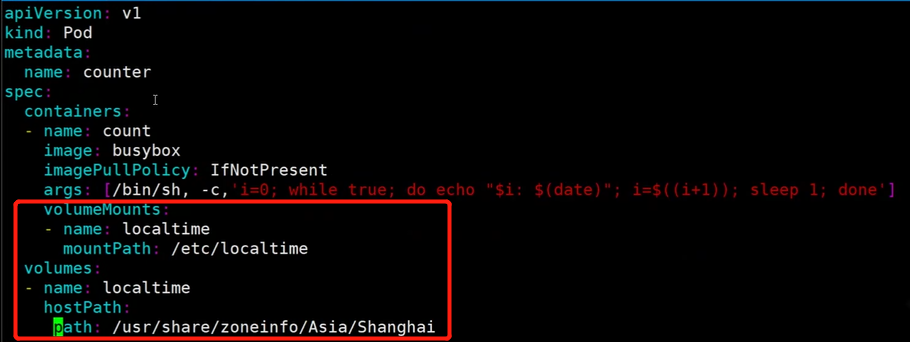
[root@master 4]# cat pod.yaml
apiVersion: v1
kind: Pod
metadata:name: counter#namespace: kube-logging
spec:containers:- name: countimage: busyboximagePullPolicy: IfNotPresentargs: [/bin/sh, -c,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 60; done']
[root@master 4]# kubectl apply -f pod.yaml
pod/counter createdKibana查询语言KQL官方地址:
https://www.elastic.co/guide/en/kibana/7.2/kuery-query.html
登录到kibana的控制面板,在discover处的搜索栏中输入kubernetes.pod_name:counter,这将过滤名为的Pod的日志数据counter,如下所示:
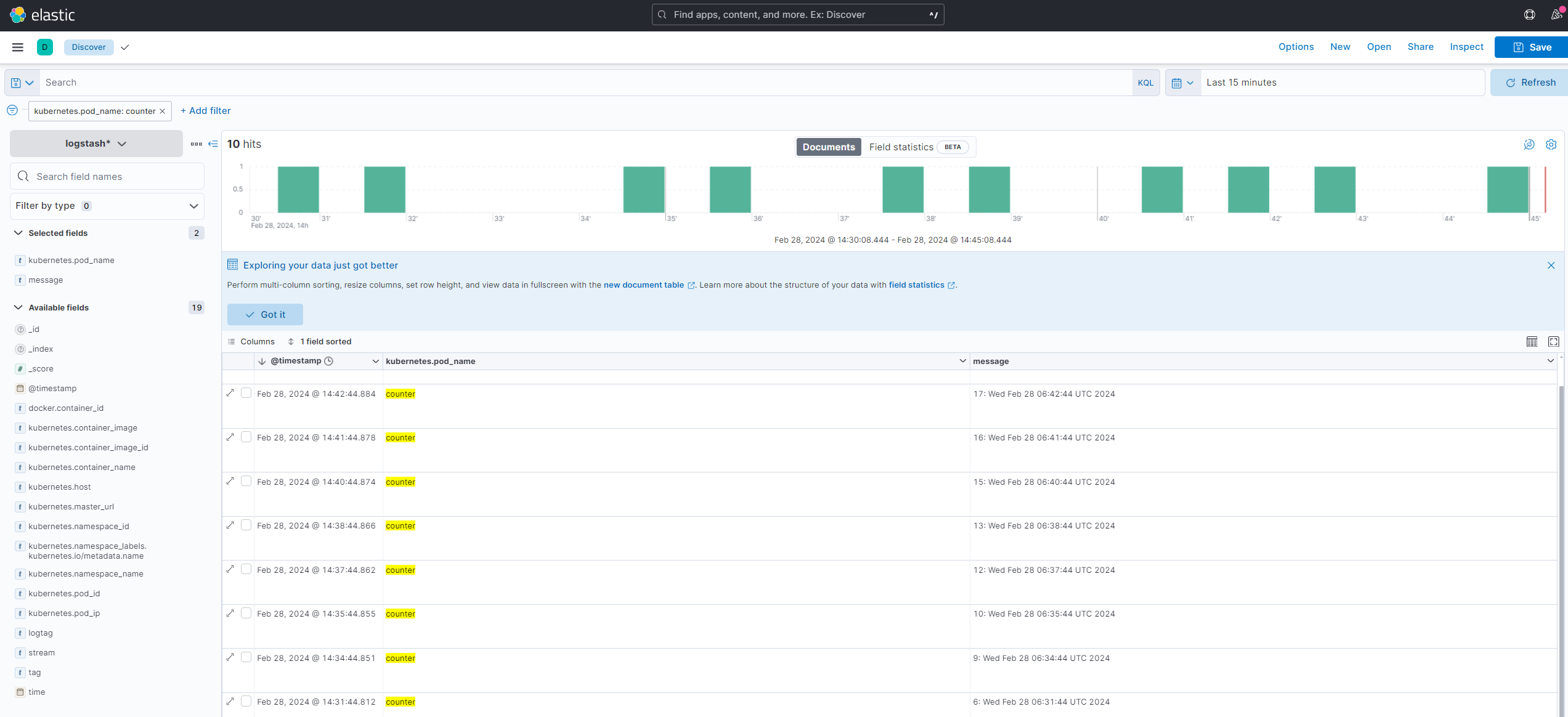
此时日志中的时间是不准确的,需要调整。
pod.yaml调整后可正常显示