ActiveMQ持久化
- 一、MQ的高可用
- 二、持久化介绍
- 三、持久化存储方式
- 1.AMQ Mesage Store(了解)
- 2.KahaDB消息存储(默认)
- 2.1 存储原理
- 3.JDBC消息存储
- 4.LevelDB消息存储(了解)
- 5.JDBC Message Store with ActiveMQ Journal
- 查询持久化存储方式
- 四、持久化存储使用
- 1.JDBC消息存储
- 1.1 选择方案
- 1.2 添加mysql数据库驱动
- 1.3 jdbcPersistenceAdapter配置
- 1.4 数据库连接池配置
- 1.5 建库SQL和创表说明
- 1.6 代码运行
- 1.7 小总结
- 1.8 开发的坑
- 2.JDBC Message Store with ActiveMQ Journal
- 2.1 配置文件配置
- 2.2 数据库连接池配置
- 2.3 总结
一、MQ的高可用
- MQ自带:
- 事务
- 持久
- 签收
- MQ非自带:可持久化
二、持久化介绍
- ActiveMQ宕机了,消息不会丢失的机制。
- 为了避免意外宕机以后丢失信息,需要做到重启后可以恢复消息队列,消息系统一般都会采用
持久化机制。 - ActiveMQ的消息持久化机制有JDBC,AMQ,KahaDB和LevelDB,无论使用哪种持久化方式,消息的存储逻辑都是一致的。
- 就是在发送者将消息发送出去后,消息中心首先将消息存储到本地数据文件、内存数据库或者远程数据库等。再试图将消息发给接收者,成功则将消息从存储中删除,失败则继续尝试尝试发送。
- 消息中心启动以后,要先检查指定的存储位置是否有未成功发送的消息,如果有,则会先把存储位置中的消息发出去。
三、持久化存储方式
1.AMQ Mesage Store(了解)
- 官网地址:https://activemq.apache.org/components/classic/documentation/amq-message-store
- AMQ是一种文件存储形式,它具有写入速度快和容易恢复的特点。消息存储再一个个文件中文件的默认大小为32M,当一个文件中的消息已经全部被消费,那么这个文件将被标识为可删除,在下一个清除阶段,这个文件被删除。
注意:AMQ适用于ActiveMQ5.3之前的版本
2.KahaDB消息存储(默认)
- 官网地址:https://activemq.apache.org/components/classic/documentation/kahadb
- 基于日志文件(类似redis的AOF),从ActiveMQ5.4开始默认的持久化插件
- KahaDB是目前默认的存储方式,可用于任何场景,提高了性能和恢复能力。
消息存储使用一个事务日志和仅仅用一个索引文件来存储它所有的地址。- KahaDB是一个专门针对消息持久化的解决方案,它对典型的消息使用模型进行了优化。
- 数据被追加到data logs中。当不再需要log文件中的数据的时候,log文件会被丢弃
2.1 存储原理
- KahaDB在消息保存的目录中有4类文件和一个lock,跟ActiveMQ的其他几种文件存储引擎相比,这就非常简洁了。
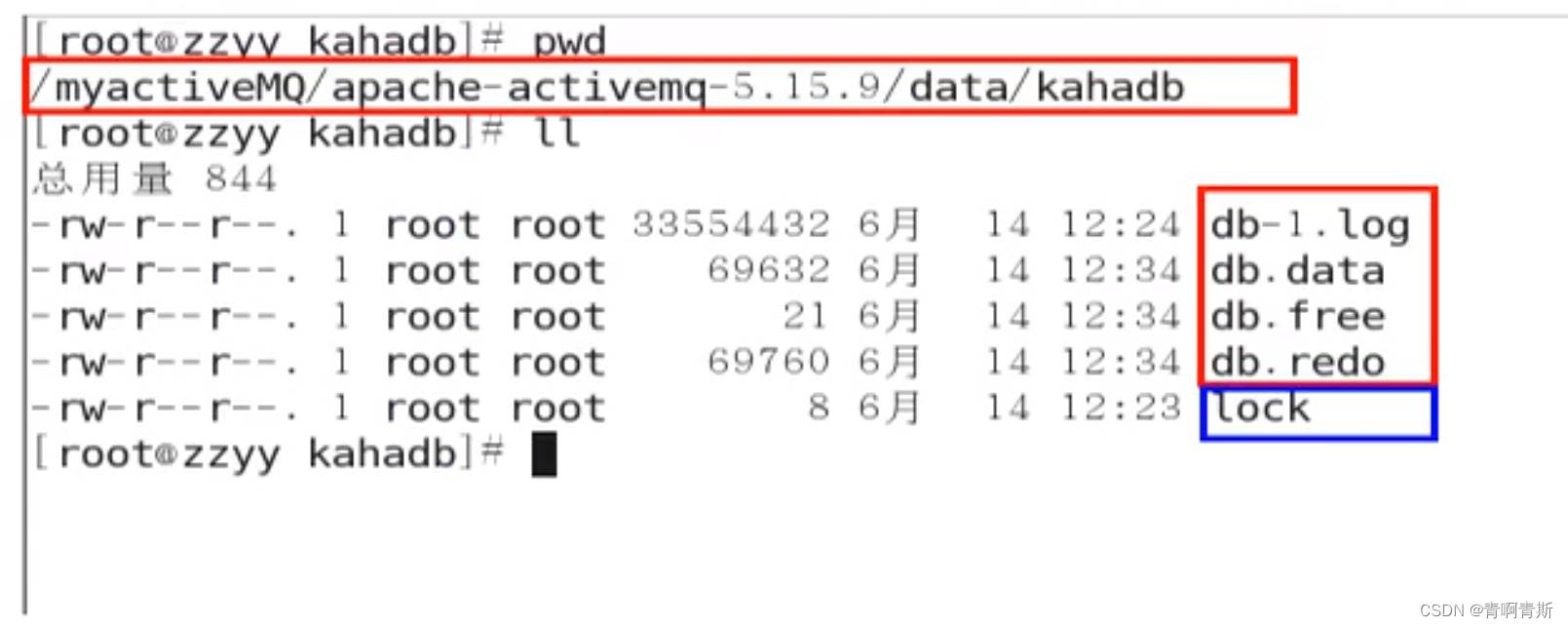
- db-number.log
- KahaDB存储消息到预定大小的数据纪录文件中,文件名为db-number.log。当数据文件已满时,一个新的文件会随之创建,number数值也会随之递增,它随着消息数量的增多,如没32M一个文件,文件名按照数字进行编号,如db-1.log,db-2.log······。当不再有引用到数据文件中的任何消息时,文件会被删除或者归档。
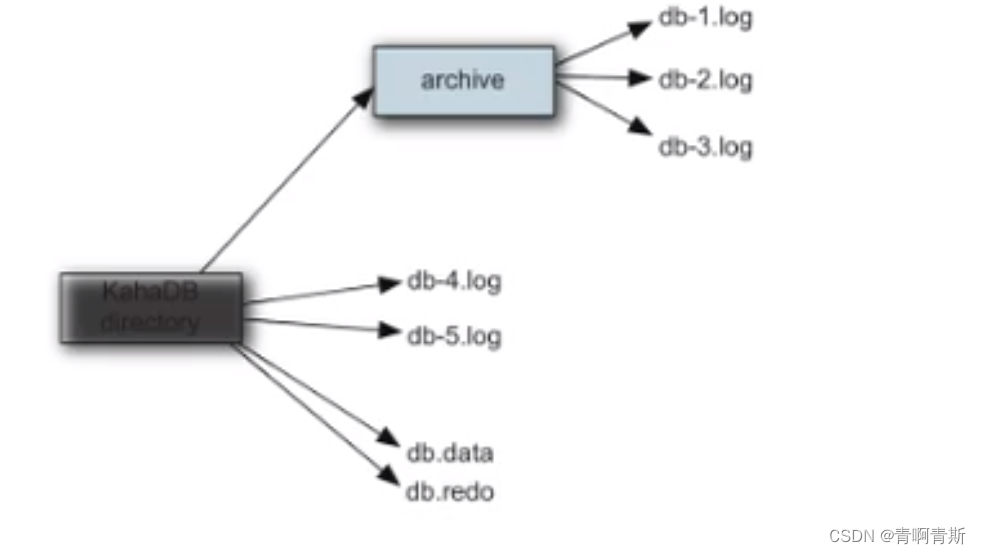
- KahaDB存储消息到预定大小的数据纪录文件中,文件名为db-number.log。当数据文件已满时,一个新的文件会随之创建,number数值也会随之递增,它随着消息数量的增多,如没32M一个文件,文件名按照数字进行编号,如db-1.log,db-2.log······。当不再有引用到数据文件中的任何消息时,文件会被删除或者归档。
- db.data:该文件包含了持久化的BTree索引,索引了消息数据记录中的消息,它是消息的索引文件,本质上是B-Tree(B树),使用B-Tree作为索引指向db-number。log里面存储消息。
- db.free:当问当前db.data文件里面哪些页面是空闲的,文件具体内容是所有空闲页的ID
- db.redo:用来进行消息恢复,如果KahaDB消息存储再强制退出后启动,用于恢复BTree索引。
- lock:文件锁,表示当前kahadb独写权限的broker。
3.JDBC消息存储
- 消息基于JDBC存储的
4.LevelDB消息存储(了解)
- 官网地址:https://activemq.apache.org/components/classic/documentation/leveldb-store
这个数据库,在5.17版本被移除了- 这种文件系统是从ActiveMQ5.8之后引进的,它和KahaDB非常相似,也是基于文件的本地数据库存储形式,但是它提供比KahaDB更快的持久性。
- 但它不使用自定义B-Tree实现来索引独写日志,而是使用基于LevelDB的索引
5.JDBC Message Store with ActiveMQ Journal
查询持久化存储方式
- 打开 conf/activemq.xml
四、持久化存储使用
1.JDBC消息存储
1.1 选择方案
- MQ+MySQL
- https://activemq.apache.org/components/classic/documentation/persistence
1.2 添加mysql数据库驱动
- 添加mysql数据库的驱动包到lib文件夹
- 我的MySQL是8.0.30
# 1.进入activemq的lib目录
cd /data/activemq/apache-activemq-5.15.9/lib
# 2.下载mysql驱动
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar
1.3 jdbcPersistenceAdapter配置
vi /data/activemq/apache-activemq-5.15.9/conf/activemq.xml
# 复制以下内容<persistenceAdapter> <jdbcPersistenceAdapter dataSource="#mysql-ds" createTableOnStartup="true"/> </persistenceAdapter>
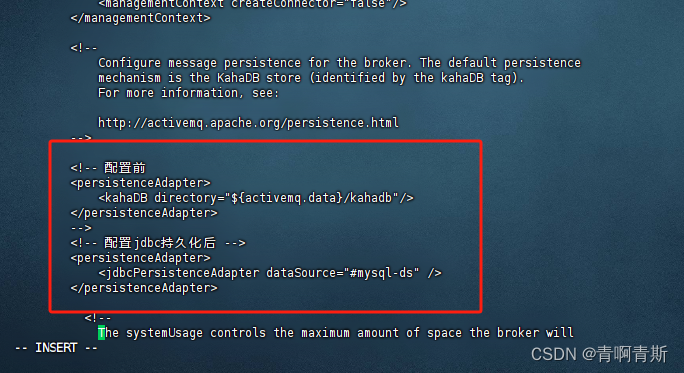
- 参数解释:
dataSource是指定将要引用的持久化数据库的bean名称。createTableOnStartup是否在启动的时候创建数据库表,默认是true,这样每次启动都会去创建表了,一般是第一次启动的时候设置为true,然后再去改成false。
1.4 数据库连接池配置
# 1.在mq的配置文件加入以下内容<bean id="mysql-ds" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close"><property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/><property name="url" value="jdbc:mysql://192.168.86.128:3306/activemq?relaxAutoCommit=true"/><property name="username" value="root"/><property name="password" value="qwe123"/><property name="poolPreparedStatements" value="true"/></bean>

1.5 建库SQL和创表说明
# 创建activemq持久化库
CREATE DATABASE activemq;
重启mq
./activemq stop && ./activemq start
- 重启后,MySQL数据库会创建3个表:
- ACTIVEMQ_MSGS:消息表,缺省表名ACTIVEMQ_MSGS,Queue和Topic都存在里面,结构如下
- ID:自增的数据库主键
- CONTAINER:消息的Destination
- MSGID_PROD:消息发送者的主键
- MSG_SEQ:是发送消息的顺序,MSGID_PROD+MSG_SEQ可以组成JMS的MessageID
- EXPIRATION:消息的过期时间,存储的是从1970-01-01到现在的毫秒数
- MSG:消息本体的Java序列化对象的二进制数据
- PRIORITY:优先级,从0-9,数值越大优先级越高
- ACTIVEMQ_ACKS:这个表用于存储消息的确认信息(Acknowledgements)。当消费者消费消息并发送确认时,确认信息会被记录在 ACTIVEMQ_ACKS 表中。这些确认信息可以帮助 ActiveMQ 跟踪哪些消息已经被成功消费,哪些消息还需要继续传递。
- ACTIVEMQ_LOCK:ACTIVEMQ_LOCK在集群环境下才有用,只有一个Broker可以获取消息,称为Master Broker,其他的只能作为备份等待Master Broker不可用,才可能成为下一个Master Broker。这个表用于记录哪个Broker是当前的Master Broker
# 注意:如果表没有生成,那么在activemq数据库执行以下语句
-- auto-generated definition
create table ACTIVEMQ_ACKS
(CONTAINER varchar(250) not null comment '消息的Destination',SUB_DEST varchar(250) null comment '如果使用的是Static集群,这个字段会有集群其他系统的信息',CLIENT_ID varchar(250) not null comment '每个订阅者都必须有一个唯一的客户端ID用以区分',SUB_NAME varchar(250) not null comment '订阅者名称',SELECTOR varchar(250) null comment '选择器,可以选择只消费满足条件的消息,条件可以用自定义属性实现,可支持多属性AND和OR操作',LAST_ACKED_ID bigint null comment '记录消费过消息的ID',PRIORITY bigint default 5 not null comment '优先级,默认5',XID varchar(250) null,primary key (CONTAINER, CLIENT_ID, SUB_NAME, PRIORITY)
)comment '用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存';create index ACTIVEMQ_ACKS_XIDXon ACTIVEMQ_ACKS (XID);-- auto-generated definition
create table ACTIVEMQ_LOCK
(ID bigint not nullprimary key,TIME bigint null,BROKER_NAME varchar(250) null
);-- auto-generated definition
create table ACTIVEMQ_MSGS
(ID bigint not nullprimary key,CONTAINER varchar(250) not null,MSGID_PROD varchar(250) null,MSGID_SEQ bigint null,EXPIRATION bigint null,MSG blob null,PRIORITY bigint null,XID varchar(250) null
);create index ACTIVEMQ_MSGS_CIDXon ACTIVEMQ_MSGS (CONTAINER);create index ACTIVEMQ_MSGS_EIDXon ACTIVEMQ_MSGS (EXPIRATION);create index ACTIVEMQ_MSGS_MIDXon ACTIVEMQ_MSGS (MSGID_PROD, MSGID_SEQ);create index ACTIVEMQ_MSGS_PIDXon ACTIVEMQ_MSGS (PRIORITY);create index ACTIVEMQ_MSGS_XIDXon ACTIVEMQ_MSGS (XID);
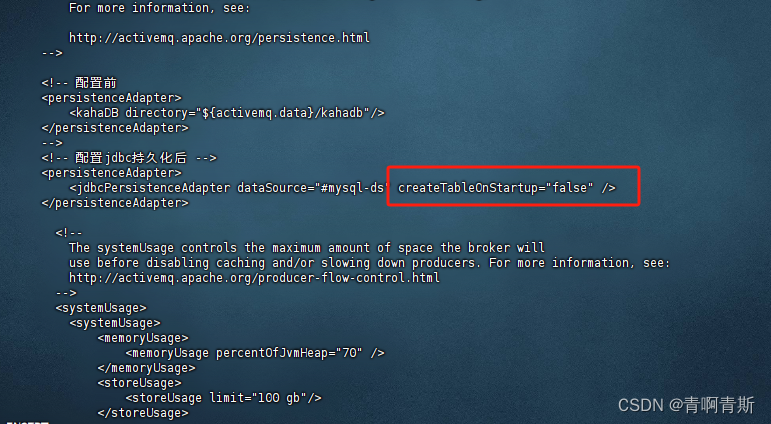
将createTableOnStartup设置为false
- 防止下次重启,重复执行建表语句
1.6 代码运行
- 生产者代码里面一定要开启持久化
- 持久化主要是针对生产者,消费者的代码不需要额外添加东西。
- 下面是生产者队列,对于topic是一样的。
package com.qingsi.activemq;import org.apache.activemq.ActiveMQConnectionFactory;import javax.jms.*;public class JmsProduce {public static final String ACTIVEMQ_URL = "nio://192.168.86.128:61616";public static final String QUEUE_NAME = "jdbc01";public static void main(String[] args) throws JMSException {//1.创建连接工厂,按照给定的URL,采用默认的用户名密码ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(ACTIVEMQ_URL);//2.通过连接工厂,获得connection并启动访问Connection connection = activeMQConnectionFactory.createConnection();connection.start();//3.创建会话session//两个参数transacted=事务,acknowledgeMode=确认模式(签收)//开启事务需要commitSession session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);//4.创建目的地(具体是队列queue还是主题topic)Queue queue = session.createQueue(QUEUE_NAME);//5.创建消息的生产者,并设置不持久化消息MessageProducer producer = session.createProducer(queue);// 开启持久化存储producer.setDeliveryMode(DeliveryMode.PERSISTENT);//6.通过使用消息生产者,生产三条消息,发送到MQ的队列里面// 7.发送消息for (int i = 0; i < 3; i++) {TextMessage textMessage = session.createTextMessage("jdbc msg--" + i);producer.send(textMessage);}//8.关闭资源producer.close();session.close();connection.close();}}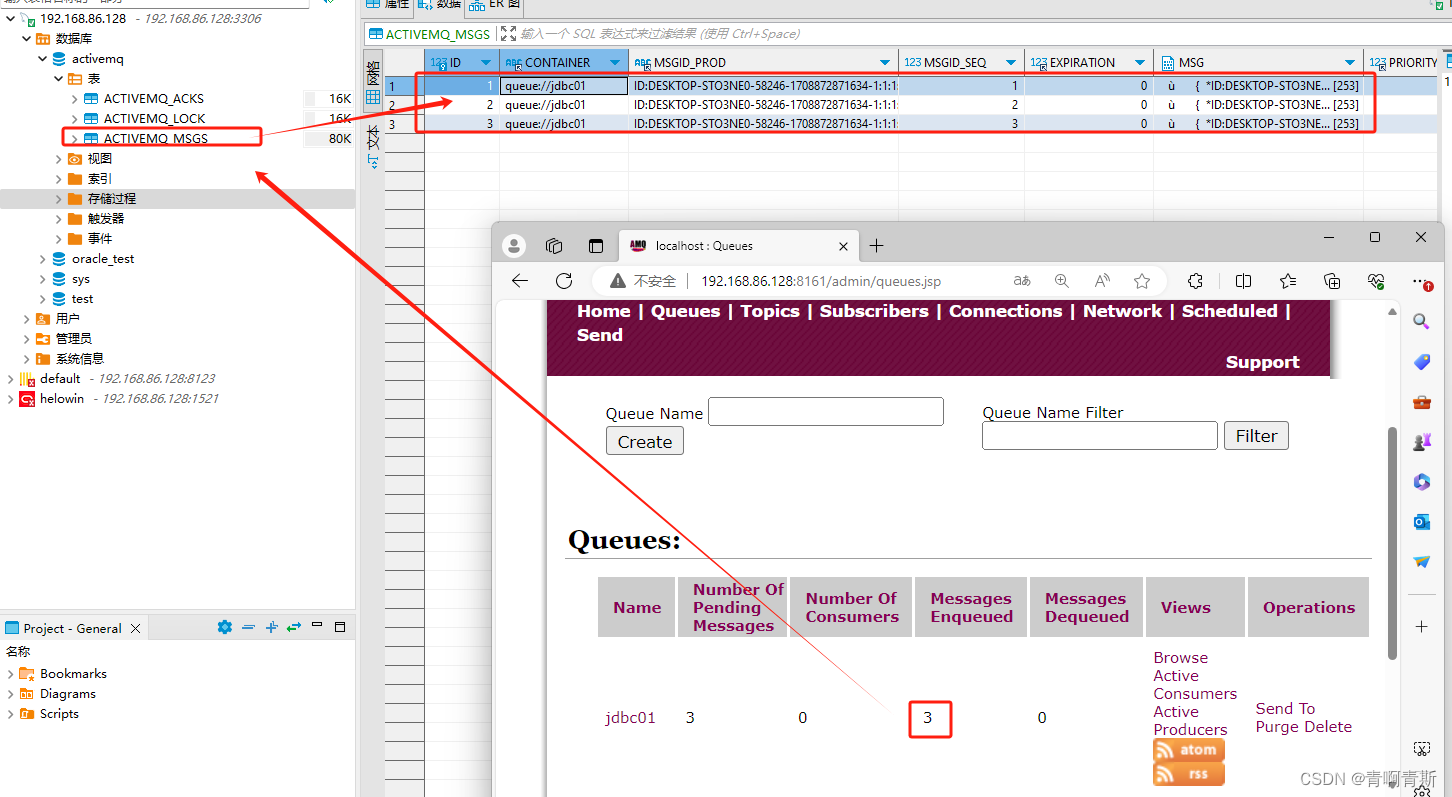
1.7 小总结
- 如果是queue:在没有消费者消费的情况下会将消息保存到activemq_msgs表中,
只要有任意一个消费者消费了,就会删除消费过的消息 - 如果是topic:一般是先启动消费订阅者然后再生产的情况下会将持久订阅者
永久保存到qctivemq_acks,而消息则永久保存在activemq_msgs,在acks表中的订阅者有一个last_ack_id对应了activemq_msgs中的id字段,这样就知道订阅者最后收到的消息是哪一条。
1.8 开发的坑
- 在配置关系型数据库作为ActiveMQ的持久化存储方案时,有坑
- 数据库jar包:注意把对应版本的数据库jar或者你自己使用的非自带的数据库连接池jar包
- createTablesOnStartup属性:默认为true,每次启动activemq都会自动创建表,在第一次启动后,应改为false,避免不必要的损失。
- java.lang.IllegalStateException: LifecycleProcessor not initialized:确认计算机主机名名称没有下划线。如果有下划线,就要更改机器名并且重启即可。
2.JDBC Message Store with ActiveMQ Journal
- 这种方式克服了JDBC Store的不足,JDBC每次消息过来,都需要去写库读库。
- ActiveMQ Journal,使用高速缓存写入技术,大大提高了性能。
- 当消费者的速度能够及时跟上生产者消息的生产速度时,journal文件能够大大减少需要写入到DB中的消息。
- 举个例子:生产者生产了1000条消息,这1000条消息会保存到journal文件,如果消费者的消费速度很快的情况下,在journal文件还没有同步到DB之前,消费者已经消费了90%的以上消息,那么这个时候只需要同步剩余的10%的消息到DB。如果消费者的速度很慢,这个时候journal文件可以使消息以批量方式写到DB。
注意:不会马上写入数据库
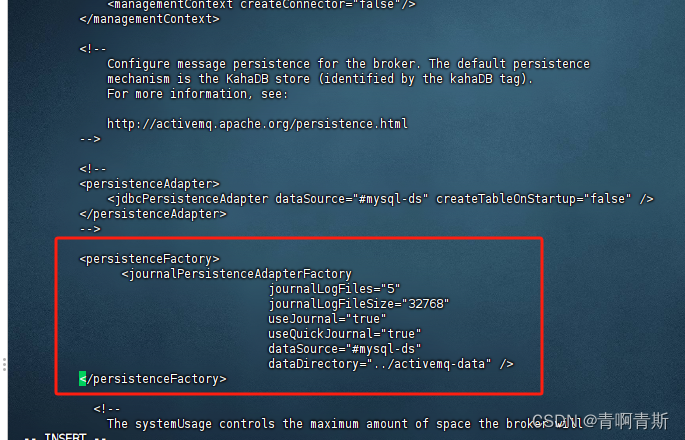
2.1 配置文件配置
vi /data/activemq/apache-activemq-5.15.9/conf/activemq.xml
# 复制以下内容<persistenceFactory><journalPersistenceAdapterFactoryjournalLogFiles="5"journalLogFileSize="32768" useJournal="true" useQuickJournal="true" dataSource="#mysql-ds"dataDirectory="../activemq-data" /></persistenceFactory>
2.2 数据库连接池配置
# 1.在mq的配置文件加入以下内容<bean id="mysql-ds" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close"><property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/><property name="url" value="jdbc:mysql://192.168.86.128:3306/activemq?relaxAutoCommit=true"/><property name="username" value="root"/><property name="password" value="qwe123"/><property name="poolPreparedStatements" value="true"/></bean>
./activemq stop && ./activemq start
2.3 总结
- 持久化消息主要指的是:MQ所在服务器宕机了消息不会丢试的机制。
- 持久化机制演变的过程:从最初的AMQ Message Store方案到ActiveMQ V4版本退出的High Performance Journal(高性能事务支持)附件,并且同步推出了关于关系型数据库的存储方案。ActiveMQ5.3版本又推出了对KahaDB的支持(5.4版本后被作为默认的持久化方案),后来ActiveMQ 5.8版本开始支持LevelDB,到现在5.9提供了标准的Zookeeper+LevelDB集群化方案。
- ActiveMQ消息持久化机制有:
- AMQ 基于日志文件
- KahaDB 基于日志文件,从ActiveMQ5.4开始默认使用
- JDBC 基于第三方数据库
- Replicated LevelDB Store 从5.9开始提供了LevelDB和Zookeeper的数据复制方法,用于Master-slave方式的首选数据复制方案。