context_switch函数完成Arm架构Linux进程切换,调用两个函数:
- 调用switch_mm() 完成用户空间切换,刷新I-CACHE,处理ASID和TLB,页表转换基址切换(即把TTBR0寄存器的值设置为新进程的PGD);
- 调用switch_to() 完成内核栈及寄存器切换,分为保存现场和切换到下一个进程运行去运行。其实ARM体系架构中涉及进程切换的寄存器只包含r4-r9,sl,fp,sp和pc寄存器。(不像x86还要涉及到gdt,ldt,TSS)
a.先将上一个进程的r4 - sl, fp, sp, lr寄存器中的内容保存到IP寄存器所指向的内存地址,这叫保持现场。
b.然后将需要运行的进程的值加载到r4 - sl, fp, sp, lr,pc寄存器中,这叫跳转到下一个进程运行去运行。sp存入寄存器SP相当于内核栈切换完成,pc存入寄存器PC相当于跳转到next进程运行。
原文如下
《深入Linux内核(进程篇)—进程切换之ARM体系架构》
https://blog.csdn.net/liyuewuwunaile/article/details/106773630
进程切换
进程切换由两部分组成:
- 切换页全局目录安装一个新的地址空间;
- 切换内核态堆栈及硬件上下文。
一、context_switch
Linux内核中由context_switch实现了上述两部分内容。
调用switch_mm完成用户空间切换;
调用switch_to完成内核栈及寄存器切换。
具体实现流程:
通过进程描述符next->mm是否为空判断当前进程是否是内核线程,因为内核线程的内存描述符mm_struct
*mm总是为空,详见《深入Linux内核(进程篇)—进程描述》内存描述一节。
如果是内核线程则借用prev进程的active_mm,对于用户进程,active_mm == mm,对于内核线程,mm = NULL,active_mm = prev->active_mm。
如果prev->mm不为空,则说明prev是用户进程,调用mmgrab增加mm->mm_count引用计数。
对于内核线程,会启动懒惰TLB模式。懒惰TLB模式是为了减少无用的TLB刷新,关于TLB的内容详见《深入Linux内核(内存篇)–页表映射》TLB一节。enter_lazy_tlb与体系结构相关。
如果是用户进程则调用switch_mm_irqs_off完成用户地址空间切换,switch_mm_irqs_off(或switch_mm)与体系结构相关。
调用switch_to完成内核态堆栈及硬件上下文切换,switch_to与体系结构相关。
switch_to执行完成后,next进程获得CPU使用权,prev进程进入睡眠状态。
调用finish_task_switch,如果prev是内核线程,则调用mmdrop减少内存描述符引用计数。如果引用计数为0,则释放与页表相关的所有描述符和虚拟内存。
/** context_switch - switch to the new MM and the new thread's register state.*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,struct task_struct *next, struct rq_flags *rf)
{/* 进程切换的准备工作 */prepare_task_switch(rq, prev, next);/** For paravirt, this is coupled with an exit in switch_to to* combine the page table reload and the switch backend into* one hypercall.*/arch_start_context_switch(prev);/** kernel -> kernel lazy + transfer active* user -> kernel lazy + mmgrab() active** kernel -> user switch + mmdrop() active* user -> user switch*/if (!next->mm) { // to kernelenter_lazy_tlb(prev->active_mm, next);next->active_mm = prev->active_mm;if (prev->mm) // from usermmgrab(prev->active_mm);elseprev->active_mm = NULL;} else { // to usermembarrier_switch_mm(rq, prev->active_mm, next->mm);/** sys_membarrier() requires an smp_mb() between setting* rq->curr / membarrier_switch_mm() and returning to userspace.** The below provides this either through switch_mm(), or in* case 'prev->active_mm == next->mm' through* finish_task_switch()'s mmdrop().*//* 调用switch_mm_irqs_off完成用户地址空间切换 */switch_mm_irqs_off(prev->active_mm, next->mm, next);if (!prev->mm) { // from kernel/* will mmdrop() in finish_task_switch(). */rq->prev_mm = prev->active_mm;prev->active_mm = NULL;}}rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);prepare_lock_switch(rq, next, rf);/* Here we just switch the register state and the stack. *//* 调用switch_to完成内核态堆栈及硬件上下文切换 */switch_to(prev, next, prev);barrier();return finish_task_switch(prev);
}
二、switch_mm
对于用户进程需要完成用户空间的切换,switch_mm函数完成了这个任务。switch_mm是与体系架构相关的函数。下面以ARM体系架构说明用户空间的切换过程。
Linux5.6.4内核调用switch_mm_irqs_off切换用户进程空间,对于没有定义该函数的架构,则调用的是switch_mm。X86体系架构定义了switch_mm_irqs_off函数,ARM体系架构没有定义。
#ifndef switch_mm_irqs_off
# define switch_mm_irqs_off switch_mm
#endif
本文只关心ARM体系架构。ARM进程地址空间的切换实际是设置页表基址寄存器TTBR0的过程,对于每个进程拥有系统全部的虚拟地址空间,但是其并没有占用所以的物理地址,物理地址的访问需要页表转换完成,页表转换的基址存放在页表基址寄存器TTBR0中,每个进程都有一套自己的映射页表存放在物理内存(实际最初并不是所以的页表都存放到内存里,而是发生缺页异常时才将页表写入物理内存),TTBR0指示了进程PGD页表基址,PGD指示了PTE页表基址,PTE指示了物理地址PA。每个进程的PGD不同,因而不同进程虚拟内存对于的物理地址就隔离开了。进程切换switch_mm实质上就是完成TTBR0寄存器的改写。
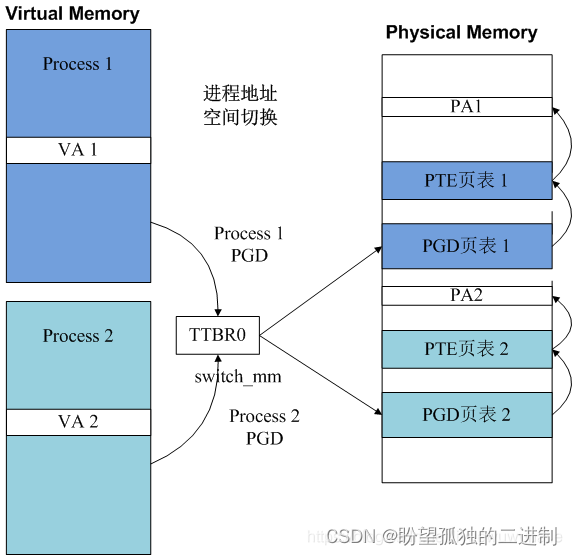
ARMv7体系架构switch_mm实现如下。由上图分析可知,switch_mm函数实质是将新进程的页表基址设置到也目录表基地址寄存器中,对于ARMv7即协处理器cp15的TTBR0寄存器。
/** This is the actual mm switch as far as the scheduler* is concerned. No registers are touched. We avoid* calling the CPU specific function when the mm hasn't* actually changed.*/
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,struct task_struct *tsk)
{
#ifdef CONFIG_MMUunsigned int cpu = smp_processor_id();/** __sync_icache_dcache doesn't broadcast the I-cache invalidation,* so check for possible thread migration and invalidate the I-cache* if we're new to this CPU.*/if (cache_ops_need_broadcast() &&!cpumask_empty(mm_cpumask(next)) &&!cpumask_test_cpu(cpu, mm_cpumask(next)))__flush_icache_all(); /* 刷新CPU Core所有I-Cache *//* 将当前CPU设置到next进程的cpumask位图 */if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next) {/* 处理TLB及切换进程页表映射地址TTBR0 */check_and_switch_context(next, tsk);if (cache_is_vivt())cpumask_clear_cpu(cpu, mm_cpumask(prev));}
#endif
}
2.1 刷新I-CACHE
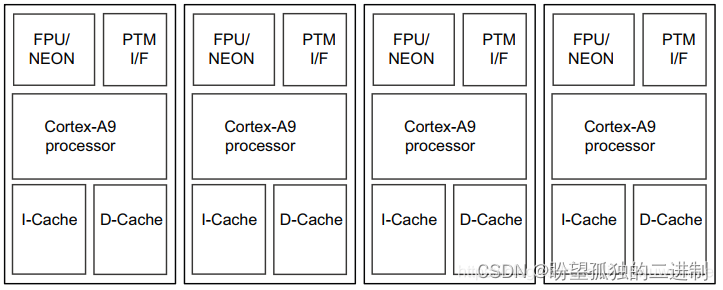
如果next进程发生迁移,在一个新的CPU上执行,则需要flush I-Cache(Instructions Cache)。如下图所示,对于ARM SMP架构来说每个core都有独立的I-Cache和D-Cache(哈佛结构L1 Cache),因而新进程第一次运行到某Core时需要将I-Cache内容全部刷新。
__flush_icache_all函数实现了I-Cache刷新,flush I-Cache是通过访问协处理器cp15的c7寄存器实现的。
/* Invalidate I-cache inner shareable */
/* 将cp15协处理器c7寄存器ICIALLUIS */
#define __flush_icache_all_v7_smp() \asm("mcr p15, 0, %0, c7, c1, 0" \: : "r" (0));
static inline void __flush_icache_all(void)
{__flush_icache_preferred();dsb(ishst);
}
CP15协处理器保护c0-c15共16个寄存器,寄存器32位的组织形式如下:

对于汇编语句“mcr p15, 0, %0, c7, c1, 0”指示四个操作数结果如下:

CRn:第一个协处理器寄存器c7;
opc1:协处理器操作码0;
CRm:第二个协处理器寄存器c1;
opc2:协处理器操作码0。
因而对应ICIALLUIS (Invalidate all instruction caches Inner Shareable to PoU)寄存器。

2.2 ASID和TLB
check_and_switch_context完成了进程地址空间的切换,这包括两部分内容:
ASID和TLB的处理;
TTBR处理。
本节关注switch_mm中关于ASID和TLB的处理。
ASID即Address Space ID,TLB即Translation Lookaside Buffer。
MMU在做Table Walk时,需要访问物理内存中的页表映射,每一级页表映射都需要访问一次内存,而内存的访问对性能影响很大,因而效率很低。TLB是用于缓存MMU地址转换结果的cache,显然访问cache找到物理地址比访问内存找物理地址快的多,因而TLB加快内存的访问效率。
ARMv7架构TLB结构如下图所示,TLB entry中缓存了VA(虚拟地址),PA(物理地址),Attr(cache策略,访问权限等属性)和ASID(地址空间ID)。
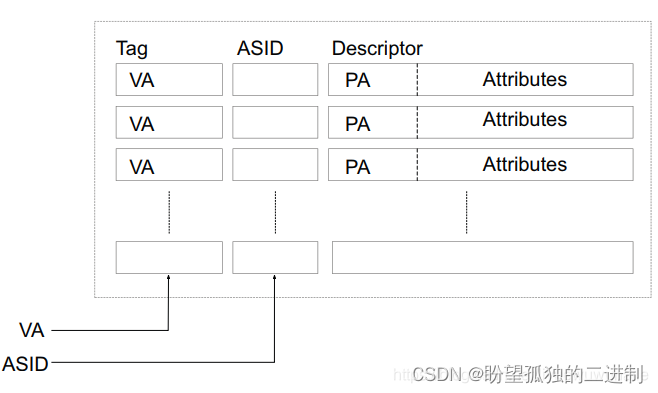
VA和PA很好理解,即物理地址和虚拟地址映射关系。Attr用来指示TLB entry属性。ASID用来干甚?
TLB缓存了地址映射关系,不同进程拥有不同的地址映射页表,因而进程切换时,TLB缓存的前一个进程的地址映射关系不能用于新进程,一个简单的办法是将TLB entry全部刷新,这导致TLB使用效率大打折扣,A和B两个进程相互切换时,每次切换后都将面对一个空白的TLB,TLB miss大大增加,显然这种方法不够完美。
ASID指示了每个TLB entry所属的进程,这样可以保证不同进程之间的TLB entry不会互相干扰,因而避免了切换进程时将TLB刷新的问题。所以ASID作用避免了进程切换时TLB的频繁刷新。
实际上,ARM TLB包含了Global和process-specific表项。
Global类型TLB entry:用于内核空间地址转换,内核空间为所以进程所共有,因而进程切换时,内核映射关系无需变化,所以其TLB entry也不用变。内核的页表基址寄存器是TTBR1,进程切换时页表不变的。
process-specific类型TLB entry:用户进程独立地址空间映射关系。即ASID用于隔离不同进程的TLB entry。
区分Global和process-specific表项则是根据PTE entry的bit11(nG位)。nG位为1时,则表示TLB entry属于进程。

check_and_switch_context函数前面部分主要实现了ASID相关的内容。
将TTBR1的内容设置到TTBR0。pgd和ASID的更新不能原子的完成,因而避免错误的映射,先将TTBR0设置成TTBR1;
从mm->context.id原子的获取ASID;
asid_generation记录ASID溢出,mm->context.id低8位记录ASID,高24位记录了ASID溢出次数,如果没有发生ASID溢出则直接调用cpu_switch_mm切换TTBR0。
如果发生ASID溢出则需要为进程重新分配ASID,并刷新TLB。
void check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)
{unsigned long flags;unsigned int cpu = smp_processor_id();u64 asid;if (unlikely(mm->context.vmalloc_seq != init_mm.context.vmalloc_seq))__check_vmalloc_seq(mm);/** We cannot update the pgd and the ASID atomicly with classic* MMU, so switch exclusively to global mappings to avoid* speculative page table walking with the wrong TTBR.*/cpu_set_reserved_ttbr0();/* 将TTBR1的内容设置到TTBR0 */asid = atomic64_read(&mm->context.id);/* 获取进程ASID *//* ASID没有发生溢出,不用关系TLB,直接跳到cpu_switch_mm切换TTBR0即可 */if (!((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS)&& atomic64_xchg(&per_cpu(active_asids, cpu), asid))goto switch_mm_fastpath;raw_spin_lock_irqsave(&cpu_asid_lock, flags);/* Check that our ASID belongs to the current generation. *//* ASID发生溢出,调用new_context为进程重新分配ASID,并记录到mm->context.id中 */asid = atomic64_read(&mm->context.id);if ((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS) {asid = new_context(mm, cpu);atomic64_set(&mm->context.id, asid);}/* ASID发生溢出,刷新TLB */if (cpumask_test_and_clear_cpu(cpu, &tlb_flush_pending)) {local_flush_bp_all(); /* 指令cache刷新 */local_flush_tlb_all(); /* TLB刷新 */}atomic64_set(&per_cpu(active_asids, cpu), asid);cpumask_set_cpu(cpu, mm_cpumask(mm));raw_spin_unlock_irqrestore(&cpu_asid_lock, flags);switch_mm_fastpath:cpu_switch_mm(mm->pgd, mm); /* 页表基址寄存器TTBR0切换 */
}
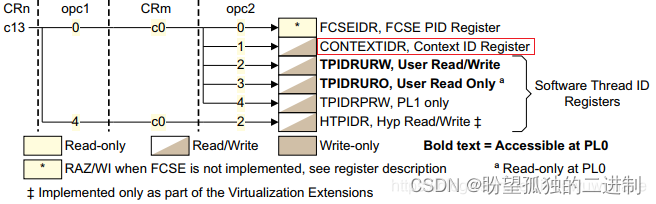
ASID为什么只有8bit,这是由 CONTEXTIDR(Context ID Register)寄存器决定的。cpu_switch_mm除了设置TTBR0寄存器外,还会设置CONTEXTIDR寄存器,3.3章节也会讲到该寄存器。
如下图所示,未开启LAPE功能时,CONTEXTIDR的[7:0]是ASID,因而ASID只有8bit,256个ASID分配完后,需要重新分配。

local_flush_tlb_all完成TLB刷新。
static inline void local_flush_tlb_all(void)
{const int zero = 0;const unsigned int __tlb_flag = __cpu_tlb_flags;if (tlb_flag(TLB_WB))dsb(nshst);__local_flush_tlb_all();tlb_op(TLB_V7_UIS_FULL, "c8, c7, 0", zero);if (tlb_flag(TLB_BARRIER)) {dsb(nsh);isb();}
}
tlb_op操作使用协处理器指令MCR操作CP15的寄存器。
“c8, c7, 0” 指示协处理器指令。根据3.1节中关于协处理器指令的描述,可以知道。
CRn:第一个协处理器寄存器c8;
opc1:协处理器操作码0;
CRm:第二个协处理器寄存器c7;
opc2:协处理器操作码1。
因而对应TLBIALL(invalidate unified TLB)寄存器,即将TLB entry全部刷新。

2.3 页表转换基址切换
进程切换需要切换进程地址空间,每个进程都拥有全部的虚拟地址空间,而物理地址空间是隔离的,操作系统能够实现这种内存策略,依靠的是芯片级的地址转换功能,也就是MMU(Memory Management Unit)。MMU完成了虚拟地址到物理地址的转换工作,使得操作系统可以通过虚拟地址访问到物理地址空间的真是数据。
对于ARM体系架构下图是其MMU及内存层次的基本框图。
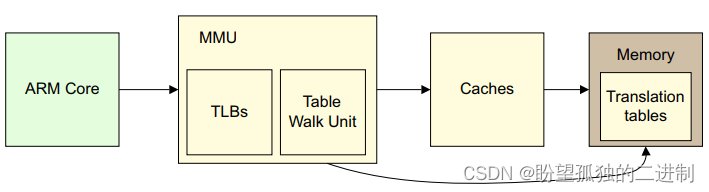
MMU包含Table Walk Unit和TLB(Translation Lookaside Buffer),其中Table Walk Unit即处理虚拟地址到物理地址的转换单元,而TLB用于缓存地址转换结果,TLB实质上是Cache,与Cache的区别在于它专门用来存储地址转换结果。
ARMv7采用二级页表映射,下图是虚拟地址转换到物理地址的页表映射过程,这个过程是由MMU完成的。
TTBRx(Translation Table Base Register x)即页表转换基址寄存器,ARMv7提供了TTBR0和TTBR1两个寄存器,Linux分别将其应用于内核态和用户态。而进程地址空间切换实质就是将TTBR0寄存器中***Translation Table Base 0 Address修改为当前进程的PGD(页全局目录)。
MMU通过TTBRx和虚拟地址中的PGD index找到 First-level descriptor,First-level descriptor记录了二级页表基址(即PTE),结合虚拟地址的PTE index即找到 * Second-level descriptor, Second-level descriptor记录了物理地址[31:12],物理地址[31:12]结合虚拟地址的VA[11:0]即得到物理地址。
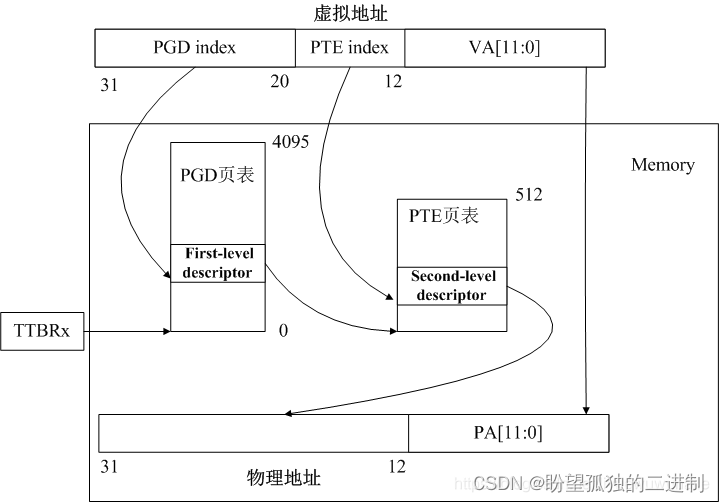
ARMv7地址空间切换由cpu_switch_mm完成。
void check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)
{…………
switch_mm_fastpath:cpu_switch_mm(mm->pgd, mm);
}
cpu_switch_mm调用cpu_do_switch_mm完成进程地址空间切换。
#define cpu_switch_mm(pgd,mm) cpu_do_switch_mm(virt_to_phys(pgd),mm)
cpu_do_switch_mm最终调用的汇编代码cpu_v7_switch_mm。ENTRY(cpu_v7_switch_mm)
#ifdef CONFIG_MMU@R1寄存器即APCS定义的第二个入参,即next进程的内存描述符mmmmid r1, r1 @ get mm->context.idALT_SMP(orr r0, r0, #TTB_FLAGS_SMP)ALT_UP(orr r0, r0, #TTB_FLAGS_UP)
#ifdef CONFIG_PID_IN_CONTEXTIDRmrc p15, 0, r2, c13, c0, 1 @ read current context IDlsr r2, r2, #8 @ extract the PIDbfi r1, r2, #8, #24 @ insert into new context ID
#endif
#ifdef CONFIG_ARM_ERRATA_754322dsb
#endifmcr p15, 0, r1, c13, c0, 1 @ set context IDisbmcr p15, 0, r0, c2, c0, 0 @ set TTB 0isb
#endifbx lr
ENDPROC(cpu_v7_switch_mm)
“mmid r1, r1” 将mm->context.id存入R1寄存器中。
“mcr p15, 0, r1, c13, c0, 1” 使用协处理器指令MCR将R1寄存器写入CP15协处理器C13寄存器中。
根据3.1节中关于协处理器指令的描述,可以知道。
CRn:第一个协处理器寄存器c13;
opc1:协处理器操作码0;
CRm:第二个协处理器寄存器c0;
opc2:协处理器操作码1。
因而对应CONTEXTIDR(Context ID Register)寄存器,即将mm->context.id写入CONTEXTIDR寄存器。这一步处理用于指示当前进程ASID(Address Space Identifier)。ASID应用于TLB,ASID可以将不同的进程在TLB中缓存的页表映射隔离,因而可以避免进程切换时将TLB表项刷新。
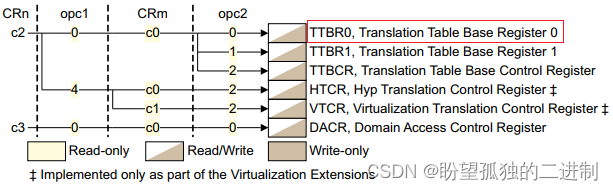
“mcr p15, 0, r0, c2, c0, 0” 使用协处理器指令MCR将R0寄存器写入CP15协处理器C2寄存器中。R0寄存器即APCS定义的第一个入参,即PGD。
根据3.1节中关于协处理器指令的描述,可以知道。
CRn:第一个协处理器寄存器c2;
opc1:协处理器操作码0;
CRm:第二个协处理器寄存器c0;
opc2:协处理器操作码0。
因而对应TTBR0寄存器,即将PGD写入TTBR0寄存器,完成进程地址空间切换。
三、switch_to
对于内核空间及寄存器的切换,switch_to函数完成了这个任务。switch_to是与体系架构相关的函数。下面以ARM体系架构说明用户空间的切换过程。
switch_to调用到__switch_to。
#define switch_to(prev,next,last) \
do { \__complete_pending_tlbi(); \last = __switch_to(prev,task_thread_info(prev), task_thread_info(next)); \
} while (0)
__switch_to汇编实现如下。三个入参分别为:
r0:移出进程prev的task_struct;
r1:移出进程prev的thread_info;
r2:移入进程next的thread_info.
ENTRY(__switch_to)UNWIND(.fnstart )UNWIND(.cantunwind )add ip, r1, #TI_CPU_SAVE @ip = r1 + TI_CPU_SAVE ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stackTHUMB( stmia ip!, {r4 - sl, fp} ) @ Store most regs on stackTHUMB( str sp, [ip], #4 )THUMB( str lr, [ip], #4 )ldr r4, [r2, #TI_TP_VALUE]ldr r5, [r2, #TI_TP_VALUE + 4]
#ifdef CONFIG_CPU_USE_DOMAINSmrc p15, 0, r6, c3, c0, 0 @ Get domain registerstr r6, [r1, #TI_CPU_DOMAIN] @ Save old domain registerldr r6, [r2, #TI_CPU_DOMAIN]
#endifswitch_tls r1, r4, r5, r3, r7
#if defined(CONFIG_STACKPROTECTOR) && !defined(CONFIG_SMP)ldr r7, [r2, #TI_TASK]ldr r8, =__stack_chk_guard.if (TSK_STACK_CANARY > IMM12_MASK)add r7, r7, #TSK_STACK_CANARY & ~IMM12_MASK.endifldr r7, [r7, #TSK_STACK_CANARY & IMM12_MASK]
#endif
#ifdef CONFIG_CPU_USE_DOMAINSmcr p15, 0, r6, c3, c0, 0 @ Set domain register
#endifmov r5, r0add r4, r2, #TI_CPU_SAVEldr r0, =thread_notify_headmov r1, #THREAD_NOTIFY_SWITCHbl atomic_notifier_call_chain
#if defined(CONFIG_STACKPROTECTOR) && !defined(CONFIG_SMP)str r7, [r8]
#endifTHUMB( mov ip, r4 )mov r0, r5ARM( ldmia r4, {r4 - sl, fp, sp, pc} ) @ Load all regs saved previouslyTHUMB( ldmia ip!, {r4 - sl, fp} ) @ Load all regs saved previouslyTHUMB( ldr sp, [ip], #4 )THUMB( ldr pc, [ip] )UNWIND(.fnend )
ENDPROC(__switch_to)
“add ip, r1, #TI_CPU_SAVE” 将IP寄存器赋值为r1+ TI_CPU_SAVE,r1即为prev->thread_info,TI_CPU_SAVE是cpu_context成员在thread_info中的偏移。
DEFINE(TI_CPU_SAVE, offsetof(struct thread_info, cpu_context));
因此IP寄存器保存了prev->thread_info->cpu_context的地址。
ARM体系架构定义的cpu_context包含了r4-r9,sl,fp,sp和pc寄存器。
struct cpu_context_save {__u32 r4;__u32 r5;__u32 r6;__u32 r7;__u32 r8;__u32 r9;__u32 sl;__u32 fp;__u32 sp;__u32 pc;__u32 extra[2]; /* Xscale 'acc' register, etc */
};
“ARM( stmia ip!, {r4 - sl, fp, sp, lr} )” 将r4 - sl, fp, sp, lr寄存器中的内容保存到IP寄存器所指向的内存地址,即prev->thread_info->cpu_context,这相当于保存了prev进程运行时的寄存器上下文。
stmia是多寄存器寻址内存操作指令。用于将多个寄存器的值存放到内存。
内存操作指令stm的ia后缀表示,数据传输完成后地址增加。
!表示数据传输完成后,将地址回写到ip寄存器。
关于stmia的详细内容请看《ARM体系架构—ARMv7-A指令集:内存操作指令》
如下操作依然是将寄存器保存到内存,内存地址不断递增,且回写到IP寄存器。
*THUMB( stmia ip!, {r4 - sl, fp} ) @ Store most regs on stack
THUMB( str sp, [ip], #4 )
THUMB( str lr, [ip], #4 ) *
prev寄存器R4和R5以压入prev进程内核栈中,因而可以被next进程使用,寄存器R4和R5分别用来保存next->thread_info->tp_value[0]和next->thread_info->tp_value[1]
ldr r4, [r2, #TI_TP_VALUE]
ldr r5, [r2, #TI_TP_VALUE + 4]
调用atomic_notifier_call_chain函数,入参为thread_notify_head和THREAD_NOTIFY_SWITCH。
ldr r0, =thread_notify_head
mov r1, #THREAD_NOTIFY_SWITCH
bl atomic_notifier_call_chain
add r4, r2, #TI_CPU_SAVE 实现r4寄存器保存了next->thread_info->cpu_context的地址。
“ARM( ldmia r4, {r4 - sl, fp, sp, pc} )” 将next->thread_info->cpu_context的数据加载到r4 - sl, fp, sp, lr,pc寄存器中,next->thread_info->cpu_context->sp存入寄存器SP相当于内核栈切换完成,next->thread_info->cpu_context->pc存入寄存器PC相当于跳转到next进程运行。即切换到next进程运行时的寄存器上下文。
这样就完成了进程内核栈及寄存器切换。
关于ARM寄存器介绍请参看《ARM体系架构—ARMv7-A处理器模式及寄存器》
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/liyuewuwunaile/article/details/106773630