论文:Visual Instruction Tuning
代码:https://llava-vl.github.io/
出处:NeurIPS 2023 Oral
系列工作:LLaVA-1.5、LLaVA-PLUS、LLaVA-Interactive、Video-LLaVA、LLaVA-Med 等,LLaVA 也是首次将指令学习引入多模态的论文
在论文开始之前,先介绍一下这几种模型训练方法的区别:
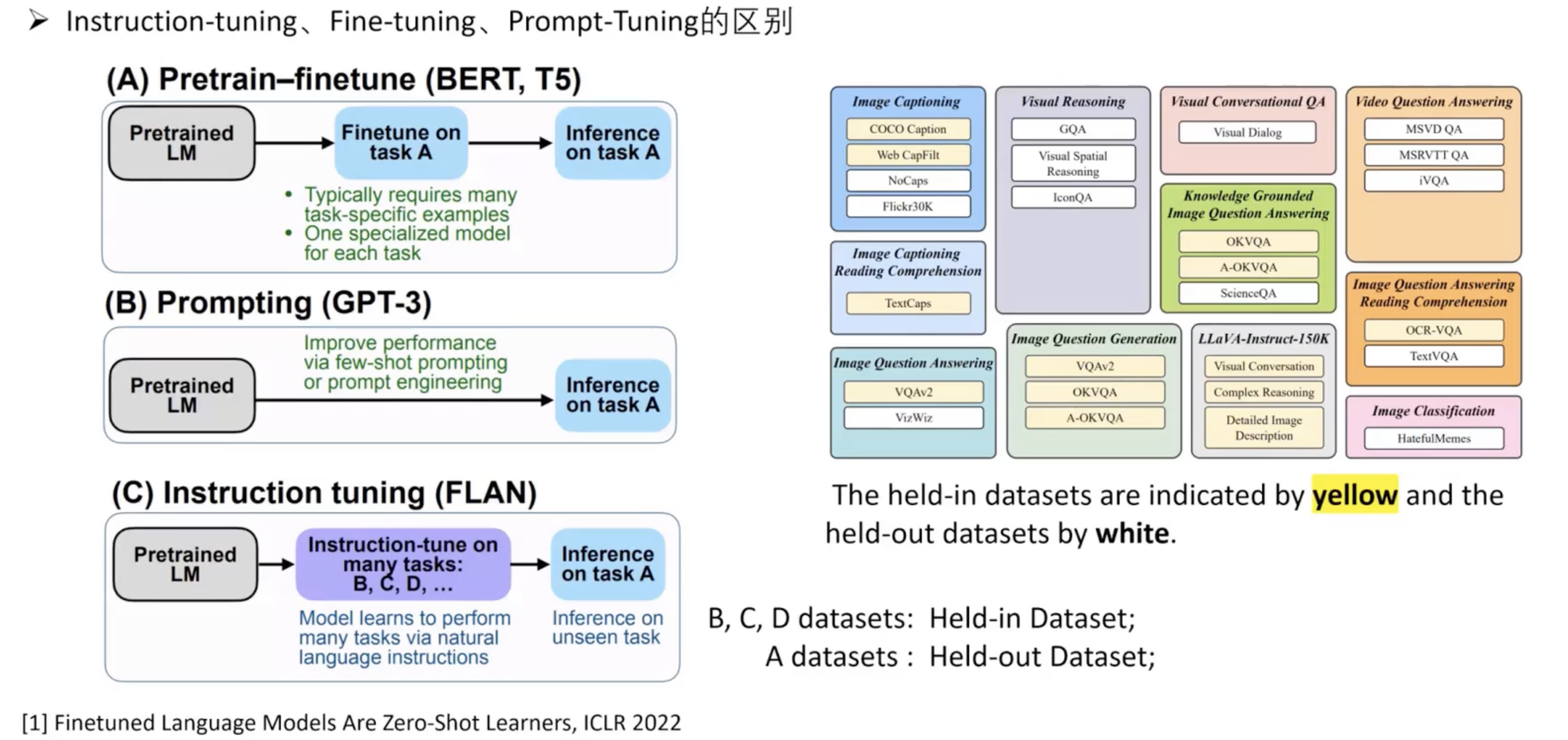
1、Pretrain-finetune:先在大量数据集上做预训练,然后针对某个子任务做 finetune
2、Prompting:
- 定义: Prompting 是指向模型提供一个或一系列的提示(prompts),通常是用自然语言编写的,这些提示旨在激发模型给出特定类型的回应。这不涉及改变模型的内部权重或结构,而是利用模型已经学习的知识和能力。
- 使用场景: Prompting 常用于零样本(zero-shot)或少样本(few-shot)学习场景,其中模型需要在没有大量特定任务数据的情况下执行任务。
- 例子: 例如,如果你想让一个语言模型生成诗歌,你可以给它一个提示,如“写一首关于春天的诗”,模型就会基于这个提示生成文本。
3、Instruct-tuning:
- 定义: Instruct-tuning 是指对模型进行额外的训练(也称为微调),通常是在一个特定的任务上,使用一个特定的数据集,这个数据集包含了特定的指令和期望的行为。这个过程实际上会改变模型的权重,使其更好地理解和执行给定的指令。
- 使用场景: Instruct-tuning 通常用于提高模型对于特定指令的响应性和准确性,尤其是当模型在原始训练中没有充分学习如何处理这些指令时。
- 例子: 如果一个模型在处理复杂的自然语言指令时表现不佳,如“整理这份报告的要点”,则可以通过 instruct-tuning 在包含类似任务的数据集上进一步训练模型,以改善其在该任务上的性能。
简而言之,prompting 是一种无需改变模型本身而利用模型现有能力的方法,而 instruct-tuning 是通过额外训练来改善模型对特定指令的响应。两者都是提高人工智能模型性能的有效方法,但它们的适用情况和目的有所不同。
一、背景
本文主要提出了视觉指令微调的方法,也是收个将指令微调应用到 language-image 多模态任务上的方法,建立了一个更通用的视觉助手。
主要贡献:
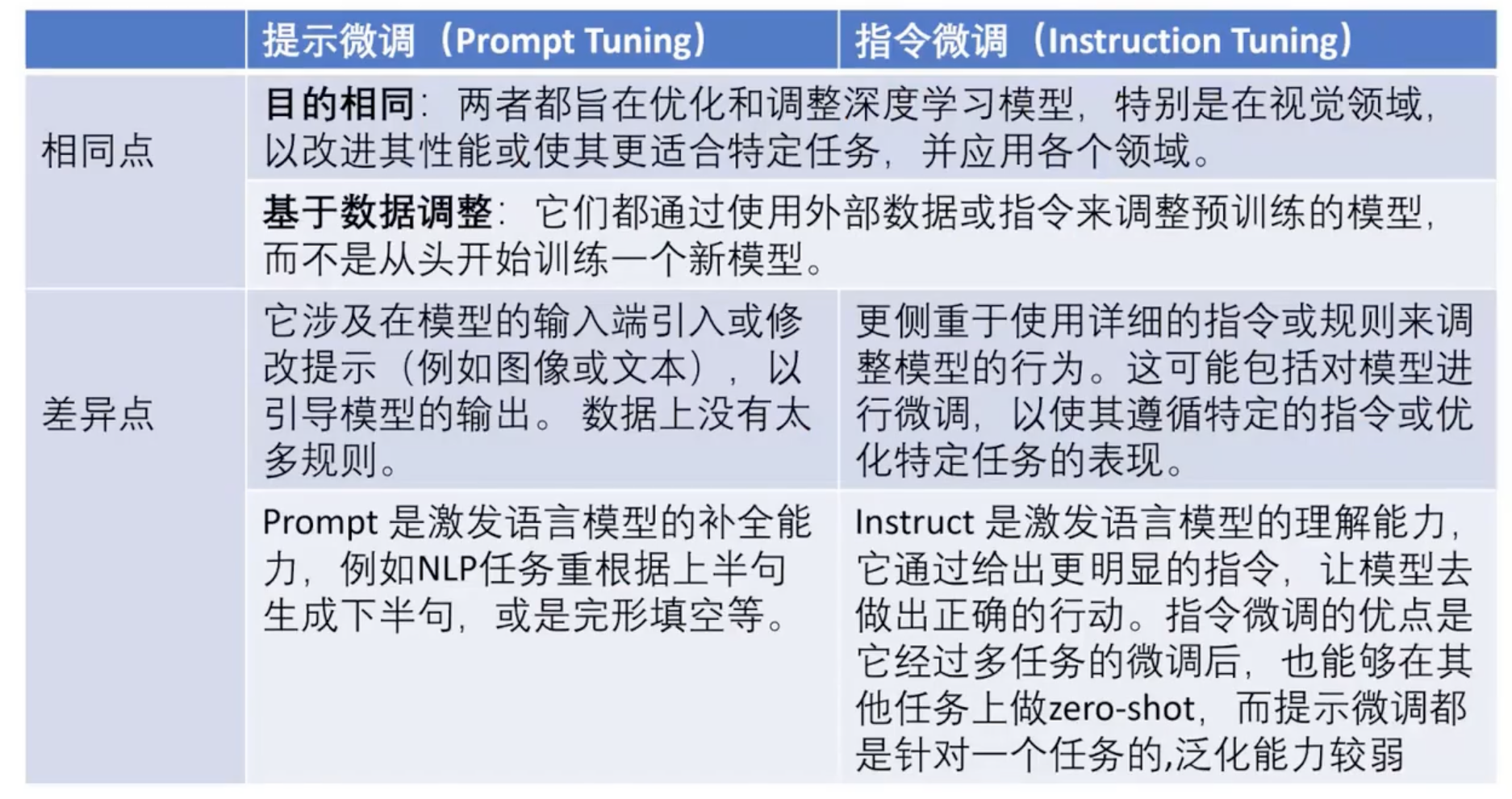
- 多模态指令跟随数据的构建:Multimodal instruction-following data,要在多模态任务上使用指令微调,首先要有数据,作者建立了一套处理流程,将 image-text pairs 转换成了 instruction-following 形式,转换使用的是 chatgpt 和 GPT4
- 大型多模态模型:作者构造了一个大的多模态模型 LMM,构造的方式是将 CLIP 作为 visual encoder,将 Vicuna 作为 language encoder,然后在作者生成的 instructional vision-language 数据上进行端到端的微调
- 多模态 instruction-following benchmark:作者提出了 LLaVA-Bench,这个 bench 是两个 challenging benchmark,它包括了一系列配对的图片、指令和详细注释,用于评估机器学习模型在执行多模态指令(即涉及多种类型输入,如图像和文本)时的性能
- 开源:作者开源了数据、代码、模型等
在自然语言处理(NLP)领域,为了使LLMs(如GPT-3、T5、PaLM和OPT)能够跟随自然语言指令并完成现实世界任务,研究人员已经探索了LLM指令调整(instruction-tuning)的方法。然后就出现了如 InstructGPT、FLAN-T5、FLAN-PaLM 和 OPT-IML 等指令调整后的对应模型。这种简单的方法被证明可以有效提高LLMs的 zero-shot 和 few-shot 学习的泛化能力。因此,从NLP借鉴这个想法到计算机视觉是自然的。更广泛地,基于基础模型的教师-学生蒸馏(distillation)思想已经在其他课题中被研究,例如图像分类。
Flamingo 可以被视为多模态领域的 GPT-3 时刻,因为它在 zero-shot 任务和上下文学习方面的强大性能。其他在图像-文本对上训练的LMMs包括BLIP-2、FROMAGe和KOSMOS-1。PaLM-E是一个用于具身AI的LMM。基于最新的“最佳”开源LLM LLaMA,OpenFlamingo和LLaMA-Adapter是使LLaMA能够使用图像输入的开源努力,为构建开源多模态LLMs铺平了道路。尽管这些模型在任务转移泛化性能方面表现出色,但它们并没有明确地使用视觉-语言指令数据进行调整,而且它们在多模态任务上的性能通常不如仅限语言的任务。本文旨在填补这一差距并研究其有效性。
最后注意的一点,视觉指令调整与视觉提示调整不同:前者旨在提高模型的指令跟随能力,而后者旨在提高模型适应中的参数效率。
二、数据生成
现成有很多 image-text pairs 的数据,如 COCO 和 LAION 等,但多模态的指令跟随数据很少,主要由于其创建难度比较大,所以作者使用了 chatgpt 和 GPT-4 在开源的 image-text pairs 数据基础上来生成多模态指令跟随数据
如何将图像-文本对(一张图像Xv和它相关的描述Xc)转换成指令跟随型数据用来训练人工智能,以便它能够理解和回答关于图像内容的问题。
作者提出了一种简单的方法来扩展图像-文本对,即通过创建一组问题Xq来指导助手描述图像内容,然后按照 “ Human : Xq Xv
这种方法成本低廉,但在指令和回应中缺乏多样性和深度推理。为了解决这个问题,作者提出使用只接受文本输入的GPT-4或ChatGPT作为强大的教师来创建涉及视觉内容的指令跟随型数据。具体来说,为了将图像编码成文本模型能够识别的视觉特征,作者使用了两种类型的符号表示方法:
- (i)描述:通常从不同角度描述视觉场景;
- (ii)边界框:框通常用于定位场景中的对象,并编码对象的概念和其空间位置。表14的顶部区块展示了一个例子。
这种符号表示方法允许我们将图像编码为语言模型(LLM)可以识别的序列。作者使用COCO图像数据库,并生成了三种类型的指令跟随型数据。表14的底部区块展示了每种类型的一个例子。对于每种类型,作者首先手动设计了一些例子。这些例子是数据收集过程中唯一的人类注释,用作上下文学习中查询GPT-4的种子例子。

将多模态任务分成了 3 类:
-
对话。作者设计了一个对话,其中助理回答有关某张照片的问题。答案的语气就好像助理正在看图片并回答问题一样。问了一系列关于图像视觉内容的多样化问题,包括对象类型、计数对象、对象动作、对象位置、物体之间的相对位置。只考虑那些有明确答案的问题。具体提示请参见附录。
-
详细描述。为了包含对图像的丰富和全面描述,作者创建了一系列带有这种意图的问题。然后提示GPT-4并筛选问题列表(具体提示和筛选过程请参见附录)。对于每张图片,随机从列表中抽取一个问题,要求GPT-4生成详细描述。对话数据主要针对物体类型,物体数量,行为,位置,物体间的相对位置等进行问题生成,利用各种问题来得到对图片丰富、全面的描述
-
复杂推理。以上两种类型专注于视觉内容本身,在此基础上,进一步创建深入的推理问题。答案通常需要按照严格逻辑进行逐步推理。
总共收集了158K个独特的语言-图像指令跟随样本,包括在对话中的58K个,在详细描述中的23K个,以及在复杂推理中的77K个。我们在早期实验中对ChatGPT和GPT-4的使用进行了消融研究,并发现GPT-4在提供高质量指令跟随数据方面始终表现更好,例如空间推理。
这是需要对图片简要描述时使用的问题:

这是需要对图片详细描述时使用的问题:

三、模型
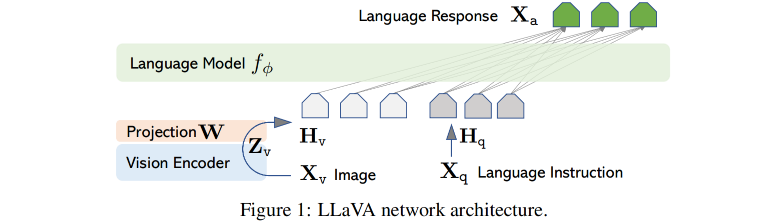
本文的方法需要同时使用预训练好的 LLM 和 visual model 的能力,结构如图 1 所示:
-
LLM:Vicuna
-
visual model:CLIP,图像是 Xv,经过 CLIP 特征提取后得到视觉特征 Zv,再使用 projection 进行维度映射,得到 language embedding token Hv
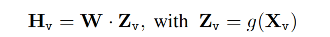
-
指令编码:指令就是 Xq,编码后得到 Hq,将 Hv 和 Hq 一起送入大语言模型后,训练大语言模型
训练:
-
对每个图片 Xv,生成多轮对话数据 ( X q 1 , X a 1 , . . . , X q T , X a T ) (X_q^1, X_a^1,..., X_q^T, X_a^T) (Xq1,Xa1,...,XqT,XaT),T 是总共的轮数
-
作者将这些组成一个序列,将所有 answer 都看做助手的回答
-
第 t-th 轮的指令 X i n s t r u c t t X_{instruct}^t Xinstructt 为
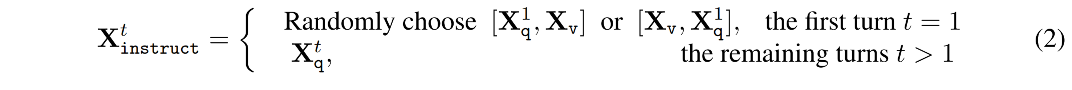
-
对一个序列的长度 L,最终计算得到回答 X a X_a Xa 的概率如下, θ \theta θ 是训练参数, X i n s t r u c t , < i X_{instruct,<i} Xinstruct,<i 和 X a , < i X_{a,<i} Xa,<i 为当前预测 token x i x_i xi 之前的 instruction token 和 answer token。
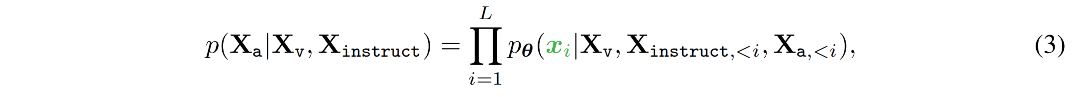
这里展示了两轮对话的过程:

整个过程就是:
- 输入为:图像+指令,之前轮的输出结果
- 输出为:大语言模型的输出结果
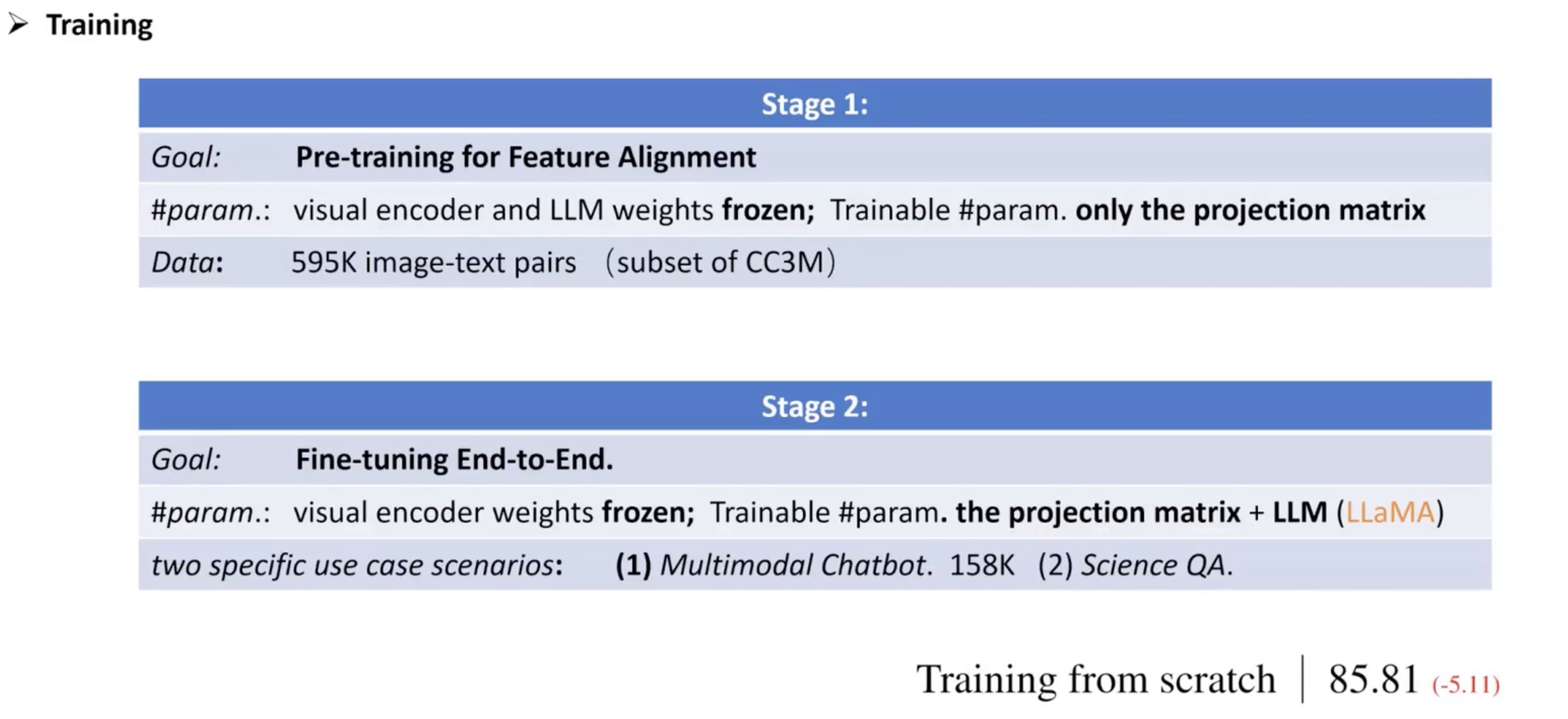
两阶段训练方式:
- 第一阶段:进行 pre-training,特征对齐,也就是将 CLIP 和 LLM 的特征对齐,CLIP 和 LLM 的参数都是冻结的,参与训练的只有 projection matrix
- 第二阶段:进行 instruct-tuning,冻结 CLIP 参数,训练 LLM 和 projection matrix 的参数
四、数据格式
数据可以在 github 的代码中找到:https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain/tree/main
pre-train 的数据使用的是 LAION-CC-SBU dataset,对话的格式如下,prompt 主要是让模型简单的描述图片的大概内容,粗糙的内容:
{"id": "004539375","image": "00453/004539375.jpg","conversations": [{"from": "human","value": "Render a clear and concise summary of the photo.\n<image>"},{"from": "gpt","value": "select luxury furniture 3 - inch gel memory foam mattress topper"}]},{"id": "002239345","image": "00223/002239345.jpg","conversations": [{"from": "human","value": "Write a terse but informative summary of the picture.\n<image>"},{"from": "gpt","value": "a grey watch with an army style strap"}]},{"id": "005947502","image": "00594/005947502.jpg","conversations": [{"from": "human","value": "<image>\nWhat is this?"},{"from": "gpt","value": "a dragon kite flying in the blue sky stock images"}]},{"id": "005116462","image": "00511/005116462.jpg","conversations": [{"from": "human","value": "<image>\nRender a clear and concise summary of the photo."},{"from": "gpt","value": "$ 10 - cute cheap printed mini dress - khaki multicolor striped floral print peasant short sleeve tunic"}]},{"id": "002017886","image": "00201/002017886.jpg","conversations": [{"from": "human","value": "What is in the photo?\n<image>"},{"from": "gpt","value": "augmented reality using aruco markers in opencv"}]},{"id": "001819539","image": "00181/001819539.jpg","conversations": [{"from": "human","value": "Describe the image concisely.\n<image>"},{"from": "gpt","value": "a pair of childrens boots in the shape of knitted shoes"}]},{"id": "002838027","image": "00283/002838027.jpg","conversations": [{"from": "human","value": "Share a concise interpretation of the image provided.\n<image>"},{"from": "gpt","value": "floral watercolor clip art rose flower border with pink"}]},{"id": "000406392","image": "00040/000406392.jpg","conversations": [{"from": "human","value": "Give a brief description of the image.\n<image>"},{"from": "gpt","value": "the divine queen in her elaborate masks canvas print featuring the face and hands of a woman with red hair"}]}
visual instruct tuning 使用的数据如下:https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/tree/main
第二阶段微调时,prompt 基本都是让描述更细致的描述图片的内容,或者带有推理性质的
detail_23k.json 如下:
{"id": "000000442786","image": "000000442786.jpg","conversations": [{"from": "human","value": "What do you see happening in this image?\n<image>"},{"from": "gpt","value": "The scene depicts a lively plaza area with several people walking and enjoying their time. A man is standing in the plaza with his legs crossed, holding a kite in his hand. The kite has multiple sections attached to it, spread out in various directions as if ready for flight.\n\nNumerous people are scattered throughout the plaza, walking and interacting with others. Some of these individuals are carrying handbags, and others have backpacks. The image captures the casual, social atmosphere of a bustling plaza on a nice day."}]},{"id": "000000539056","image": "000000539056.jpg","conversations": [{"from": "human","value": "What do you think is going on in this snapshot?\n<image>"},{"from": "gpt","value": "The image displays a tidy home office desk setting with a laptop placed in the center. On the desk, there is a cordless keyboard in front of the laptop and a wireless mouse situated slightly to the right of it. A cell phone can be seen on the left side of the desk, close to the laptop.\n\nNear the top left corner, there is a coke glass adding a personal touch to the workspace. A collection of books is scattered around the scene in various positions and stacks, possibly serving as reference material or leisure reading for the desk's occupant."}]},{"id": "000000131697","image": "000000131697.jpg","conversations": [{"from": "human","value": "Can you elaborate on the elements of the picture provided?\n<image>"},{"from": "gpt","value": "The image depicts a classroom full of children working together on laptops. There are several kids in the room, with some of them sharing a laptop in pairs. The students are focused on their tasks with laptops placed on desks or tables.\n\nAside from the laptops, there are multiple chairs in the room, accommodating the students as they work. Other objects in the classroom include a bottle, a cell phone, a book, and a keyboard. Some children can also be seen using additional electronic devices such as tablets or cell phones. The overall atmosphere indicates a modern, technology-filled learning environment."}]},{"id": "000000281721","image": "000000281721.jpg","conversations": [{"from": "human","value": "Describe the following image.\n<image>"},{"from": "gpt","value": "The image presents a bustling city street with cars driving down the road and pedestrians walking along the sidewalks. Multiple vehicles are passing through a green light at the intersection, traveling in both directions. Some cars are closer to the camera, while others can be seen further down the street.\n\nThere are a couple of pedestrians visible near the left side of the image, possibly navigating their way through the city. Various traffic lights are positioned throughout the scene, ensuring a safe flow of traffic for both vehicles and pedestrians alike. The atmosphere suggests a busy and lively city environment."}]},{"id": "000000314298","image": "000000314298.jpg","conversations": [{"from": "human","value": "What do you think is going on in this snapshot?\n<image>"},{"from": "gpt","value": "The image shows a woman with glasses sitting at a dining table, biting into a delicious donut with a smile on her face. Another man is sitting next to her, celebrating or enjoying the moment. They are surrounded by several chairs and cups placed on the table.\n\nIn the background, there's another dining table with a few more cups on it as well as another person who appears to be engaged in a separate activity. The scene is lively, capturing a pleasant social gathering with people enjoying food and each other's company."}]},{"id": "000000543263","image": "000000543263.jpg","conversations": [{"from": "human","value": "What's happening in the scene?\n<image>"},{"from": "gpt","value": "The image captures a scene with several people in the vicinity of uniquely designed benches. One of the benches, which is the focal point of the image, is shaped like a butterfly. A woman in a white shirt is sitting on this butterfly-shaped bench with a handbag placed beside her. \n\nSeveral other people can be spotted around the area, including a lady with glasses and a backpack walking behind the woman sitting on the bench. One more bench is visible in the distance, and there seem to be a few people sitting or standing by the other benches as well. Overall, it appears to be a casual outdoor setting where people are taking a break, engaging in conversations or passing by."}]},
llava_instruct_80k.json 如下:
{"id": "000000379143","image": "000000379143.jpg","conversations": [{"from": "human","value": "What is the man doing in the back of the pickup truck?\n<image>"},{"from": "gpt","value": "The man is sitting on top of piled objects or belongings loaded into the back of a pickup truck."},{"from": "human","value": "Is the man holding anything in his hands?"},{"from": "gpt","value": "Yes, the man is holding a beer in his hand while sitting on top of the objects in the back of the pickup truck."},{"from": "human","value": "What color is the pickup truck?"},{"from": "gpt","value": "The pickup truck is white."},{"from": "human","value": "Is the man sitting or standing?"},{"from": "gpt","value": "The man is sitting on top of the piled objects in the back of the pickup truck."},{"from": "human","value": "What could be the possible reasons for the man sitting on top of the possessions in the back of the pickup truck?"},{"from": "gpt","value": "There could be several reasons for the man sitting on top of his possessions in the back of the pickup truck:\n\n1. Moving: The man might be moving to a new location and needed to transport his items in a pickup truck, utilizing available space efficiently. By sitting on top of the belongings, he could be helping to stabilize and secure the items during the move, preventing them from falling or shifting during transportation.\n\n2. Lack of seating: If the cab of the pickup truck is already at full capacity or there isn't enough space for him to sit inside, the man may have chosen to sit on his possessions as an alternative seating arrangement.\n\n3. Road trip or outing: The man might be on a road trip or a casual outing with friends or family, where he is using the back of the pickup truck as an open-air seating area. By sitting on top of the loaded items, he may be enjoying the journey while savoring his beer.\n\n4. Keeping an eye on belongings: The man could be safeguarding his possessions by staying close to them, ensuring that no items are lost, stolen or damaged during the journey.\n\nRegardless of the specific reason, the image shows a person making the most of their situation, adding a touch of lightheartedness or adventure to an otherwise mundane scene."}]},{"id": "000000083996","image": "000000083996.jpg","conversations": [{"from": "human","value": "<image>\nHow many people are seen surfing in the image?"},{"from": "gpt","value": "The image shows several people or a group of people surfing the waves in the ocean."},{"from": "human","value": "What is the weather like in the image?"},{"from": "gpt","value": "The weather in the image is sunny."},{"from": "human","value": "What are the people doing in the water?"},{"from": "gpt","value": "The people in the water are surfing the waves on surfboards."},{"from": "human","value": "Can you explain the basics of surfing and the necessary equipment for beginners?"},{"from": "gpt","value": "Surfing is a popular water sport that involves riding waves on a surfboard while standing or lying in various positions. The main goal is to balance on the surfboard while being propelled forward by the wave's momentum. The sport originated from Polynesian culture and has evolved into a global phenomenon, attracting participants of all skill levels and backgrounds.\n\nFor beginners, there are a few essentials to get started with surfing:\n\n1. Surfboard: A beginner's surfboard should be wide, thick, and long to provide better stability and buoyancy. This makes it easier for beginners to learn balance and catch waves. Soft-top boards or foam boards are recommended for beginners, as they are more forgiving and less likely to cause injury during a wipeout.\n\n2. Wetsuit: A wetsuit is essential for most surfers, depending on the water temperature. Wetsuits are made of neoprene, providing insulation and flexibility to allow surfers to stay warm and move comfortably in the water. Thickness and type of wetsuit will vary based on the water temperature and local climate.\n\n3. Leash: A leash is a cord that attaches the surfboard to the surfer's ankle, preventing the board from drifting away after a wipeout. This is an essential safety tool and ensures that the surfboard stays within reach at all times.\n\n4. Surf Wax or Traction Pad: Surf wax or a traction pad is applied to the surfboard deck to provide grip and prevent surfers from slipping off their boards. Wax is applied in a circular pattern, while traction pads are adhesive pads placed on the deck.\n\n5. Sun Protection: Surfers should wear sunscreen, sunglasses, and, in some cases, a hat or rash guard to protect their skin from the sun's harmful rays.\n\nBefore hitting the waves, beginners should take a few lessons with an experienced instructor to learn essential techniques, safety tips, and surfing etiquette. With the right equipment and proper training, anyone can experience the thrill of catching and riding waves in the ocean."}]},{"id": "000000091544","image": "000000091544.jpg","conversations": [{"from": "human","value": "<image>\nHow many people are in the image?"},{"from": "gpt","value": "There are two people in the image."},{"from": "human","value": "What type of clothing are the people wearing in the image?"},{"from": "gpt","value": "The people in the image are wearing jackets or coats, possibly leather or black in color."},{"from": "human","value": "What activity are the two people engaged in?"},{"from": "gpt","value": "The two people are walking next to each other on a street, likely during the day."},{"from": "human","value": "Is there a traffic light visible in the image?"},{"from": "gpt","value": "Yes, there is a yellow traffic light visible in the image."},{"from": "human","value": "Can you tell if the two people are walking close together or maintaining some distance?"},{"from": "gpt","value": "The image shows the two people walking close together, as seen in the close-up view of them."}]},{"id": "000000148540","image": "000000148540.jpg","conversations": [{"from": "human","value": "<image>\nAre people getting off a train or a bus in the image?"},{"from": "gpt","value": "People are getting off a train in the image."},{"from": "human","value": "Can you describe the colors of the train?"},{"from": "gpt","value": "The train is blue and pink in color."},{"from": "human","value": "What is happening at the platform when the train stops?"},{"from": "gpt","value": "When the train stops at the platform, the door opens, and people start to exit the train. Among them, there is a couple carrying their luggage."},{"from": "human","value": "Is there any luggage seen on the platform?"},{"from": "gpt","value": "Yes, there is a suitcase on the ground near a pole on the platform."},{"from": "human","value": "How many suitcases does the couple carry?"},{"from": "gpt","value": "Unfortunately, the image does not explicitly show the exact number of suitcases the couple is carrying."}]},{"id": "000000257752","image": "000000257752.jpg","conversations": [{"from": "human","value": "<image>\nHow is the teddy bear positioned in the image?"},{"from": "gpt","value": "The teddy bear is hanging by a string or thread in the image."},{"from": "human","value": "What is happening to the teddy bear in terms of the surrounding elements?"},{"from": "gpt","value": "Water droplets are falling on the teddy bear as it's hanging by the string."},{"from": "human","value": "What is the background like in the image?"},{"from": "gpt","value": "The background of the image features a dirt wall, which could indicate an outdoor or cave-like setting."},{"from": "human","value": "Could you describe a possible scenario or story behind this image?"},{"from": "gpt","value": "The image of the teddy bear hanging by a string and having water droplets fall on it in front of a dirt wall creates an intriguing and somewhat mysterious scene. One possible interpretation of this image could be an art installation or a creative photography concept, focusing on the juxtaposition of a soft, innocent teddy bear with the harsh, natural elements of water and earth.\n\nAnother possible scenario could be that the teddy bear represents an abandoned or lost toy, left to the elements and the passage of time. The hanging position of the teddy bear and the falling water droplets might symbolize feelings of loneliness, vulnerability, or helplessness. \n\nIn either case, the image's composition and subject evoke a sense of curiosity and may lead the viewer to wonder about the intentions, emotions, or stories behind the scene. The image thus becomes a visual metaphor or prompt for creating and exploring narratives within the context of the photograph."}]},{"id": "000000426016","image": "000000426016.jpg","conversations": [{"from": "human","value": "How many orange parking meters are there in the image?\n<image>"},{"from": "gpt","value": "There are two orange parking meters in the image."},{"from": "human","value": "What is the color of the parking meters?"},{"from": "gpt","value": "The parking meters are orange."},{"from": "human","value": "Where are the parking meters in relation to trees and bushes?"},{"from": "gpt","value": "The parking meters are positioned next to a tree and near some bushes."},{"from": "human","value": "Is there any caution tape on the parking meter?"},{"from": "gpt","value": "Yes, there is caution tape wrapped around the parking meter, possibly indicating that it is out of order or needs attention."}]},{"id": "000000242544","image": "000000242544.jpg","conversations": [{"from": "human","value": "What color is the horse in the image?\n<image>"},{"from": "gpt","value": "The horse in the image is brown."},{"from": "human","value": "Is the horse stationary or in motion?"},{"from": "gpt","value": "The horse is in motion, walking through the field."},{"from": "human","value": "What is the woman doing in the image?"},{"from": "gpt","value": "The woman is standing in front of the brown horse and looking at it."},{"from": "human","value": "What is the setting of the image?"},{"from": "gpt","value": "The setting of the image is a field, where the brown horse is walking, and the woman is standing in front of it observing the horse."}]},
在处理视觉指令调整(visual instruct tuning)的标注数据时,使用多轮对话可以更好地模拟真实的人机交互场景。在这种情况下,多轮对话有以下好处:
-
上下文理解:通过连续的对话,系统可以更好地理解和跟踪上下文信息,从而提供更加准确和连贯的回答。
-
逐步澄清:用户可能会逐步提出问题,以澄清或获取更多的细节信息。多轮对话允许系统累积这些信息并相应地调整其回答。
-
动态反馈:用户可以对系统的回答进行反馈,系统可以根据反馈进行调整和改进。
-
灵活性和适应性:多轮对话展示了系统处理不同类型问题和用户需求的能力,包括对不明确或开放式问题的响应。
-
用户体验:模拟真实对话有助于提高用户体验,使得交互更加自然和人性化。
在上述标注数据中,多轮对话的使用确保了对话流畅且信息丰富,同时也帮助标注者理解如何在实际情况下设计和优化智能助手的回答。通过这种方式,可以确保智能助手在处理视觉信息和相关问题时能够提供有用的反馈和解释。