本来其实不知道爬虫的意义的,但是发现爬虫在信息收集的那一方面好像挺重要!!
那么就来浅学一下吧!!! 
1.基本的储备
对于爬虫,我们一般都是用的python去编写脚本 ,其中还要导入对应的一些库
pip install lxml
pip install bs4
pip install requests这些库都要在后面所用到
2.Requests
话不多说,我们直接上代码,再上代码之前,我们先拿RCE的页面来举例子!!!
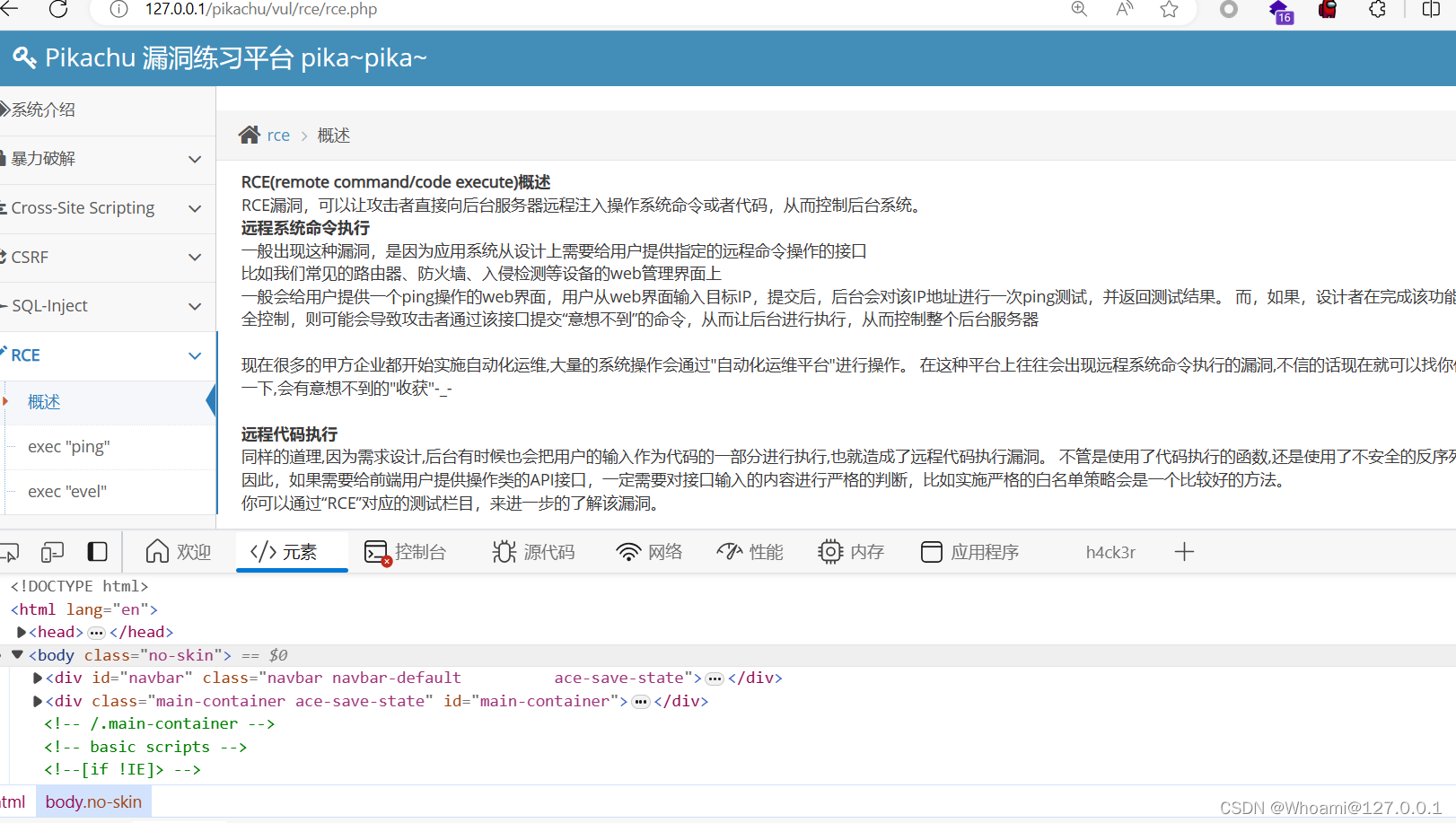
对,没错,我们就是要去爬取这个页面
from requests import *my_file = open("D:/crawler_data/data.txt","a+")try:url="http://127.0.0.1/pikachu/vul/rce/rce.php"response = get(url)response.encoding="utf-8" ##设置响应内容的编码方式text=response.textprint(text)
except Exception as e:print("发生错误:", e)
来解释一下这些代码
- 先从requests模块导入了所有东西
- try except这种错误捕获模块就不说了
- 然后就是先定义了一个目标网站的url !! 并且用response来接受请求结果
- response.encoding="utf-8" 是用来设置返回结果的编码方式为 utf-8
- 然后用text来接受response返回会的text内容,并且输出
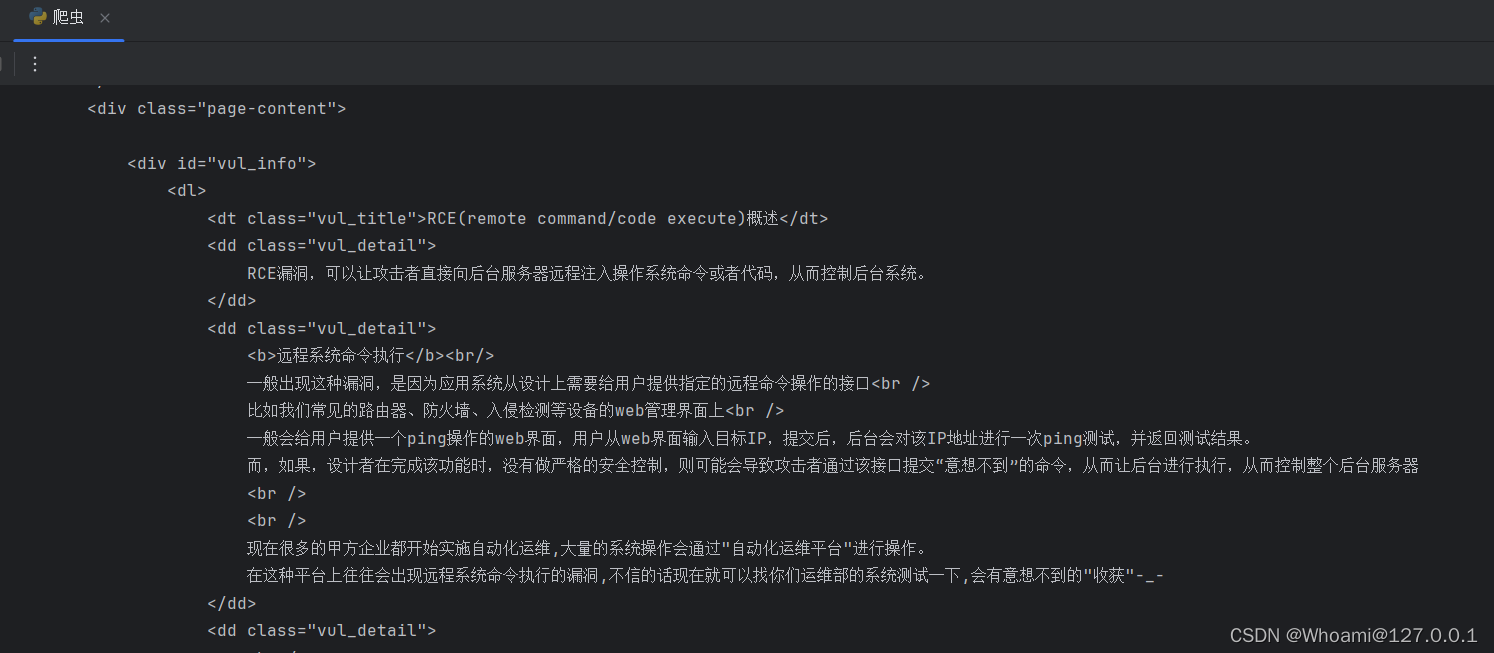
最后的得到的结果如下!!
有咩有别的偷懒一点的写法呢?? 那也肯定还是有的!!!
from requests import *my_file = open("D:/crawler_data/data.txt","a+")try:url="http://127.0.0.1/pikachu/vul/rce/rce.php"response = get(url)text=response.content.decode()print(text)except Exception as e:print("发生错误:", e)
还是来解释一下对应的代码,一样的我就不讲了,来讲一下这一行!!!
text=response.content.decode()没错,它就是首先获取了response的content的内容,然后用默认是utf-8解码的decode函数去解码
3.BeautifulSoup
所以为什么这个模块要叫这个名字呢,哈哈哈我也不知道,可能它的汤比较好喝吧!!!
1.对象创建
对于BeautifulSoup的对象创建,第一部分就是文档内容,第二部分是lxml解释器!!
soup = BeautifulSoup("文档内容",'lxml')2.搜索方法
对于创建出来的对象,我们有三种搜索方法!!!
1.根据标签的名字查找
find("标签的名字") ---> 返回第一个标签和其对应的内容!!
假设我想要寻找我的网页的script标签,那么就要这么写
from requests import *
from bs4 import BeautifulSoup
my_file = open("D:/crawler_data/data.txt","a+")try:url="http://127.0.0.1/pikachu/vul/rce/rce.php"response = get(url)text=response.content.decode()soup =BeautifulSoup(text,'lxml')search = soup.find("script")print(search)except Exception as e:print("发生错误:", e)
2.根据属性的名称查找
像在日常的生活中,一些标签有对应的一些属性
![]()
那么我们就可以这样查找
- soup.find(属性名="对应属性值") 不适用于属性名字含有 -符号的情况!!!
- soup.find(attrs{"属性名":"属性值"})
而且你的标签还要包含全,如果你只包含多个属性中的一个,那么是不会有返回值的!!!
from requests import *
from bs4 import BeautifulSoup
my_file = open("D:/crawler_data/data.txt","a+")try:url="http://127.0.0.1/pikachu/vul/rce/rce.php"response = get(url)text=response.content.decode()soup =BeautifulSoup(text,'lxml')search = soup.find(type="text/javascript")print(search)
except Exception as e:print("发生错误:", e)
这个代码就能找到第一个标签属性只包含 type='text/javascript' 的标签,并返回内容

提示一下,如果想要返回全部的结果,那么你只需要用find_all()这个函数就行
只需要略微修改上面的代码
search = soup.find_all(type="text/javascript")for sample in search:print(sample)就能得到全部的结果(美观版!!!)

3.根据内容进行查找(???)
这个虽然我不知道有什么用,但是还是讲讲! 用法
soup.find(string="你要查找的内容") 但是建议这个不存在嵌套,否则情况不一样
search = soup.find(string='Get the pikachu')
4.Tag对象
书接上回,当我们用find之后,返回的变量其实就是一个Tag对象
对于Tag对象,我们可以进行以下操作(假设这个对象是以属性查询后返回) 就是这样

1.name
这个功能用来获取标签名,直接上代码
search = soup.find(type="text/javascript")Tag=search.nameprint(Tag)  成功返回标签名
成功返回标签名
2.attrs
应该就是attribution的缩写 我们也是直接上代码
search = soup.find(type="text/javascript")Tag=search.attrsprint(Tag) 也是成功返回属性内容
也是成功返回属性内容
3.text
字面理解就是直接获取标签所对应的文本 也是上代码
search = soup.find(type="text/javascript")Tag=search.textprint(Tag)