⭐作者介绍:大二本科网络工程专业在读,持续学习Java,努力输出优质文章
⭐作者主页:@逐梦苍穹
⭐如果觉得文章写的不错,欢迎点个关注一键三连😉有写的不好的地方也欢迎指正,一同进步😁
目录
- 1、官网
- 2、框架文件夹
- 3、如何下载
- 3.1、python
- 3.2、Java
⭐⭐写在前面:
下载这个element-ui也是折腾了很久,在官网一直都没有找到,最后实在没辙,用了下面提到的方法。
有个问题就是用代码爬取会比较慢,如果不想花时间等待下载,也可以一键三连私信我单独分享云盘链接😉😊
1、官网
https://element.eleme.cn/#/zh-CN/component/installation
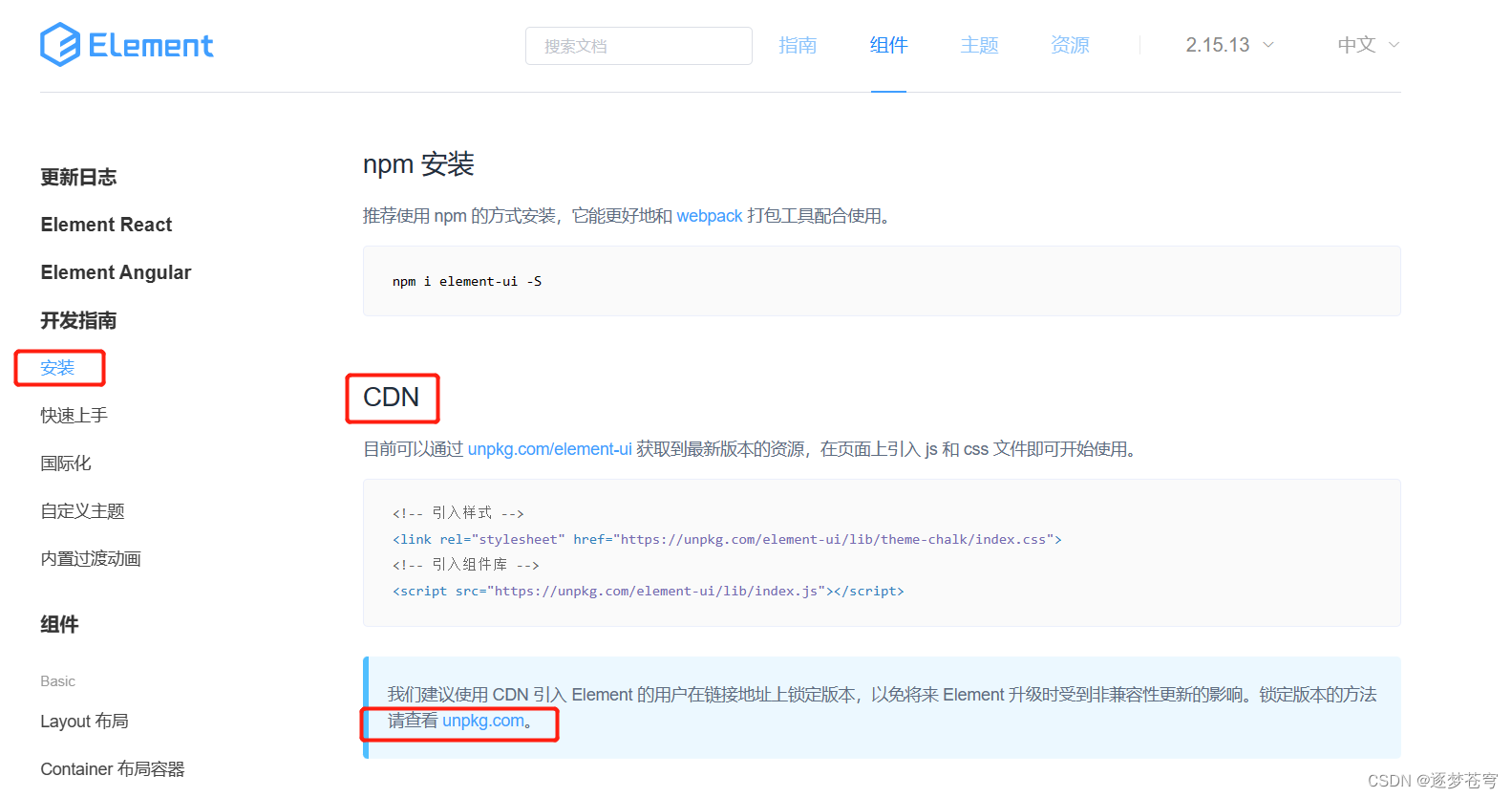
2、框架文件夹
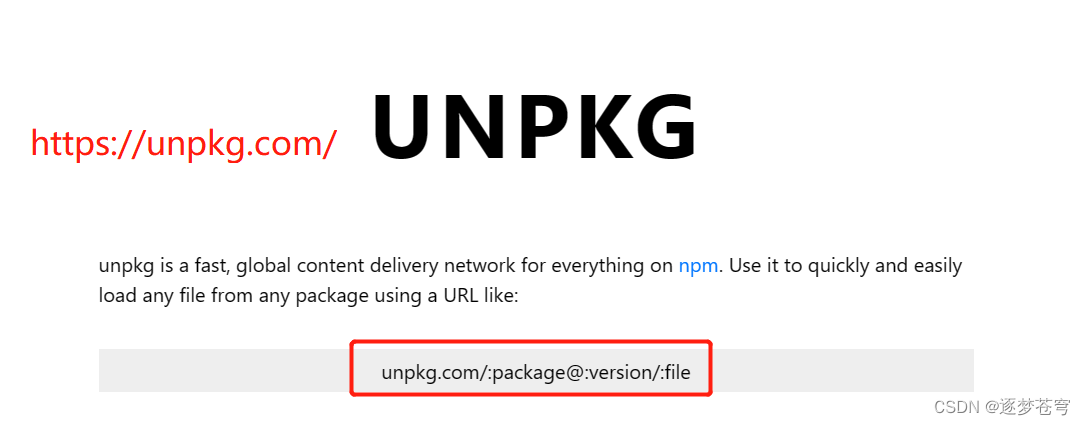
访问对应的路径:https://unpkg.com/browse/element-ui@2.15.13/
版本可以选择:
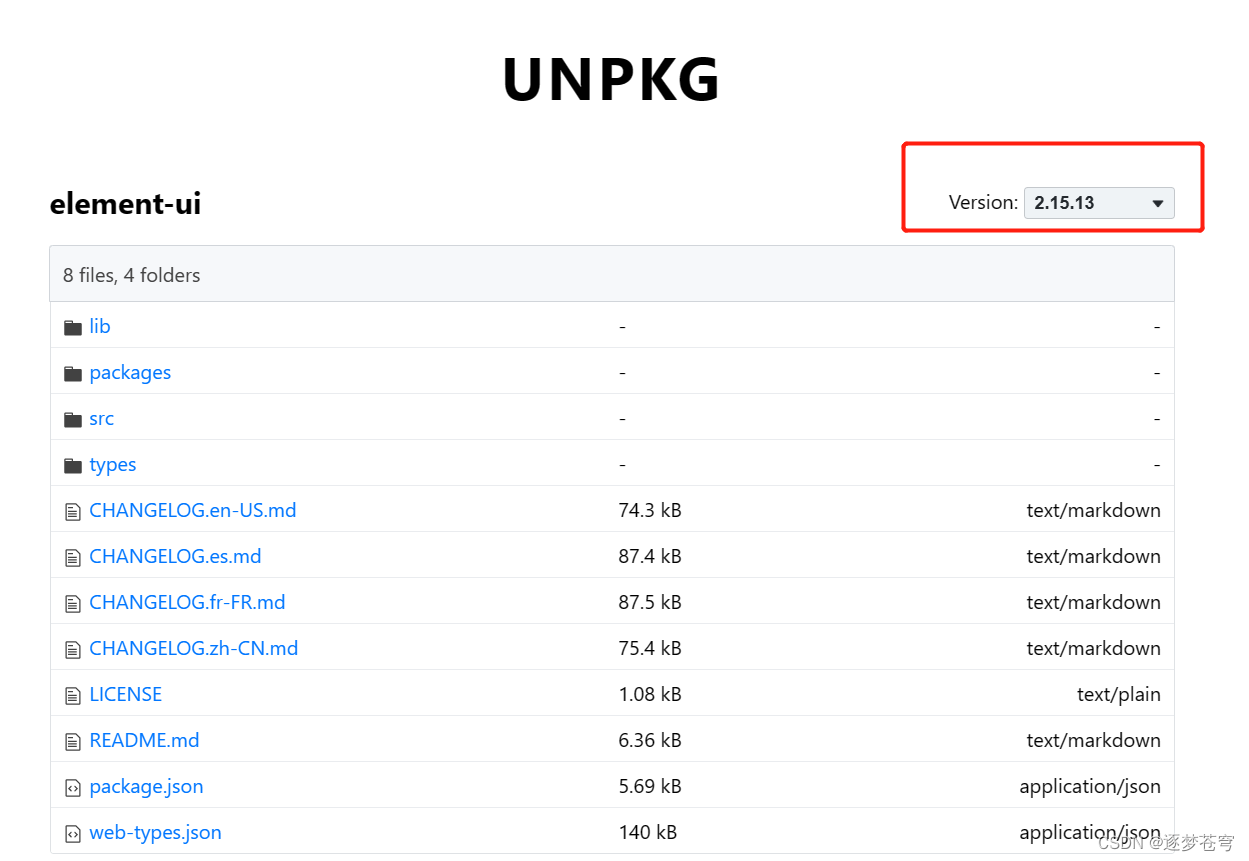
但是并没有下载的选项
3、如何下载
没下载选项,那只能,爬!
下面是python和Java的爬虫代码,有非常详细的注释,使用的时候只需要手动替换想要的版本信息和想要保存的路径即可(推荐使用python,这个需求的实现,Java的阅读性没有python直观)
比如:
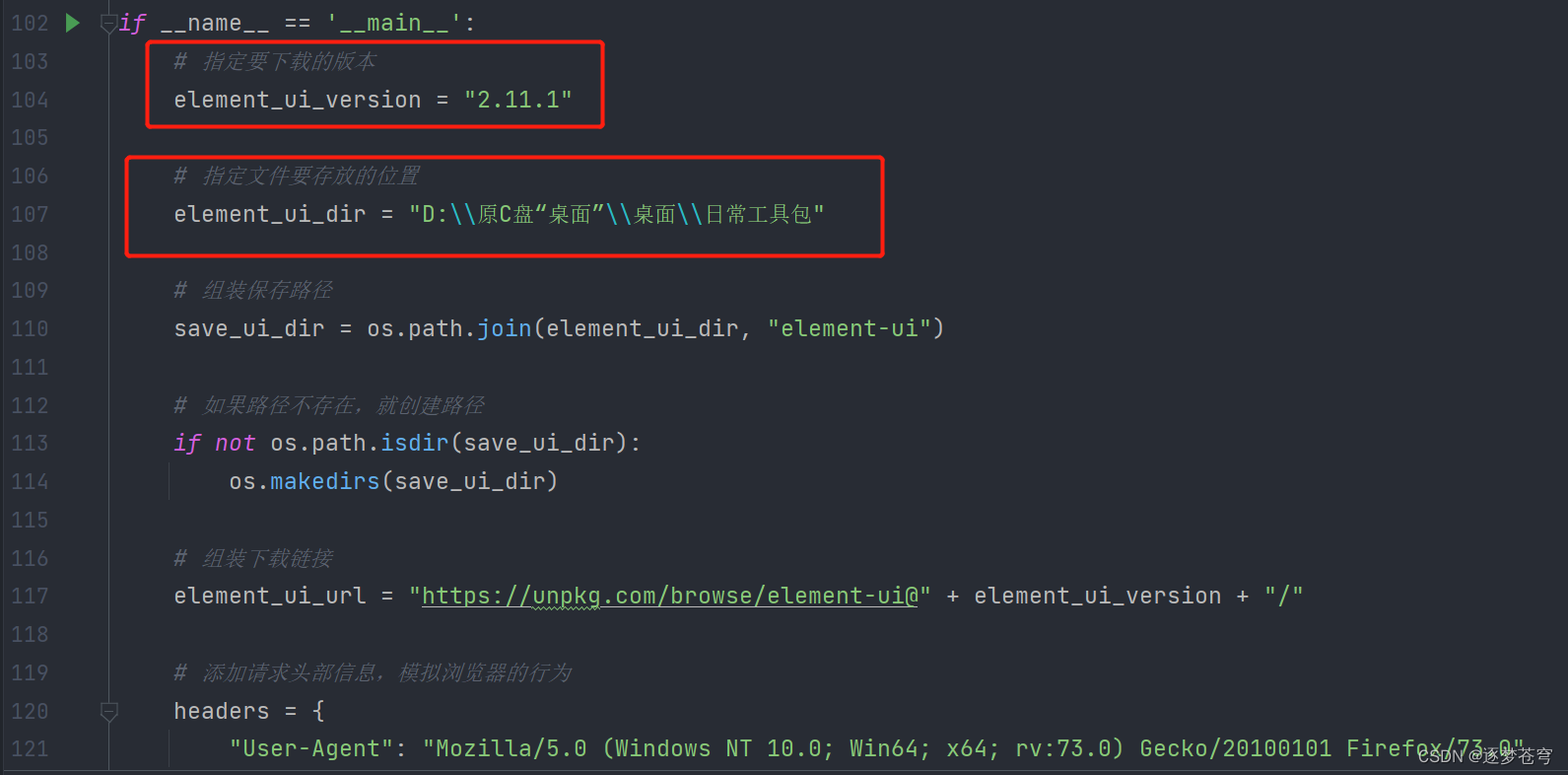
3.1、python
# encoding:utf-8
# @Author:逐梦苍穹# 导入需要使用的模块
from bs4 import BeautifulSoup # 解析 HTML 页面的库
import requests # 发送 HTTP 请求的库
import re # 正则表达式匹配的库
import os # 处理文件和目录的库
import socket # 处理网络连接超时的库
from urllib import request # 处理 URL 请求的库# 定义获取页面的函数
def get_page(url, save_dir):# 打印当前处理的页面 URLprint("Current Page: ", url)# 发送 HTTP GET 请求response = requests.get(url, headers=headers)# 使用 BeautifulSoup 对 HTML 页面进行解析soup = BeautifulSoup(str(response.content), "lxml")# 从页面中获取 tbody 标签中的内容tbody = soup.find("tbody")# 定义正则表达式规则,用于匹配 href 属性的内容rule_name = r'href="(.+?)"'# 使用正则表达式查找 href 属性的内容td_href = re.findall(rule_name, str(tbody))# 定义目录列表dir_list = []# 遍历每个 href 属性for href in td_href:# 组装完整的路径href_path = os.path.join(save_dir, href)# 如果是父目录,跳过if href == "../":pass# 如果是子目录,就创建目录elif "/" in href:os.mkdir(href_path)print("Makedir: ", href_path.replace(save_ui_dir, ""))dir_list.append(href)# 否则就是文件,就下载文件else:file_url = url + hrefabs_name = file_url.replace(element_ui_url, "")print("Download: ", abs_name)get_file(file_url, href_path)# 遍历目录列表,递归调用本函数for sub_dir in dir_list:sub_url = url + sub_dirsub_dir = os.path.join(save_dir, sub_dir)get_page(sub_url, sub_dir)# 定义下载文件的函数
def get_file(url, filename):# 创建一个网络请求的openeropener = request.build_opener()# 设置请求头opener.addheaders = [('User-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0')]# 将opener安装到全局request.install_opener(opener)# 设置socket超时时间为30秒socket.setdefaulttimeout(30)# 去除URL中的"browse/"字符url = url.replace("browse/", "")# 设置重试次数为5次count = 1while count <= 5:try:# 使用urlretrieve函数下载文件到本地request.urlretrieve(url, filename)# 下载成功则跳出循环breakexcept socket.timeout:# 超时则输出错误信息,并进行重试err_info = '<Timeout> Reloading for %d time' % countprint(err_info)count += 1except Exception as e:# 其他异常情况也需要重试err_info = '<' + str(e) + '> Reloading for %d time' % countprint(err_info)count += 1# 如果重试5次还是失败,则输出错误信息if count > 5:print("<Error> download job failed!")else:# 下载成功则不做处理,直接跳过passif __name__ == '__main__':# 指定要下载的版本element_ui_version = "2.11.1"# 指定文件要存放的位置element_ui_dir = "D:\\原C盘“桌面”\\桌面\\日常工具包"# 组装保存路径save_ui_dir = os.path.join(element_ui_dir, "element-ui")# 如果路径不存在,就创建路径if not os.path.isdir(save_ui_dir):os.makedirs(save_ui_dir)# 组装下载链接element_ui_url = "https://unpkg.com/browse/element-ui@" + element_ui_version + "/"# 添加请求头部信息,模拟浏览器的行为headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0"}get_page(element_ui_url, save_ui_dir)3.2、Java
对要使用的包进行解释说明:
下面是每个导入包的详细介绍:
- import java.io.File; import java.io.FileOutputStream; import java.io.InputStream;这些包提供了与文件和输入/输出操作相关的类和接口。File类提供了访问文件和目录的方法,FileOutputStream类用于向文件写入数据,而InputStream类用于从文件读取数据。这些类和接口可以帮助您读取和写入本地文件系统上的文件。
- import java.net.HttpURLConnection; import java.net.URL;这些包提供了用于HTTP和URL连接的类和接口。HttpURLConnection类提供了HTTP连接的方法,使您可以发送和接收HTTP请求和响应。URL类则提供了解析和构建URL的方法。
- import java.nio.charset.StandardCharsets;这个包提供了Java支持的所有字符集的常量,如UTF-8、ISO-8859-1等。这些常量用于指定字符编码,以便正确地读取和写入文本数据。
- import java.util.ArrayList;这个包提供了一个动态数组的实现,称为ArrayList。它提供了添加、删除、搜索和遍历数组元素的方法。ArrayList是Java编程中最常用的集合之一,可以方便地存储和操作对象的列表。
/*** 作者:逐梦苍穹* 日期:2023/4/12 8:45*/// 导入所需要的Java类库
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;public class element_ui {// 定义静态变量fileP,表示文件保存的路径static String fileP = "D:\\原C盘“桌面”\\桌面\\日常工具包\\element-ui";// 定义静态变量urlP,表示要爬取的网站的URLstatic String urlP = "https://unpkg.com/browse/element-ui@2.13.0/";// 定义静态变量urlF,表示要爬取的文件的URLstatic String urlF = "https://unpkg.com/element-ui@2.13.0/";public static void main(String[] args) {try {// 调用GetPage方法,开始爬取资源GetPage("");} catch (Exception e) {e.printStackTrace();}}// 定义GetPage方法,用于爬取指定URL下的资源static void GetPage(String after) throws Exception {// 输出当前正在爬取的URLSystem.out.println(urlP + after);// 创建对应的目录,如果已存在则不会重复创建new File(fileP + after).mkdir();// 打开HTTP连接HttpURLConnection http = (HttpURLConnection) (new URL(urlP + after)).openConnection();// 设置请求方法为GEThttp.setRequestMethod("GET");// 设置User-Agent头部信息http.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3562.0 Safari/537.36");// 连接到指定URLhttp.connect();// 如果连接成功if (http.getResponseCode() == 200) { // 检查请求是否成功InputStream inputStream = http.getInputStream(); // 获取响应的输入流byte[] buffer = new byte[1024]; // 定义一个字节数组作为缓冲区ArrayList<byte[]> byteList = new ArrayList<>(); // 定义一个字节数组列表,用于存储读取的数据ArrayList<Integer> byteLength = new ArrayList<>(); // 定义一个整数列表,用于存储每个字节数组的长度int length; // 定义一个整数,用于存储每次读取的字节数int totalLength = 0; // 定义一个整数,用于存储读取的总字节数while ((length = inputStream.read(buffer)) != -1) { // 循环读取输入流中的数据,直到读到末尾byteList.add(buffer); // 将读取的字节数组添加到列表中byteLength.add(length); // 将读取的字节数组长度添加到列表中totalLength += length; // 累加已读取的字节数buffer = new byte[1024]; // 清空缓冲区}http.disconnect(); // 关闭HTTP连接byte[] all; // 定义一个字节数组,用于存储读取的所有数据all = new byte[totalLength]; // 分配足够的空间totalLength = 0; // 重新初始化读取的总字节数while (byteList.size() != 0) { // 循环遍历字节数组列表,将所有字节数组合并成一个大的字节数组System.arraycopy(byteList.get(0), 0, all, totalLength, byteLength.get(0)); // 将当前字节数组拷贝到大数组中totalLength += byteLength.get(0); // 更新已拷贝的字节数byteList.remove(0); // 从列表中删除已经拷贝的字节数组byteLength.remove(0); // 同时删除对应的字节数组长度}String content = new String(all, StandardCharsets.UTF_8); // 将字节数组转换成字符串all = null; // 释放字节数组的空间content = content.split("tbody")[1]; // 切割字符串,只保留tbody标签之后的内容String[] us = content.split("href=\""); // 切割字符串,将所有的链接分割出来for (int i = 1; i < us.length; i++) { // 遍历所有链接String href = us[i].split("\"", 2)[0]; // 提取当前链接的URLif (href.equals("../")) { // 如果是上一级目录的链接,跳过continue;}if (href.charAt(href.length() - 1) == '/') { // 如果是目录的链接,递归调用GetPage方法GetPage(after + href);} else { // 如果是文件的链接,调调用GetFile方法GetFile(after + href);}}} else {// 如果返回的状态码不是 200,就重新调用 GetFile 方法,传入相同的参数GetPage(after);}}static void GetFile(String url) throws Exception {System.out.println(url);HttpURLConnection http;// 创建一个 HttpURLConnection 对象,用于发送 HTTP 请求http = (HttpURLConnection) (new URL(urlF + url)).openConnection();http.setRequestMethod("GET");// 设置请求头 User-Agent 信息,模拟浏览器访问http.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3562.0 Safari/537.36");http.connect();if (http.getResponseCode() == 200) {// 如果返回的状态码是 200,说明请求成功,获取输入流并读取数据InputStream inputStream = http.getInputStream();byte[] buffer = new byte[1024];ArrayList<byte[]> byteList = new ArrayList<>();ArrayList<Integer> byteLength = new ArrayList<>();int length;int totalLength = 0;while ((length = inputStream.read(buffer)) != -1) {// 将读取到的数据保存到一个 byte 数组中byteList.add(buffer);byteLength.add(length);totalLength += length;buffer = new byte[1024];}http.disconnect();byte[] all;all = new byte[totalLength];totalLength = 0;// 将多个 byte 数组拼接成一个 byte 数组while (byteList.size() != 0) {System.arraycopy(byteList.get(0), 0, all, totalLength, byteLength.get(0));totalLength += byteLength.get(0);byteList.remove(0);byteLength.remove(0);}// 将 byte 数组转换为字符串,并对字符串进行处理String filePath = fileP + url.replaceAll("/", "\\\\");// 创建一个新文件File f = new File(filePath);f.createNewFile();// 将文件的内容写入到新文件中FileOutputStream fos = new FileOutputStream(f, false);fos.write(all);fos.flush();fos.close();} else {// 如果返回的状态码不是 200,就重新调用 GetFile 方法,传入相同的参数GetFile(url);}}
}————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_60735796/article/details/130102906