Shuffle Tracking
Shuffle Tracking 是 Spark 在没有 ESS(External Shuffle Service)情况,并且开启 Dynamic Allocation 的重要功能。如在 K8S 上运行 spark 没有 ESS。本文档所有的前提都是基于以上条件的。
如果开启了 ESS,那么 Executor 计算完后,把 shuffle 数据交给 ESS, Executor 没有任务时,可以安全退出,下游任务从 ESS 拉取 shuffle 数据。
1. 背景
如果 Executor 执行了上游的 Shuffle Map Task 并且把 shuffle 数据些到本地。并且现在 Executor 没有 Task 运行,那么此 Executor 是否能销毁?
现状是如果 Executor 没有 active 的 shuffle 数据,则可以被销毁。
active shuffle 的定义:如果 Shuffle Map Stage 的 task 把 shuffle 数据输出到本地。如果依赖此 shuffle 的Stage 没有计算完毕,则称此 shuffle 为 active shuffle。因为依赖此 shuffle 的 Task 可能从 Driver 端获取了 MapStatus,但是还没有拉取完 shuffle 数据。
为了达到此目的,需要跟踪每个 Stage 和每个 Task 的运行信息。并且启动定时任务,定时扫描每个 Executor,判断是否有任务运行,是否有 active 的 shuffle,如果没有则可以退出。
退出有两种,如果开启了 decommission,则到期的 executors 进入 decommission 模式,否则执行 killExecutors。
参数配置
spark.dynamicAllocation.shuffleTracking.enabled: 默认 true,是否开启 shuffle tracking。
spark.dynamicAllocation.shuffleTracking.timeout: 默认 Long.MaxValue,
2. 设计
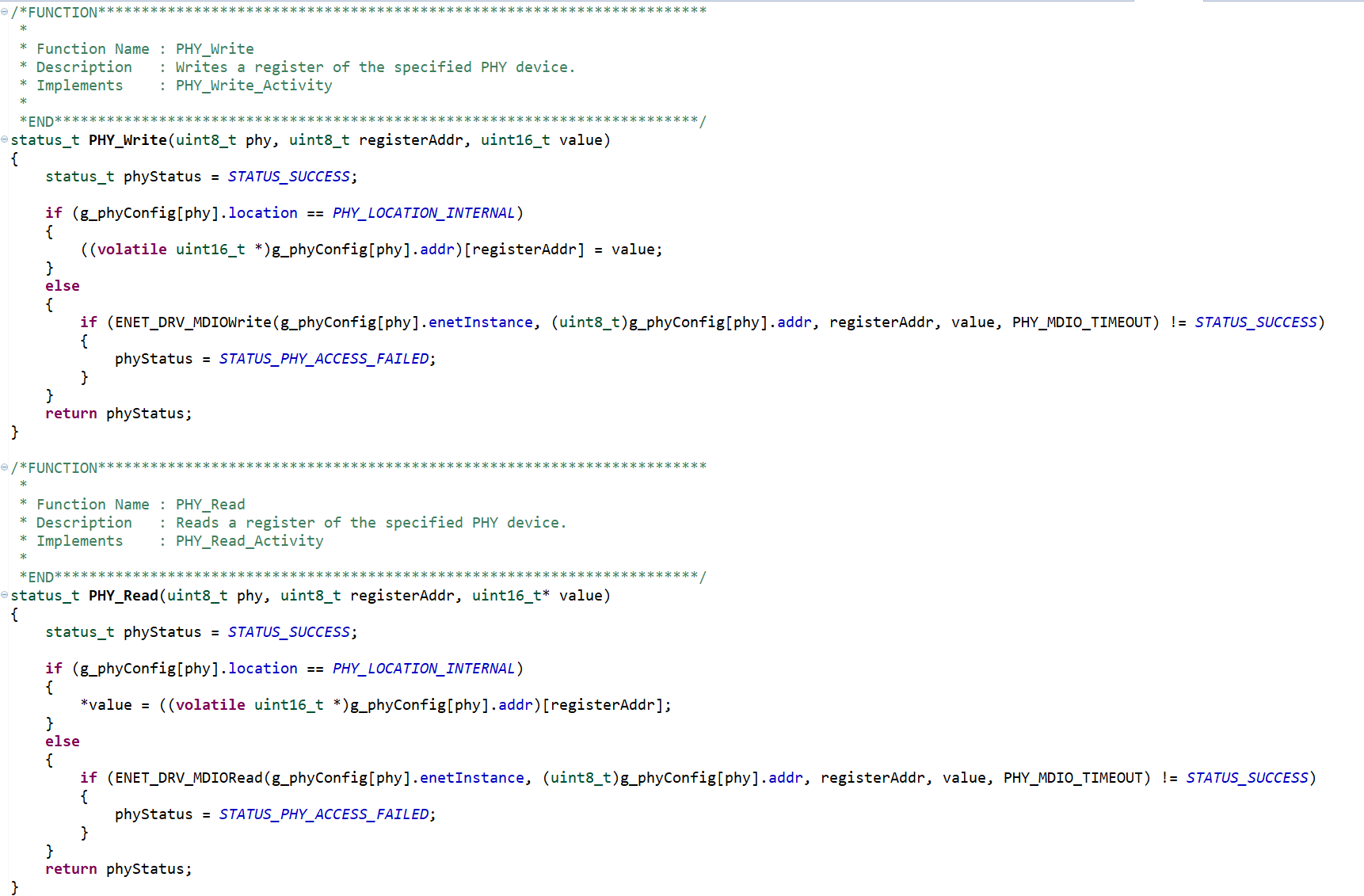
ExecutorMonitor 为每个 Executor 创建一个 Tracker, 用于跟踪此 Executor 的状态。
private val executors = new ConcurrentHashMap[String, Tracker]()
定时任务间隔时间查找 timeout 的 executor,然后处理。
timedOutExecutors 方法的主要逻辑,就是遍历 executors。如果 executor 没有 active 的 shuffle 并且当前时间大于 executor 的超时时间 timeoutAt,则此 executor 可以被安全释放。
为什么 executor 有 active shuffle 数据就不能 kill?
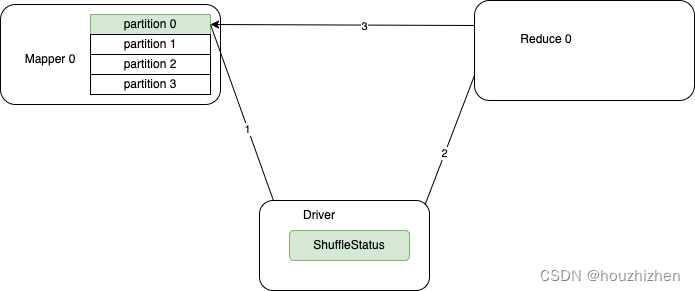
- Shuffle 的过程:
- MapTask 把 shuffle 写到本地,并且把状态汇报给 Driver.
- Reduce Task 从 Driver 获取 shuffle status,并从 shuffle status 获取每个 shuffle 数据的地址。
- 连接对应的 executor 获取 shuffle 数据。
如果在 reduce 获取完 shuffle status 后,MapTask 所在的 Executor 被 kill 掉,Reduce Task 就无法获取 shuffle 数据。
如果执行 decommission 逻辑,把 MapTask 的 shuffle 数据长传到 bos 等分布式存储是否可以?
也是不可以的,因为 reduce 可能已经把 shuffle status 拿走,获取的 shuffle status 没有记录 shuffle 数据在分布式存储上。
参考: ExecutorMonitor,ExecutorAllocationManager
Executor 状态的更新
ExecutorMonitor 实现了 SparkListner 接口,当 Job, Stage, Task 等 start 和 end 时,都会执行回调。
以 hasActiveShuffle 为例
每个 executor 用一个集合 shuffleIds 存储其上拥有的 shuffle 数据。 当其为空时,说明没有 shuffle 数据。
在 onTaskEnd 和 onBlockUpdated 时调用 addShuffle 向 shuffleIds 添加数据。
在以下时机删除 shuffleIds 里的数据。
- 依赖 driver 端的 ContextCleaner,当 ShuffleRDD 仅有 weakReference 时触发。
- rdd.cleanShuffleDependencies 方法,但是此方法仅在 org.apache.spark.ml.recommendation.ALS 使用。
timeoutAt 的计算逻辑
总结:timeoutAt 根据 idle 的时间,spark.dynamicAllocation.cachedExecutorIdleTimeout 和 spark.dynamicAllocation.shuffleTracking.timeout 这 3 个值中最大的值。
详细计算逻辑:
timeoutAt 在一些事件发生时触发计算,如 onBlockUpdated, onUnpersistRDD, updateRunningTasks, removeShuffle, updateActiveShuffles
timeoutAt 的计算逻辑:
当执行器有计算任务时 为 Long.MaxValue。
否则为 max(_cacheTimeout, _shuffleTimeout, idleTimeoutNs)
_cacheTimeout: 如果没有 cache 数据,为0,否则为参数 spark.dynamicAllocation.cachedExecutorIdleTimeout 的值(默认 Long.MaxValue)。
_shuffleTimeout: 如果没有 shuffle数据,为 0, 否则为参数 spark.dynamicAllocation.shuffleTracking.timeout 的值(默认 Long.MaxValue)。
idleTimeoutNs 为 spark.dynamicAllocation.executorIdleTimeout
3. 测试
测试命令
spark-shell \--conf spark.dynamicAllocation.enabled=true \--conf spark.dynamicAllocation.initialExecutors=2 \--conf spark.dynamicAllocation.maxExecutor=400 \--conf spark.dynamicAllocation.minExecutors=1 \--conf spark.shuffle.service.enabled=false \--conf spark.dynamicAllocation.shuffleTracking.enabled=true
参考资料:
https://www.waitingforcode.com/apache-spark/what-new-apache-spark-3-shuffle-service-changes/read