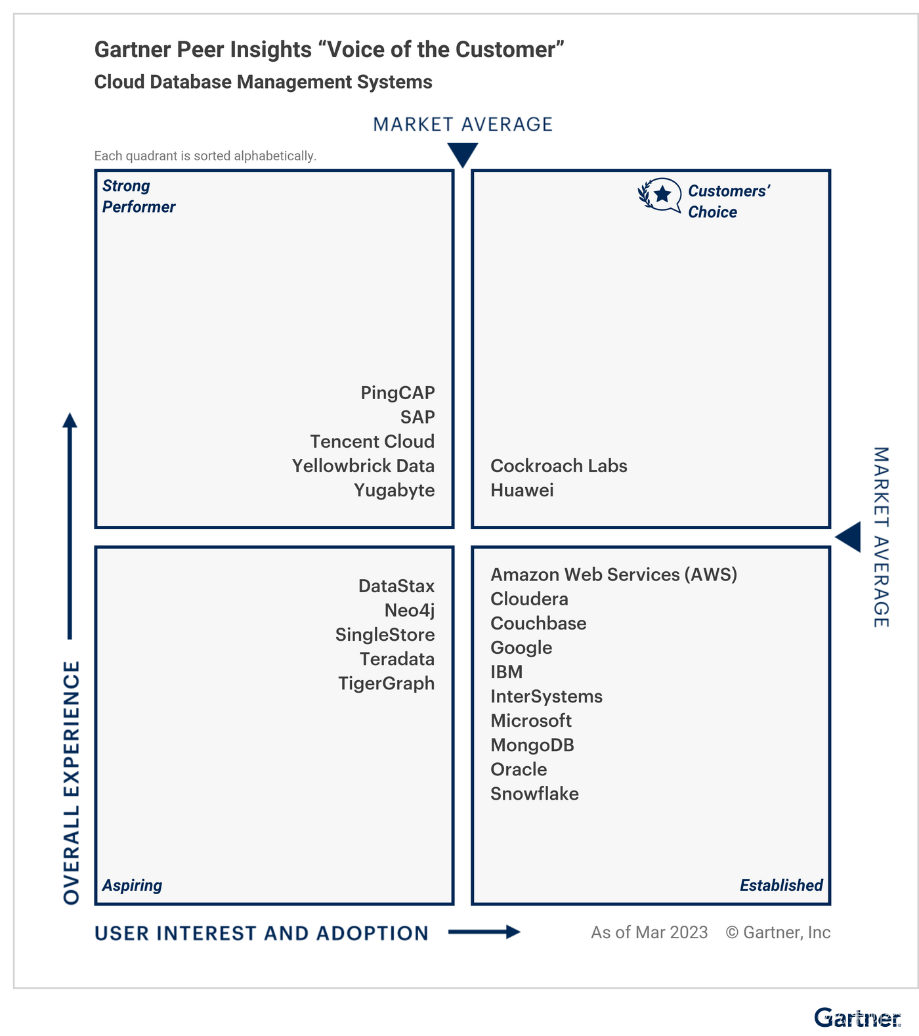
没有一个行业比数据库更需要长期主义,而在践行长期主义的道路上,国内数据库厂商中华为是不可忽视的存在。
近日,Gartner Peer Insights《Voice of the Customer for Cloud Database Management Systems,2023》报告发布,显示华为云成为全球唯一获得云数据库管理系统“客户之选”的云厂商,客户满意和推荐度高达98%。
而此前,在2023年华为全球智慧金融峰会上,华为云正式发布全新一代分布式数据库GaussDB,软硬协同、全栈自主,交出了公司研发数据库二十年来的答卷。
纵观国内外数据库发展史,做好数据库的确并非易事,不仅需要强劲的技术实力,还需要构建完善的商业生态。而且相对于前者,后者可能才是相关厂商成功的关键所在。
从商业替代的角度看,相比甲骨文等在数据库领域积累超过45年的企业,国内数据库厂商虽然已经付出巨大的时间成本和资金投入,但似乎仍处于一个追赶阶段。
而华为云持续深耕数据库领域,并成为“客户之选”,是否意味着真正的国产化替代已经来到?

图片来源:网络
数据库60年,向商业繁荣而生
芯片、操作系统和数据库并称为科技领域的三大基础设施。
相比前两者,数据库并不是日常新闻中的“主角”。但事实上,几乎所有的商业系统都需要数据库来进行组织、储存、管理与调用。因此,数据库也被称为“基础软件皇冠上的明珠”。
1964年,通用电气公司开发出了世界上第一个数据库系统——IDS。自此之后的60年,美国开启了一轮又一轮的数据库技术浪潮。直至今日,美国依然在数据库行业占据领先地位。
而为了增强竞争力,摆脱对国外技术和产品的依赖性,国内数据库厂商也在持续推进数据库研发,以尽早实现国产化替代。在2009年,阿里巴巴就率先提出“去IOE”的概念。所谓“去IOE”,是指在IT基础架构中排除IBM的小型机、Oracle数据库和EMC高端存储,代之在开源软件基础上开发的系统。
然而,十多年过去了,国产数据库依然没有占据主导地位。根据公开数据显示,国外厂商仍然占据中国数据库市场份额超50%,微软、亚马逊、甲骨文这几家巨头的地位难以动摇。
技术实力不足可能是一方面的原因。根据信通院发布的数据显示,截至2022年6月,全球数据库企业为363家,其中美国145家、中国116家。在中国的这些企业中,只有3家企业的规模达到了千人以上,而甲骨文等美国数据库厂商的规模已达数万人,反映出较大的人才储备差距。
另据公开资料显示,美国开源和商业数据库的占比为48%和52%,我国为83.4%和16.6%,可以看出,国内数据库主要基于开源技术开发,自主研发较少,技术方面有较大提升空间。
而相比技术优势,国外厂商数据库生态的商业优势可能更难超越。比如,占据市场主要份额的甲骨文早早完成了自身的数据库生态建设。2009年,甲骨文推出合作伙伴计划(OPN),在全球的合作伙伴早已突破2.5万家。

图片来源:甲骨文,OPN官方网站
这也意味着,第三方产品及服务基本可以解决绝大多数甲骨文数据库的异常问题。对比来看,目前国内不少数据库软件仍然依赖原厂商的技术支持,难以形成完整的商业生态,这也成为实现国产化替代道路上的一大阻力。
但国产数据库并非完全没有机会。当迁移收益远远大于迁移成本,产品替代就会自然而然地发生。
2012年,亚马逊从自身业务的实际需求出发,推出分布式存储系统DynamoDB。在这之后,分布式云数据库开始飞速发展,不断抢占传统数据库的重要阵地。传统数据库看似固若金汤的“马奇诺防线”,正在遭遇分布式云数据库的“闪电战”。
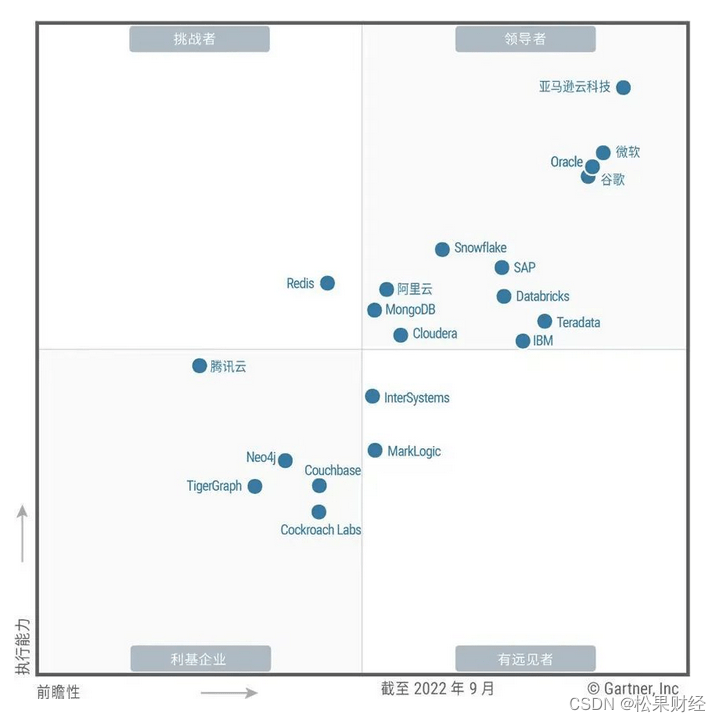
资料来源:Gartner《云数据库管理系统魔力象限》
亚马逊的DynamoDB为什么能获得成功,并迅速成为数据库行业的领导者?这主要归功于电子商务这一全新的商业场景。在该商业场景下,亚马逊的DynamoDB体现出极强的迁移收益,因此越来越多的企业选择了“亚马逊方案”。
可以这样理解,更高的迁移收益实际上来源于商业场景的进化。纵观整个数据库的历史,通用电气、IBM、霍尼韦尔、亚马逊、阿里巴巴等企业都因为新的商业场景而进一步发展了数据库技术。
而对于华为等数据库厂商而言,想要自身的技术路线得到认可,就必须找到面向未来的新商业图景。这个新商业图景包括更前沿的技术概念、更优秀的性能处理以及更完善的商业生态。
GaussDB 20年,从技术可行到生态建设
2001年,为了支持自身的电信业务,华为开始研发数据存储组件DopraDB。十年后,华为成立Gauss实验室,DopraDB也成为GaussDB的GMDB V1系列产品。而后,再走过十年左右的时间,如今GaussDB已经完成了华为内部600多套数据库的全面替换,累计建设超过6000个分布式数据库节点,承载数据量高达6PB,并借此次发布会的机会,成功从幕后走到了台前。
走到台前的路途多少有些艰难,打造技术优势只是万里长征的第一步。
所谓打造技术优势,本质上可以拆解成两件事:提高数据库性能和保障数据库安全。作为国内唯一同时做到软硬协同、全栈创新的自研数据库,GaussDB在性能和安全上都实现了新的突破。
比如,性能方面,在招商银行的实际应用中,GaussDB的抖动率比其他厂商减少了85.6%;在与邮储银行的合作中,邮储银行向华为开放了6.5亿用户用于建设分布式新核心系统,和原有的系统相比,GaussDB的效率提升了40%。而故障处理方面,2023年,GaussDB在工行核心信贷系统中,上线了同城双集群RPO=0方案。与原先甲骨文数据库双集群方案需15-30分钟进行故障修复相比,GaussDB仅需2分钟。

资料来源:华为云GaussDB发布会
然而在数据库领域,技术领先并不代表商业成功。可以这么说,技术优势是商业成功的下限,生态建设是商业成功的上限,也是国内数据库厂商急需突破的枷锁。而在构建商业生态的过程中,确定好从什么行业入手至关重要。
从当前情况来看,金融行业已成为国内数据库厂商瞄准的一大领域。
对比其他行业,金融行业具有数据量大、性能要求高、故障容忍度低的特点。同时,该行业对数据库国产化替代的需求也极为旺盛。从2022年国产数据库的中标信息看,46%的采购单位集中在金融行业,其次是政府。因此,金融行业可以说是一片挖掘商业价值的“广阔天地”,能啃下这块“硬骨头”的数据库厂商,在面对其他商业应用时也会更加游刃有余。
基于此,和OceanBase、腾讯TDSQL一样,GaussDB将金融场景作为重点发力的商业应用。目前,GaussDB已广泛应用于金融行业,助力中国建设银行、中国农业银行等国有大行的核心业务运转。
但只有金融场景是远远不够的,想要深入更多商业场景,数据库厂商必须和独立软件开发商建立联系,形成连接上下游的全面产业协同。如果商业应用的目标是解决特定行业的特定问题,那么产业协同的终极就是建立更普适的系统方案。
面对甲骨文等领先者的先发优势,开源也许是后来者整合产业资源最重要的工具。从2022年开始,国产数据库厂商开始陆续推出自家的开源产品,例如阿里云Polar-X的开源项目X-Paxos、蚂蚁集团CeresDB的开源项目CeresDB 0.2.0、华为云GaussDB的开源项目OpenGemini等。
不过,开源是一种相对被动的产业协同,更主动的办法是与上下游建立合作关系。由于数据库软件并不是一个孤立的系统,其中包含数据库迁移、备份恢复、容灾、一站式运维、数据库咨询服务、数据库培训等解决方案,因此近年来相关厂商都在谋求更多合作机会,以打通商业链条各环节。
比如,从阿里独立出去的OceanBase陆续与基础硬件厂商、软件服务厂商等建立产品适配认证体系,而华为也携手17家软件伙伴企业、7家服务伙伴企业,共同启动了GaussDB数据库金融行业生态发展计划。
但正如前文所说,生态建设成功的标志是迁移收益高于迁移成本。就这一点而言,华为能再现亚马逊DynamoDB的成功吗?结合产品功能和行业需求来看,还是存在一定的可能性。
据了解,华为云GaussDB具有易部署、易迁移的特性,可以实现存储成本下降50%,整体资源利用率提升4倍以上,同时通过提供结构+数据一站式迁移解决方案,最大程度满足相关行业的需求,并有望借助应用模式复制,走向更多场景。
当然,华为云GaussDB问世不等于数据库的国产化替代已经完成。需要看到,国内数据库厂商所面对的是一片“蓝海”。2018年,“信创”被纳入国家战略,并提出了“2+8+N”的发展体系。其中,“N”是指国内市场的千行百业。另外,数据显示,预计到2025年,我国数据库市场规模将达688亿元,CAGR为23.4%。

在这种背景下,华为云GaussDB的发布自然不会是国产数据库的终局,而可能是一个崭新的开端。未来,随着国产化替代的深入,国产数据库将有机会在更多行业中发挥价值。
作者:添泽Tyler
来源:松果财经