我们进入到淘宝商品数据页面,按F12打开开发者模式,对页面进行观察,我们发现淘宝页面是Ajax方式加载的,而且它的接口参数很复杂且没有固定的规律,但是Selenium又被淘宝反爬限制了,所以我们不能使用Ajax来获取商品数据。获取淘宝API调用地址
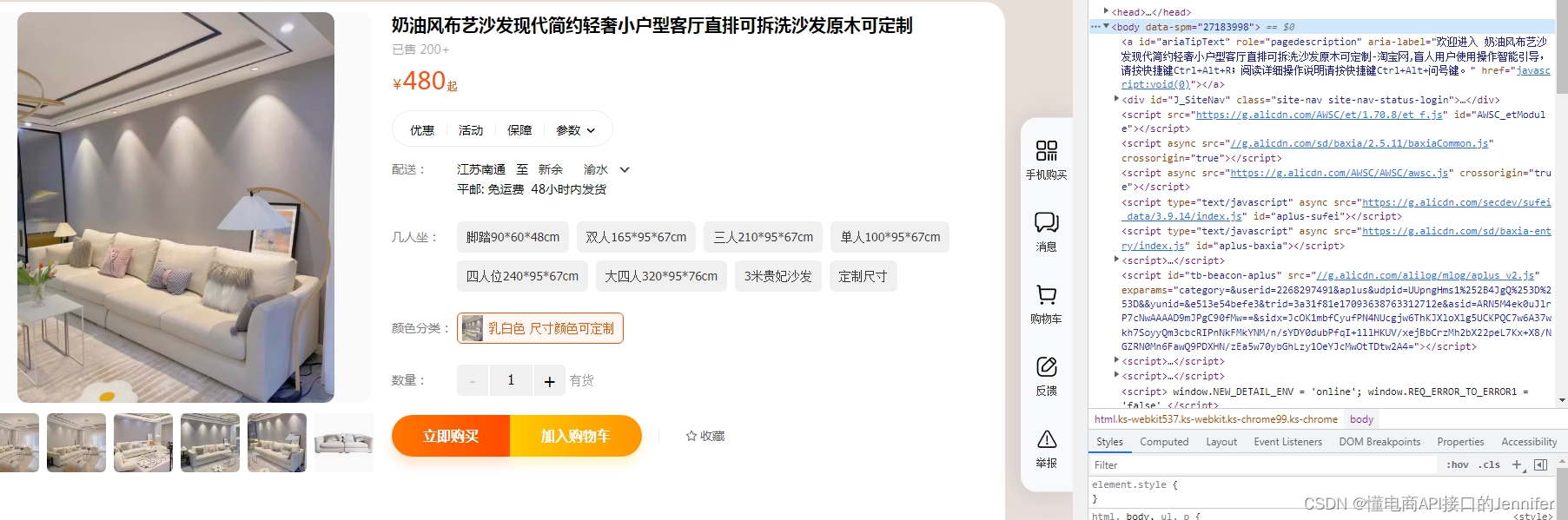
在这时,我突然发现页面的数据在源网页里面存放着。如图:

登录爬取
当我们将Requests和Cookie构造好,我们尝试对商品网页发送请求,我们发现可以请求到数据了,并且也没有被反爬限制。我们终于解决了反爬带来的困扰,现在就只需要将数据爬取下来并存储就大功告成了!
提取数据
我们通过对数据存储方式进行观察发现,用正则表达式来对数据进行提取是最为方便的。代码如下:
shangpinming = re.findall('"raw_title":"(.*?)"',response.text)
jiage = re.findall('"view_price":"(.*?)"',response.text)
fahuodi = re.findall('"item_loc":"(.*?)"',response.text)
fukuanrenshu = re.findall('"view_sales":"(.*?)人付款"',response.text)
dianpumingcheng = re.findall('"nick":"(.*?)"',response.text)
数据存储
我们这里直接放入代码:
csv_file = open('pingban_1.csv', 'a', newline='', encoding='utf-8')
writer = csv.writer(csv_file)
for i in range(44):try:writer.writerow([dianpumingcheng[i],shangpinming[i],jiage[i],fahuodi[i],fukuanrenshu[i]])with open('shangpinmingcheng_1.txt','a',encoding='utf-8') as f:f.write(shangpinming[i])except:pass
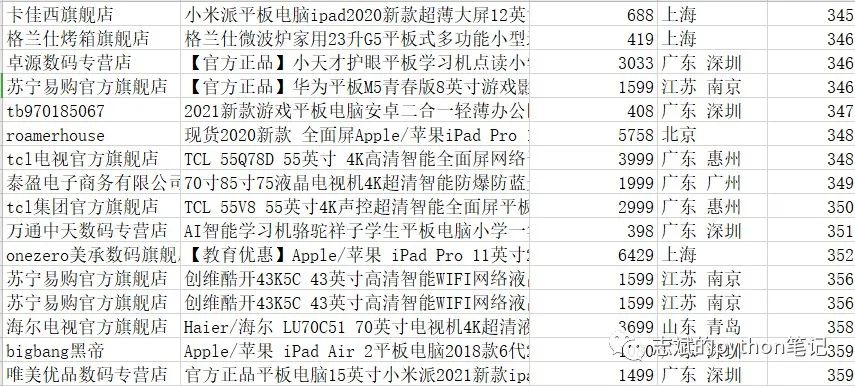
csv_file.close()让我们来看看存储的数据: