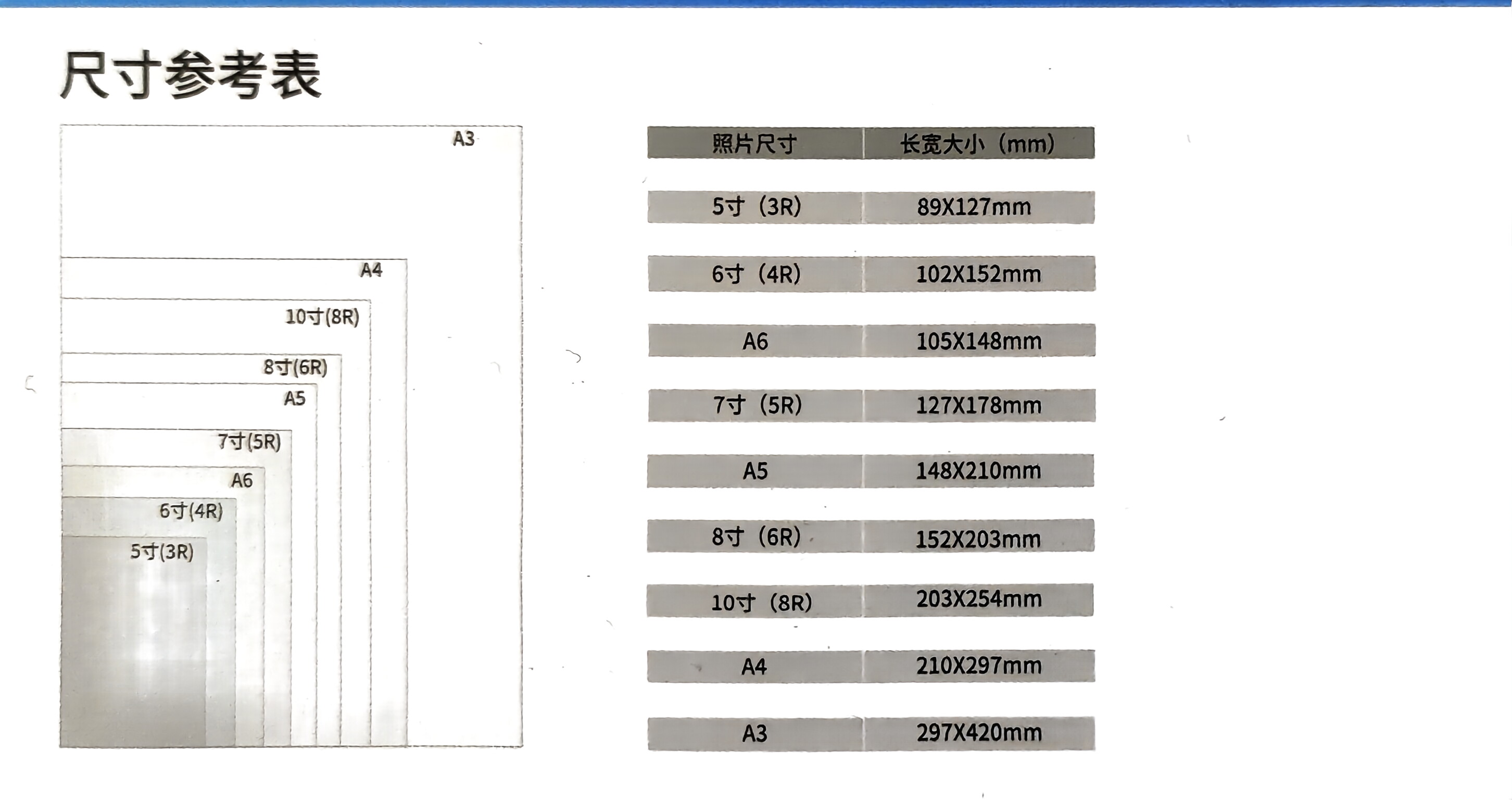
中心化特征金字塔(CFP) = 特征金字塔 + 显式视觉中心(EVC)+ 全局集中调节(GCR)
- 提出背景
- 中心化特征金字塔(CFP)
- CFP 架构图
- 问题:不同尺度的对象检测
- 问题:有限感受野
- 问题:全局和局部特征的有效整合
- 不同尺度的对象检测
- 有限感受野
- 全局和局部特征的有效整合
- 小目标涨点
- YOLO v5 魔改
- YOLO v7 魔改
- YOLO v8 魔改
提出背景
论文:https://arxiv.org/pdf/2210.02093.pdf
代码:https://github.com/QY1994-0919/CFPNet
在计算机视觉领域,特别是在目标检测任务中,我们的目标是让计算机能够从图片中识别和定位出各种对象,比如人、车辆、动物等。
这个任务听起来简单,但实际上非常复杂,因为图片中的对象大小不一,有的远有的近,还可能部分被遮挡,光照条件也各不相同。
为了解决这个问题,研究人员发明了一种名为“特征金字塔”的技术。
想象一下,你有一堆不同大小的筛子,通过这些筛子过滤沙子,大的留在上面,小的落到下面。
类似地,特征金字塔可以帮助模型捕获不同尺度(大小)的对象信息,使得无论对象大小如何,都能被有效识别。
然而,使用传统的卷积神经网络(CNN)作为基础,尽管有了特征金字塔的帮助,但还是有一些局限性,比如它们难以捕捉到图片中的全局信息,比如整个场景的布局,或者是图片角落里的细节。
最近,一种名为“视觉变换器”(Vision Transformer)的新技术开始被应用于目标检测,它通过将图片分割成小块(称为Patch),然后通过一种特殊的机制(称为注意力机制)来分析这些块之间的关系,从而捕获全局的信息。
但是,这种方法计算量很大,而且有时候会忽略图片中一些重要的细节部分。
为了克服这些问题,本文提出了一种新的方法,名为“中心化特征金字塔”(CFP)。
它的核心思想是在特征金字塔的基础上,通过一个轻量级的机制来专门捕捉图片中的全局信息和局部细节。
简单来说,它就像是在原有的筛子上,加了一个能够调节的镜头,既能看到全景,也能聚焦到细节。
通过这种方法,无论是远处的小车还是近处的行人,甚至是角落里的小细节,都能被有效地识别出来。
实验结果显示,这种新方法在一些标准的测试集上,比如MS-COCO(一个广泛使用的计算机视觉数据集),能够实现更好的识别效果。
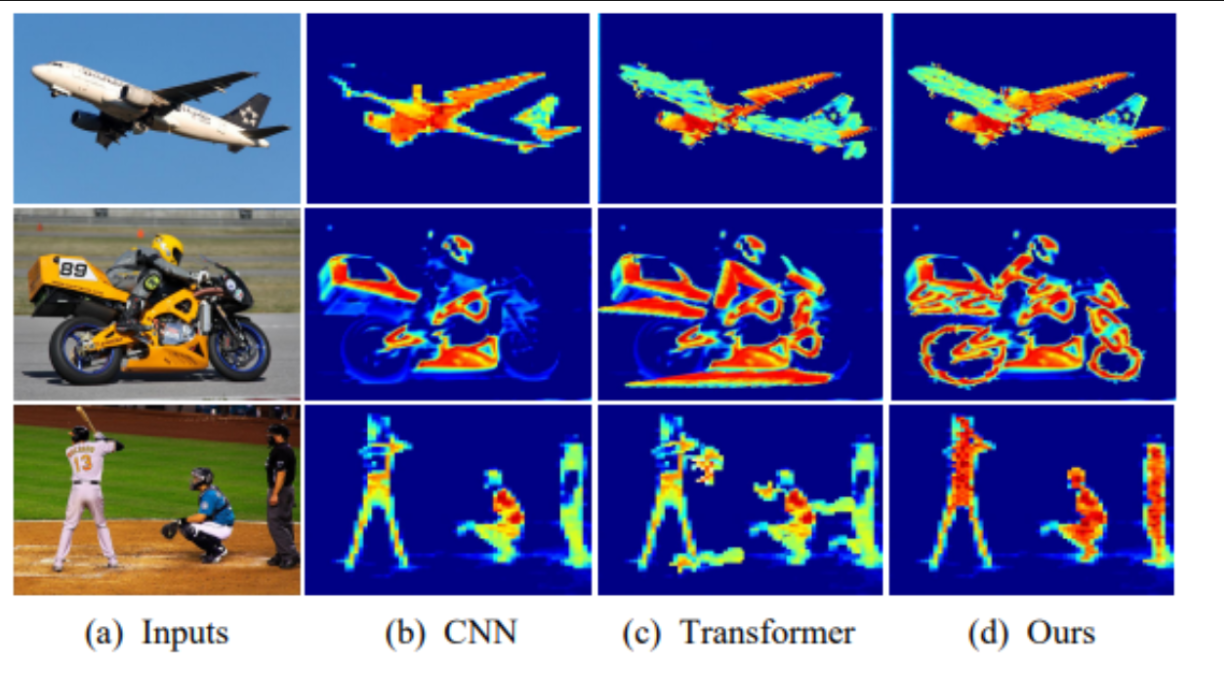
- (a) Inputs:展示了原始输入图像。
- (b) CNN:展示了使用卷积神经网络模型处理输入图像后的特征可视化,它主要关注最有区别性的区域。
- © Transformer:展示了使用Transformer模型(一个基于注意力机制的模型)处理同一个输入图像后的特征可视化,它能看到更宽的范围,但通常忽略对密集预测任务重要的角落线索。
- (d) Ours:展示了使用你的模型(可能是中心化特征金字塔CFP模型)处理输入图像后的特征可视化,这个模型不仅能看到更广的范围,而且通过利用高级长距离依赖性的集中化约束,实现了更全面的特征表示,更适合密集预测任务。
图片的文字说明强调了使用CFP模型可以提供更全面的视觉特征表示,这在处理那些需要精确空间定位的复杂视觉任务中特别有价值,比如密集的目标检测或场景解析任务。
以自动驾驶为例自动驾驶系统需要准确识别和定位包括行人、车辆、交通标志等多种对象。
这些对象的大小、形状和出现在图像中的位置可以大相径庭,从远处的小汽车到近处的大型卡车,再到路边的交通标志牌。
问题:对象大小的不确定性导致单一特征尺度无法满足高精度识别性能的需求。
- 解法:基于网络内特征金字塔的方法。
- 之所以使用基于网络内特征金字塔的方法,是因为这种方法能够为不同大小的对象分配合适的上下文信息,并在不同的特征层上识别这些对象。
- 实例: 在自动驾驶的对象检测系统中,采用基于网络内特征金字塔的方法,可以为每个不同大小的对象分配最合适的特征层进行识别。
- 例如,远处的小汽车可能在较深的特征层上被识别,因为这些层捕获了更抽象的、全局的信息;而近处的大型卡车或路边的交通标志牌可能在较浅的特征层上被识别,这些层包含更多的局部、详细的信息。
问题:现有方法基于CNN骨架,受限于固有的感受野限制。
- 解法:使用视觉变换器基于对象检测方法。
- 之所以使用视觉变换器,是因为它们通过将输入图像分割成不同的图像块,并使用多头注意力机制在块之间进行特征交互,来获取全局长距离依赖性,从而解决了CNN中有限的感受野和局部上下文信息问题。
- 实例: 通过采用视觉变换器方法,如Swin Transformer,自动驾驶系统的对象检测模块能够处理整个图像分割成的小块,使用多头注意力机制在这些块之间进行特征交互,从而实现对长距离依赖性的捕获。
- 这样,系统即使在复杂的场景中也能准确识别出每个对象的精确位置和类别,包括那些在图像角落或边缘部分的对象。
问题:视觉变换器方法存在大计算复杂性,且易忽略对密集预测任务重要的角落区域。
-
解法:提出中心化特征金字塔(CFP)网络。
- 子特征1:空间显式的视觉中心方案。
- 之所以使用空间显式的视觉中心方案,是因为它能通过轻量级MLP架构捕获长距离依赖性,并通过并行可学习的视觉中心机制汇聚输入图像的局部关键区域。
- 子特征2:全局中心化调节。
- 之所以使用全局中心化调节,是因为通过在自顶向下的方式对提取的特征金字塔进行调节,使用从最深特征获得的空间显式视觉中心来同时调节所有前面的浅层特征,能够高效地获得全方位且具有区分性的特征表示。
- 实例: 在自动驾驶的对象检测系统中引入CFP网络,首先通过CNN骨架提取特征金字塔,然后利用空间显式的视觉中心方案捕获长距离依赖性并聚合输入图像的关键局部区域。
- 接着,采用全局中心化调节策略,使用从最深层特征提取的视觉中心信息来优化和调节所有前面的浅层特征。
- 这种方法不仅提高了对象检测的准确性和效率,也确保了即使是图像中的边缘和角落区域的对象也能被准确识别,非常适合于自动驾驶系统在复杂多变环境中的应用需求。
- 子特征1:空间显式的视觉中心方案。
中心化特征金字塔(CFP)
CFP 主要包括如何有效处理不同尺度的对象,如何克服有限感受野的问题,以及如何捕获全局和局部的重要特征。
CFP特别关注于层间特征交互和层内特征调节,从而克服了现有方法在这方面的不足。
想象一下,我们的任务是在一张照片中找到并标记出所有的对象,比如人、车、树等。
这个任务对于人来说可能很直观,但对于计算机来说却非常复杂。
原因之一是照片中的对象大小不一,有的远有的近,这就需要一种能处理不同大小对象的智能方法。
1. 处理不同大小的对象: 为了解决这个问题,CFP使用了一种叫做“特征金字塔”的技术。
你可以将其想象为一系列的滤镜,每个滤镜捕捉不同大小的细节。
就像用不同密度的网捕捉不同大小的鱼一样。这样,无论对象是大是小,都能被发现。
2. 看到全景和细节: 但仅有大小的处理还不够,我们还需要让计算机“看到”照片的全景(全局上下文)和重要的细节。
这里,CFP用到了类似于人类注意力的技术,让计算机能够专注于照片中的关键部分,同时也不忽视整体场景。
这就像当你看一张照片时,你的视线可能会被某个特别的细节吸引,但你仍然对整个画面有所感知。
3. 提高识别的准确性: 最后,为了让计算机更准确地识别出照片中的对象,CFP采用了一种特别的计算方法(MLP),这种方法帮助计算机更好地理解照片中的信息,就像提高它的“智商”一样,让它更聪明地识别出各种对象。
CFP就是一种让计算机在查看照片时,能够处理不同大小的对象,同时关注到全局和局部的重要细节,最终更准确地识别出照片中的对象的技术。
CFP 架构图
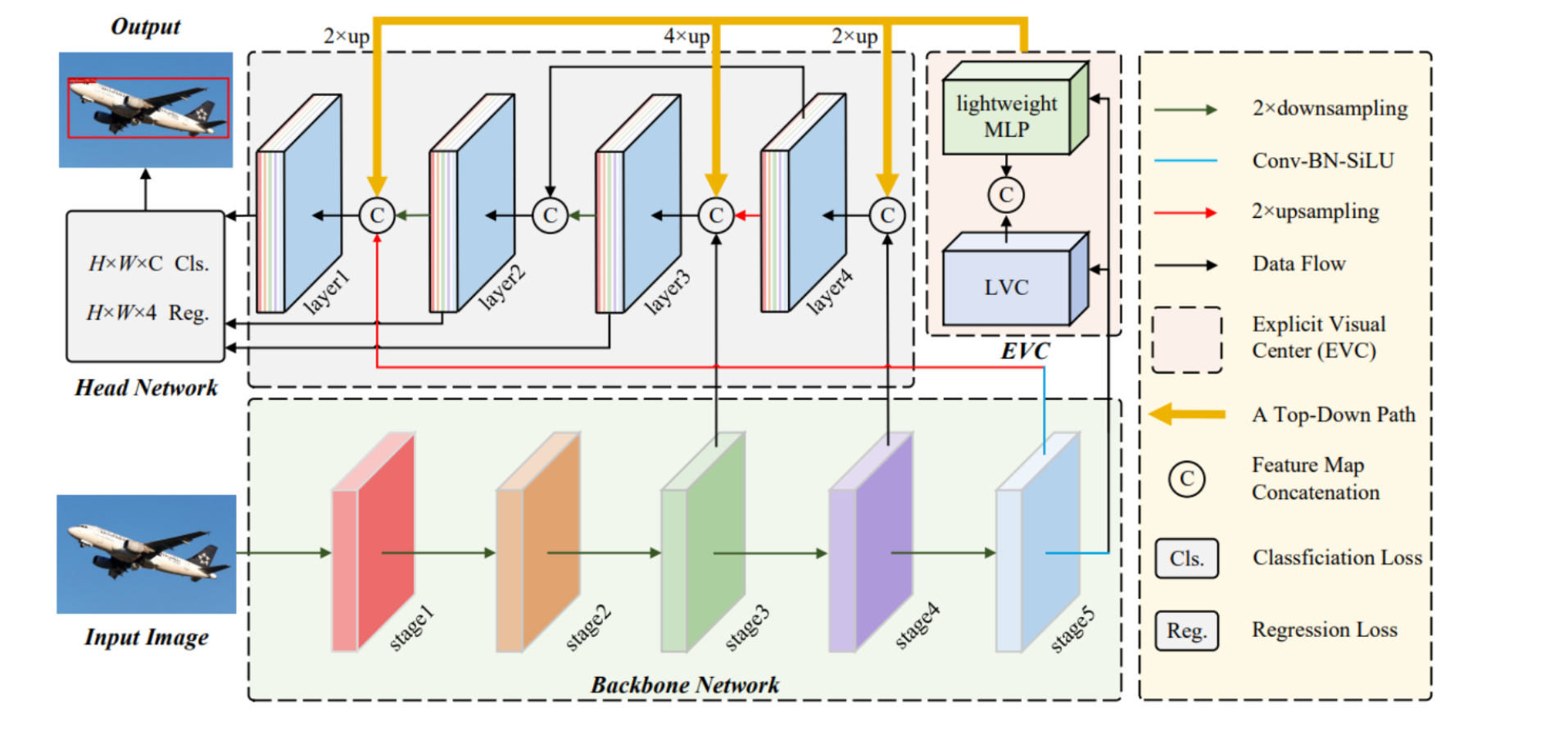
-
(a) 输入: 这部分很可能展示了模型设计用来处理的原始输入图像。这些图像可能包含需要被检测的各种对象。
-
(b) CNN: 这部分可能展示了输入图像经过卷积神经网络(CNN)处理后的特征激活或响应。CNN是一种常用于图像识别任务的深度学习模型。它们能够捕捉到如边缘、纹理等的模式和特征。
-
© 变换器: 这里的图像可能被一个变换器模型处理,变换器是另一种利用自我关注机制来捕捉数据中全局依赖性的神经网络。它特别擅长考虑图像的整体上下文。
-
(d) 我们的(CFP): 最后这个部分展示了所提出的CFP模型的输出。这些图像将展示模型不仅能检测主要对象,还能捕捉到更精细的细节,并可能涵盖图像中更多的上下文区域。这表明CFP可能在理解整个场景方面更为有效,不仅仅是最突出的特征。
图片下方的文本通常解释了所提出的CFP方法相对于传统CNN和变换器模型的优势,强调其捕捉对于密集预测任务(如复杂场景中的目标检测)至关重要的全局和局部线索的能力。
所描述的架构可能展示了CFP是如何整合由CNN骨干网络提取的特征,并通过一系列步骤(可能涉及MLP和其他机制)来提高目标检测性能的。
问题:不同尺度的对象检测
- 解法:特征金字塔的构建
- 子特征1:多层级特征提取。
- 之所以构建多层级的特征提取,是因为它可以捕获从细粒度到粗粒度的不同尺度特征,这对于处理图片中大小不一的对象至关重要。
问题:有限感受野
- 解法:引入视觉变换器组件和空间显式视觉中心(EVC)
- 子特征2:轻量级MLP和视觉中心机制的应用。
- 之所以结合轻量级MLP和视觉中心机制,是因为它们能够同时捕获全局长距离依赖性和局部重要区域,解决了传统CNN由于感受野限制而忽视的问题。
问题:全局和局部特征的有效整合
- 解法:全局集中调节(GCR)
- 子特征3:全局信息与浅层特征的融合。
- 之所以采用全局集中调节,是因为它通过顶层的全局信息来优化前端浅层特征,实现全局和局部信息的有效整合,提高了模型对于不同对象的识别能力。
CFP通过构建特征金字塔捕获不同尺度的特征,利用轻量级MLP和视觉中心机制扩展模型的感受野,以及通过全局集中调节机制整合全局与局部特征,有效提升了目标检测的准确性和效率。
这种方法能够更全面和差异化地表示图像特征,从而在复杂的目标检测任务中取得更好的性能。
将上述中心化特征金字塔(CFP)的解决方案与前文提供的城市街景对象检测的案例结合起来,可以帮助我们更深入地理解CFP是如何在实际应用中解决具体问题的。
不同尺度的对象检测
在城市街景中,我们需要识别的对象大小各异,从远处的小狗到近处的大楼都可能是目标。
特征金字塔的构建允许模型通过多层级特征提取来处理这种多尺度变化,确保无论对象的大小如何,都可以被有效地识别。
例如,精细的特征层可以捕捉到远处小狗的细节,而粗糙的特征层则有助于识别近处的大楼。
有限感受野
城市街景图像中的关键信息可能分布在整个图像中,包括一些细节和全局布局。
引入视觉变换器组件和空间显式视觉中心(EVC)通过轻量级MLP和视觉中心机制共同工作,既可以捕捉到整个场景的全局布局,也可以关注到街角的特定细节,如远处的交通标志或街道角落的行人,从而克服了传统CNN模型由于有限感受野而可能忽略的重要信息。
“显式视觉中心”(EVC)是中心化特征金字塔(CFP)方法中的一个组件。
在CFP的上下文中,EVC被设计用于捕获和强调输入图像中的关键区域,尤其是那些对于目标检测任务来说重要的局部角落区域。
EVC通过一个轻量级的多层感知器(MLP)结构来处理这些局部特征,并将它们整合进模型的中心化特征学习过程中。
简单来说,CFP提供了一个框架,它使用不同的技术和机制来优化目标检测任务。
EVC是这个框架内的一个模块,专注于改进图像特征的局部表示。
这样的设计允许CFP方法更加精确地识别和定位图像中的对象,包括那些在图像边缘或角落的对象。
通过集中和利用这些通常被忽视的局部特征,CFP能够提供更全面、更准确的目标检测性能。
(EVC)的组件:
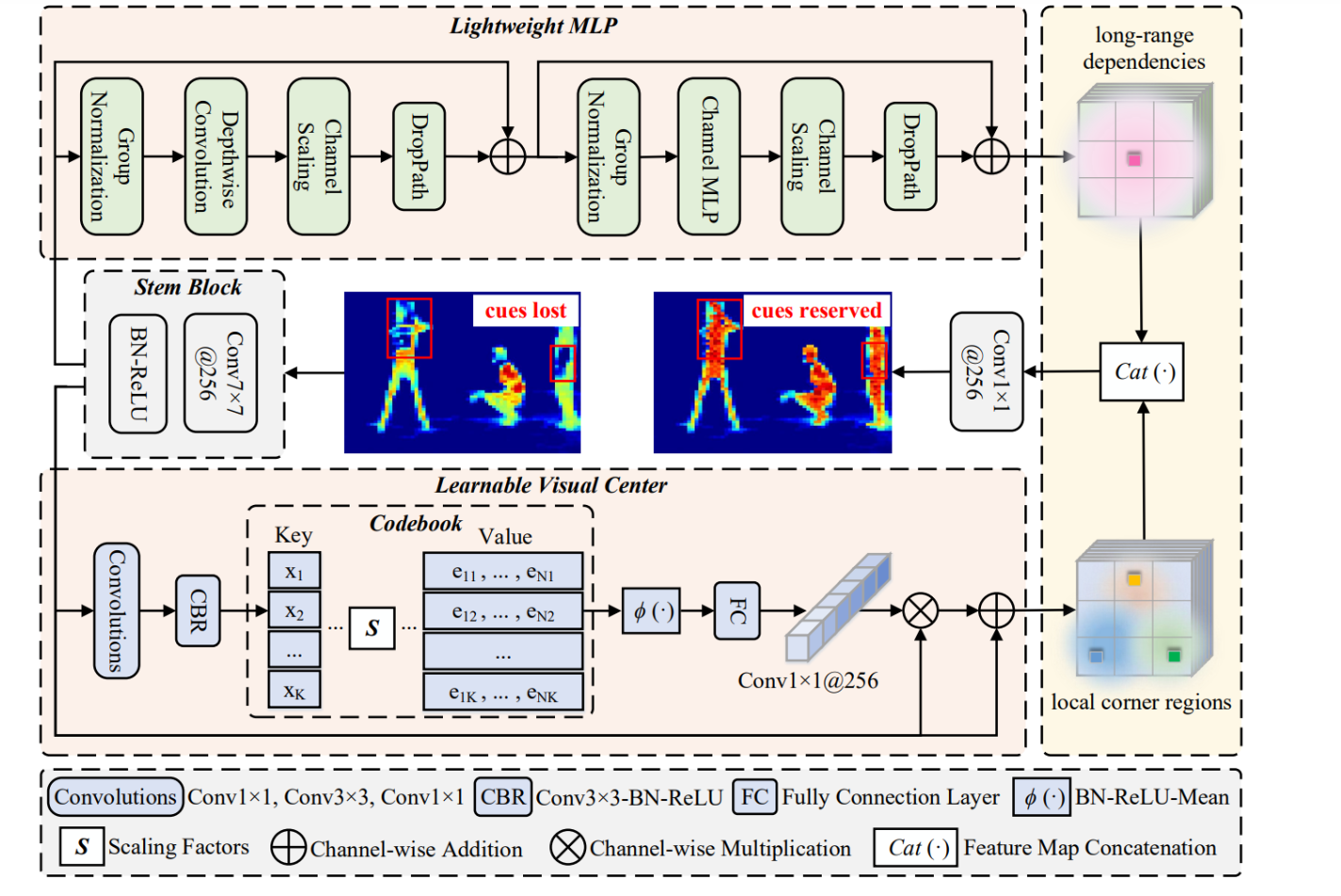
图中的内容可以分为几个部分:
-
轻量级 MLP(多层感知器):这是一个用于处理图像的深度学习网络结构,用于捕获图像中的长距离依赖性,也就是图像中不同部分之间的联系。
它通过一系列层来处理图像,包括标准化层(Norm)、分组卷积层(Group Convolution)、通道混合层(Channel MLP)和DropPath操作,这通常是为了提高网络的泛化能力和鲁棒性。
-
Stem Block:这是一个特殊的网络结构,通常在模型的开始处使用,用于初步处理输入图像,准备特征供后续的网络层使用。
-
Learnable Visual Center:这是一个可学习的视觉中心编码器,用于聚合图像的局部角落区域的特征。
这可以帮助模型在进行目标检测时更好地识别图像中的边缘和角落,这些区域通常包含关键的信息但可能会在传统模型中被忽略。
-
Codebook 和 Scaling Factors:这表示模型中使用的编码器和缩放因子,用于处理特征并将它们映射到一个更易于分类和检测的空间。
图中还提到了一些操作,如“Conv1x1@256”表示使用1x1的卷积核和256个通道,“Cat (·)”表示特征图的连接操作。
这些都是深度学习中常用的操作,用于组合和优化从输入图像中提取的特征。
全局和局部特征的有效整合
为了确保模型不仅能看到整个图片的全局信息还能关注到局部细节,全局集中调节(GCR)通过全局信息与浅层特征的融合来实现。
这意味着模型可以利用从顶层特征中提取的全局信息来优化浅层特征,使得即使是在复杂多变的城市街景中,模型也能准确识别和定位各种对象,如行人、车辆、交通灯等。
CFP方法通过特征金字塔、视觉注意力学习,以及轻量级MLP架构(用于捕获全局的长距离依赖性),解决了城市街景对象检测中的关键挑战,包括处理不同尺度的对象、克服有限感受野的问题,以及有效整合全局和局部特征。
小目标涨点
更新中…