MySQL知识点总结(七)——主从复制、读写分离、高可用、分库分表
- 主从复制
- 主从复制原理
- 主从复制配置
- 主节点
- 从节点
- 主从复制的多种类型
- 一主一从
- 一主多从
- 多主一从
- 双主复制
- 级联复制
- 主从复制的多种模式
- 异步复制
- 全同步复制
- 半同步复制
- 主从复制延迟及其解决办法
- 读写分离
- 读写分离的实现方式
- 读写分离如何保证写入马上可被读取到
- 高可用
- MMM
- MHA
- MGR
- 分库分表
- 垂直分库
- 垂直分表
- 水平分库 & 水平分表
主从复制
在生产环境,通常会给MySQL配置主从同步,一方面是可以达到热备的效果,当主节点宕机,从节点可以顶上,另一方面是从节点可以提供查询以缓解主节点的压力。
主从复制原理
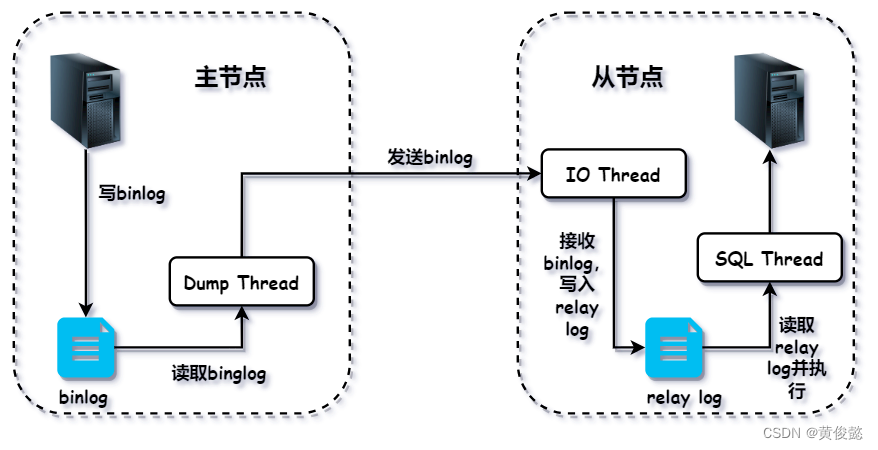
首先,如果我们要配置主从复制,第一步肯定是要开启主节点的binlog,因为主从复制是基于binlog的。当我们开启了主节点的binlog之后,主节点执行的增删改SQL都会写入到binlog中。
当主节点接收到从节点的主从复制的请求后,会开启一个Dump线程,专门进行主从复制。Dump线程会读取主节点上的binlog,发送到从节点。
当从节点开启主从复制后,会开启一个IO线程,请求主节点进行主从复制。IO线程会接收到由主节点的Dump线程发来的binlog,写入到从节点的relay log(中继日志)。
然后从节点还会开启一个SQL线程,读取relay log,然后执行relay log中的SQL,应用到从节点。
主从复制配置
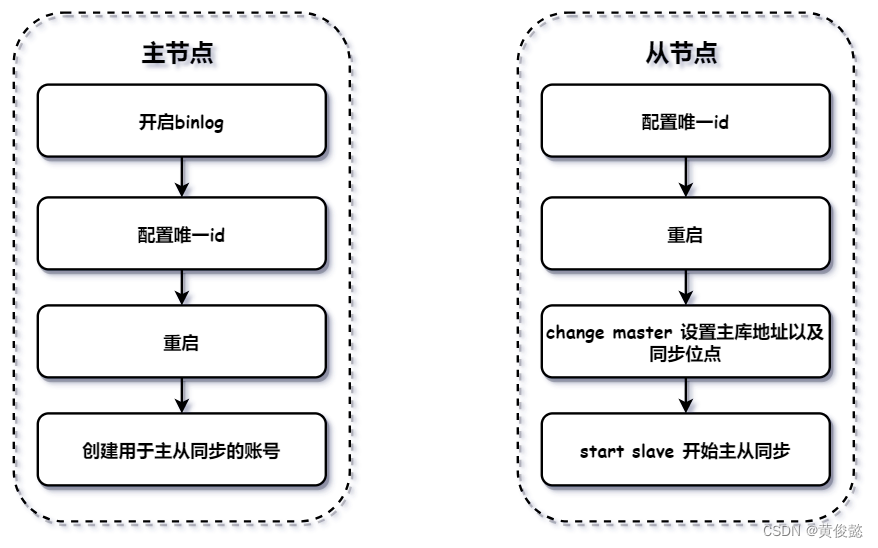
主节点
首先主节点要开启binlog配置,并且设置一个全局唯一的id号。我们要修改MySQL的my.cnf配置文件,添加两行配置:
log-bin=mysql-bin
server-id=200
“log-bin=mysql-bin”表示启用binlog日志,“server-id=200”表示给当前服务器配置一个唯一id“200”。
然后要重启MySQL服务器:
systemctl restart mysqld
最后,还要创建一个用于主从复制的账号,并给该账号授权:
GRANT REPLICATION SLAVE ON *.* to '账号'@'%' identified by '密码';
然后就可以查看主节点上的binlog文件和位点,并记录下来:
show master status;
从节点
从节点也必须配置一个全局唯一的id号,也是在my.cnf中配置:
server-id=201 #[必须]服务器唯一ID
然后要重启MySQL:
systemctl restart mysqld
重启完成后,要登录上MySQL,设置主库地址和binlog的同步位点:
change master to master_host='主库地址',master_user='主从同步账号',master_password='主从同步账号的密码',master_log_file='binlog日志文件',master_log_pos=同步位点;
然后输入“start slave”命令开始主从复制:
start slave;
最后可以通过通过“show slave status”命令返回的结果中显示的Slave_IO_running 和 Slave_SQL_running两个字段的值是否为yes判断主从复制是否就绪。
show slave status
主从复制的多种类型
上面是一主一从的配置,是最简单的一种主从复制。除此之外,我们还可以配置其他类型的主从复制,配置方法都是相同的。主从复制的类型包括:一主一从、一主多从、多主一从、双主复制、级联复制。
一主一从

一主一从是最简单最普通的主从复制类型,基于一主一从的主从复制,就可以配置读写分离,也可以实现高可用,当主机宕机,从机可以顶上去(当然这个要配合上高可用机制)。
一主多从
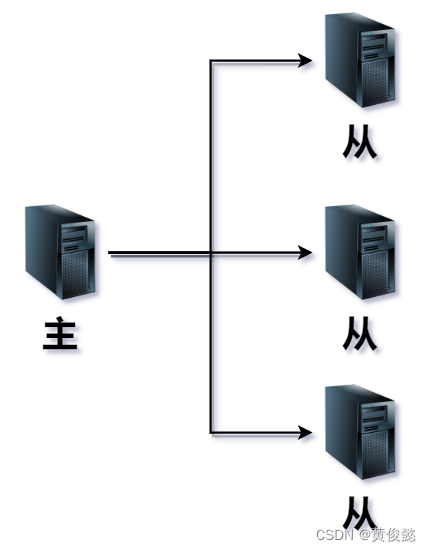
给主节点配置多个从节点,就是一组多从的主从复制,多个从节点可以通过负载均衡分摊读请求的压力,提升集群的读请求并发性能。
多主一从
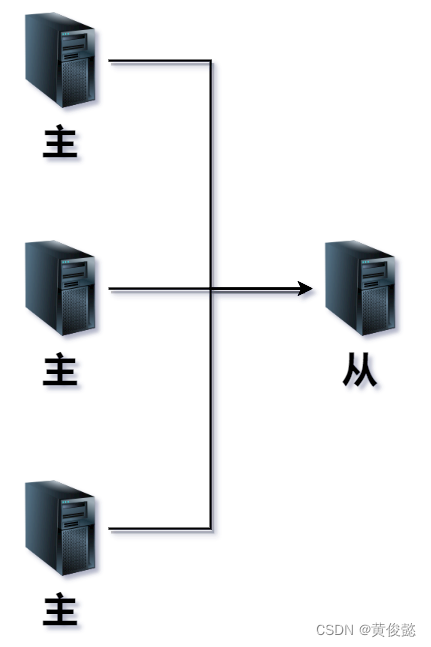
我们也可以配置多个主节点,往一个从节点同步数据,这时候就是多主一从的主从复制。这种类型的主从复制的作用,就是可以利用从节点做一些聚合查询。
比如我们做了分库分表,此时有多个主节点可以接收写请求,但是如果要做一些聚合查询,需要轮询多个主节点,比较麻烦。于是我们可以把多个主节点的数据往一个从节点同步,从节点是一个存储性能非常好的机器,那么我们有一些比较耗时但实时性要求不高的聚合查询,就可以放到从节点来做。
双主复制

双主复制就是两个主节点,都可以接受读写请求,然后互相同步数据,这种类型的主从复制可以提升MySQL集群处理写请求的并发能力。
级联复制
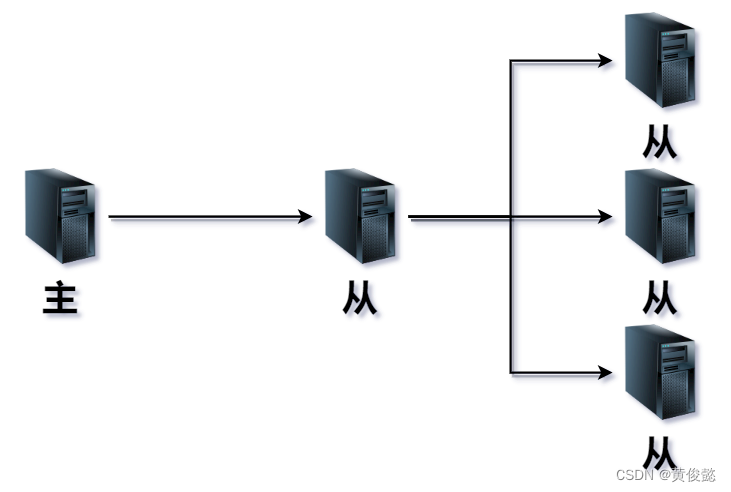
当我们从节点过多时,如果都由主节点给他们同步数据,会造成主节点的主从复制压力过大,这时候我们应该采用级联复制的方式,减轻主节点主从复制的压力,有一部分的从节点是通过其他从节点同步数据的。
主从复制的多种模式
主从复制又有多种模式:异步复制、半同步复制、全同步复制。默认是异步复制。
异步复制
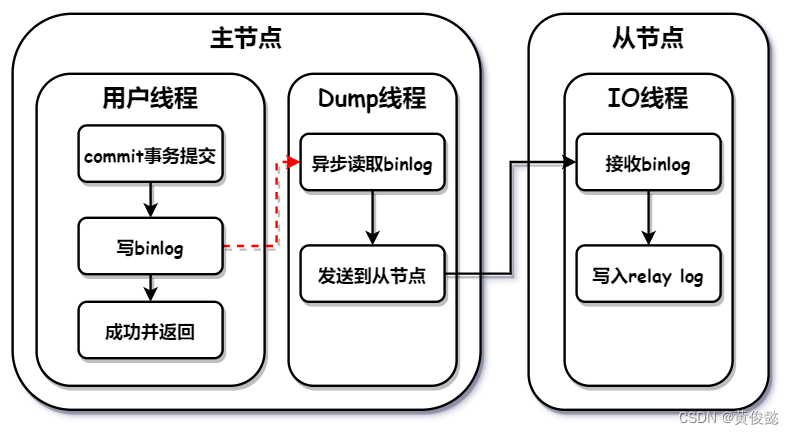
异步复制是指不用等待主从复制完成,用户线程写入binlog成功后,就马上返回。
当主节点的用户线程接收到写请求之后,写入数据成功后,就会写入binlog日志文件,当binlog写入成功后,就返回写请求处理成功。而Dump线程则异步的读取binlog日志文件,发送到从节点,进行主从复制。
这种模式下的主从复制,主节点的压力非常小,对写请求处理的性能影响最小,但是最不安全。
全同步复制
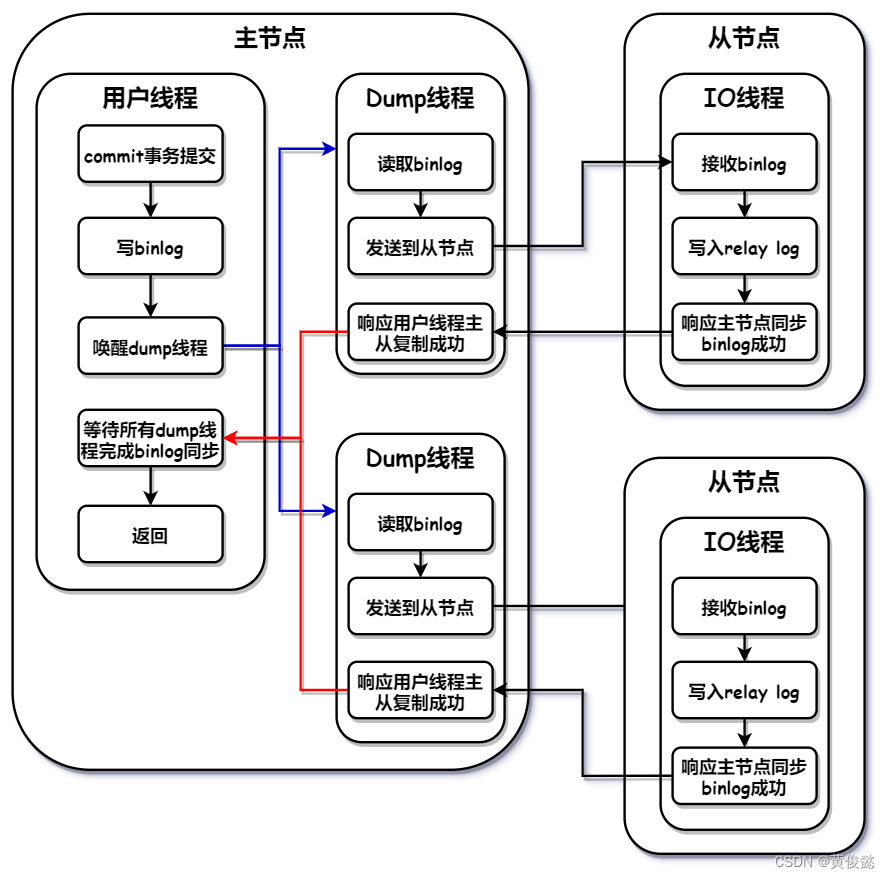
全同步复制模式下,用户线程需要等待所有的Dump线程完成binlog同步,才能返回。
当主节点的用户线程完成写请求的数据写入之后,并且写入binlog成功后,就会唤醒所有的dump线程进行binlog的同步,然后用户线程挂起,等待所有的dump线程同步binlog成功。当dump线程被用户线程唤醒后,就会进行binlog同步,把binlog日志中最新写入的内容同步到从节点,从节点的IO线程写入relay log成功后,响应主节点的dump线程,主节点的dump线程再去通知用户线程。当收到了所有dump线程的通知后,用户线程就会解阻塞,返回客户端写入成功。
这种模式的主从复制性能是较低的,但是是最安全的。
半同步复制
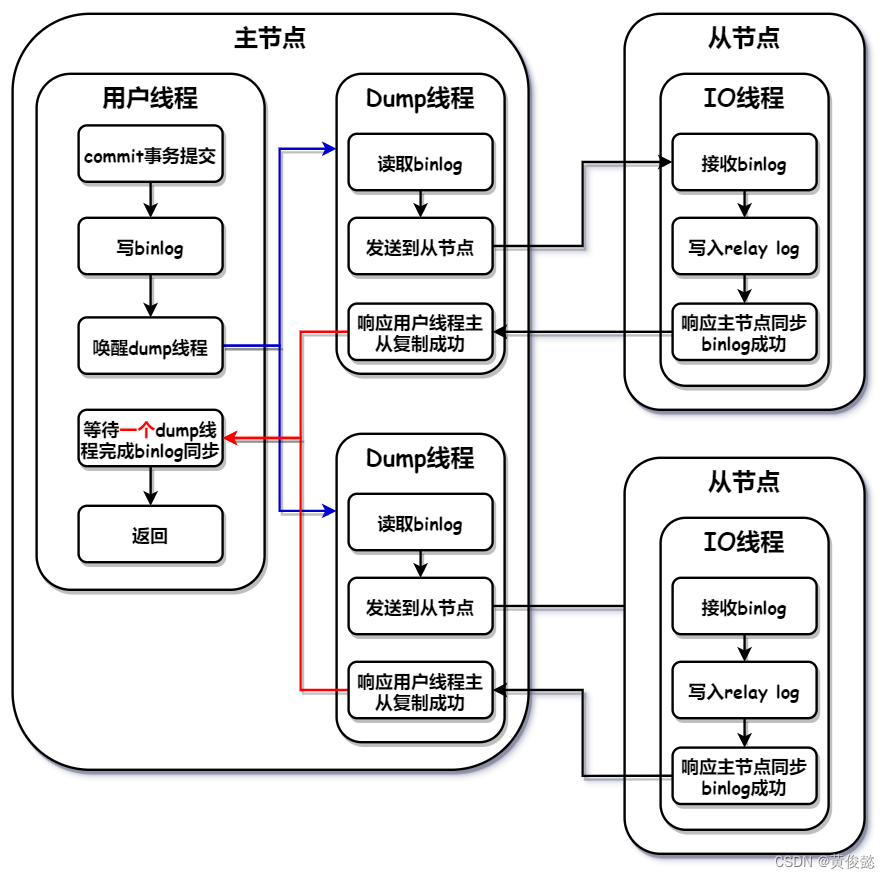
半同步复制与全同步复制的不同点在于,半同步复制的用户线程不需要等待所有的dump线程同步binlog成功,而是只需要等待一个dump线程同步binlog成功,用户线程就可以解阻塞,响应客户端写入成。
这种模式的主从复制的写入性能和安全性介于异步复制和全同步复制之间,是一种折中方案。
主从复制延迟及其解决办法
由于主节点的写请求是可以并发进行的,也就是有多个用户线程同时处理写请求,并写入binlog。而从节点只有一个SQL线程去读取relay log并应用到从节点。因此,主节点的写并发量过大时,从节点就会跟不上主节点的写入速度,造成主从延迟。
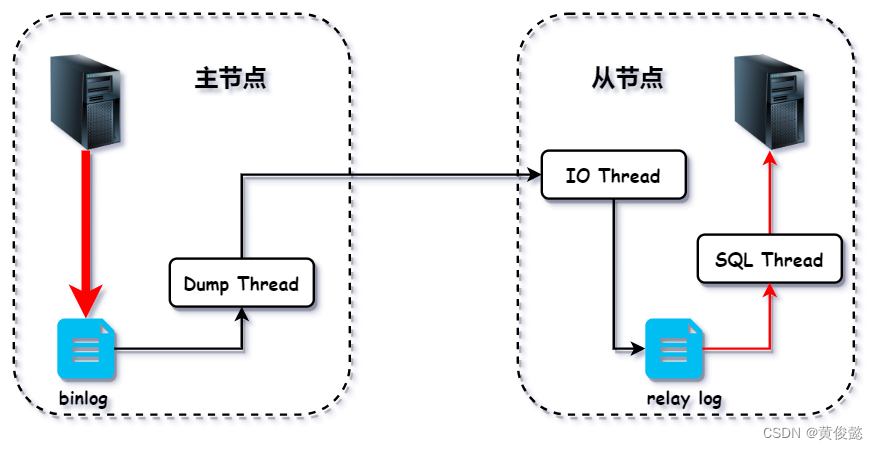
主从复制延迟的根本原因,就是从节点只有一个SQL线程去执行relay log中的SQL。因此,解决办法就是多搞几个SQL线程,并行的读取relay log并执行,这就是并行复制。
原来只有一条SQL线程执行relay log时,是这样子:
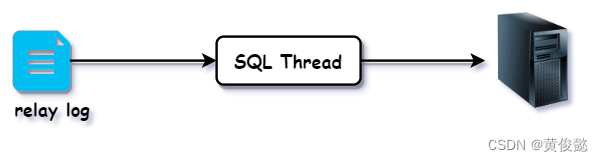
SQL线程读取relay log,然后直接应用到从节点。
而采用并行复制时,就变成下面这样:
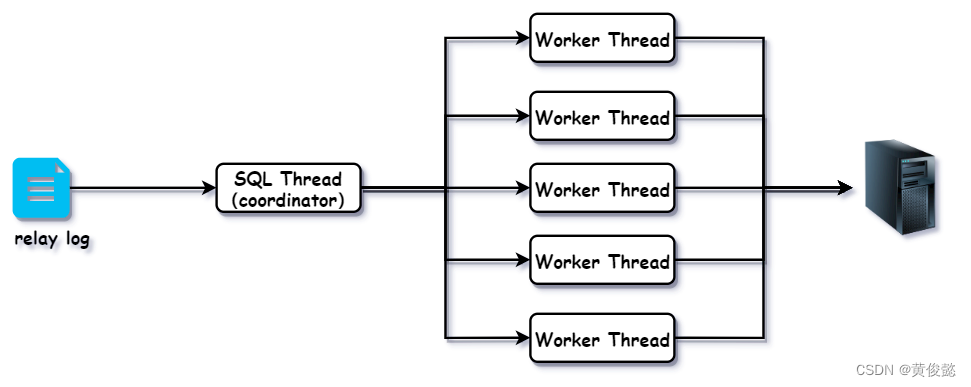
此时SQL线程读取relay log后,不再直接执行,而是分发给其中某一个Worker线程。Worker线程会开启多个,接收SQL线程发来的sql,然后在从节点上执行。
此时的SQL线程相当于一个coordinator协调器,专门进行sql分发,分发方式有多种,比如:按库分发、按表分发、按行分发等。不同的MySQL版本,提供的分发方式不一样,比如老版本的MySQL只支持按库分发,而新版本的MySQL则支持按行分发,使用的是哪种分发方式,这取决于MySQL的版本以及相应的配置,这里就不深入细说了。
读写分离
MySQL读写分离是基于主从复制之上进行配置的。当我们配置好主从复制之后,我们就可以进行读写分离的配置。让写请求发送到主节点,而读请求则发送到从节点,这样从节点就可以分摊主节点的读请求压力。
读写分离的实现方式
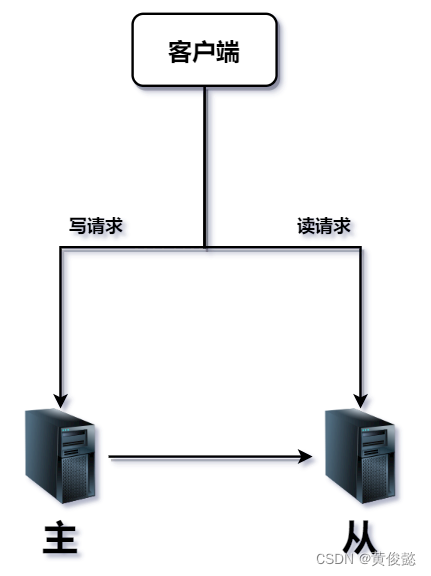
但是我们怎么控制读请求发送到从节点,写请求发送到主节点呢?
我们可以在客户端和MySQL之间加一个中间层。我们的读写请求不再直接发到MySQL,而是发到这个中间层,让这个中间层进行代理转发。这个中间层有两种类型:一种是客户端jar包形式的,比如ShardingJDBC;一种是中间件形式的,比如ShardingProxy、MyCat。
客户端jar包形式的,我们需要引入对应的依赖包,然后进行相关的配置,比如一些读写规则的配置。然后让它根据读写规则代理我们发起读写请求。
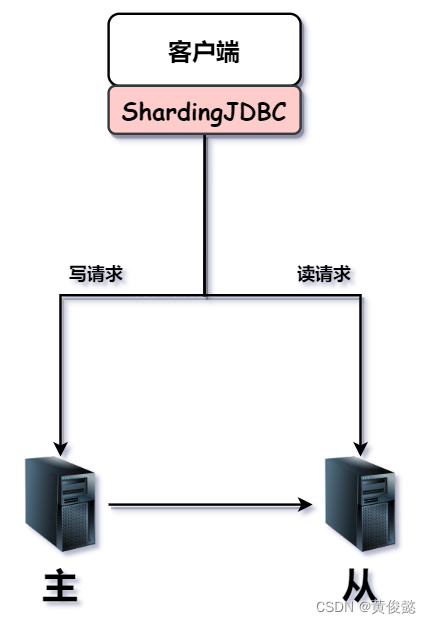
如果是采用中间间形式,则要独立部署一个中间件服务,然后请求发送到该中间件,再由该中间根据配置的读写规则件进行代理转发。
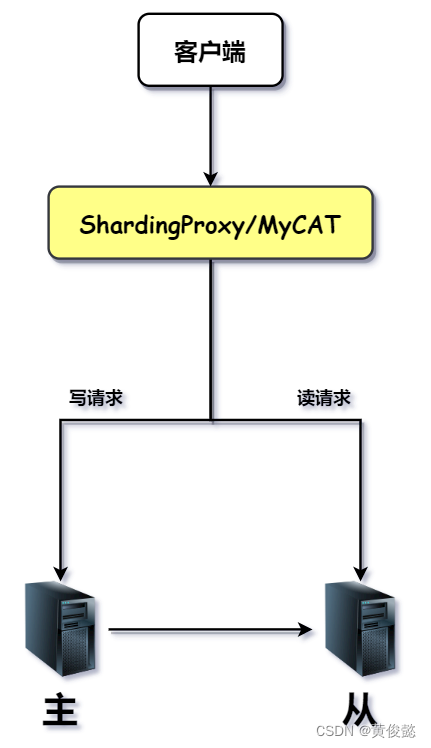
这两种方式的区别就是:客户端依赖方式的读写分离性能较高,但是客户端使用的编程语言将受到限制;而中间件形式读写分离,由于还要经过中间件做一次代理转发,因此性能会降低,但是客户端使用的编程语言不受限制,适用于任何编程语言。
读写分离如何保证写入马上可被读取到
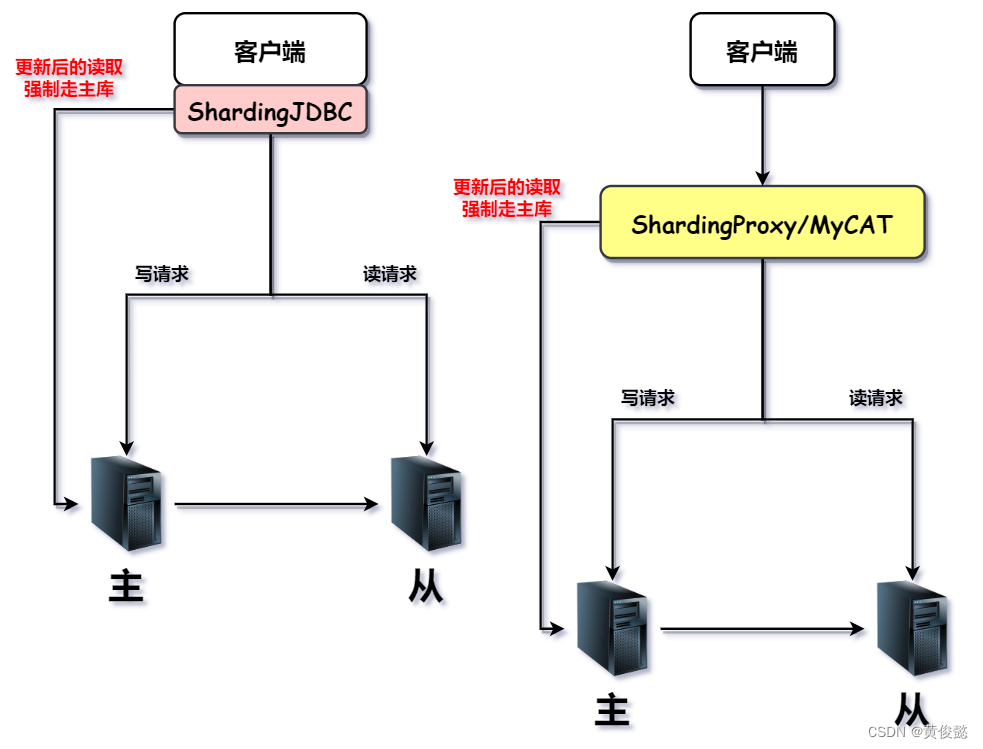
这里有一个问题,因为主从复制是存在一定的延迟的,当我们配置了读写分离之后,写入主节点的数据,可能无法在从节点上被马上读取到。比如我们对主节点发起一次更新请求,然后在该更新同步到从节点前,我们向从节点发送一次读请求,希望更新结果被马上读取到,这时候显然是失败的,读取到的是旧的数据。
解决这种问题的方法,可以使用强制读请求走主库。当我们希望更新后的结果马上被读取到,我们可以配置更新后的读操作强制走主节点。
高可用
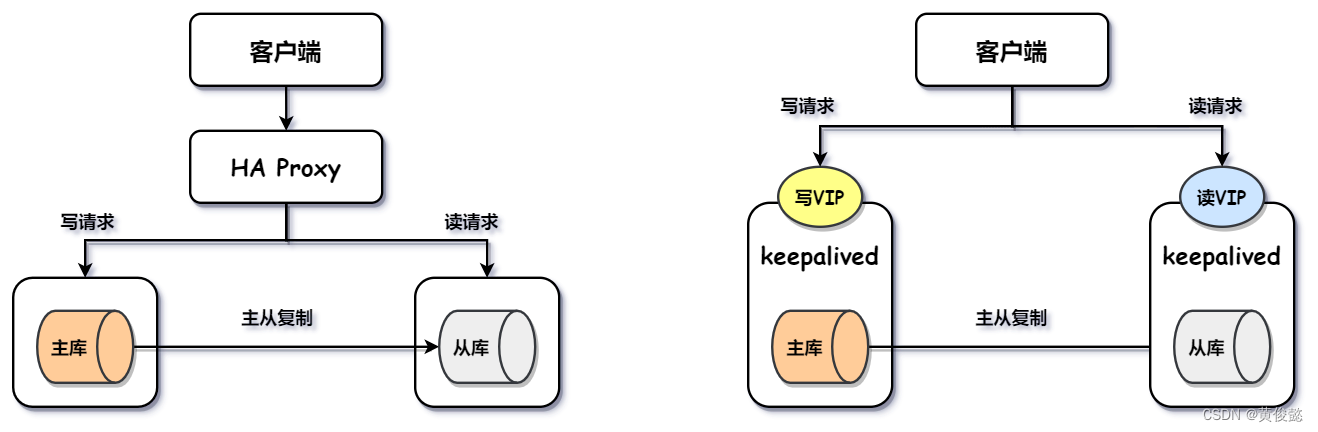
当我们配置了主从复制之后,并不意味着我们的MySQL集群就是高可用的,因为当主节点宕机后,从节点并不会自动切换为主节点,需要人工进行切换,这样显然是很不方便的,没有高可用而言。因此,我们还要在主从复制的基础上,进行一些高可用配置,达到MySQL集群的高可用。
在数据库节点较少的情况下,我们可以自己配置实现数据库的高可用,比如通过HA Proxy、keepalived等工具实现MySQL的高可用。
但是当节点一旦多起来,这种方式的配置就会非常麻烦,不利于维护。于是我们需要通过数据库管理软件来实现MySQL的高可用,主要方案有三种:MMM、MHA、MGR。
MMM
MMM(Master-Master replication managerfor Mysql,Mysql主主复制管理器)是一套由Perl语言实现的脚本程序。
MMM架构的方案,主要包括两个主节点和若干从节点,两个主节点中有一个是对外处理写请求的,另一个是热备,而从节点则从处理写请求的主节点同步数据。每个数据库节点都配置一个虚拟IP,其中对外处理写请求的节点的虚拟IP是写IP,客户端往这个IP发送写请求,而另一个主节点和其他从节点,则分配的是读IP,客户端会往这些IP发送读请求。
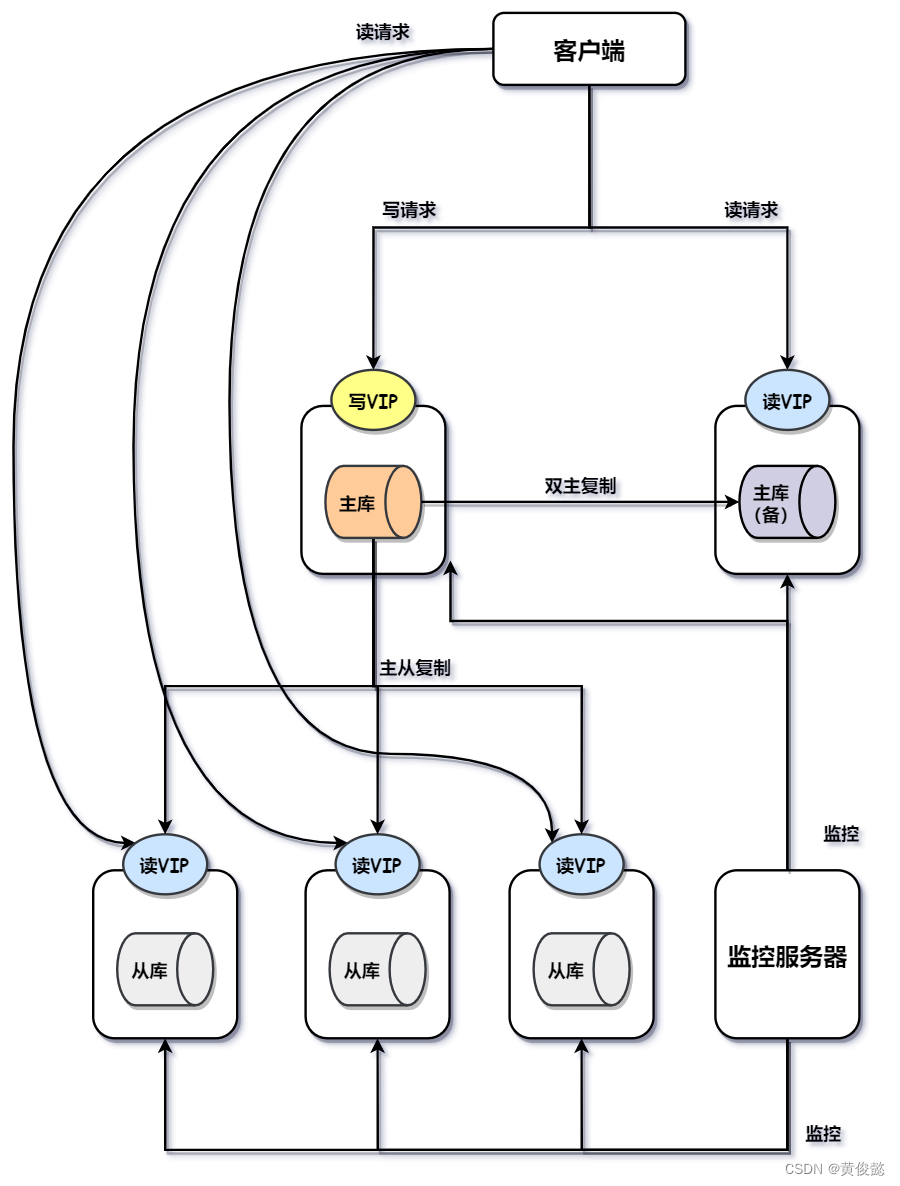
最后还有一个监控服务器,监控这些节点的健康状况,一旦对外提供写请求的节点不可用,马上触发切换,把写IP切换到另一个主节点,然后从节点向新的主节点进行复制。这个IP切换的动作,也叫做“IP漂移”。
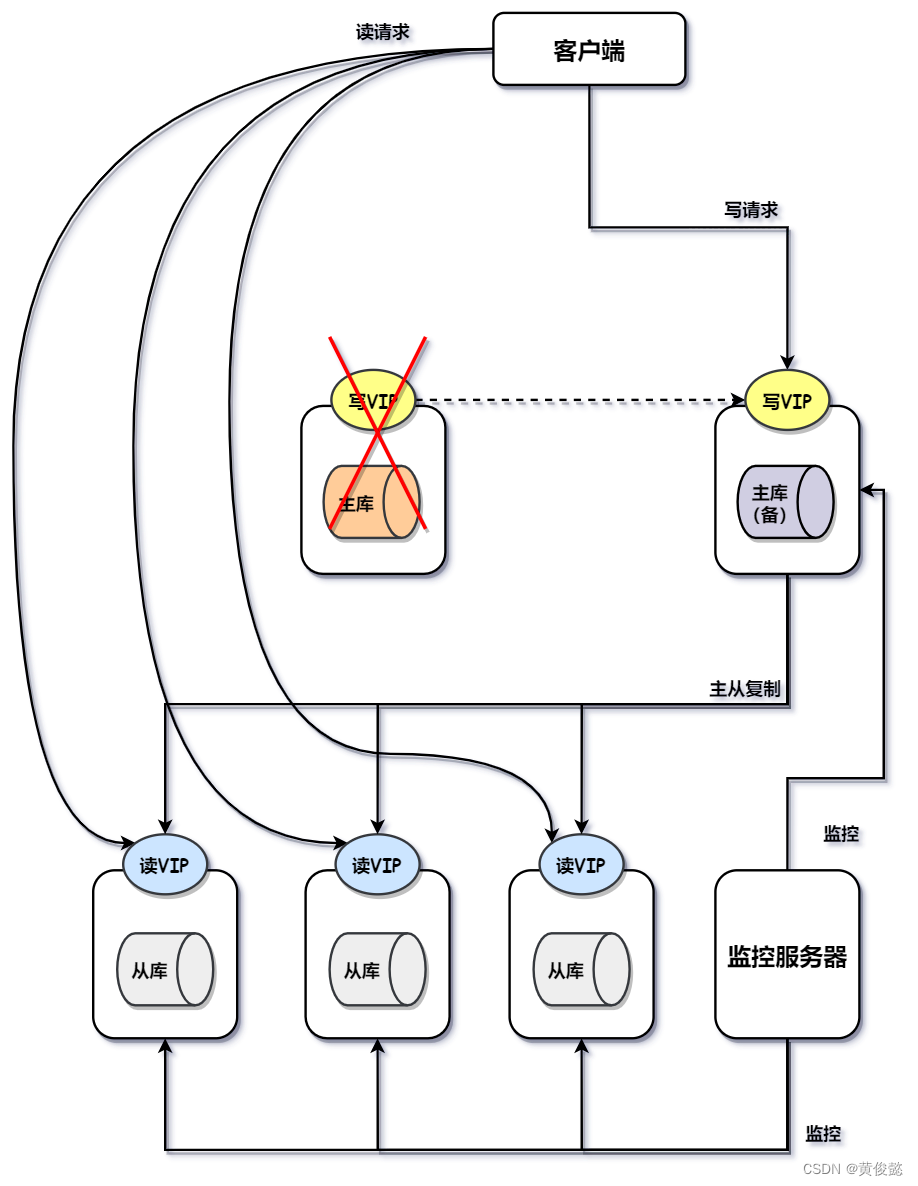
目前MMM社区已经缺少维护,并且不支持基于GTID的复制,因此也很少使用了。
MHA
MHA(Master High Availability Manager and Tools for MySQL),是由日本人开发的一个基于Perl脚本写的工具。
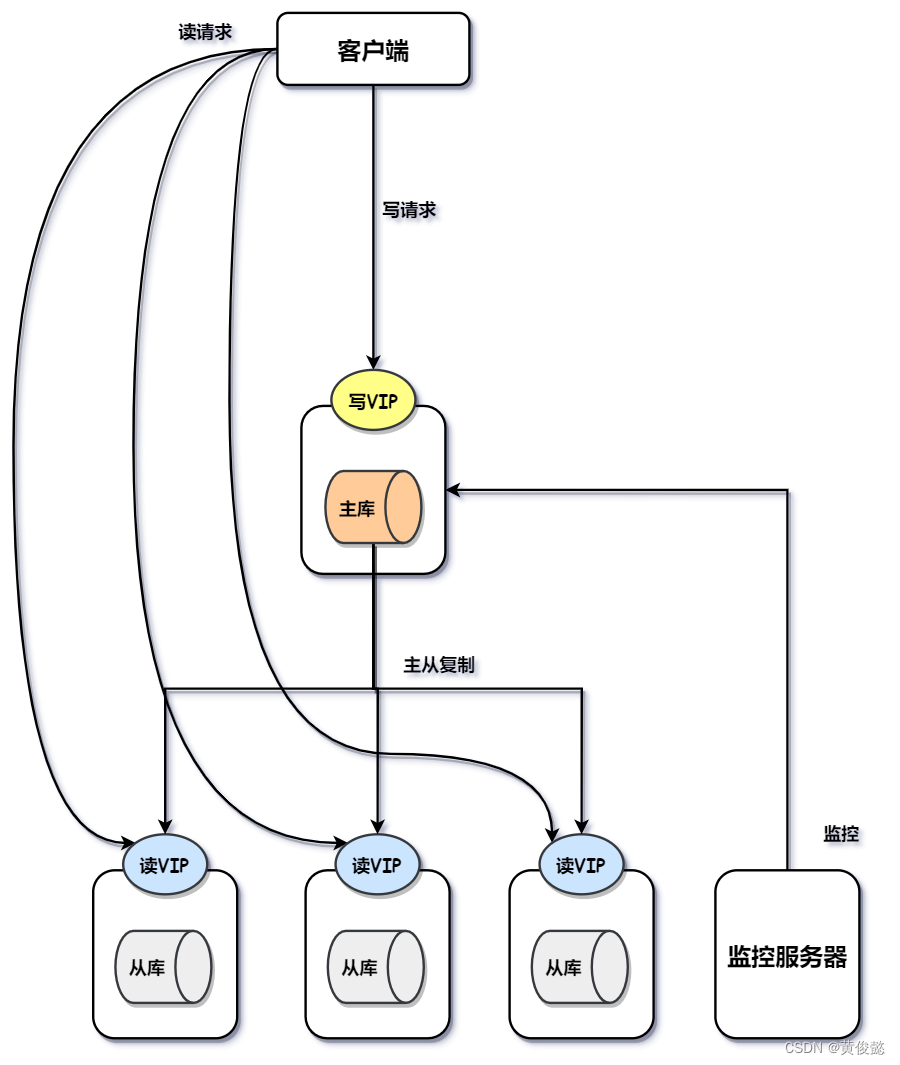
MHA则是一主多从的结构,当主节点出现故障是,会有一个从节点顶上去。
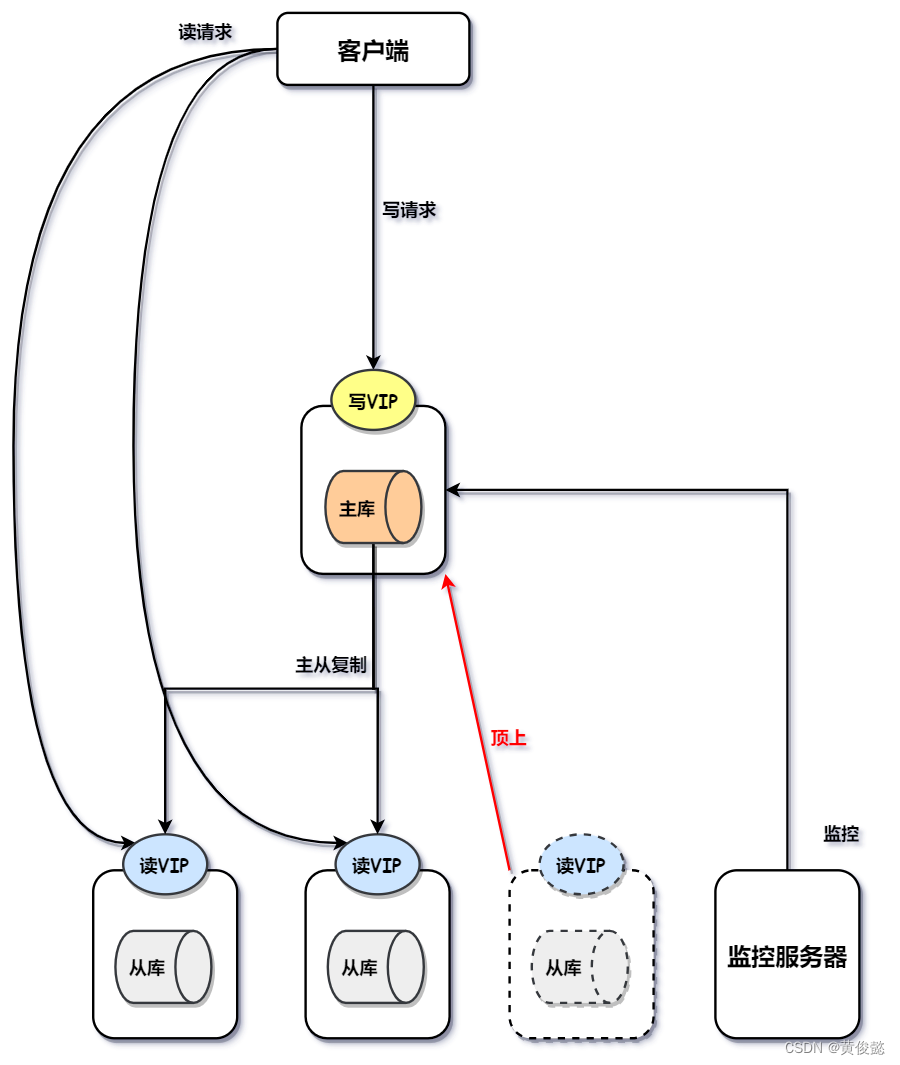
这里从图中可以看出,MHA架构是不对从节点进行监控的。并且MHA虚拟IP漂移脚本是需要自己编写的,这是MHA架构的一大缺陷。
MGR
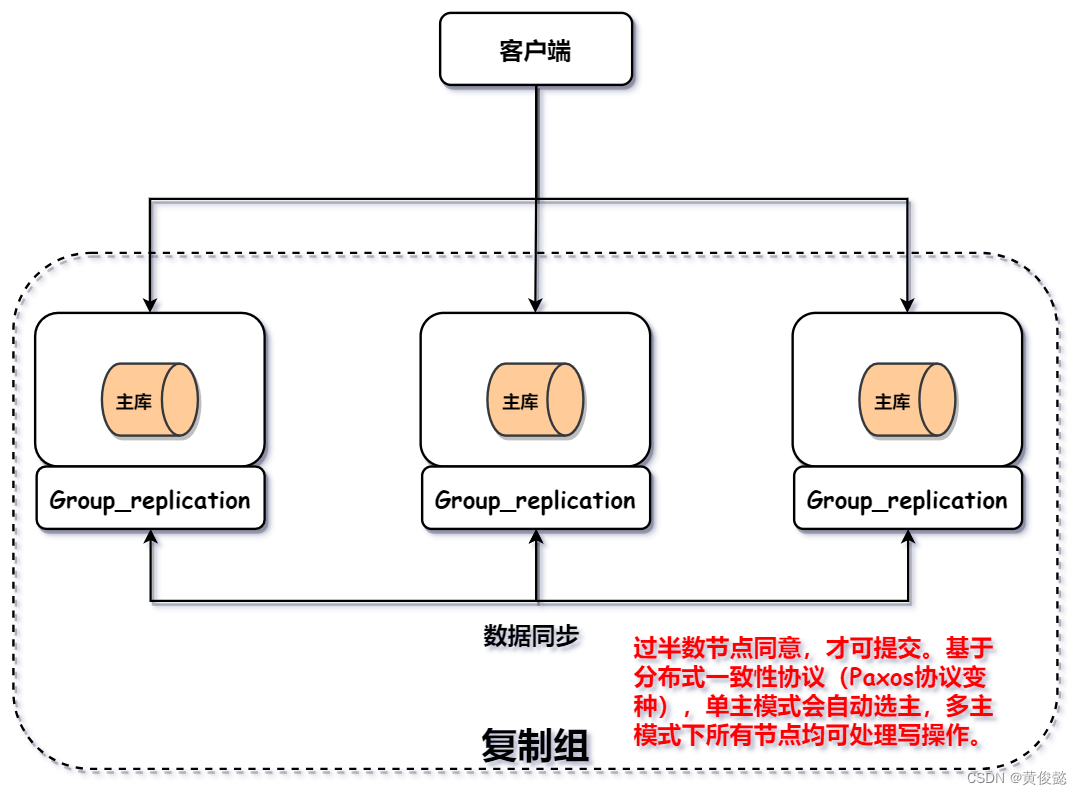
MGR(MySQL Group Replication,MySQL组复制),是MySQL官方在5.7.17版本正式推出的一种组复制机制。
MGR方案是基于分布式一致性协议的,该协议是Paxos协议的一个变种,一个写请求,需要大部分节点同意,才可以提交。并且我们可以配置一主多从或多主两种模式,如果是一主一从,集群会自动选主,多主模式下,任何一个节点都可以处理写请求。
分库分表
说到分库分表,一般的共识是能不分就尽量不分,因为拆分会涉及到很多问题,比如分布式id、分布式事务、多库join查询等问题都需要考虑。但是一个MySQL数据库,只适合存储大约两千万以下的数据量,不适宜存储太多的数据,因为数据量的增大,意味着索引越来越庞大,查询性能就会越来越低。当超过两千万的数据量时,就需要考虑对MySQL进行分库分表了。
分库分表有几种方式,分别是:垂直分库、垂直分表、水平分库、水平分表。具体要进行哪种方式的拆分,要根据实际情况考虑。
垂直分库
垂直分库是从业务的角度出发以库的维度进行拆分,比如我们有一个商城应用,原来所有的库表都在一个数据库服务器节点上:
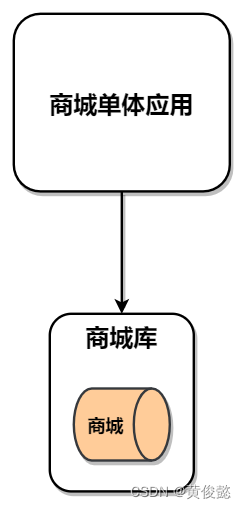
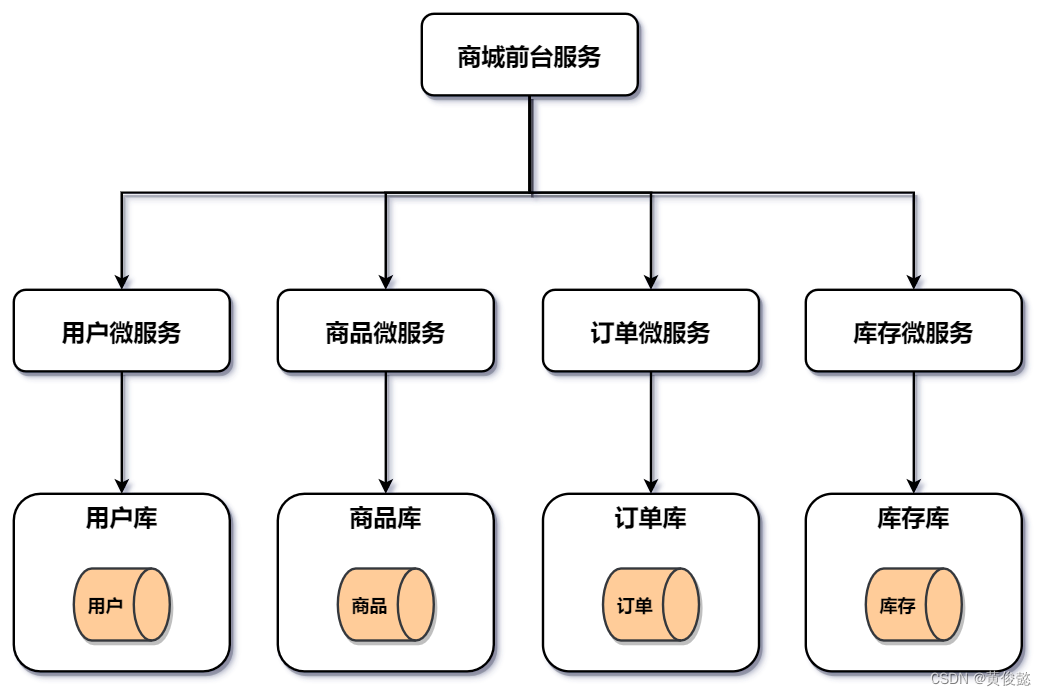
现在我们要以业务维度,对其进行库的拆分,用户库、商品库、订单库、库存库分别作为一个数据库。这种拆分方式,往往伴随着应用的拆分,把原先的一个单体应用,拆分成多个微服务,比如:用户微服务、商品微服务、订单微服务、库存微服务。
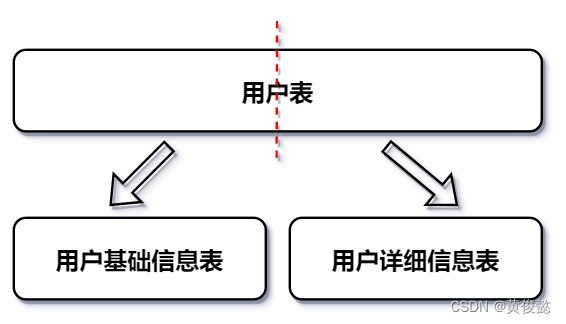
垂直分表
对表进行的垂直拆分,一般是由于某张表的字段过多,而大部分字段在大多数的查询中用不到,此时我们可以把这张表拆成两张表,一张是基本信息表,一张是详细信息表。基本信息表只包含大多数查询需要返回的字段,而其余的字段则放到详细信息表中。
水平分库 & 水平分表
水平分库,往往是伴随着水平分表的。我们把原先的一个数据量很大的表,拆分成几个数据量相对较小的表,并且放到不同的数据库节点中。这种方式的拆分就是水平分库、水平分表,这里面即涉及了库的拆分,又涉及了表的拆分。
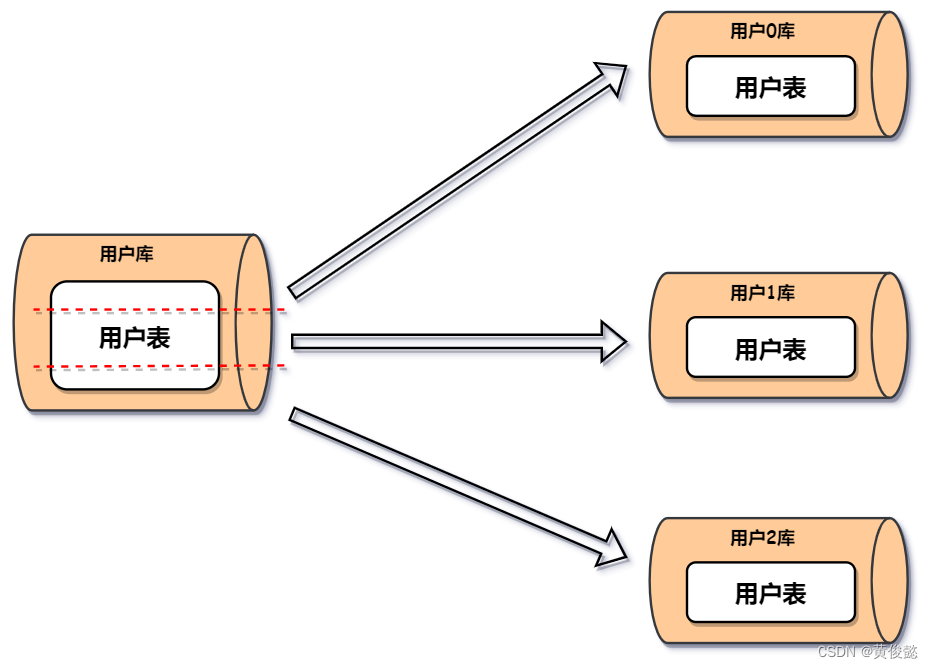
此时客户端发送的请求,要根据一定的规则路由到对应的节点,比如我们可以通过用户ID(user_id)进行取模,路由到对应的节点。
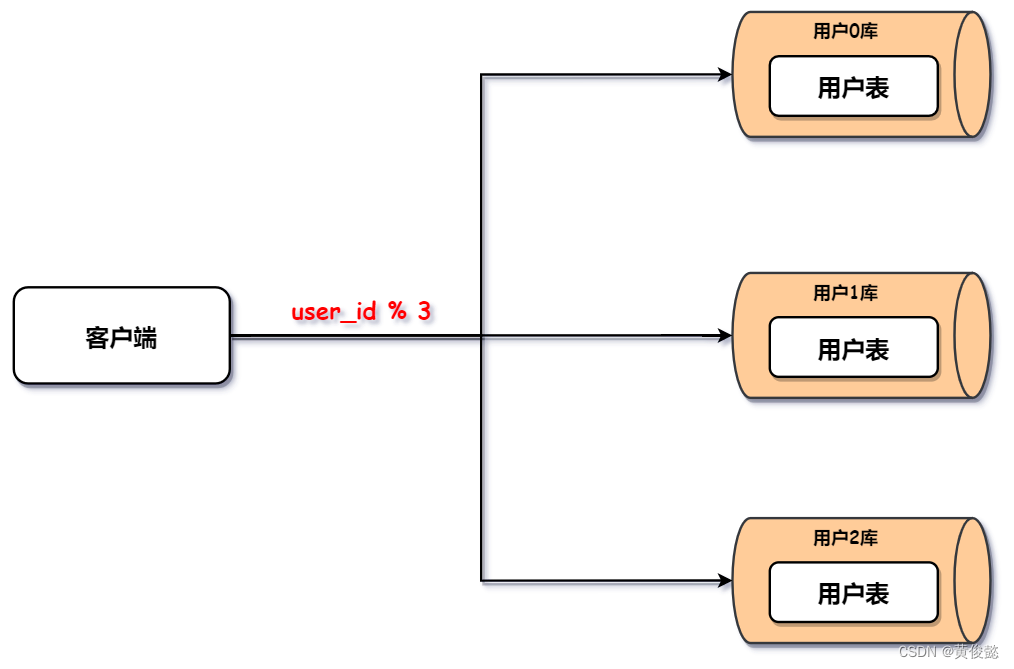
当然,如果是直接在SQL里面写死这种路由规则,那也太麻烦了,而且灵活性不高,还很容易出错。因此我们还是通过像ShardingSphere、MyCat等分库分表中间件来实现分库分表下的数据库查询和修改操作。
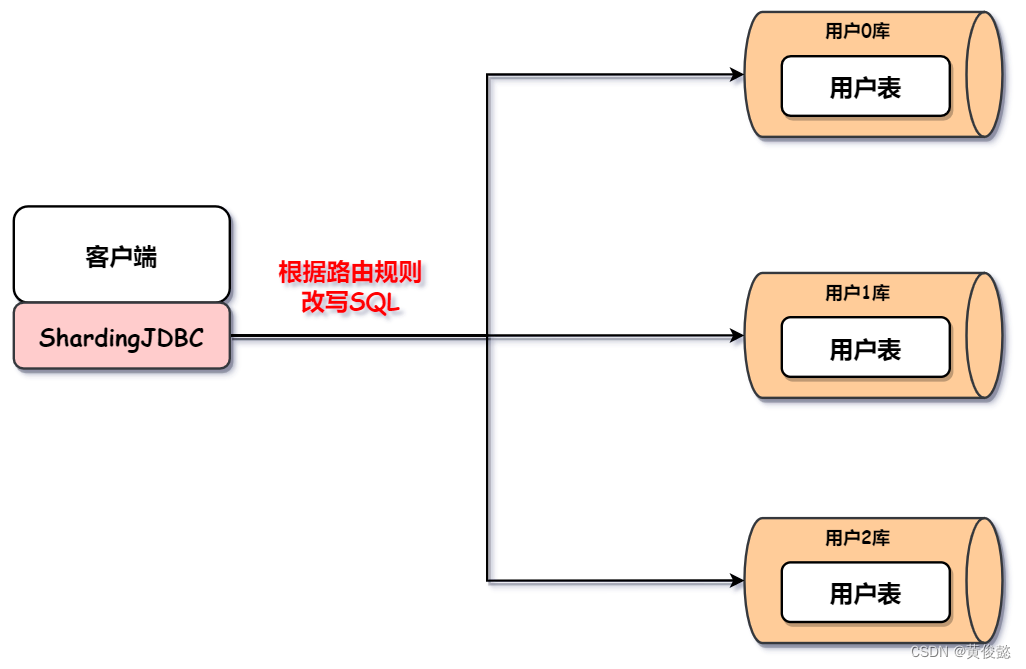
比如客户端直连的方式,我们可以引入ShardingJDBC依赖包,然后配置好相应的路由规则,那么ShardingJDBC就会根据路由规则改写SQL,把对应的SQL发送到相应的数据库节点上。
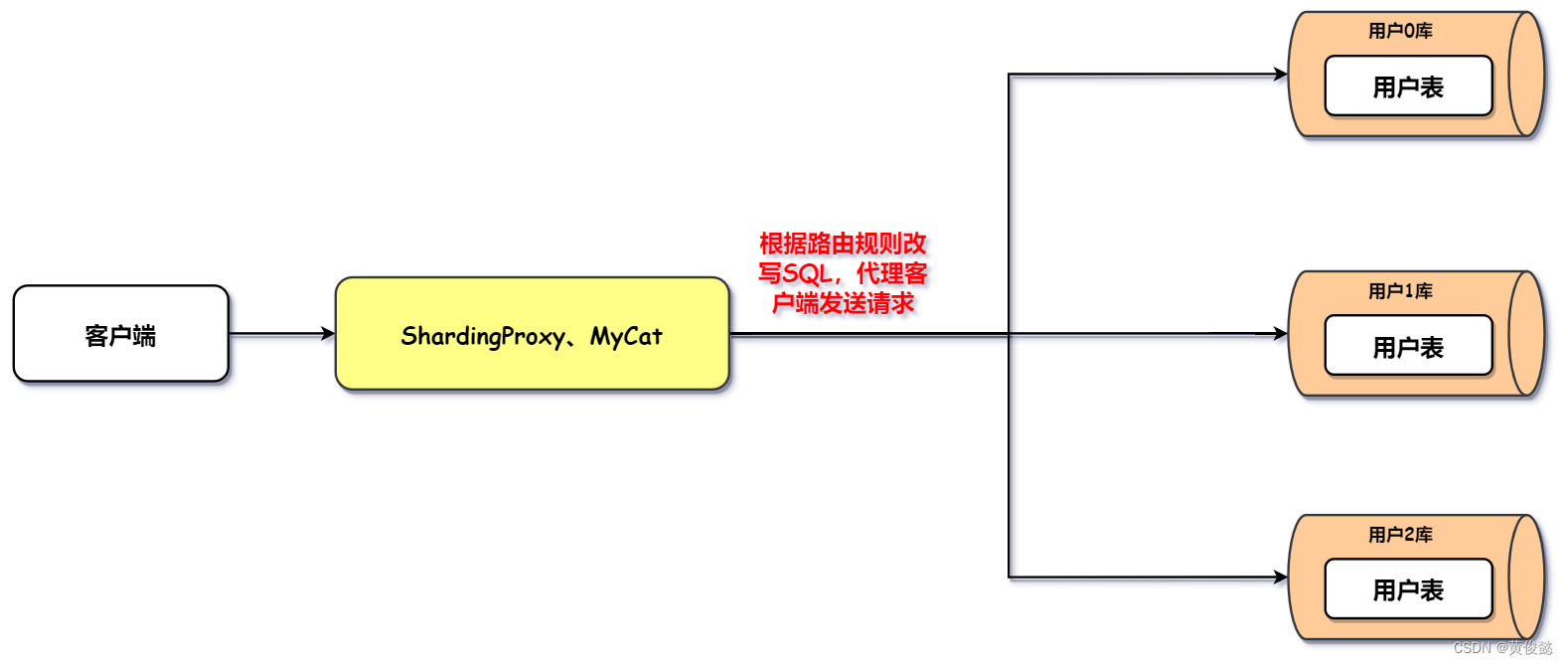
如果是ShardingProxy或者MyCat这种中间件方式的话,那么就还要部署一个数据库中间件服务,我们的请求发往这个数据库中间件,再由这个中间件根据一定的路由规则改写SQL,代理我们的客户端请求对应的数据库节点。




![Sqli-labs靶场第12关详解[Sqli-labs-less-12]](https://img-blog.csdnimg.cn/direct/86fa43f3b9b445c0a674971550db29c1.png)