引言:大语言模型的长上下文理解能力
在当今的人工智能领域,大语言模型(Large Language Models,简称LLMs)的长上下文理解能力成为了一个重要的研究方向。这种能力对于模型来说至关重要,因为它使得LLMs能够有效地应对各种应用场景,例如在庞大的PDF文件中分析和回应查询、保留扩展的对话历史以及增强交互式聊天机器人的功能。然而,由于训练语料库的可获取性有限,以及长上下文微调的成本过高,目前的开源模型在性能上往往无法与专有模型相媲美,且通常只能提供较小的模型尺寸(例如7B/13B)。
针对这些限制,不需要额外训练即可进行上下文扩展的方法变得尤为吸引人。最近的无训练方法,包括LM-infinite和StreamingLLM,已经展示了在有限上下文窗口训练的LLMs能够高效处理无限长度的文本。这些模型通过选择性保留关键的局部信息来处理扩展序列,有效地维持了低困惑度(Perplexity,PPL),但它们失去了长距离依赖性。为了保留全局信息,另一种观点是有效地推断出超出训练时遇到的序列长度。一些流行的技术,如基于Llama模型的位置插值(PI)和NTK-Aware RoPE,是对旋转位置编码(RoPE)的调整。这些扩展的位置编码相比原始RoPE需要更少的微调步骤,而且它们的训练成本可以通过YaRN和CLEX等方法进一步降低。
论文标题: Training-Free Long-Context Scaling of Large Language Models
论文链接: https://arxiv.org/pdf/2402.17463.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。
长上下文处理的挑战与现有方法局限性
在大语言模型(LLMs)的发展中,理解和处理长上下文信息是一个关键挑战。这种能力对于有效地应对各种应用场景至关重要,包括在庞大的PDF文件中分析和回应查询、保留扩展的对话历史以及增强交互式聊天机器人的功能。然而,尽管通过在长文本序列上进一步训练短上下文模型可以提高长上下文能力,目前的开源模型在性能上往往不及专有模型,并且通常只提供较小的尺寸(例如7B/13B)。
现有的方法,如LM-infinite和StreamingLLM,展示了在有限上下文窗口训练的LLMs能够高效处理无限长度的文本。这些模型通过选择性保留关键的局部信息来处理扩展序列,有效地保持了低困惑度(PPL),但却丢失了长距离依赖。为了保留全局信息,另一种观点是有效地推断超出训练期间遇到的序列长度。流行的技术,如基于Llama模型的Position Interpolation(PI)和NTK-Aware RoPE(NTK),是对Rotary Positional Encodings(RoPE)的调整。这些扩展的位置编码相比原始RoPE需要更少的微调步骤,其训练成本可以通过YaRN和CLEX等方法进一步降低。然而,在无需训练的环境中,这些方法通常会导致PPL显著增加,尤其是在输入长度是训练长度两倍以上时。
双块注意力(DCA)框架
1. DCA的三个组件:内块、间块和连续块注意力
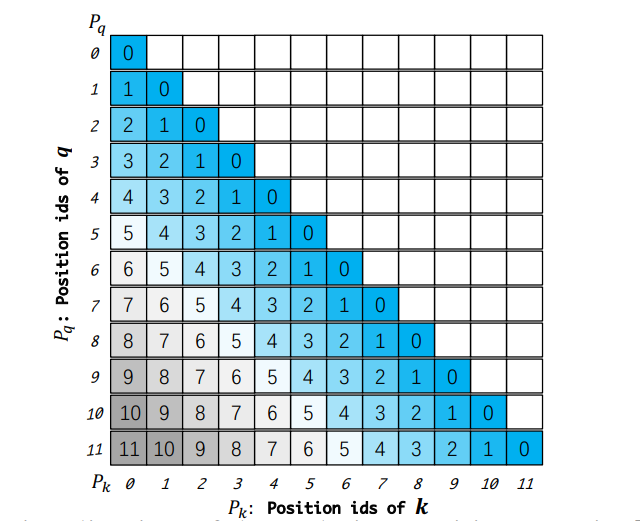
双块注意力(DCA)是一个新的无需训练的框架,用于推断LLMs的上下文窗口。DCA避免了线性缩放位置索引或增加RoPE的基频。相反,它选择重用预训练模型中的原始位置索引及其嵌入,但重新设计了相对位置矩阵的构建,以尽可能准确地反映两个标记之间的相对位置。DCA由三个组件组成:(1)内块注意力,针对同一块内的标记处理;(2)间块注意力,用于处理不同块之间的标记;(3)连续块注意力,用于处理连续的、不同的块中的标记。这些各自的处理帮助模型有效捕捉序列中的长距离和短距离依赖。
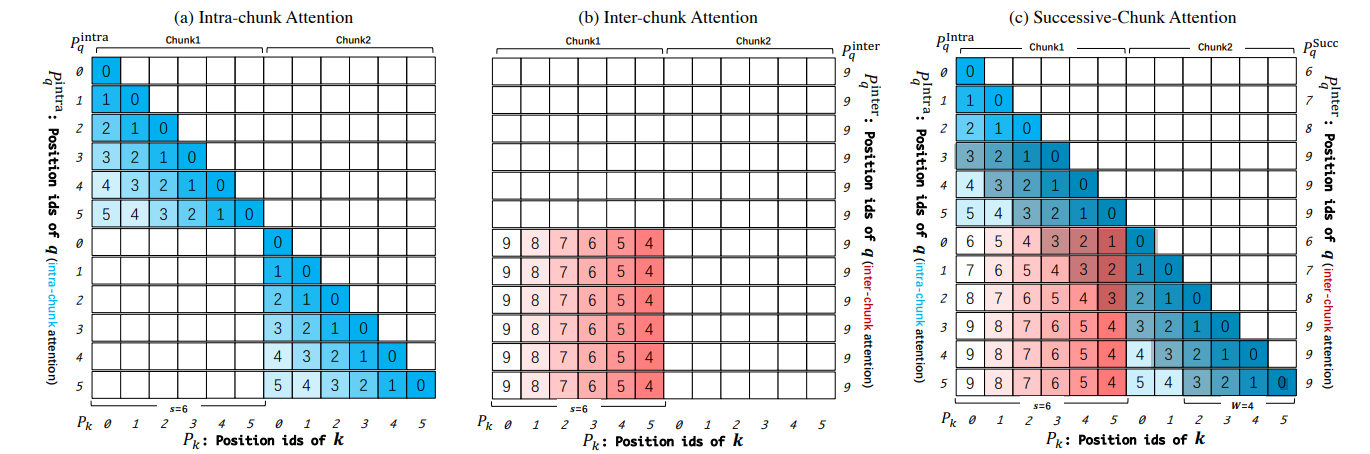
2. DCA与Flash Attention的集成
DCA的块基础注意力计算可以与Flash Attention无缝集成,Flash Attention是开源社区中长上下文扩展的关键元素。该研究在模型上进行了全面评估,包括语言建模、密钥检索和涵盖问答(Q&A)和摘要等实际长上下文应用的多样化任务。与以往的工作不同,通常仅限于在7B/13B模型上进行验证,该方法的显著训练效率使得可以在70B模型上进行验证,确保了结论的稳健性。为了验证模型的长上下文能力,不受预训练期间可能的数据暴露的影响,使用本文本身作为输入,并为模型设计了一系列问题。实证结果揭示了以下见解:在语言建模上,DCA对于无需训练的方法来说是一个显著的进步。它首次展示了具有4k上下文窗口的LLMs可以扩展到超过32k而无需训练,并保持PPL的微小增加,而以前的方法通常在超过8k的上下文长度上就会失败。此外,该研究展示了当与DCA集成时,Llama2 70B展现出处理超过100k标记上下文大小的卓越推断能力。
实验设置:评估DCA在不同任务上的表现
1. 实验目的与设计
本研究旨在评估Dual Chunk Attention(DCA)在不同任务上的表现,特别是在长序列语言建模中的效果。DCA是一种无需额外训练即可扩展大型语言模型(LLMs)上下文窗口的新框架。实验设计包括在多种任务上进行全面评估,如语言建模、密钥检索和现实世界的长上下文应用,包括问答和摘要。
2. 实验设置
实验中,DCA应用于不同版本的Llama2模型(7B、13B和70B),以及它们的聊天对应模型,这些模型的预训练上下文为4k。此外,DCA还被应用于两个流行的开源长上下文模型:Together-32k和CodeLlama。为了验证模型的长上下文能力,研究团队使用本文作为输入,并为模型设计了一系列问题。
3. 实验资源
实验在NVIDIA A100-80G GPU上进行,7B/13B版本的CHUNKLLAMA2只需要一块GPU即可进行推理。当扩展到70B模型时,两块GPU足以处理长达16k的上下文长度。此外,实验还涉及到了基于Flash Attention 2的优化,以实现与原始自注意力在GPU内存使用和推理速度上的可比性。
实验结果分析:DCA在长序列语言建模中的效果
1. 语言建模
在PG19数据集上的评估显示,DCA在语言建模任务上取得了显著进步。例如,Llama2 70B模型在整合DCA后,能够处理超过100k个令牌的上下文大小,同时仅有微小的困惑度(PPL)增加。此外,已经支持32k上下文窗口的现有长上下文LLMs,通过DCA进一步扩展到192k上下文长度时,仍然保持了高密钥检索准确率和低困惑度。
2. 实际任务
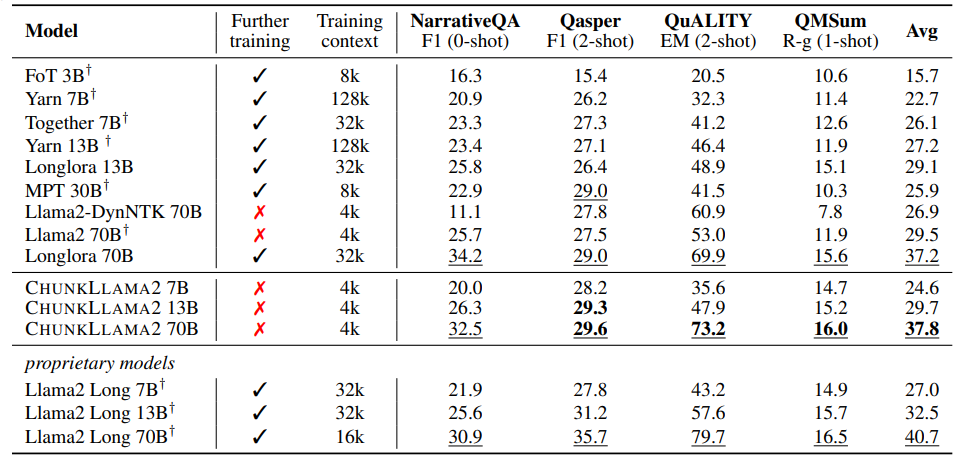
在现实世界基准测试中,DCA不仅在基于PPL的评估中表现出色,还在基础模型和经过指令微调的聊天模型上应用于真实任务。例如,DCA在没有额外训练的情况下,与流行的微调基线模型如YaRN、MPT和Together相比,7B/13B版本的CHUNKLLAMA2在NarrativeQA、QMSum、QuALITY和Qasper等任务上取得了可比或更好的结果。
3. 效率分析
DCA与Flash Attention结合使用时,在不同提示长度下的推理时间和GPU内存消耗与原始自注意力机制相当,没有引入显著的额外开销。这表明DCA能够在保持模型性能的同时,有效地扩展LLMs的上下文窗口。
4. 结论
实验结果表明,DCA是一种有效的训练方法,能够显著扩展LLMs的上下文窗口,同时保持或提升模型在长序列语言建模任务上的性能。通过巧妙利用模型现有的位置索引和引入多方面的注意力机制,DCA为长上下文场景中的LLM应用提供了一种成本效益高的解决方案。
DCA在实际任务中的应用
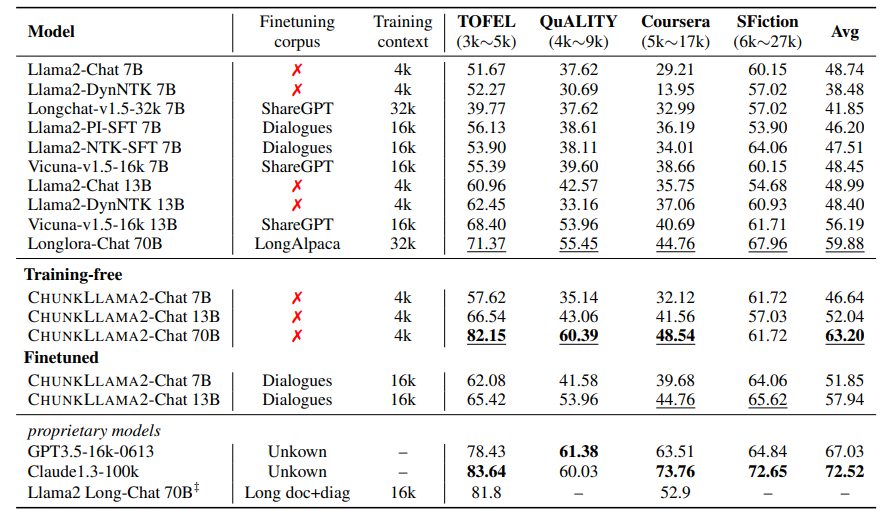
1. 7B/13B模型的训练自由与微调模型
在实际任务中,Dual Chunk Attention(DCA)框架被应用于7B和13B的Llama2模型,以及它们的聊天模型变体。这些模型在预训练时具有4k的上下文窗口。通过DCA的应用,这些模型能够在不需要额外训练的情况下处理更长的上下文。此外,研究者还对7B/13B的Llama2模型进行了微调,使用了长对话数据集,其中包含16k个输入令牌,这些数据集来源于ShareGPT和AlpacaGPT4。微调过程遵循了Vicuna和LongChat的方法,仅使用了大约40至60个GPU小时。
2. 70B模型的性能提升
对于70B的Llama2模型,DCA展示了显著的性能提升。与原始的4k训练长度相比,DCA使得70B模型能够处理超过100k令牌的上下文大小,同时仅略微增加了困惑度(Perplexity,PPL)。这一性能提升证明了DCA在扩展上下文窗口方面的有效性。研究者没有找到许多开源的70B模型作为基线进行比较,但是与支持32k上下文窗口的Longlora模型相比,70B的DCA模型在不需要任何训练步骤的情况下,实现了可比的性能。
DCA在零样本和少样本设置中的表现
在零样本和少样本的设置中,DCA框架的表现与通过昂贵的持续训练构建的现有最先进模型相当,甚至超过了它们。在零样本的实验中,DCA应用于基础模型和经过指令微调的聊天模型,展示了与开源模型相当的性能。特别是在零样本实验中,70B的DCA模型在与Longlora 70B聊天版本相比时显示出显著的改进,并且与GPT-3.5以及Llama2 Long的聊天版本相比,70B的DCA模型在没有额外训练的情况下直接扩展到16k上下文窗口,达到了94%的性能。
在少样本的实验中,DCA在没有进行指令调整的模型上进行了验证。实验结果表明,大多数NarrativeQA和QMSum的测试案例输入长度超过16k令牌,而Qasper和QuALITY的测试案例长度通常在8k令牌以下。在这些设置中,7B/13B的DCA模型实现了与YaRN、MPT、Together等流行的微调基线相当的结果。
效率分析:DCA的推理时间和GPU内存消耗
在评估大语言模型(LLMs)的长上下文理解能力时,推理时间和GPU内存消耗是两个关键的性能指标。Dual Chunk Attention(DCA)作为一种新的训练无关框架,旨在扩展LLMs的上下文窗口,同时保持高效的计算性能。以下是DCA在这些方面的表现分析。
1. 推理时间
根据实验结果,DCA与Flash Attention集成后,在不同的输入长度上的推理时间与原始的自注意力机制(PyTorch实现)和Flash Attention相比较。实验在单个NVIDIA A100 80G GPU上进行,使用Llama2 7B模型,输入长文本来自NarrativeQA。在20次试验中,DCA保持了与原始Flash Attention相似的推理速度,没有引入显著的额外开销。
2. GPU内存消耗
同样地,DCA集成Flash Attention后的GPU内存消耗与原始自注意力机制和Flash Attention进行了比较。在没有Flash Attention的情况下,单个GPU能够处理的最大输入长度大约在12k到16k tokens之间。DCA在GPU内存消耗方面与原始Flash Attention相当,没有显著增加。
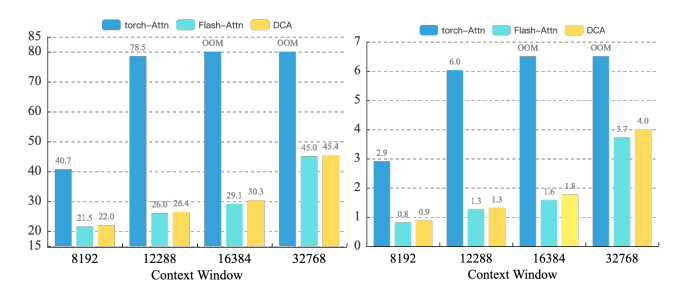
综上所述,DCA不仅能够有效扩展LLMs的上下文窗口,而且在推理时间和GPU内存消耗方面保持了高效性能,这对于开源社区中长上下文扩展的关键元素Flash Attention来说尤为重要。
总结:DCA的创新点和对长上下文LLM的影响
Dual Chunk Attention(DCA)提出了一种新颖的训练无关框架,通过巧妙地利用模型现有的位置索引和引入多面向的注意力机制,允许LLMs扩展超过8倍的训练长度,而无需昂贵和耗时的进一步训练。
DCA的创新点在于它与Flash Attention的兼容性,仅需要对推理代码进行修改,无需进行大量的重新训练。DCA在训练长度内保持模型性能,并在此范围之外提供额外的性能提升,与已经进行了长上下文微调的模型兼容。因此,DCA可能对行业产生重大影响,为LLM应用中的长上下文场景提供了一种成本效益高的解决方案。
在长上下文能力的评估中,DCA展现了显著的性能,能够在不增加训练成本的情况下,与现有的最先进模型相媲美,甚至超越。例如,DCA与Llama2 70B集成后,展现了处理超过100k tokens上下文大小的卓越扩展能力。此外,DCA还与现有的长上下文LLMs(如PI和NTK)正交,实验证明,已经支持32k上下文窗口的现有长上下文LLMs可以进一步扩展到192k上下文长度,同时保持高通行密钥检索精度和低困惑度(PPL)。
总之,DCA为长上下文LLMs提供了一种高效且无需额外训练的扩展方法,这对于处理大规模文本数据,如PDF分析、长对话历史保持和交互式聊天机器人等应用至关重要。